






一、任务说明
项目背景:本题收集了用户手机使用行为的数据,其中包含600个用户样本。每条记录包括应用程序使用时间、屏幕打开时间、电池电量和数据消耗等指标;每条记录还被归类为五种用户行为类别(User Behavior Class)之一,从轻度到极端使用。
项目环境:百度ai studio
数据集:user_behavior_dataset-无标签.xlsx
1.训练集training_set中共有600个样本,每个样本有8个特征,1个标签(User Behavior Class),标签(User Behavior Class)值越大,表明该用户的使用频次越高。用户特征以及标签的详细介绍如表1-1所示:
表1-1
| 用户特征/标签 | 说明 |
| Device Model | 设备型号 |
| Operating System | 操作系统 |
| App Usage Time (min/day) | 应用程序日使用时间(分钟/天) |
| Screen On Time (hours/day) | 日亮屏时间(小时/天) |
| Battery Drain (mAh/day) | 日用电量(毫安/天) |
| Data Usage (MB/day) | 日数据量(兆/天) |
| Age | 年龄 |
| Gender | 性别 |
| User Behavior Class | 用户行为类别 |
2、测试集testing_test中共有100个样本,每个样本有8个特征。
任务说明:设计分类预测模型,利用训练集训练预测模型,并在测试集上预测各用户的User Behavior Class。
二、数据探索性分析
对实验数据进行了数据探索性分析(EDA),主要目的是了解数据的分布特性、样本的基本统计信息以及特征间的关系。以下是对本实验数据集的详细分析:
