






FastDFS原理
FastDFS是一个用C语言编写的开源轻量级分布式文件系统,它专为解决大容量文件存储和高并发访问问题而设计,特别适合于存储4KB至500MB之间的小文件,如图片、视频、文档等。FastDFS充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标。以下是FastDFS原理的详细解析:
一、架构组成
FastDFS的架构主要由三个部分组成:
- 客户端(Client):上传下载数据的服务器,即项目所部署的服务器。
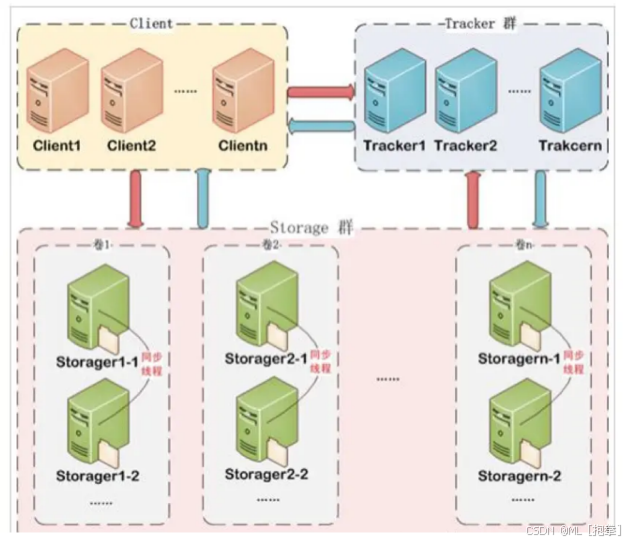
- 跟踪服务器(Tracker Server):主要负责服务调度和负载均衡。它管理所有的Storage Server和Group,每个Storage Server在启动后会连接Tracker Server,告知自己所属Group等信息,并保持周期性心跳。
- 存储服务器(Storage Server):主要提供容量和备份服务。以Group为单位,每个Group内可以有多台Storage Server,数据互为备份。
二、工作原理
1. 文件上传流程
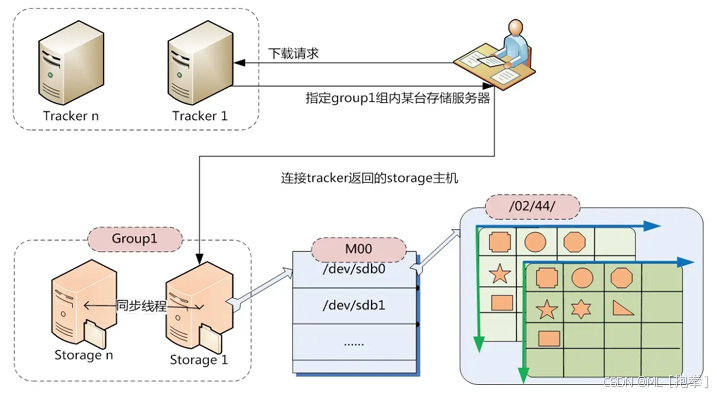
- 选择Tracker Server:客户端在上传文件时,可以任意选择一个Tracker Server进行连接。
- 分配Group、Storage Server和存储路径:Tracker Server接收到上传请求后,会为该文件分配一个可以存储的Group,然后在Group中分配一个Storage Server给客户端,最后在接收到客户端写文件请求时,Storage Server会分配一个数据存储目录并写入文件。
- 生成file_id并返回:Storage Server会生成一个file_id作为当前文件名,该file_id采用base64编码,包含源Storage Server IP、文件创建时间、文件大小、文件CRC32校验码和随机数等信息。然后,Storage Server会根据file_id进行两次hash路由,将文件存储到指定的子目录下,并返回文件路径给客户端。
2. 文件下载流程
- 请求Tracker Server:客户端发送文件下载请求给Tracker Server,请求中必须包含文件名信息。
- 解析文件名并选择Storage Server:Tracker Server从文件名中解析出文件的Group、大小、创建时间等信息,然后根据这些信息选择一个可用的Storage Server返回给客户端。
- 文件访问:客户端与选定的Storage Server建立连接,校验文件是否存在,并最终返回文件数据给客户端。
3. 文件同步
- 组内同步:文件同步只在Group内的Storage Server之间进行,采用push方式。源服务器读取binlog文件,将文件内容解析后,按操作命令发送给目标服务器,目标服务器按命令进行操作。
- 同步进度管理:Storage Server会记录向Group内其他Storage Server同步的进度,以便重启后能接上次的进度继续同步。进度信息以时间戳的方式记录,并会上报到Tracker Server。
三、特性与优势
- 高可靠性:采用分布式存储技术,可以实现数据备份和故障转移,保证数据的可靠性和稳定性。
- 高可扩展性:支持快速扩展存储容量和性能,满足业务增长需求。
- 高性能:通过负载均衡和分布式存储技术,实现高效的文件上传和下载服务。
- 易于集成:提供丰富的API和客户端工具,方便集成到各种应用系统中。
综上所述,FastDFS通过其独特的架构和工作原理,为互联网应用提供了高效、可靠、可扩展的文件存储解决方案。
FastDFS文件的上传
FastDFS文件的上传是一个涉及客户端、Tracker Server和Storage Server之间的交互过程。以下是FastDFS文件上传的详细步骤和原理:
