







一:自动化测试
1.1 自动化概念
自动化是指用机器或系统代替人工行为来完成操作。自动化在日常生活中随处可见,并广泛应用于各个领域,同理软件中的测试也可以进行自动化。

1.2 UI 自动化
UI 测试也称为界面测试,是用于验证软件用户界面的功能和表现是否符合预期的一种测试方式。常见的 UI 自动化测试包括 Web 自动化测试和移动端自动化测试。
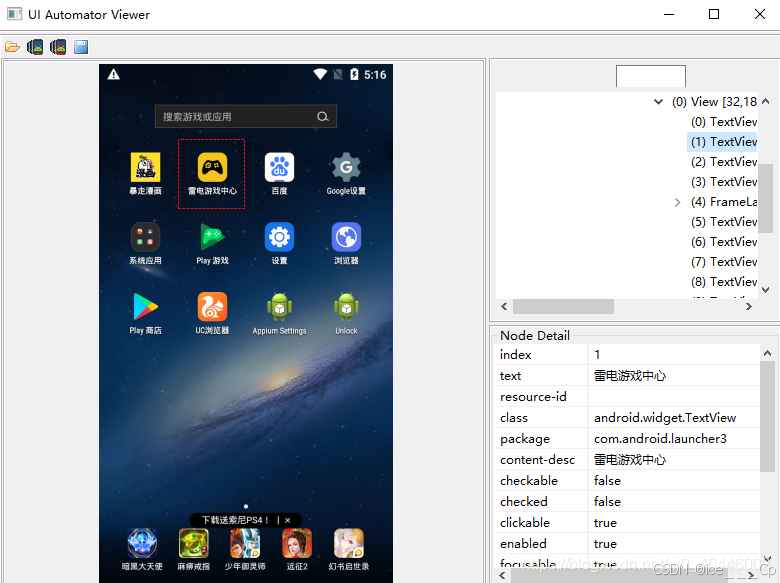
1.3 自动化测试金字塔
自动化测试的类型多种多样,那么哪种类型最优?哪种测试能够带来更高的收益?为了解决这一问题,测试领域引入了一个非常著名的概念——自动化测试金字塔。
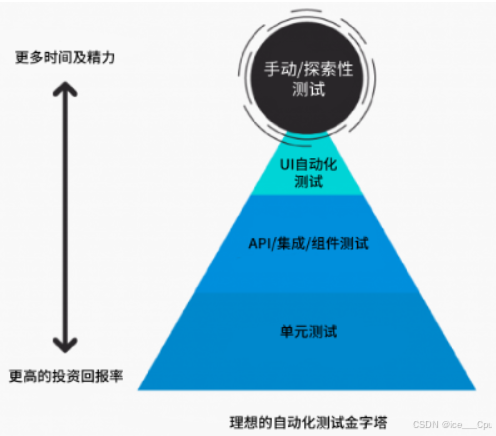
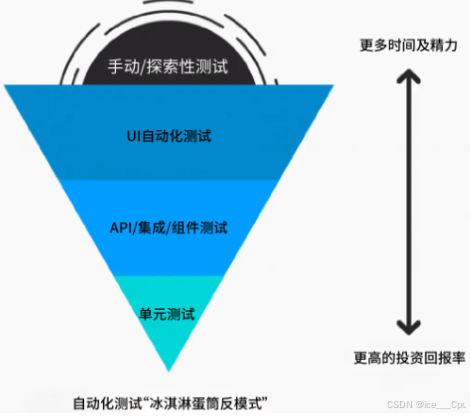
理想的自动化测试金字塔展示了自动化测试的最佳效果,即通过在单元测试上投入较少的时间和精力,就能有效发现大多数问题,因为单元测试成本低执行快。然而,在实际的企业环境中,自动化测试常常呈现出“冰淇淋蛋筒反模式”,即更多的测试集中在用户界面层,而单元测试和服务层测试较少,让开发过程中难以及时发现底层逻辑缺陷。
1.4 web 自动化测试
1.4.1 驱动
“驱动”一词广泛应用于各个领域。汽车需要驱动才能行驶,计算机依靠驱动程序与设备(如耳机、摄像头、麦克风、键盘、显示器等)进行通信,从而确保设备的正常运行和交互。同样地,程序要想打开 Web 浏览器,也需要安装 Web 驱动即 WebDrive 。WebDriver 通过本地化方式驱动浏览器,实现对浏览器的控制和操作。
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>5.8.0</version>
<scope>test</scope>
</dependency>
1.4.2 Selenium
万事俱备,只欠东风。接下来便是使用 Selenium 编写 Web 自动化测试脚本。Selenium 是一款功能强大的 Web 自动化测试工具,提供了丰富的方法和功能,帮助用户高效地完成 Web 自动化测试任务。
- 安装 selenium 库
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0</version>
</dependency>
- 使用 selenium 编写代码
public void example_test() {
// 1. 自动配置并下载Chrome浏览器驱动,无需手动管理驱动版本
WebDriverManager.chromedriver().setup();
// 2. 配置Chrome浏览器选项,解决跨域访问限制(常见于本地测试环境)
ChromeOptions options = new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
