



DeepSeek爆火引发AI竞争格局变革,降低AI应用门槛,推动金融、医疗、教育等行业应用爆发。企业需通过GPU算力优化、场景化小模型训练、引入私域知识、智能体协同框架等技术叠加来抓住机遇。MoE架构可能成为主流,软硬协同能力与安全合规是企业面临的主要挑战。中小企业可通过模型蒸馏等技术低成本创新,实现AI应用从头部企业垄断向长尾场景渗透。
本文整理自 InfoQ 策划的 DeepSeek 系列直播第九期节目。在直播中,极客邦科技创始人 &CEO 霍太稳对话神州数码集团首席 AI 专家谢国斌,深入探讨了 DeepSeek 爆火背后,AI 竞争格局将发生哪些变化,以及在新的格局下,AI 企业会面临哪些新的机会和挑战,企业又该如何抓住这些机遇。
谢国斌表示,随着 AI 接入门槛和成本的降低,金融、医疗、教育和汽车等行业的应用可能会率先爆发。除此之外,制造业、办公行业等也有很大的发展空间。
但对于 B 端企业而言,除了 DeepSeek 这样的开源大模型外,还需要多方面的技术进行叠加,从多个维度考虑技术的应用,比如:在部署过程中尽可能利用 GPU 算力优化,进行进行场景化、专业的小模型训练,引入私域化的知识,提供一套智能体协同框架等等。
DeepSeek 技术创新带来的影响
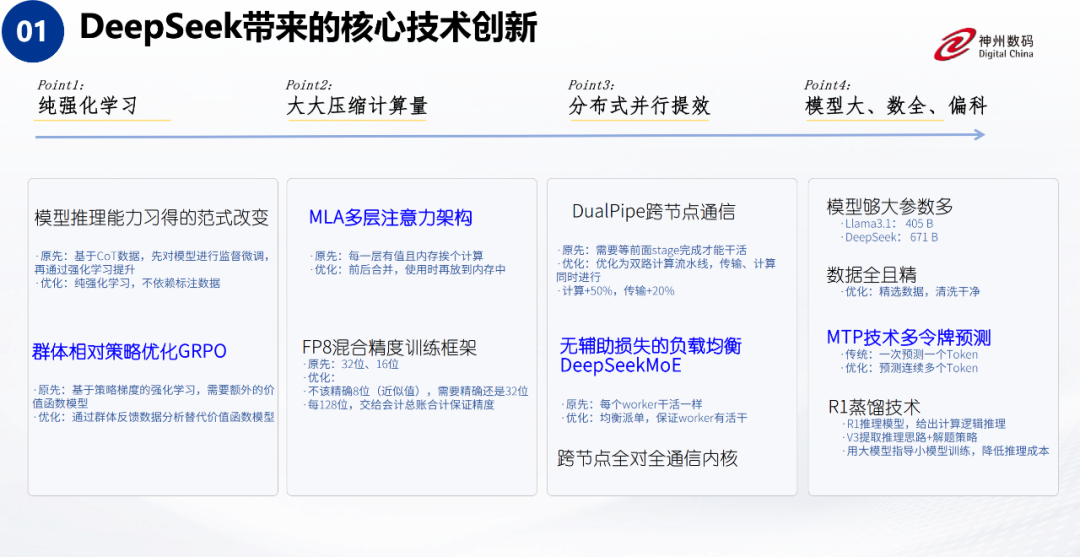
在原创核心技术方面,我们特别关注以下几个方面。
-
群体相对策略优化(GRPO):在传统的强化学习中,评价一个模型表现好坏的函数通常需要人工设定。而 DeepSeek 采用了一种创新方法,即引入多个“评委”进行投票,取平均值作为评价标准。这种方法省略了人工设定评价函数的流程,简化了算法,是强化学习领域的一个关键创新。
-
多头潜在注意力(MLA):该架构通过降维操作大幅压缩了计算量,显著降低了模型的训练和推理成本。
-
混合专家模型(MoE):这种架构通过集成多个专家网络,极大地扩展了模型的参数规模,同时在推理侧显著加速了推理过程。这种结构类似于“有通识专家、有专识专家,相互配合、各司其职”,与传统方法相比,效果显著提升。
-
多令牌预测(MTP):这一技术已经在很多技术专家的分享和网络博客中被广泛讨论,因此我们这里也不再详细介绍。
在企业应用落地方面,DeepSeek 的价值主要体现在以下四个方面,这些价值对全球 AI 格局产生了深远影响。
-
降低推理成本:虽然训练成本已经较低,但 DeepSeek 的最大优势在于推理成本。通过 MLA 等技术,推理成本降至之前的约 3%,降低了 97%。这一优势对中小企业尤其友好,能够加速 AI 大模型在企业应用场景中的落地。