一、上传流程
- 客户端请求Tracker Server:
- 客户端(Client)在上传文件时,首先会选择一个Tracker Server进行连接。Tracker Server作为调度中心,负责管理所有的Storage Server和Group。
- Tracker Server分配Storage Server:
- Tracker Server在接收到客户端的上传请求后,会根据一定的策略(如负载均衡、存储容量等)为文件分配一个合适的Group和Storage Server。
- Tracker Server将分配的Storage Server的IP地址和端口号返回给客户端。
- 客户端上传文件到Storage Server:
- 客户端根据Tracker Server返回的IP地址和端口号,与指定的Storage Server建立连接。
- 客户端将文件数据发送给Storage Server,Storage Server负责将文件存储在本地磁盘上。
- 生成文件ID并返回:
- 文件上传成功后,Storage Server会生成一个唯一的文件ID(file_id),该ID包含了文件的组名、虚拟磁盘路径、数据两级目录和文件名等信息。
- Storage Server将文件ID返回给客户端,客户端使用这个ID来后续访问文件。
二、文件ID的构成
文件ID是FastDFS中用于访问文件的唯一标识,它由以下几部分组成:
- 组名:文件上传后所在的storage组名称,由Tracker Server分配。
- 虚拟磁盘路径:storage配置的虚拟路径,与storage的配置文件中的store_path*对应,如M00、M01等。
- 数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据,目录名是根据文件ID的hash值生成的。
- 文件名:与文件上传时不同,是由存储服务器根据特定信息(如源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等)生成的。
三、FastDFS的优势
- 高性能:通过分布式存储和负载均衡技术,FastDFS能够提供高效的文件上传和下载服务。
- 高可靠性:数据在多个Storage Server之间进行备份,保证了数据的安全性和可靠性。
- 可扩展性:支持动态扩容,可以方便地增加新的Storage Server来扩展存储容量。
- 易用性:提供了丰富的API和客户端工具,方便集成到各种应用系统中。
四、注意事项
- 在进行文件上传时,需要确保客户端已经正确配置了Tracker Server的地址和端口号。
- 如果文件上传失败,可能是由于Tracker Server或Storage Server故障、网络问题或磁盘空间不足等原因导致的,需要根据具体情况进行排查和解决。
- 为了保证文件上传的效率和安全性,建议根据业务需求合理设置Tracker Server和Storage Server的数量和配置。
以上信息基于FastDFS的官方文档和广泛使用的实践经验总结得出,旨在为用户提供关于FastDFS文件上传的全面了解。
FastDFS文件的下载
FastDFS文件的下载过程是一个相对直接的过程,主要涉及客户端、Tracker Server和Storage Server之间的交互。以下是FastDFS文件下载的详细步骤和原理:
一、下载流程
- 客户端请求Tracker Server:
- 客户端在需要下载文件时,首先会选择一个Tracker Server进行连接。这个Tracker Server可以是集群中的任意一个,因为Tracker Server之间是对等的关系。
- Tracker Server解析文件信息:
- 客户端向Tracker Server发送下载请求,请求中需要包含文件的完整路径或文件名等必要信息。
