






 本文介绍了如何使用自然语言处理方法实现bigram模型,包括数据预处理(如提取中文字符、构建字典)、频次矩阵计算、加一平滑处理以及生成推荐词的过程。代码示例详细展示了整个流程和技术细节。
本文介绍了如何使用自然语言处理方法实现bigram模型,包括数据预处理(如提取中文字符、构建字典)、频次矩阵计算、加一平滑处理以及生成推荐词的过程。代码示例详细展示了整个流程和技术细节。
- 设计思路
-
代码整体实现步骤
- 运行结果展示
-
源代码
设计思路
这里参考自然语言处理作业(实现bigram)_哔哩哔哩_bilibili的思路
先遍历语料库里的汉字,为每个汉字建立一个类似如下的字典:

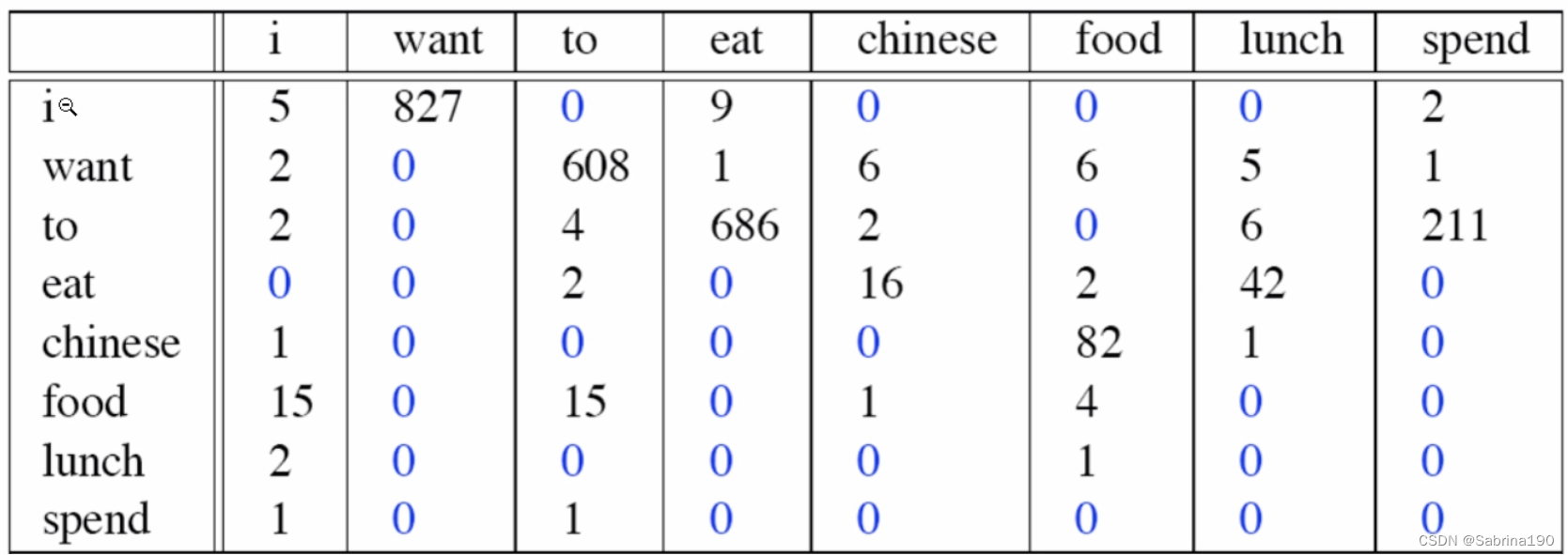
然后遍历整个文档(只保留汉字字符),为每个汉字建立其后一个汉字出现的频次,得到类似如下的矩阵:
用上面的矩阵通过加一平滑法平滑后,除以总频次,得到类似如下的概率矩阵。然后就可以根据输入的字查找概率最大的5个字作为二元词组的后一个字。
<
代码整体实现步骤
源代码
这里参考自然语言处理作业(实现bigram)_哔哩哔哩_bilibili的思路
先遍历语料库里的汉字,为每个汉字建立一个类似如下的字典:
然后遍历整个文档(只保留汉字字符),为每个汉字建立其后一个汉字出现的频次,得到类似如下的矩阵:
用上面的矩阵通过加一平滑法平滑后,除以总频次,得到类似如下的概率矩阵。然后就可以根据输入的字查找概率最大的5个字作为二元词组的后一个字。
< 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