// 3. 初始化WebDriver实例,启动Chrome浏览器并应用配置选项
WebDriver driver = new ChromeDriver(options);
// 4. 导航至目标页面(百度首页),模拟用户访问行为
driver.get("https://www.baidu.com");
// 5. 定位搜索框并输入关键词(迪丽热巴)
// 使用XPath定位元素:通过页面元素的XPath路径精准定位
// sendKeys()方法:模拟键盘输入,触发搜索关键词
driver.findElement(By.xpath("//*[@id=\"kw\"]")).sendKeys("迪丽热巴");
// 6. 定位搜索按钮并执行点击操作
// click()方法:模拟鼠标点击,触发搜索动作
driver.findElement(By.xpath("//*[@id=\"su\"]")).click();
// 7. 关闭浏览器并释放资源,避免残留进程占用内存
driver.quit();
}
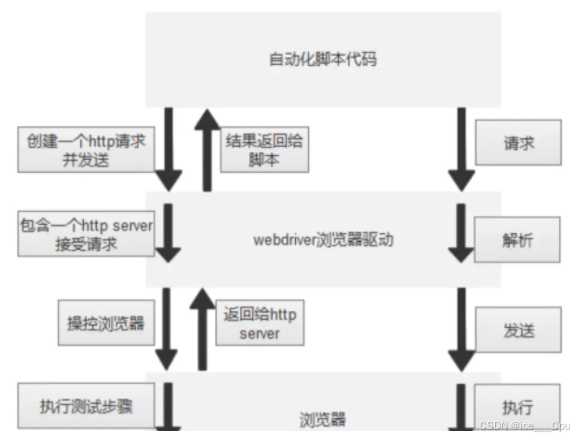
1.4.3 selenium + 驱动 + 浏览器的工作原理
实现 Web 自动化测试需要浏览器、浏览器驱动和 Selenium 自动化脚本,这三者通过协同工作完成自动化操作:
| 步骤 | 描述 |
|---|---|
| 1 | 在 Selenium 自动化脚本中,通过 ChromeDriverService 创建一个服务,用于管理浏览器驱动的运行。 |
| 2 | 启动创建的服务,打开 WebDriver,本地驱动服务的地址为 localhost,端口号由 ChromeDriverService 指定,作为服务地址。 |
| 3 | 向浏览器驱动程序发送 HTTP 请求,驱动程序解析请求,启动浏览器并生成一个 sessionId,后续操作需携带此 sessionId。 |
| 4 | 浏览器启动后,所有 Selenium 的操作(如访问地址、查找元素等)通过服务地址链接到 WebDriver,然后使用 execute 方法发送请求。 |
| 5 | 浏览器驱动收到请求后进行解析,将其转换为浏览器可执行的命令脚本并发送给浏览器,浏览器根据请求内容执行相应操作。 |
| 6 | 浏览器将执行结果通过驱动程序返回给 Selenium 测试脚本,完成操作的反馈和结果传递。 |
简单点说:你写好的自动化测试代码,这些指令是给人看的,浏览器听不懂,而驱动就是专门负责把 Selenium 的指令翻译成浏览器能理解的“机器语言”的一个翻译官,它还会在本地启动一个小服务,用来接收 Selenium 的指令并转发给浏览器,浏览器收到翻译后的指令后就老老实实执行操作,执行完后,它会把结果通过驱动“回传”给Selenium脚本,脚本就知道测试是否成功了。
二: 自动化测试常用函数
