







填充和步幅
填充
- 给定(32 x 32)输入图像
- 应用 5 x 5 大小的卷积核
- 第1层得到输出大小 28 x 28
- 第7层得到输出大小 4 x 4
- 更大的卷积核可以更快地减小输出大小
- 形状从 n h × n w n_h \times n_w nh×nw 减少到 ( n h − k h + 1 ) × ( n w − k w + 1 ) (n_h - k_h + 1) \times (n_w - k_w + 1) (nh−kh+1)×(nw−kw+1)
填充是在输入周围添加额外的行 / 列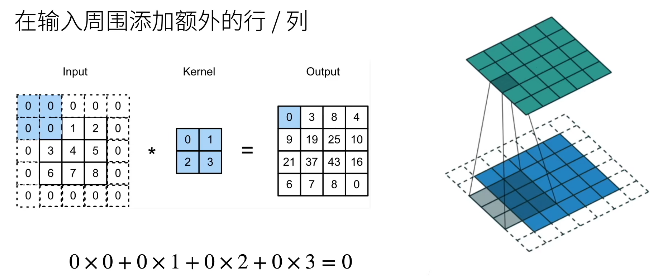
-
填充 p h p_h ph 行和 p w p_w pw 列,输出形状为
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) (n_h - k_h + p_h + 1) \times (n_w - k_w + p_w + 1) (nh−kh+ph+1)×(nw−kw+pw+1) -
通常取 p h = k h − 1 p_h = k_h - 1 ph=kh−1, p w = k w − 1 p_w = k_w - 1 pw=kw−1
-
当 k h k_h kh 为奇数:在上下两侧填充 p h / 2 p_h / 2 ph/2
-
当 k h k_h kh 为偶数:在上侧填充 [ p h / 2 ] [p_h / 2] [ph/2],在下侧填充 [ p h / 2 ] [p_h / 2] [ph/2]
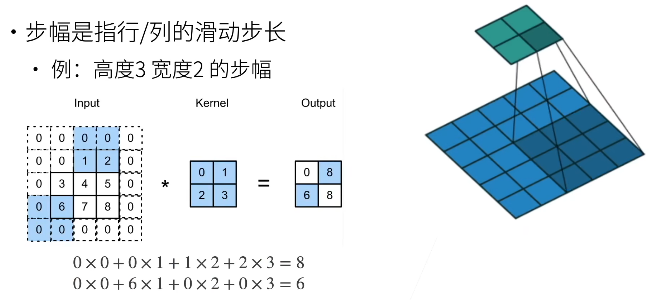
步幅
- 填充减小的输出大小与层数线性相关
- 给定输入大小 224 x 224,在使用 5 x 5 卷积核的情况下,需要 55 层将输出降低到 4 x 4
- 需要大量计算才能得到较小输出
-
给定高度 s h s_h sh 和宽度 s w s_w sw 的步幅,输出形状是
⌊ n h − k h + p h + s h s h ⌋ × ⌊ n w − k w + p w + s w s w ⌋ \left\lfloor \frac{n_h - k_h + p_h + s_h}{s_h} \right\rfloor \times \left\lfloor \frac{n_w - k_w + p_w + s_w}{s_w} \right\rfloor ⌊shnh−kh+ph+sh⌋×⌊swnw−kw+pw+sw⌋ -
如果 p h = k h − 1 p_h = k_h - 1 ph=kh−1, p w = k w − 1 p_w = k_w - 1 pw=kw−1
⌊ n h + s h − 1 s h ⌋ × ⌊ n w + s w − 1 s w ⌋ \left\lfloor \frac{n_h + s_h - 1}{s_h} \right\rfloor \times \left\lfloor \frac{n_w + s_w - 1}{s_w} \right\rfloor ⌊shnh+sh−1⌋×⌊swnw+sw−1⌋ -
如果输入高度和宽度可以被步幅整除
( n h / s h ) × ( n w / s w ) (n_h / s_h) \times (n_w / s_w) (nh/sh)×(nw/sw)
总结
- 填充和步幅是卷积层的超参数
- 填充在输入周围添加额外的行/列,来控制输出形状的减少量
- 步幅是每次滑动核窗口时的行/列的步长,可以成倍的减少输出形状
代码实现
在所有侧边填充 1 个像素
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8)) #表示输入张量的高度为8,宽度为8
comp_conv2d(conv2d, X).shape # .shape 用来获取输出张量的维度信息。 而不需要张量本身的内容
# torch.Size([8, 8])
填充不同的高度和宽度
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
# 表示核的行数是五行,列数是三列,上下填充的行数为2,表示上下分别填充两行
comp_conv2d(conv2d, X).shape
# torch.Size([8, 8])
将高度和宽度的步幅设置为 2
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
# torch.Size([4, 4])
下面是一个稍微复杂点的例子:
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
# 这里利用计算公式可以算出来对应的结果,
# 对于高度 (8-3+2*0)/3 +1 然后向下取整,得到2
# 对于宽度(8-5+2*1)/4 +1然后向下取整,结果还是2
comp_conv2d(conv2d, X).shape
# torch.Size([2, 2])
QA 思考
Q1:这几个超参数的影响重要程度排序是如何?核大小,填充,步幅
A1:一般来说。填充会使得输入和输出的高宽是一样的,填充通常会取 核 - 1。这样做比较的方便。步幅,通常来说,为1是最好的,这样能看的东西更多,但是不选步幅为1的话,就是计算量太大了,但是也只是取到2,主要还是要看将模型复杂度控制到何种程度。
Q2:为啥卷积核的边长一般选奇数?
A2:偶数也是可以的,效果也是差不多的,但是选奇数的话,对称一点。一般取 3*3 居多。
Q3:现在已经有很多经典的网络结构了,对应于各种任务有各种结构,我们平时使用的时候,自己设计卷积核大小的情况多吗,还是说直接套用经典网络结构?
A3:要是输入不是特别特殊的话,一般就是套用经典的架构,或者是在经典的架构上稍微做一点调整。
Q4:一般调用卷积层的时候,只有一个padding参数和一个stride参数,怎么应用老师提到的分别高度填充和宽度填充,以及分别高度步幅和宽度步幅?
A4:要想分别的话,可以用一个tuple,如下:
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
Q5:为什么通常用3x3的卷积核呢?3个像素的视野感觉很小?
A5:3*3 其实没有问题,只是说我用了比较小的卷积核,我就需要比较深的神经网络使得我的最后一层每个元素能够看到足够多的图片的信息。

















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









