 MapReduce本地与集群词频统计步骤
MapReduce本地与集群词频统计步骤




一、目的
练习本地模式和集群模式进行词频统计
二、本地模式的词频统计步骤
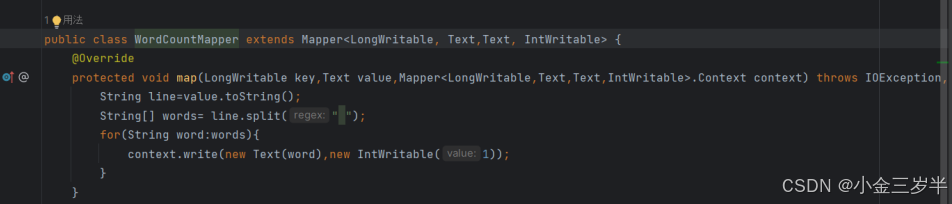
1.首先使用mapper组件处理数据,讲TextInputFormat映射的键值对转化为数据类型<Text,IntWritable>的键值对,其中键为每个单词,值为1,创建wordcountmapper文件。
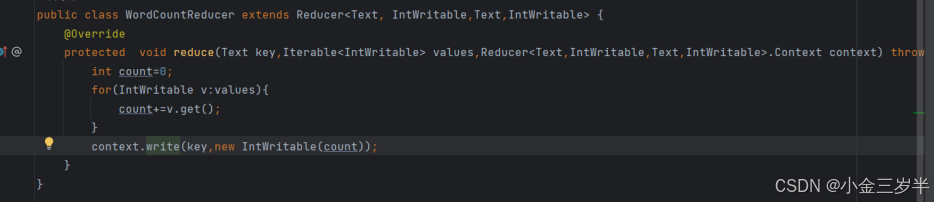
2.使用reducer组件处理数据,对mapper组件输出到reducer组件的数据进行处理,将相同见对应的值累加,从而统计每个单词的出现次数,创建wordcountreducer文件。
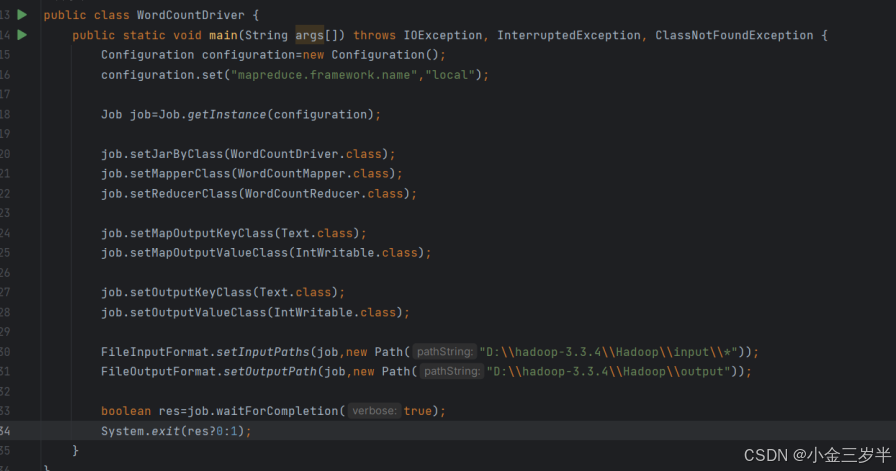
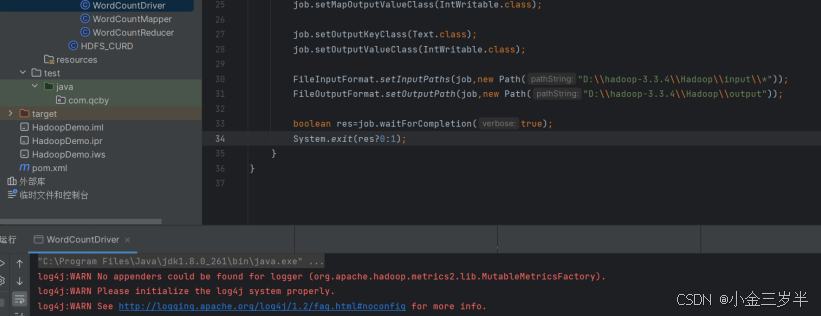
3.本地运行方式实现mapreduce程序的驱动类
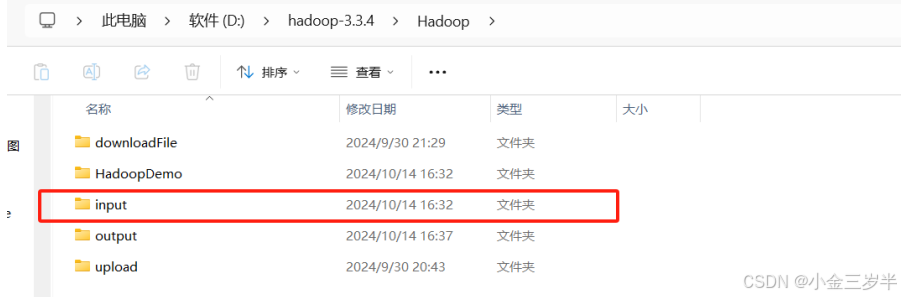
4.在本地创建input文件夹
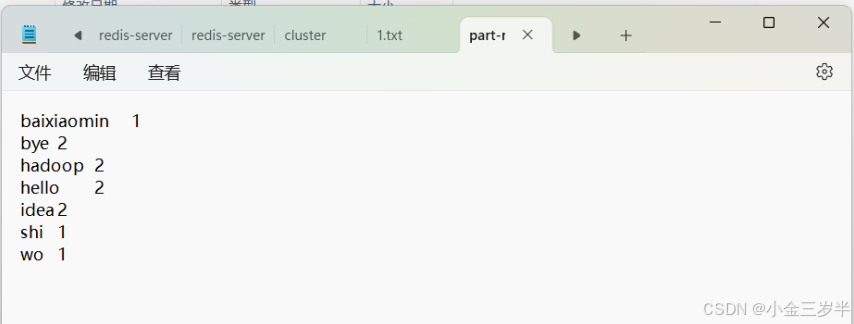
5.运行程序查看output中进行的词频统计的结果。
三、集群运行词频统计步骤
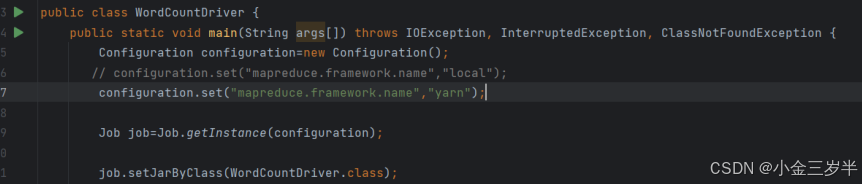
1.指定mapreduce程序运行模式为本地运行,将local修改为yarn
2.指定的文本文件的输入路径和输出结果的输出路径是固定的,如果修改了路径,那么还需要重新封装jar文件,这对于使用集群模式运行mapreduce程序来说非常不变,所以需要修改文件的路径,args[0]表示第一个参数为文本文件的输入路径,args[1]表示第二个参数为处理结果的输出路径