-
模型思考,深度如人:R1 模型是一个深度思考模型,不仅提供问题的答案,还展示了推理过程,类似于数学题的解题步骤。这种推理模型的可解释性更强,更适合赋能更多企业应用场景。用户可以通过模型的推理过程,清晰地看到模型是如何得出答案的。
-
小模型,大作为:除了完整的全参模型,DeepSeek 的 R1 模型还蒸馏出了 7 个不同尺寸的小模型。这些小模型数据质量高,蒸馏效果优于同类尺寸模型。在企业落地时,可以选择这些小模型,进一步降低推理成本,同时保持良好的效果。
-
开源、全栈自主可控:DeepSeek 将模型开源,为全球同行和企业提供了一个自主研发和迭代的基础。目前,国内众多企业,包括芯片企业和云厂商,已经开始接入 DeepSeek 原生态模型。这不仅推动了国产化进程,也为建立安全可控的 AI 生态提供了重要的参考和标杆。
AI 市场格局变化,
机遇挑战并存
在全球市场,包括国内的重点领域,AI 市场格局发生了诸多变化,对企业与个人而言,机遇与挑战并存。以神州数码为例,我们是一家专注于 ToB 的技术服务公司,从客户市场需求的角度出发,探讨客户需要什么样的 AI 技术企业为其提供服务。除了 DeepSeek 这样的开源大模型外,企业客户还需要以下几方面的技术进行叠加。
- 企业需要将 DeepSeek 大模型部署起来,并在部署过程中尽量利用 GPU 算力优化,以节省 GPU 算力成本,无论是训练成本还是推理成本。
- 基于 DeepSeek 开源模型,企业可以进行场景化、专业的小模型后训练,例如 7B、14B 等,以降低算力门槛。在训练过程中,数据源就像炒菜的原材料一样重要。只有通过专业的模型训练,才能保证模型的质量和效果。
- 企业还需要引入私域化的知识,例如企业内部的文档和专家经验等。这是因为通用的大模型无法满足企业的个性化需求,就像厨师需要根据客人的口味进行私人化的调制一样,企业也需要将内部的知识和经验融入模型中,通过知识管理实现这一点。
- 企业需要提供一套智能体协同框架。以炒菜为例,整个过程可以分为多个步骤,如放油、炒佐料、放菜品、勾芡等。在企业中,智能体可以将这些步骤串联起来,让每一步都发挥专业功能。在 AI 技术中,这可能涉及引入外部工具,此外,还可以结合不同的大模型和小模型、专业模型和通用模型,以提升智能体的效果。
