






RDD 详解
为什么需要 RDD
分布式计算需要:
- 分区控制
- Shuffle 控制
- 数据存储\序列化\发生
- 数据计算 API
- 等一系列功能
不能简单的通过 Python 内置的本地集合对象(List\字典等)去完成。
在分布式框架中,需要由一个统一的数据抽象对象,来实现上述功能。
这个抽象对象,就是 RDD
RDD 定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
- Dataset:一个数据集合,用于存放数据的。
- Distributed:RDD 中的数据是分布式存储的,可用于分布式计算。
- Resilient:RDD 中的数据可以存储在内存中或者磁盘中。
RDD 五大特性

1)RDD 是有分区的
RDD 的分区是 RDD 数据存储的最小单位。
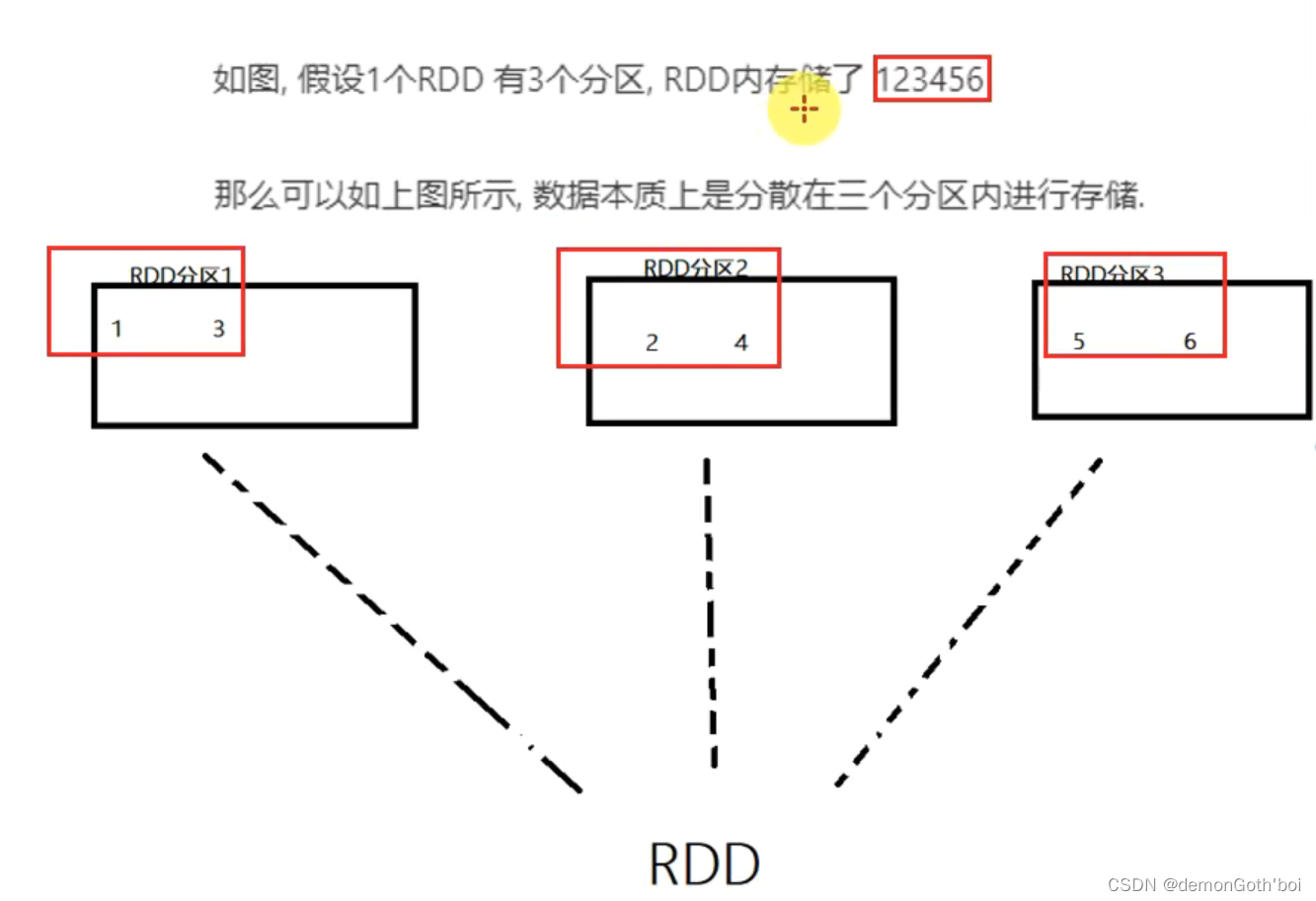
2)计算方法都会作用到每一个分片(分区)之上
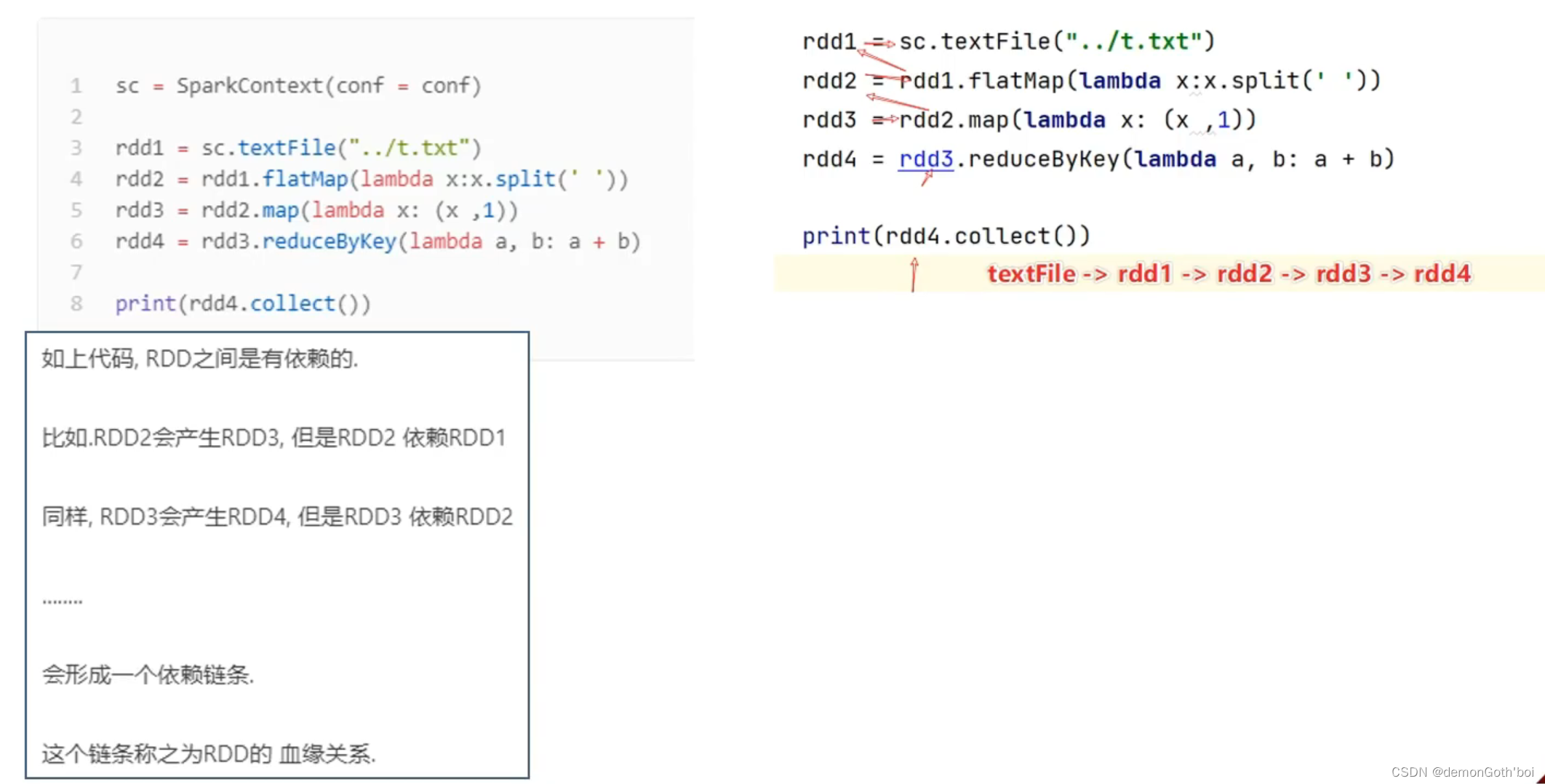
3)RDD 之间是有相互依赖的关系的
4)KV 型 RDD 可以有分区器
5)RDD 分区数据的读取会尽量靠近数据所在地

以上图片资源来自于黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