Web自动化测试的核心在于能够准确定位页面上的元素,这是对元素进行具体操作的前提。常见的元素定位方式包括 id、classname、tagname、xpath 和 cssSelector 等,其中最常用的方式是 cssSelector 和 xpath。
2.1 cssSelector
选择器的作用是用于选中页面中指定的标签元素。选择器分为基础选择器和复合选择器两类,常见的元素定位方式可以通过 id 选择器和子类选择器进行定位。
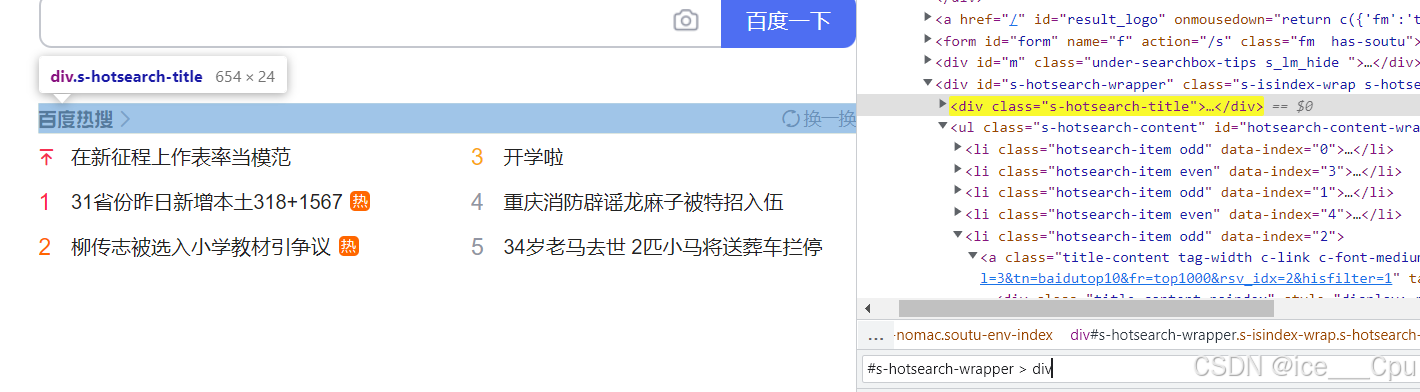
2.2 xpath
XPath 翻译为XML路径语言,它不仅可以用于在XML文件中查找信息,还可以在HTML中选取节点。它通过路径表达式来定位和选择 XML 文档中的节点。
| 功能描述 | XPath 表达式 | 示例 |
|---|---|---|
| 获取 HTML 页面所有的节点 | //* | - |
| 获取 HTML 页面指定的节点 | //[指定节点] | //ul:获取所有的 ul 节点 |
| 获取一个节点中的直接子节点 | / | //span/input:获取 span 下的 input 子节点 |
| 获取一个节点的父节点 | … | //input/… :获取 input 节点的父节点 |
| 实现节点属性的匹配 | [@属性名=‘值’] | //*[@id=‘kw’]:匹配 id 属性为 kw 的节点 |
| 使用指定索引的方式获取对应的节点内容 | 索引从 1 开始 | //div/ul/li[3]:获取百度热搜的第三个标签 |
更便捷的生成 selector/xpath 的方法是通过右键操作选择“Copy selector”或“Copy xpath”,手动复制的 selector 或 xpath 表达式并不总是满足唯一性要求,有时可能需要手动修改或优化表达式以确保其唯一性和准确性。
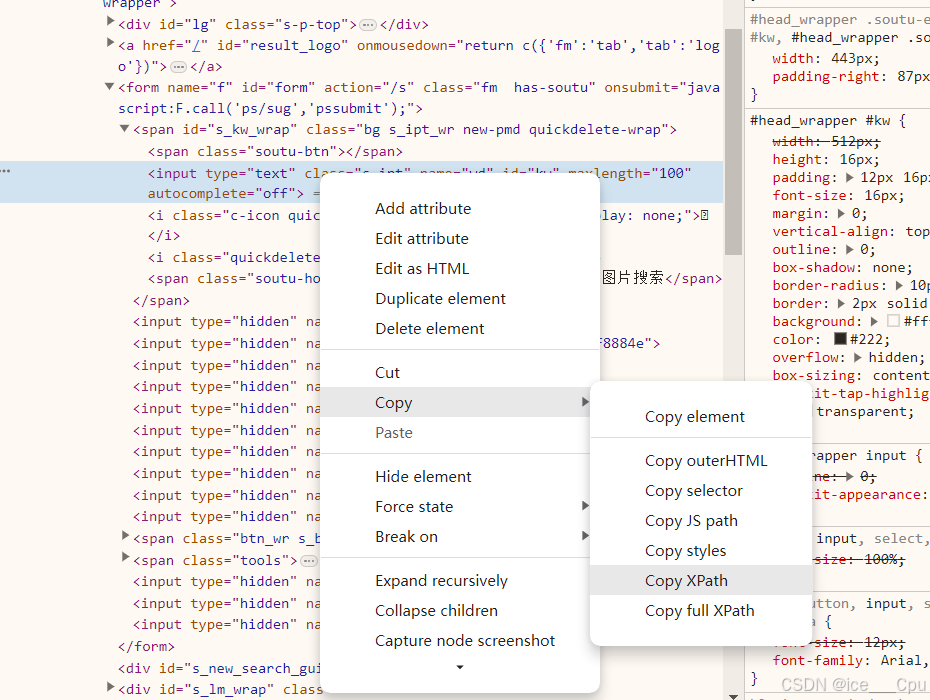
2.3 操作测试对象
获取页面元素后,可以对其执行一系列操作。常见的操作包括点击、提交、输入内容、清除内容以及获取文本等。
2.3.1 点击 / 提交对象
// 找到百度一下按钮并点击
driver.findElement(By.cssSelector("#su")).click();
| 名称 | 作用与描述 |
|---|---|
| findElement | Selenium 提供的方法,用于在当前页面中查找单个元素。通过指定的定位方式(如 cssSelector、id、xpath 等)定位目标元素,并返回 WebElement 对象。如果找不到匹配元素,会抛出 NoSuchElementException 异常。 |
| By | Selenium 提供的辅助类,用于定义各种元素定位方式:
By.id:通过元素的 id 属性定位 By.name:通过元素的 name 属性定位 By.xpath:通过 XPath 表达式定位 |