当企业的应用越来越多时,就需要一个大模型平台来承载这四方面的功能,以便在企业中有上百个、上千个应用和智能体时能够正常运转。神州问学平台正是按照这样的逻辑进行研发和服务于企业的。在实现过程中,客户不仅需要技术手段,还希望在业务中实现高准确性和高并发能力。例如,对话机器人在回答客户问题时,需要较高的准确性,并且能够同时支持上百个、上千个 C 端客户的提问。同时,项目还需要满足经济预算要求,例如对话机器人的预算可能是 50 万或 100 万。最终目标是让大模型在企业应用场景中落地,帮助企业实现增收降本和提升办公效率。

客户需求和市场需求的变化正在深刻地引导整个 AI 市场格局的演变,尤其是 ToB(企业服务)领域。虽然 ToC 领域也会受到影响,但这里我们重点关注的是 ToB 市场格局的变化。DeepSeek 的出现,凭借其开源、低成本等特性,正在引发 AI 市场格局的重大变革,并推动商业模式的重塑。
市场格局变化
生态格式变化: 众多企业围绕 DeepSeek 建立生态,上下游企业纷纷进行 适配。这可能导致市场格局转向更加开放和多元化的竞争格局。更多的企业将有机会参与到 AI 技术的研发和应用中,推动 AI 技术的普及和创新。
垂直领域分化: 医疗、法律等专业场景将出现基于 DeepSeek 的细分模型,打破通用基础模型的统治。
产业链价值转移: 上游算力需求向推理侧倾斜,下游应用开发门槛降低将催生更多垂直领域 SaaS 服务商。硬件厂商需转向算力部署和能效优化,软件企业则需强化工程平台和应用能力。
商业模式重塑
开源重要性上升: 从 DeepSeek R1 的成功我们可能会看到更多的公司转向开源或部分开源模型,以保持竞争力。这种变化将促使 AI 市场形成更加良性的竞争环境,消费者也将获得更具性价比的 AI 服务。
**催生新的商业模式:**DeepSeek R1 的成功及开源,改变了市场竞争的格局和态势,将来也会催生新的商业模式。比如围绕开源生态、高效推理、模型蒸馏等模型架构创新、 核心关键技术展开新的商业范式。
**企业流程重塑与再造:**DeepSeek R1 的成功及开源,改变了市场竞争的格局和态势,将来也会催生新的商业模式。比如围绕开源生态、高效推理、模型蒸馏等模型架构创新、 核心关键技术展开新的商业范式。
对于企业而言,AI 技术的发展既带来了机遇,也带来了挑战,两者是并存的。
新机遇
为技术企业带来了新的机会
- DeepSeek 生态的建立为技术企业带来了新的机会。例如,中小企业可以通过低成本接入 DeepSeek 生态,实现低成本创新。
- DeepSeek 通过模型蒸馏技术赋能中小企业,降低 AI 开发门槛, 推动 AI 应用从头部企业垄断转向长尾场景渗透,如金融、医疗、 教育等领域。
端侧应用爆发