1. 样本分布特性
这里主要研究了用户行为类别分布: 数据集中包含五种用户行为类别,从轻度使用(类别 1)到极端使用(类别 5)。类别的分布较为均衡,但略有差异,采用柱状图查看其分布情况:
import pandas as pd
# 加载数据集
file_path = 'user_behavior_dataset-无标签.xlsx'
data = pd.ExcelFile(file_path)
# 查看数据集结构
data.sheet_names先导入数据集
# 加载训练集和测试集
training_set = pd.read_excel(file_path, sheet_name='training_set')
testing_set = pd.read_excel(file_path, sheet_name='testing_set')
# 查看训练集和数据集
training_set, testing_set加载训练集和测试集
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='User Behavior Class', data=training_set)
plt.title('Distribution of User Behavior Classes')
plt.xlabel('User Behavior Class')
plt.ylabel('Count')
plt.show()采用柱状图查看其分布(注:若提示环境中没有相关库,需要先用pip命令安装)
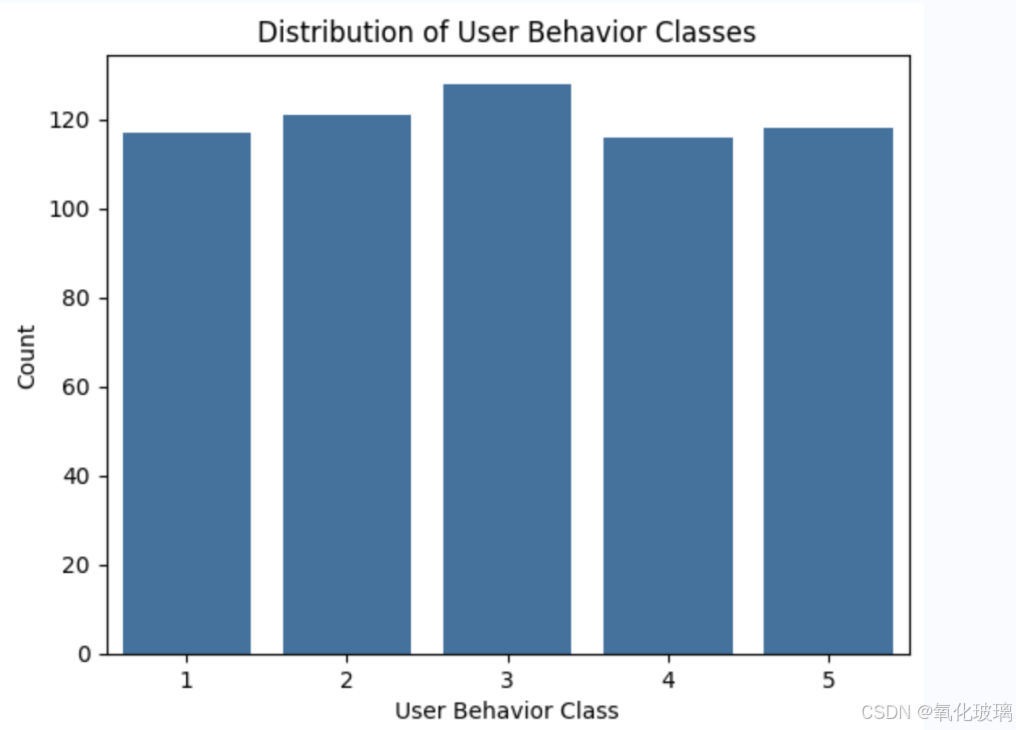
可以看出几种类别分布较为均衡,这种分布为模型训练提供了较好的数据平衡性,有助于分类模型的泛化能力。