| cssSelector | 一种通过 CSS 选择器定位元素的方式,支持灵活且复杂的定位规则,适用于需要复杂选择逻辑的场景。 |
2.3.2 模拟按键输入
driver.findElement(By.cssSelector("#kw")).sendKeys("输⼊⽂字");
2.3.3 清除文本内容
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱游戏");
driver.findElement(By.cssSelector("#kw")).clear();
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱学习");
2.3.4 获取文本信息
// 获取指定元素的文本内容
String bdtext = driver.findElement(By.xpath("//*[@id='title-content']/span[1]")).getText();
System.out.println("打印的内容是:" + bdtext);
2.3.5 获取当前页面标题
// 获取当前页面的标题
String pageTitle = driver.getTitle();
System.out.println("当前页面的标题是:" + pageTitle);
2.3.6 获取当前页面 URL
// 获取当前页面的 URL
String pageURL = driver.getCurrentUrl();
System.out.println("当前页面的 URL 是:" + pageURL);
2.4 窗口
在手动测试时,我们可以通过肉眼判断当前的窗口是什么,但对于程序来说它无法直接知道当前最新的窗口是哪一个。在自动化测试中,每个浏览器窗口都有一个唯一的标识属性 -> 句柄。通过这个句柄,程序可以识别并切换到指定的窗口,从而进行操作。
2.4.1 切换窗口
2.4.1.1 获取当前页面句柄
// 获取当前页面的句柄
String currentHandle = driver.getWindowHandle();
System.out.println("当前页面的句柄是:" + currentHandle);
2.4.1.2 获取所有页面句柄
// 获取所有页面的句柄
Set<String> allHandles = driver.getWindowHandles();
System.out.println("所有页面的句柄是:" + allHandles);
2.4.1.3 切换当前句柄为最新页面
// 获取当前页面的句柄
// 1. 获取当前窗口句柄(假设当前窗口是 A)
String curWindow = driver.getWindowHandle();
// 2. 打开新窗口(例如点击链接后新开窗口 B)
// ... 执行打开新窗口的操作 ...