- Tracker Server根据文件名等信息解析出文件所在的Group和Storage Server的信息。
- Tracker Server返回Storage Server信息:
- Tracker Server将解析出的Storage Server的IP地址和端口号返回给客户端。
- 客户端请求Storage Server:
- 客户端根据Tracker Server返回的IP地址和端口号,与指定的Storage Server建立连接。
- 客户端向Storage Server发送下载请求,请求中需要包含文件的路径或ID等信息。
- Storage Server返回文件数据:
- Storage Server在接收到下载请求后,根据请求中的路径或ID等信息找到对应的文件。
- Storage Server将文件数据发送给客户端,客户端接收并保存文件。
二、文件下载命令(以Linux为例)
在Linux系统中,可以使用fdfs_download_file命令来下载FastDFS中的文件。命令的基本格式如下:
groupName:文件所在的分组名称。remote_filename:远程文件名,即需要下载的文件名。[local_filename]:可选的本地文件名,默认为远程文件名。
三、Java客户端下载文件
在Java应用中,可以使用FastDFS提供的Java客户端API来实现文件的下载。大致流程包括初始化FastDFS客户端、获取文件元数据、下载文件到本地等步骤。具体实现可以参考FastDFS的Java客户端库文档和示例代码。
四、注意事项
- 在进行文件下载时,需要确保客户端已经正确配置了Tracker Server的地址和端口号。
- 如果文件下载失败,可能是由于Tracker Server或Storage Server故障、网络问题或文件不存在等原因导致的,需要根据具体情况进行排查和解决。
- 为了保证文件下载的效率和安全性,建议根据业务需求合理设置Tracker Server和Storage Server的数量和配置。
FastDFS作为一个开源的轻量级分布式文件系统,提供了高效、可靠、可扩展的文件存储和访问服务,特别适合用于大规模文件存储和管理的场景。
FastDFS同步时间管理
FastDFS的同步时间管理是确保文件在多个存储服务器(Storage Server)之间正确同步的关键机制。以下是对FastDFS同步时间管理的详细解析:
一、同步时间管理的必要性
在FastDFS系统中,文件一旦上传成功,就会被存储在一个或多个存储服务器上,以实现数据的冗余备份和负载均衡。为了确保数据的一致性和可用性,存储服务器之间需要保持同步,即确保同一文件在各个存储服务器上的副本是最新的。同步时间管理就是用来监控和协调这一同步过程,确保数据同步的准确性和及时性。
二、同步时间管理的实现方式
- 定时上报机制:
- 每个存储服务器都需要定时将自身的信息上报给跟踪服务器(Tracker Server)。这些信息包括本地同步时间(即同步到的最新文件的时间戳)等关键信息。
- Tracker Server根据各个存储服务器的上报情况,能够实时掌握每个存储服务器的同步状态,从而判断文件是否已经在组内的所有存储服务器上完成了同步。
- 时间戳记录:
- 存储服务器在生成文件名时,会包含文件的创建时间戳。这个时间戳用于标识文件的创建时间,也作为同步过程中的一个重要参考依据。
- 当客户端请求下载文件时,Tracker Server会根据文件的创建时间戳和各个存储服务器的同步时间戳来判断哪个存储服务器上的文件是最新的,从而选择最合适的存储服务器进行文件下载。
- 同步延迟处理:
- 由于网络延迟、服务器性能差异等原因,文件同步可能会存在一定的延迟。FastDFS通过配置同步延迟阀值和同步一个文件的最大时长等参数来处理这种情况。
- 当Tracker Server收到客户端的下载请求时,会根据这些参数来判断存储服务器上的文件是否已经同步完成,从而确保客户端能够下载到最新的文件。