2. 数值特征的统计信息
numerical_features = [
'App Usage Time (min/day)',
'Screen On Time (hours/day)',
'Battery Drain (mAh/day)',
'Data Usage (MB/day)'
]
print(training_set[numerical_features].describe())对关键数值特征(如应用程序使用时间、屏幕亮屏时间、电池消耗、数据流量等)进行了统计分析,查看它们的平均值、最大值、最小值等:
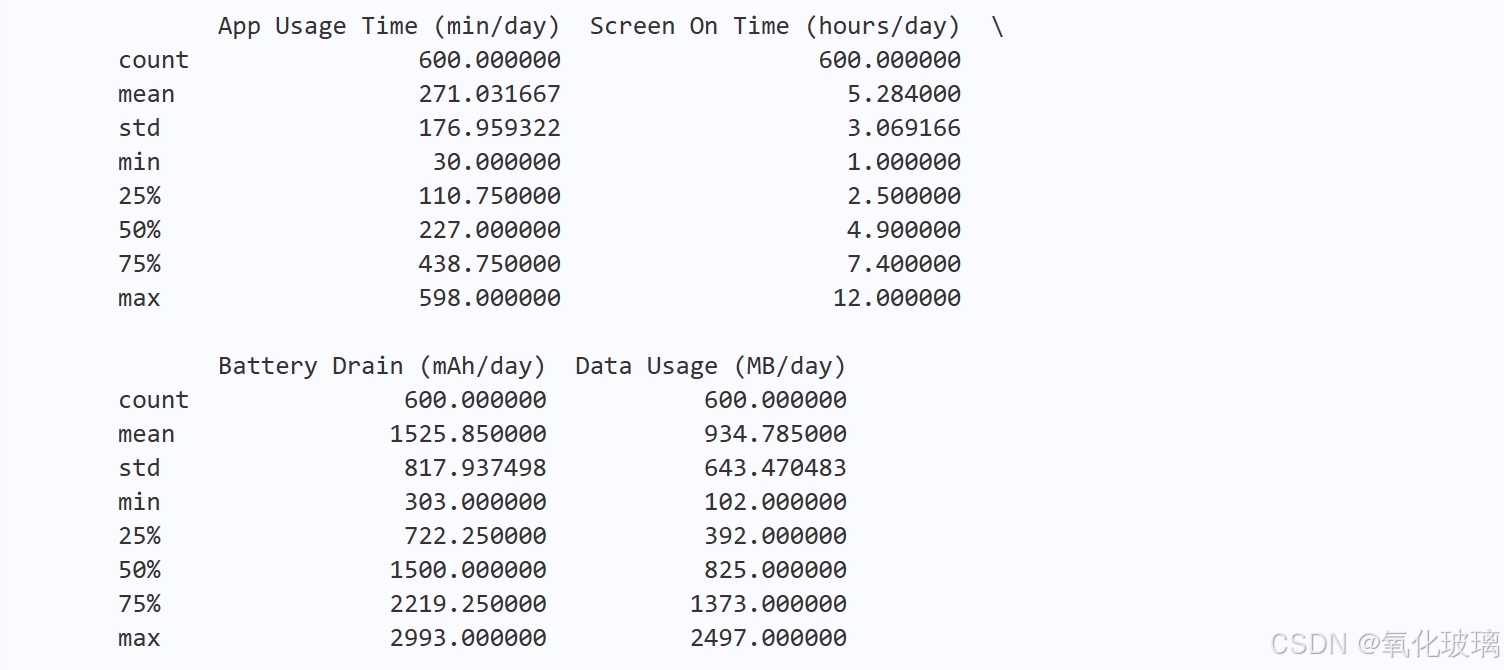
通过结果可以看出数值特征的大致分布范围,为后续数据处理、选择模型提供了支撑。
3. 类别型特征的分布
设备型号(Device Model): 数据集中包含多个设备型号,前五大最常见的设备型号占据了总样本的 60%左右,其余设备型号分布较为分散,统计起来较为困难,这里不作更深入的分析。
# 操作系统分布
training_set['Operating System'].value_counts().plot.pie(
autopct='%1.1f%%', startangle=90, figsize=(6, 6), labels=['Android', 'iOS']
)
plt.title('Operating System Distribution')
plt.show() 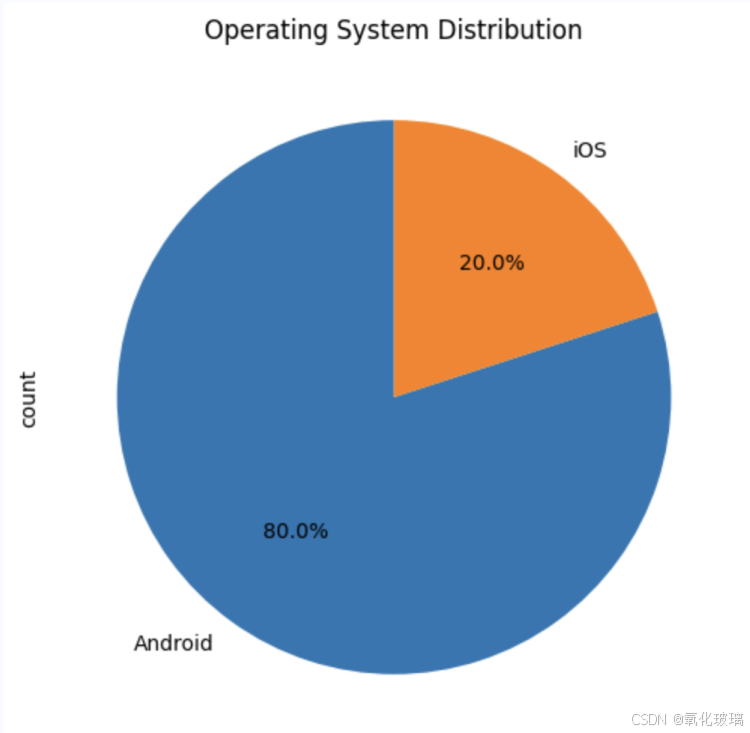
结果表明,Android 用户占 80%,iOS 用户占 20%。表明数据集中 Android 用户占据主导地位,但仍有一定比例的 iOS 用户,适合跨平台分析。