DeepSeek 轻量版适配手机、电脑 AIPC、IoT 设备,催生本地 化 AI 应用(如离线语音助手)。
数据标注工业化
专业标注公司可能会向推理链标注等高阶服务转型。
新挑战
技术企业将面临更多样化的挑战:例如,如何在保证模型性能的同时进一步降低训练成本和推理延迟等。企业需要不断提升自身的技术实力和创新能力,以应对这些挑战。
软硬协同能力:技术企业需建立算法 - 硬件协同优化能力(如 DeepSeek 的 GRPO、MLA、MoE 与架构创新结合)。
安全合规风险:垂直开源模型应用可能面临一定的安全风险,需内嵌审计模块。
AI 技术企业应对的策略和思路
策略 1:提供 DeepSeek 全套解决方案 – 模型部署、训练和应用适配
以我们公司过往的经验为例,首先,作为一家专注于 AI 技术落地应用的公司,神州数码的第一个策略是为行业提供完整的 DeepSeek 解决方案。这包括模型的部署,无论是满血版还是各种尺寸的蒸馏版,以及模型训练和算力管理。例如,基于千问 32B 这种主流模型,我们现有的平台产品不仅能支持模型训练,还能实现多元异构算力的高效利用和管理,从而提升算力的使用效率。同时,我们的平台还集成了智能体和知识管理模块,以支持企业场景的应用和适配。我们认为,这个过程不是一个单向的,而是一个不断迭代的循环。通过模型的部署、训练和应用适配,我们不断循环优化,持续抽取企业行业中的最佳实践案例,从而为客户提供更优质的解决方案。

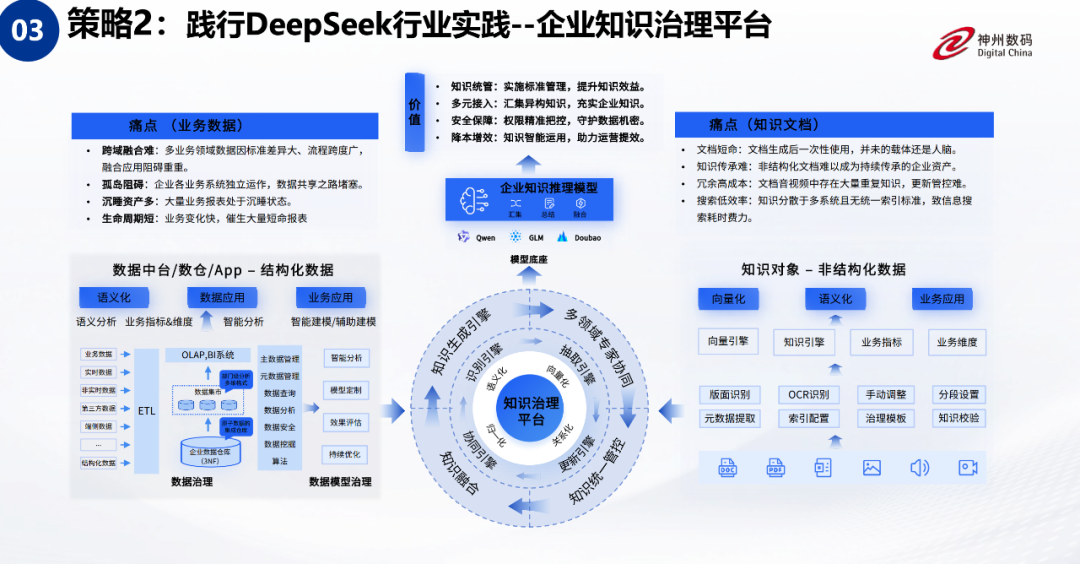
策略 2:践行 DeepSeek 行业实践 – 企业知识治理平台
我们的第二个策略是践行 DeepSeek 在行业中的实验应用,特别是在企业的知识治理平台上。我们会将企业内部的结构化数据中台和数据仓库中的结构化数据,与中台里的知识对象以及非结构化数据进行融合。这里所说的非结构化数据,是指大家常见的 PDF 文档、Word 文档、PPT 文档,甚至是图片和语音等。这些数据都可以被纳入我们的知识治理平台进行利用。当然,在使用过程中,我们会充分考虑数据的脱敏和安全,确保这些数据仅在企业内部使用,不会对外泄露。基于我们问学的知识治理平台,我们将企业的知识类化到模型中,或者作为外部工具进行调用。
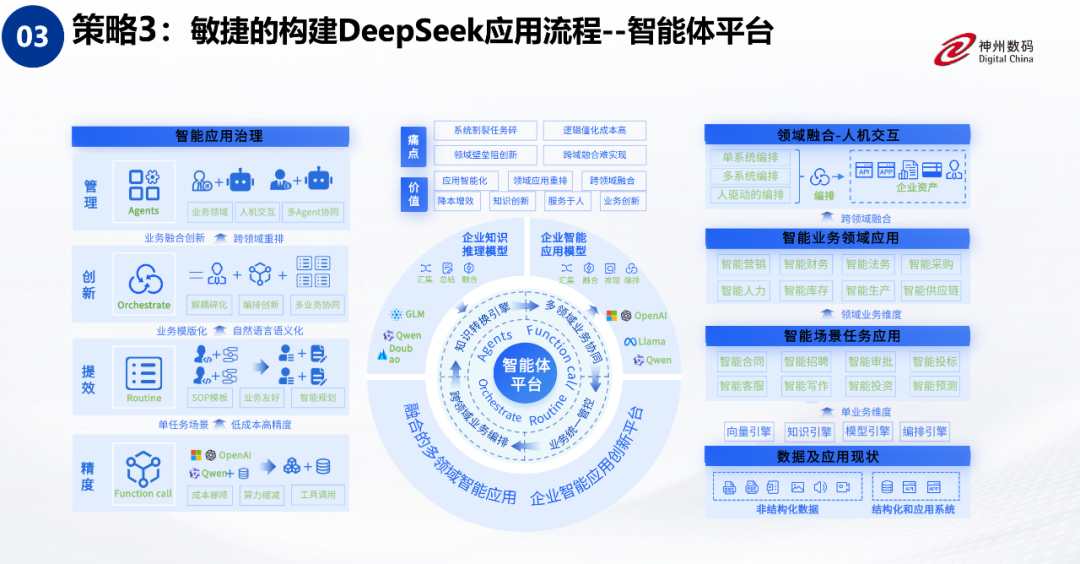
策略 3:敏捷的构建 DeepSeek 应用流程 – 智能体平台