三、同步时间管理的优势
- 确保数据一致性:通过定时上报和同步时间戳记录等机制,FastDFS能够确保同一文件在各个存储服务器上的副本是最新的,从而保证了数据的一致性。
- 提高系统可靠性:即使某个存储服务器出现故障或网络中断等情况,FastDFS也能够通过其他存储服务器上的副本提供文件服务,从而提高了系统的可靠性和可用性。
- 优化资源利用:通过合理的同步时间管理,FastDFS能够避免不必要的同步操作和数据传输,从而优化了系统资源的利用。
四、结论
FastDFS的同步时间管理是确保文件同步准确性和及时性的关键机制。通过定时上报、时间戳记录和同步延迟处理等方式,FastDFS能够确保同一文件在各个存储服务器上的副本是最新的,从而提高了系统的可靠性和可用性。同时,合理的同步时间管理还能够优化系统资源的利用,提高整个文件系统的性能。
FastDFS集成nginx
FastDFS集成Nginx是提升文件访问效率的一种常见做法,尤其适用于需要高效处理静态文件(如图片、视频等)的场景。以下是对FastDFS集成Nginx的详细解析:
一、为什么需要集成Nginx
- 性能优势:Nginx是一个高性能的HTTP和反向代理服务器,具有出色的并发处理能力和低内存消耗。通过Nginx来访问FastDFS,可以显著提高文件访问的速度和稳定性。
- 简化访问方式:Nginx可以提供统一的文件访问接口,使得客户端可以通过HTTP协议直接访问FastDFS存储的文件,而无需了解FastDFS的内部架构和协议细节。
- 负载均衡:Nginx支持多种负载均衡算法,可以根据服务器的负载情况自动将请求分发到不同的FastDFS存储节点上,从而实现负载均衡,提高系统的整体性能。
二、集成步骤
1. 环境准备
- 确保Linux系统已安装gcc、make等编译工具。
- 安装Nginx所需的依赖库,如pcre、zlib等。
- 安装FastDFS及其依赖库libfastcommon。
2. 安装Nginx和FastDFS-Nginx-Module
- 下载Nginx源码包和FastDFS-Nginx-Module源码包。
- 解压Nginx源码包,并进入解压后的目录。
- 使用
./configure命令配置Nginx,并添加FastDFS-Nginx-Module模块。例如:

- 编译并安装Nginx。
3. 配置Nginx
- 在Nginx的配置文件中(通常是
nginx.conf),添加对FastDFS的支持。这通常涉及到在http块中添加一个server块,用于处理对FastDFS文件的请求。 - 配置
mod_fastdfs.conf文件,该文件是FastDFS-Nginx-Module的配置文件,用于指定FastDFS的tracker服务器地址、文件存储路径等信息。
4. 重启Nginx
- 修改配置后,需要重启Nginx以使配置生效。
5. 测试集成效果
- 通过浏览器或命令行工具访问Nginx配置的FastDFS文件访问URL,检查文件是否能够正常下载或显示。
三、注意事项
- 确保FastDFS的tracker和storage服务已经正常运行。
- 在配置Nginx和FastDFS-Nginx-Module时,注意路径和参数的正确性。
- 如果遇到编译或配置错误,请仔细查看错误日志,并根据错误提示进行相应的调整。
四、参考资料
- Nginx和FastDFS的整合:详细介绍了Nginx和FastDFS的整合过程,包括环境准备、安装步骤、配置方法等。
- FastDFS与Nginx集成:提供了FastDFS与Nginx集成的详细步骤和注意事项。
- FastDFS+Nginx,轻轻松松搭建一个本地文件服务器:介绍了在本地搭建FastDFS文件服务器,并通过Nginx实现远程访问的方法。
通过上述步骤和注意事项,您可以将FastDFS与Nginx成功集成,从而实现对文件的高效访问和管理。
FastDFS部署