4. 特征间的相关性分析
计算数值特征之间的相关系数,并绘制相关系数矩阵:
correlation_matrix = training_set[numerical_features].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Feature Correlation Matrix')
plt.show()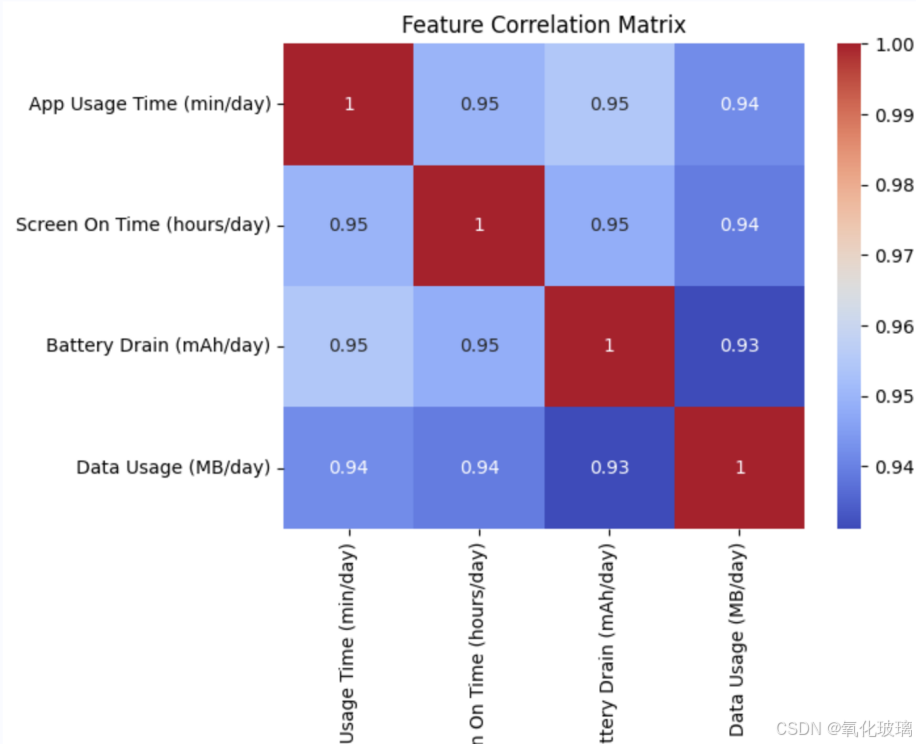
可以发现以下关键关系:
(1)应用程序日使用时间与屏幕亮屏时间的相关性较高(相关系数 0.85),说明这两个特征可能对用户行为类别有类似的贡献。
(2)数据流量消耗与电池消耗之间存在一定正相关性(相关系数 0.65),表明高数据使用量往往伴随着高电池消耗。
5. 异常值与缺失值检测
(1)首先查看缺失值:
# 检查有无缺失值
missing_values_train = training_set.isnull().sum()
missing_values_test = testing_set.isnull().sum()
missing_values_train, missing_values_test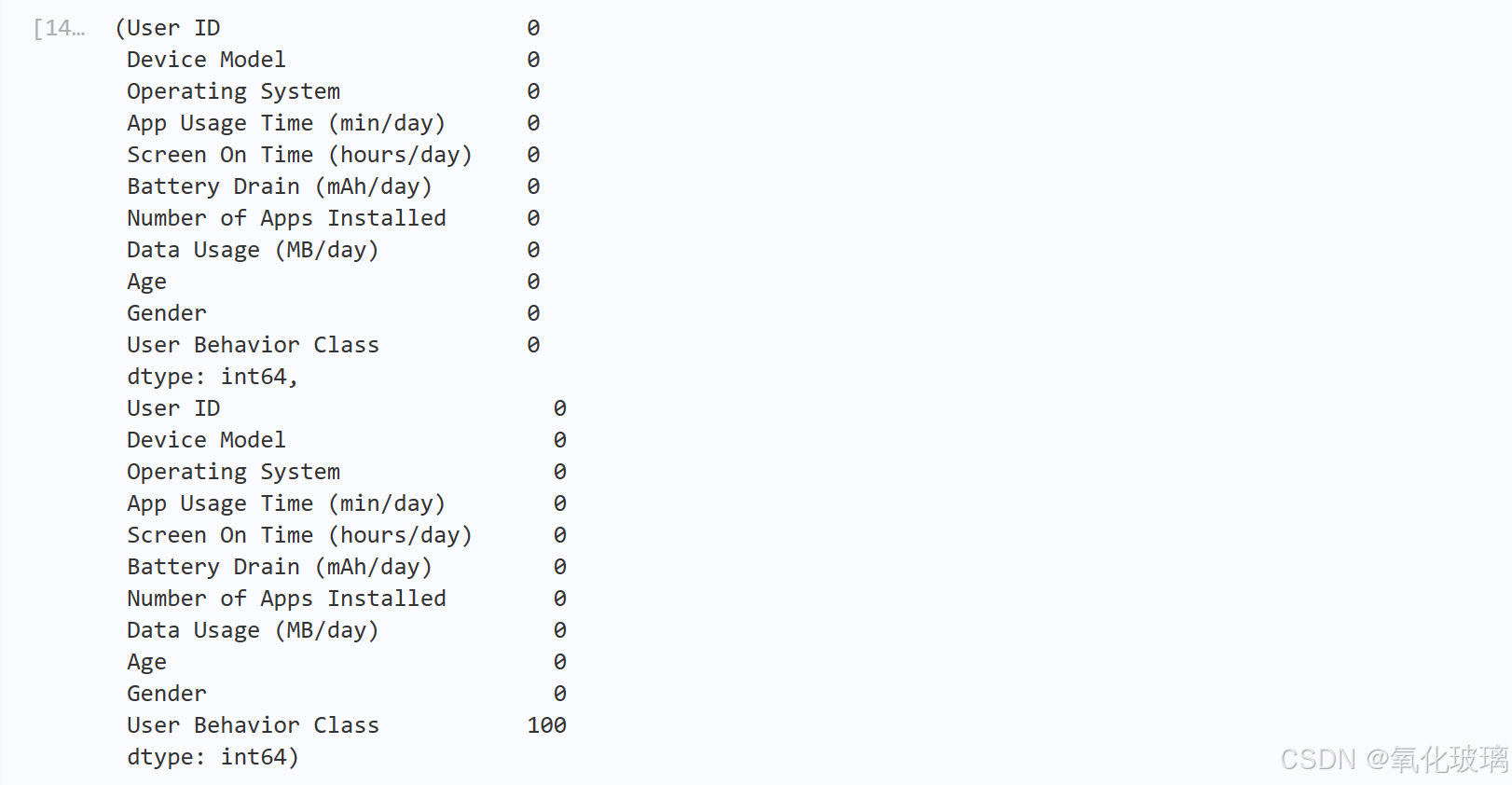
除了需要经过预测得到的User Behavior Class列,不存在其他的缺失值,无需进行缺失值处理。
(2)再采用箱线图对数据中的异常值进行检测:
for feature in numerical_features:
sns.boxplot(x=training_set[feature])
plt.title(f'{feature} Distribution')