3.在集成开发工具idea中右侧单机maven按钮,然后双击折叠框下的package选项,即可在idea的控制台看到jar文件的封装流程以及其存储路径。
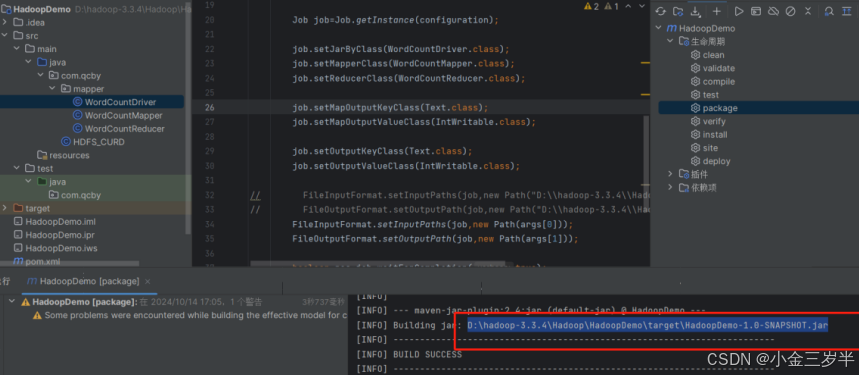
4.将封装的jar文件命名为wordcount-1.0-SNAPSHOT.jar
5.将word count-1.0-SNAPSHOT.jar文件上传到Hadoop集群所在的虚拟机的任意目录

6.将文本文件上传到hdfs的input目录

7.确保Hadoop集群处于启动状态,将mapreduce程序提交到yarn集群运行。
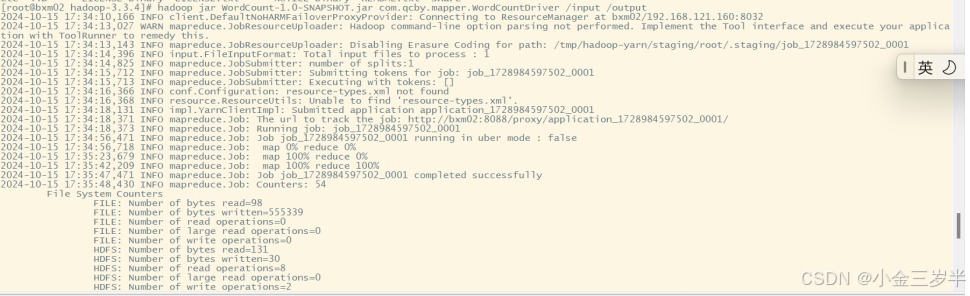
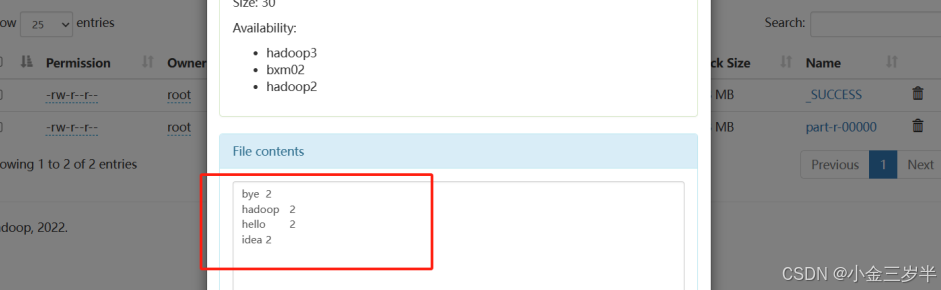
8.在output中查看词频统计的结果

















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