// 3. 获取所有窗口句柄(此时包含 A 和 B)
Set<String> allWindows = driver.getWindowHandles();
// 4. 遍历所有句柄,找到非当前窗口的句柄(即 B)
for (String window : allWindows) {
if (!window.equals(curWindow)) {
driver.switchTo().window(window); // 切换到窗口 B
break; // 找到后立即退出循环
}
}
注意:每次打开新页面新窗口时句柄是随机生成的,当前句柄并不会自动指向新窗口,而是需要手动切换。这段代码正是用来处理这种情况的,通过比较当前句柄和所有句柄,找到新窗口并切换过去,遍历是必须的:因为无法预知新窗口的句柄,必须通过遍历找到它。但是这段代码只能用于两个页面的切换,要是多个页面就不能精确切换了。
例如,当用户点击一个链接,该链接在新标签页打开时,Selenium 的焦点仍然停留在原来的窗口,此时必须切换到新窗口才能进行后续操作。否则,任何查找元素的操作都会在旧窗口中执行,导致失败。
2.4.2 窗口设置大小
//窗⼝最⼤化
driver.manage().window().maximize();
//窗⼝最⼩化
driver.manage().window().minimize();
//全屏窗⼝
driver.manage().window().fullscreen();
//⼿动设置窗⼝⼤⼩
driver.manage().window().setSize(new Dimension(1024, 768));
2.4.3 屏幕截图
在自动化测试中,脚本通常会部署在机器上自动运行。如果出现错误,我们无法实时得知问题原因,因此可以通过截图来记录当时的错误场景,方便后续排查和分析。实现屏幕截图功能需要额外导入相关的库或包。
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
public class ScreenshotExample {
// 简单版本:截取屏幕截图并保存为固定文件名
public static void simpleScreenshot(WebDriver driver) throws IOException {
// 将当前页面截屏保存为文件
File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
// 将截取的文件保存为 "my.png" 文件
FileUtils.copyFile(srcFile, new File("my.png"));
System.out.println("简单截图已保存为 my.png");
}
// 高阶版本:截取屏幕截图并动态生成文件路径
public static void advancedScreenshot(WebDriver driver, String basePath, String testName) throws IOException {
// 获取当前时间,用于生成唯一的文件名和文件夹
List<String> times = getTime(); // 假设该方法返回时间格式 ["2022-08-01", "214130"]
// 生成的文件夹路径,例如:./src/test/autotest-2022-08-01/goodsbroser-20220801-214130.png
String fileName = basePath + "/autotest-" + times.get(0) + "/" + testName + "-" + times.get(1) + ".png";
// 截取当前屏幕并保存为文件
File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
// 将截取的文件保存到指定路径
FileUtils.copyFile(srcFile, new File(fileName));
System.out.println("高阶截图已保存为:" + fileName);
}
// 示例时间获取方法(需实现逻辑)
public static List<String> getTime() {
// 返回时间列表,例如 ["2022-08-01", "214130"],表示日期和时间
// 可以通过 Java 的日期和时间 API 实现此方法
return List.of("2022-08-01", "214130");
}
public static void main(String[] args) throws IOException {
// 示例 WebDriver(需替换为实际驱动实例)
WebDriver driver = null; // 初始化你的 WebDriver 实例
// 调用简单截图方法
simpleScreenshot(driver);
// 调用高阶截图方法,设置基础路径和测试名称
advancedScreenshot(driver, "./src/test", "goodsbrowser");
}
}
2.4.4 关闭窗口
driver.close();
执行 driver.close() 之前需要切换到未被关闭的窗口,窗口关闭后 driver 要重新定义。
2.5 等待
2.5.1 强制等待
// 强制等待 5 秒
Thread.sleep(5000);
System.out.println("强制等待了 5 秒");
2.5.2 隐式等待
// 设置隐式等待时间为 10 秒
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
System.out.println("隐式等待已设置为 10 秒");
2.5.3 显示等待
显示等待也是⼀种智能等待,在指定超时时间范围内只要满足操作的条件就会继续执行后续代码
// 创建 WebDriverWait 对象,设置最大等待时间为 15 秒
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(15));
// 等待指定元素可见