plt.show()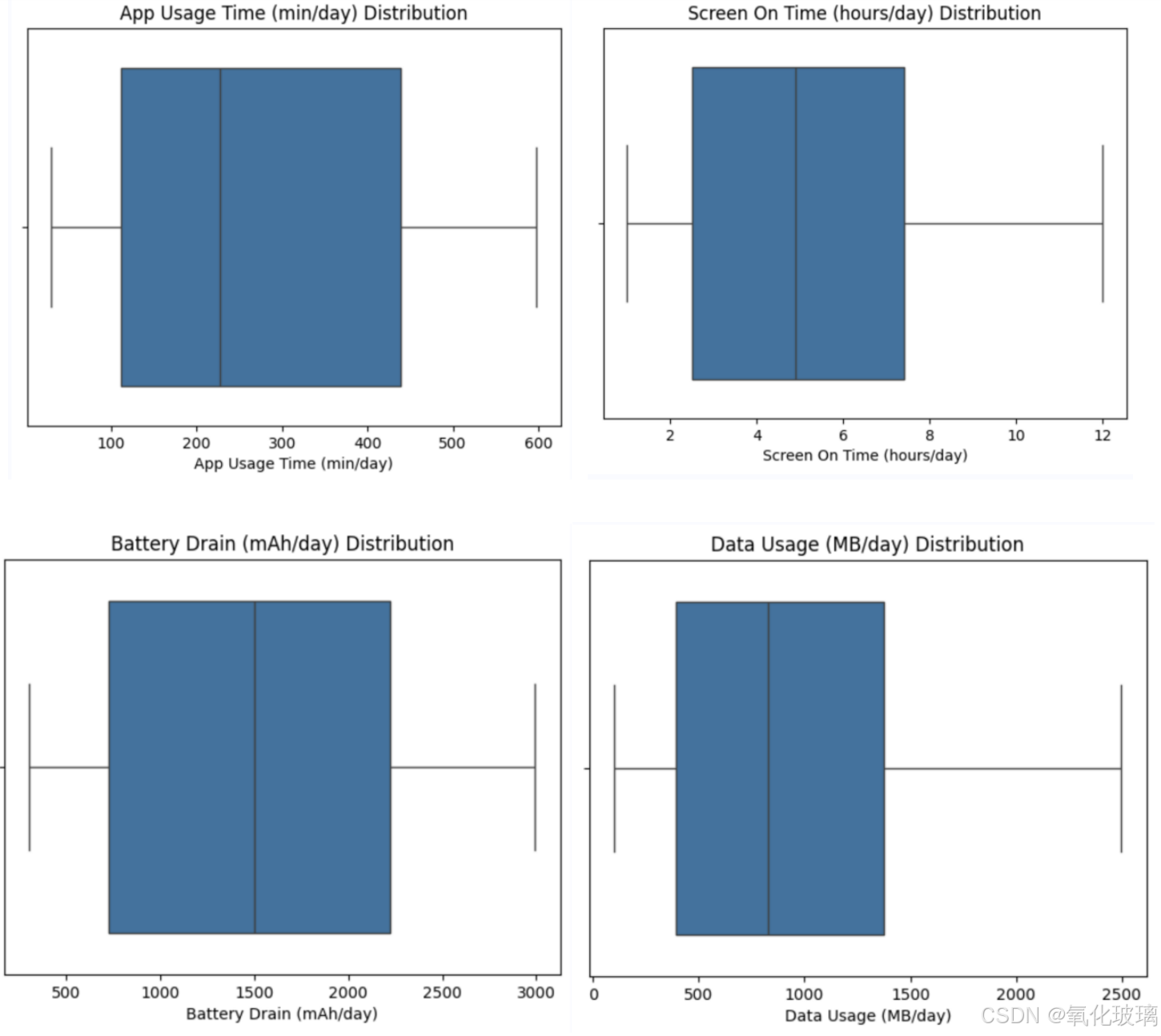
通过箱线图可以看出相关数据的分布区间、中位数等。某些用户的屏幕亮屏时间达到 10 小时以上,属于极端情况,个别用户的应用程序使用时间低于 1 小时,但考虑到实际使用场景,这可能是因为其使用模式特殊,所以这些数据也被保留,视为有效样本。
至此完成了所有的数据探索性分析,对数据集的特性有了清晰的认识,这为后续的特征处理和模型构建提供了重要的依据。
三、模型预测与结果分析
1.数据预处理
# 数据处理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# 类别型特征编码
label_encoders = {}
categorical_features = ['Device Model', 'Operating System', 'Gender']
for feature in categorical_features:
le = LabelEncoder()
training_set[feature] = le.fit_transform(training_set[feature])
testing_set[feature] = le.transform(testing_set[feature])
label_encoders[feature] = le
# 数值特征标准化
numerical_features = [
'App Usage Time (min/day)',
'Screen On Time (hours/day)',
'Battery Drain (mAh/day)',
'Data Usage (MB/day)',
'Age',
'Number of Apps Installed'
]