我们的第三个策略是提供一个敏捷的应用流程平台,类似于厨师炒菜的步骤规划。我们将其称为智能体平台,它的作用是将一个复杂的应用分解为多个步骤。这就好比人脑的规划过程——比如从北京到上海出差,我们会先规划订机票的时间、起飞时间,以及当地的酒店和行程安排。规划完成后,在出差过程中会用到各种工具,比如订机票和酒店,这些工具在我们的平台上被称为“功能调用”(Function Call)。在此基础上,我们在规划过程中设计了执行流程,通过这些流程提高效率并创新企业的业务流程。最后,我们利用低代码工具将这些流程串联起来,从而轻松构建智能体,赋能企业的应用。
神州数码的未来愿景 – 助力企业 AI for Process
神州数码的未来愿景是通过 AI 助力企业内部流程的重塑与再造,提升效率,并为此提供相应的工具和服务。我们认为企业流程主要体现在三个方面:首先是商业模式,即企业如何创造、传递和获取商业价值;其次是管理方法,涉及企业内部运营资源的决策、绩效管理等基本实践;最后是技术的领先性,通过技术架构(如大模型架构、AI 架构和中台架构)与商业模式和管理方法的融合,提升企业的运行效率、降低成本并优化资源配置。
神州数码提出的“AI for Process”概念,正是商业模式、管理方法和技术架构三者的融合点。我们倡导的企业落地方法论是“大小模型通专融合”,以促进企业 AI 在流程中的应用。具体而言,横向的基础模型,如 DeepSeek V3 以及其他商业或开源模型,通过不断迭代,逐渐从狭义走向广义,最终迈向通用人工智能。这些模型就像通识专家,能够解答各种问题,其通用能力会越来越强。而纵向的专业能力则是通过小模型 (专识专家) 结合场景数据进行微调,例如 7B、14B 模型,它们可能针对金融、招聘、财务或风险管控等具体场景,逐步达到甚至超越专业人才的水平。
当横向的通用能力和纵向的专业能力经过长期发展后,会形成一个兼具通用性和专业性的区域。这种大模型的通用能力与小模型的专业能力相结合,将有力推动企业 AI 的落地应用。在这个过程中,需要运用智能体的决策能力、规划能力、判断能力、反思能力和工具调用能力等,以决定何时使用大模型、何时使用小模型。这些能力将不断推动行业企业及业务场景的落地,逐步实现从商业模式到管理方法再到技术架构的闭环,最终助力企业实现 AI for Process 的目标。
2025年伊始,AI技术浪潮汹涌,正在深刻重塑程序员的职业轨迹:
阿里云宣布核心业务全线接入Agent架构;
字节跳动后端岗位中,30%明确要求具备大模型开发能力;
腾讯、京东、百度等技术岗位开放招聘,约80%与AI紧密相关;
……
大模型正推动技术开发模式全面升级,传统的CRUD开发方式,逐渐被AI原生应用所替代!