WebElement element = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("example")));
System.out.println("元素已可见:" + element.getText());
代码的大意是创建一个 WebDriverWait 对象,设置最大等待时间为 15 秒,然后等待 ID为"example"的元素可见,一旦元素可见,就获取该元素并输出其文本内容。
2.5.4 总结
| 等待方式 | 优点 | 缺点 |
|---|---|---|
| 强制等待 | 简单易用,通过固定时间实现,无需额外条件设置。 | 不灵活,会固定等待时间,无论条件是否满足都会等待完全时间,可能导致测试效率低下或时间浪费。 |
| 隐式等待 | 全局设置,作用于所有查找元素的操作,设置一次即可,适合处理页面元素短暂延迟的场景。 | 只适用于查找元素,无法等待其他条件(如页面加载完成或特定文本出现),对于复杂场景不够精确。 |
| 显式等待 | 灵活性强,可根据特定条件(如元素可见、可点击、URL 匹配等)精准等待,避免不必要的时间浪费。 | 相比隐式等待,代码实现稍显复杂,需要单独为每个条件编写逻辑,可能增加代码量。 |
2.6 浏览器导航
Selenium WebDriver 提供的接口,用于控制浏览器的导航操作,如跳转到指定的 URL、前进、后退、刷新页面等操作。
| 方法 | 用途 |
|---|---|
| navigate().to(String url) | 跳转到指定的 URL,相当于 driver.get(url),但更适用于复杂导航场景。 |
| navigate().back() | 浏览器后退到上一页,模拟浏览器的后退按钮操作。 |
| navigate().forward() | 浏览器前进到下一页,模拟浏览器的前进按钮操作。 |
| navigate().refresh() | 刷新当前页面,模拟浏览器的刷新按钮操作。 |
- 打开网站
// 更⻓的⽅法
driver.navigate().to("https://selenium.dev");
// 简洁的⽅法
driver.get("https://selenium.dev");
- 浏览器的前进、后退、刷新
driver.navigate().back();
driver.navigate().forward();
driver.navigate().refresh();
2.7 弹窗
2.7.1 警告弹窗 + 确认弹窗
弹窗是在页面是找不到任何元素的,此时就可以使用 Selenium 提供的 Alert 接口来处理弹窗。通过 Alert 接口,能够完成弹窗的接受、取消、获取弹窗文本等操作,从而应对弹窗相关的测试场景。
// 切换到弹窗(Alert)
Alert alert = driver.switchTo.alert();
//确认
alert.accept()
//取消
alert.dismiss()

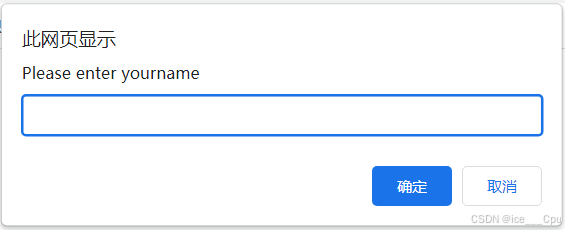
2.7.2 提示弹窗
// 切换到弹窗(Alert)
Alert alert = driver.switchTo().alert();
// 向弹窗中输入文本(适用于带输入框的弹窗)
alert.sendKeys("hello");
// 确认弹窗
alert.accept();
// 取消弹窗
alert.dismiss();
2.8 文件上传
在文件上传的场景中,会弹出系统自带的文件选择窗口。由于 Selenium 无法识别非 Web 的控件,系统窗口中的元素无法被直接定位。然而,可以通过在文件上传的输入框中使用 sendKeys 方法,直接指定文件路径来实现文件上传,从而达到与手动选择文件相同的效果。
// 定位文件上传的输入框
WebElement ele = driver.findElement(By.cssSelector("body > div > div > input[type=file]"));
// 使用 sendKeys 方法,将指定路径的文件直接上传
ele.sendKeys("D:\\selenium2html\\selenium2html\\upload.html");
2.9 浏览器参数设置
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class BrowserConfigExample {
public static void main(String[] args) {
// 创建 ChromeOptions 对象,用于设置浏览器参数
ChromeOptions options = new ChromeOptions();
// 1. 设置无头模式(Headless Mode)
options.addArguments("--headless");
// 2. 设置浏览器加载策略(正常加载、延迟加载等)
options.setExperimentalOption("pageLoadStrategy", "eager"); // "eager" 表示延迟加载
// 创建 WebDriver 实例并传入配置
WebDriver driver = new ChromeDriver(options);
// 打开网页
driver.get("https://www.example.com");
System.out.println("当前页面标题是:" + driver.getTitle());
// 关闭浏览器
driver.quit();
}
}
| 设置项 | 作用 |
|---|---|
| 无头模式(Headless Mode) | 无头模式是指浏览器在后台运行,不会显示图形界面。适用于需要提升测试执行速度、不需要用户界面的测试场景(如服务器上运行的自动化测试)。 |
| 浏览器加载策略 | normal(默认值):等待页面所有资源完全加载后再继续操作。
eager:等待页面的 DOMContentLoaded 事件触发后(即 HTML 文档加载完成,但不等待图片和样式加载完成)继续操作。 none:不等待页面加载,直接继续执行操作,适用于不关心页面加载的场景。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