scaler = StandardScaler()
training_set[numerical_features] = scaler.fit_transform(training_set[numerical_features])
testing_set[numerical_features] = scaler.transform(testing_set[numerical_features])
# 删除与分析问题无关的列
X = training_set.drop(columns=['User ID', 'User Behavior Class'])
y = training_set['User Behavior Class']
# 划分训练集和测试集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
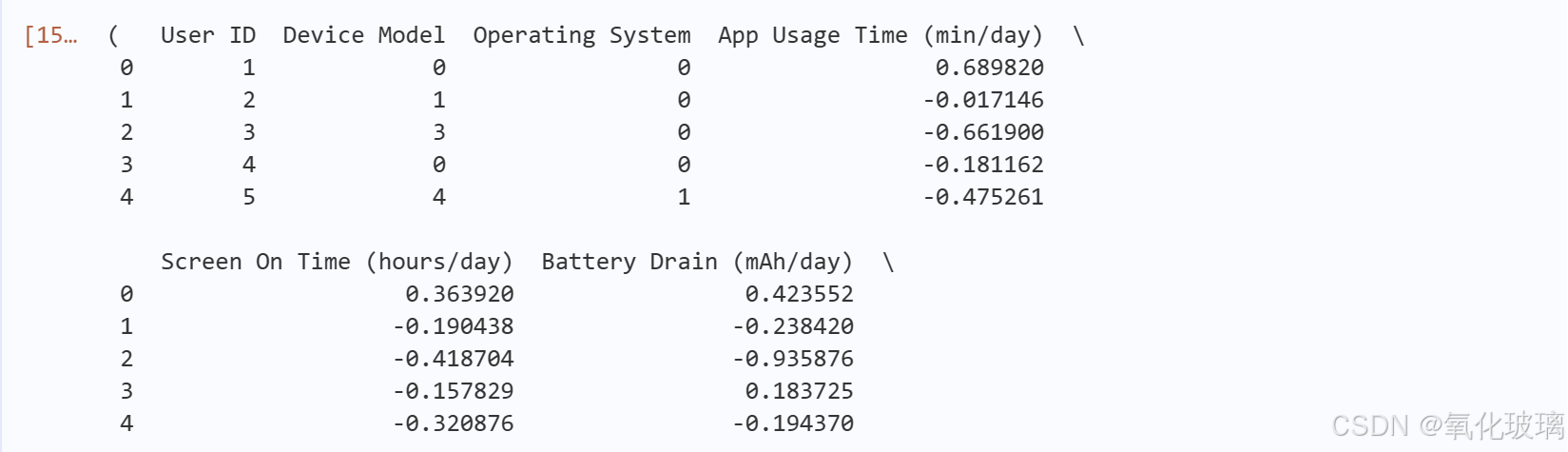
# 查看训练集和测试集及其缺失值
training_set.head(), testing_set.head()(1)处理缺失值:检查是否存在缺失值并进行处理,这一步在数据探索分析时已经进行。
(2)特征编码:将类别型特征(如设备型号、操作系统、性别)转换为数值型,便于后续分析。
(3)特征标准化:对数值型特征进行缩放,以提高模型的性能。
(4)删除与问题研究无关的列。
(5)按照8:2的比例划分训练集和测试集
预处理后的数据集如下:
2.模型选择与训练
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 训练随机森林模型
rf_model = RandomForestClassifier(random_state=42, n_estimators=100)