眼下,已有超60%的企业加速推进AI应用落地,然而市场上能真正交付项目的大模型应用开发工程师,却极为短缺!实现AI应用落地,远不止写几个提示词、调用几个接口那么简单。企业真正需要的,是能将业务需求转化为实际AI应用的工程师!这些核心能力不可或缺:
✅RAG(检索增强生成):为模型注入外部知识库,从根本上提升答案的准确性与可靠性,打造可靠、可信的“AI大脑”。
✅Agent(智能体): 赋能AI自主规划与执行,通过工具调用与环境交互,完成多步推理,胜任智能客服等复杂任务。
✅微调:如同对通用模型进行“专业岗前培训”,让它成为你特定业务领域的专家。
大模型未来如何发展?普通人如何抓住AI大模型的风口?
随着AI技术飞速发展,大模型的应用已从理论走向大规模落地,渗透到社会经济的方方面面。
- 技术能力上:其强大的数据处理与模式识别能力,正在重塑自然语言处理、计算机视觉等领域。
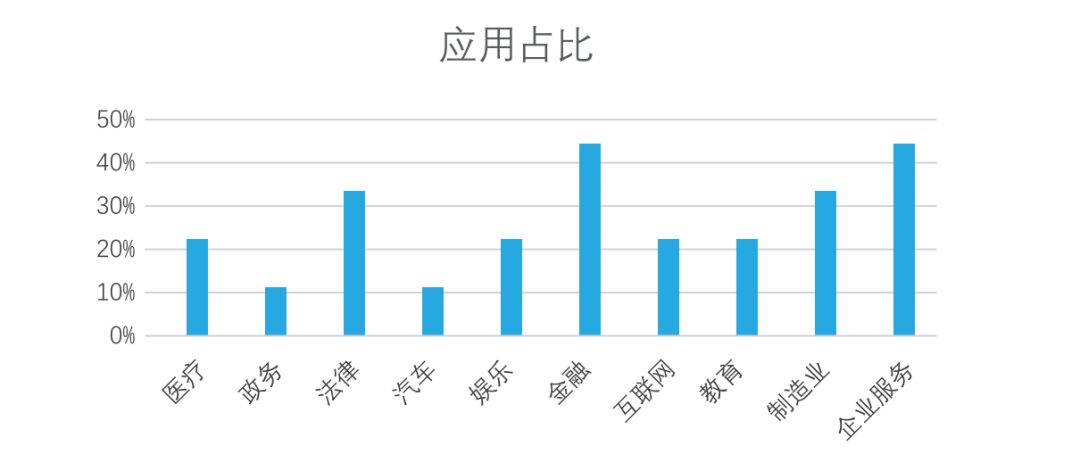
- 行业应用上:开源人工智能大模型已走出实验室,广泛落地于医疗、金融、制造等众多行业。尤其在金融、企业服务、制造和法律领域,应用占比已超过30%,正在创造实实在在的价值。
未来大模型行业竞争格局以及市场规模分析预测:
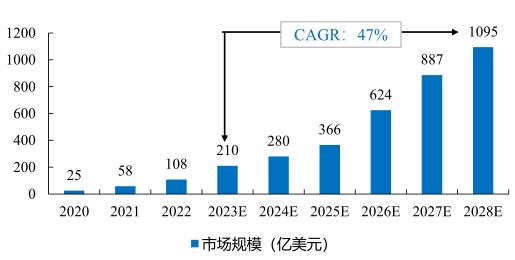
掌握AI能力的程序员,其薪资水位已与传统开发拉开显著差距。当大厂开始优化传统岗位时,却为AI大模型人才开出百万年薪——而这,在当下仍是一将难求。
技术的稀缺性,才是你「值钱」的关键!