FastDFS 是一个开源的高性能分布式文件系统,主要用于文件存储、文件同步和文件访问(包括文件上传和文件下载),特别适合中大型网站以文件为载体的在线服务,特别是存储 4KB ~ 500MB 之间的小文件,如图片、文档、音频、视频等。以下是一个详细的 FastDFS 部署步骤,以 CentOS Linux 系统为例:
一、环境准备
-
检查系统环境
- 确保 Linux 系统已安装 gcc、make 等编译工具。
- 检查是否已安装 libevent 库,它是 FastDFS 依赖的网络通信库。
-
安装依赖库

-
下载并解压软件包
- 从 GitHub 或其他可靠源下载 FastDFS、libfastcommon、Nginx 以及 FastDFS-Nginx-Module 的软件包。
- 使用 tar 命令解压这些软件包到指定目录。
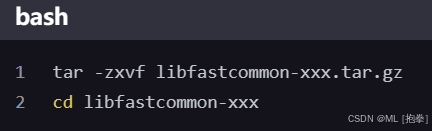
二、安装 libfastcommon
1.解压并进入 libfastcommon 目录
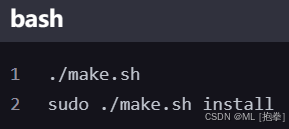
2.编译并安装
-
设置环境变量(如果需要)
- 可以通过设置环境变量
LD_LIBRARY_PATH或创建软链接来确保系统能找到 libfastcommon 的库文件。
- 可以通过设置环境变量
三、安装 FastDFS
解压并进入 FastDFS 目录
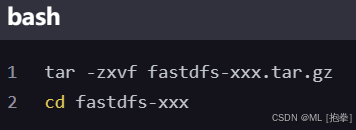
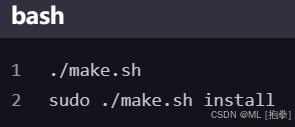
编译并安装
复制配置文件

四、配置 Tracker Server
编辑 tracker 配置文件
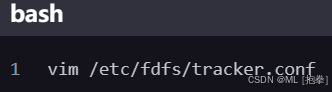
- 修改
base_path为一个合适的目录,用于存放 tracker 的数据和日志。
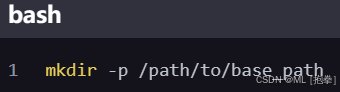
创建目录
启动 Tracker Server

或
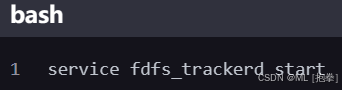
设置开机自启动
五、配置 Storage Server
编辑 storage 配置文件
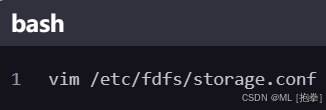
- 修改
base_path和store_path0为存储文件的目录。 - 配置
tracker_server为 tracker 服务器的 IP 地址和端口。
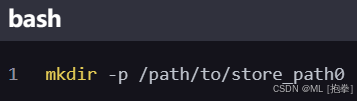
创建目录
启动 Storage Server

或
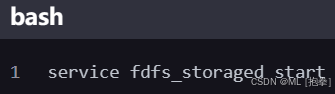
设置开机自启动
六、集成 Nginx
- 安装 Nginx
- 可以使用 yum 或从源代码安装 Nginx。
- 配置 Nginx 以支持 FastDFS
- 编译 Nginx 时需要添加 FastDFS-Nginx-Module。
- 配置 Nginx 的
nginx.conf或fastdfs.conf(如果单独配置的话),以代理 FastDFS 的文件访问请求。
- 重启 Nginx
七、测试
- 编写一个测试脚本或使用 FastDFS 提供的客户端工具来上传和下载文件,以验证 FastDFS 和 Nginx 的集成是否成功。
八、注意事项
- 确保防火墙和网络设置允许 FastDFS 和 Nginx 的相关端口。
- 监控 FastDFS 和 Nginx 的日志,以便及时发现并解决问题。
- 根据实际需求调整 FastDFS 和 Nginx 的配置参数。

















 7069
7069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