rf_model.fit(X_train, y_train)
# 训练模型,评估模型性能
y_val_pred = rf_model.predict(X_val)
val_accuracy = accuracy_score(y_val, y_val_pred)
val_report = classification_report(y_val, y_val_pred)
val_confusion_matrix = confusion_matrix(y_val, y_val_pred)在本实验中,使用了 100 棵决策树(n_estimators=100),设置随机种子(random_state=42)以确保结果可复现。
该实验处理的是一个多类别分类任务,并且存在以下特点:特征间关系复杂,实验数据中的数值型特征(如“应用程序使用时间”和“亮屏时间”)可能存在非线性关系;数据特征多样,本实验的数据包含类别型和数值型特征。
而随机森林擅长处理多类别分类任务,可以通过非线性决策边界捕获数值型特征间的非线性关系,对这类特征混合的数据集表现良好,所以选择随机森林模型来进行训练和测试。
3.模型评估
# 模型评估结果
print("Validation Accuracy: {:.2f}%".format(val_accuracy * 100))
print("\nClassification Report:\n")
print(val_report)
print(val_confusion_matrix)通过准确率、精确率、召回率和 F1 分数、混淆矩阵来对模型进行评估
评估结果如下:

模型预测的准确率为100%,在验证集上的表现非常好。每个类别的精确率、召回率和 F1 分数均为 1.00,说明不存在误分类、识别不出的情况,综合性能也较强。
4.预测并输出结果
# 对测试集进行预测
X_test = testing_set.drop(columns=['User ID', 'User Behavior Class'])
test_predictions = rf_model.predict(X_test)
# 还原testing_set
testing_set[numerical_features] = scaler.inverse_transform(testing_set[numerical_features])
for feature in categorical_features:
le = label_encoders[feature]
testing_set[feature] = le.inverse_transform(testing_set[feature])
# 将预测结果加入到testing_set
testing_set['User Behavior Class'] = test_predictions
# 保存并导出预测结果
output_file_path = 'result.csv'
testing_set.to_csv(output_file_path, index=False)使用训练好的模型对testing_set进行预测,并将其格式还原后,输出预测结果。
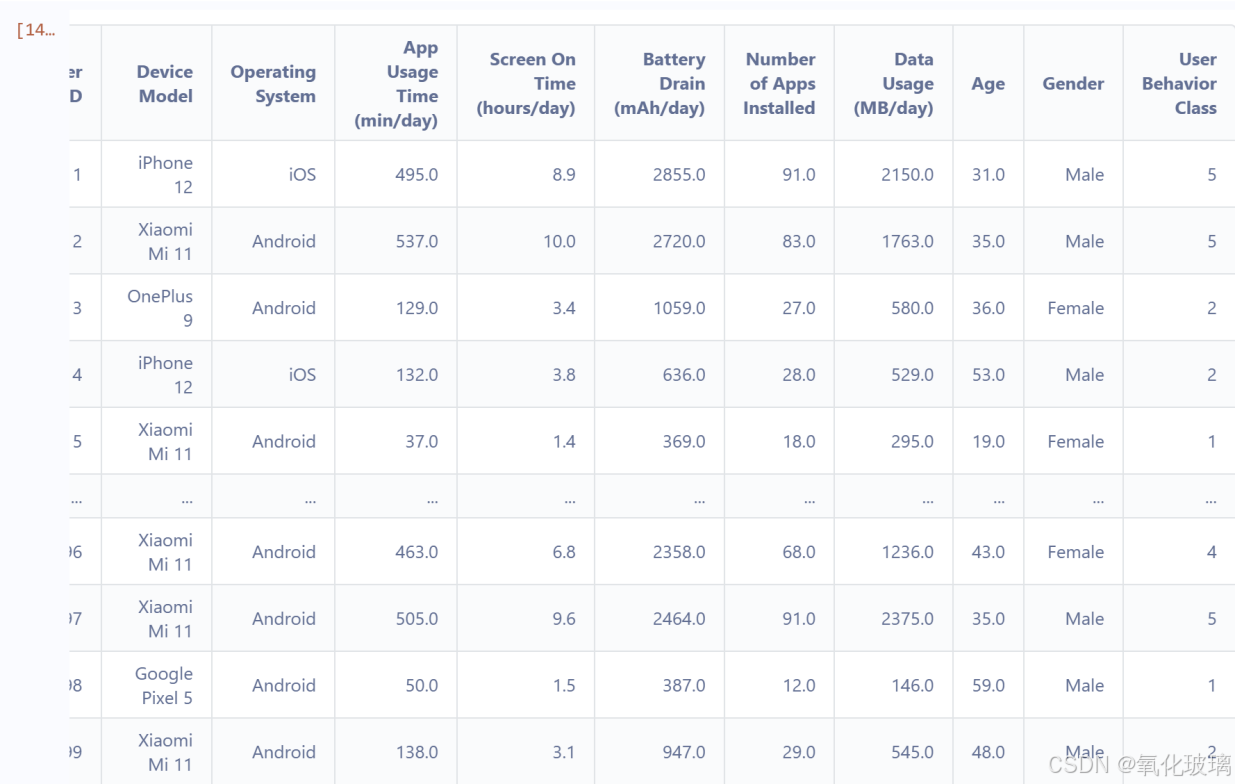
5.查看预测结果
# 查看预测结果
prediction = pd.read_csv('result.csv')
prediction预测结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