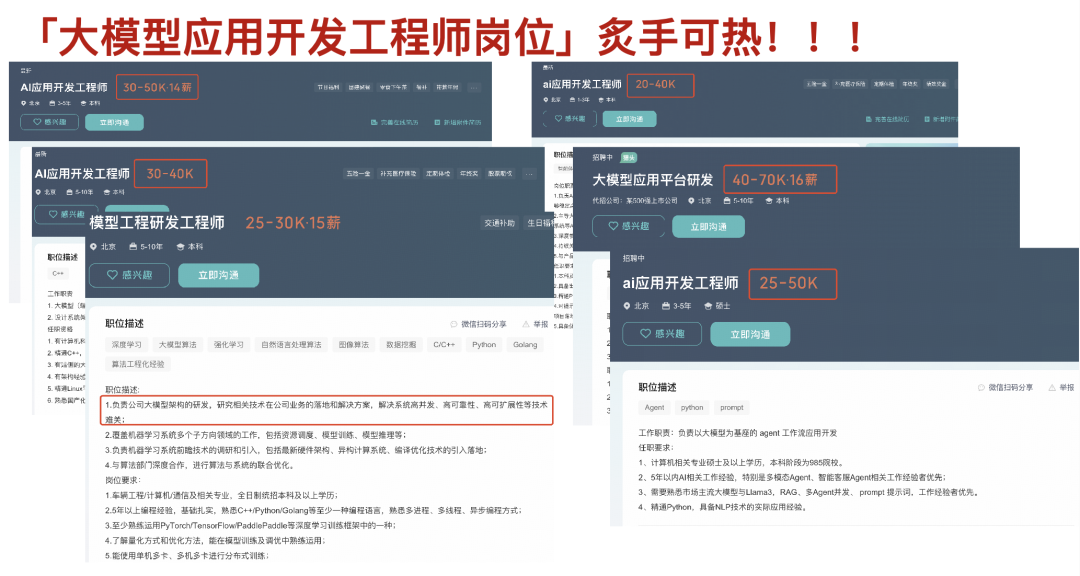
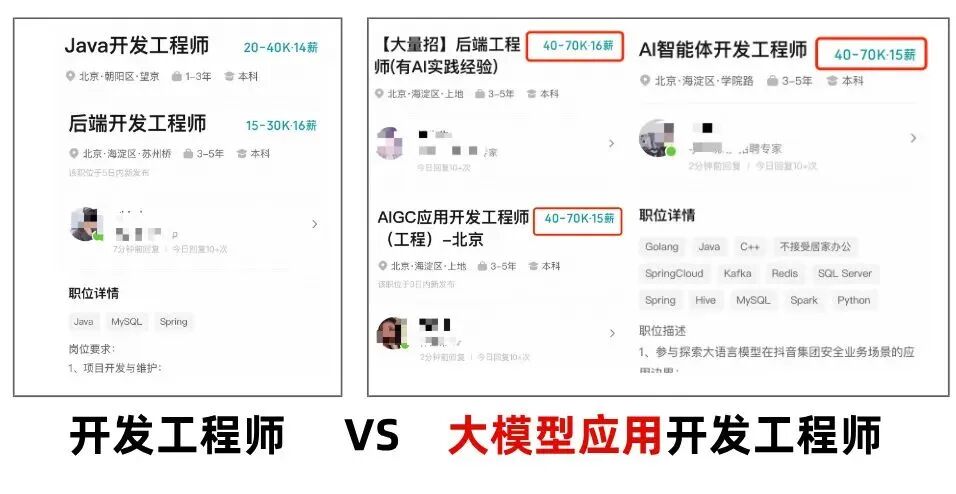
AI浪潮,正在重构程序员的核心竞争力!不要等“有AI项目开发经验”,成为面试门槛的时候再入场,错过最佳时机!
那么,我们如何学习AI大模型呢?
在一线互联网企业工作十余年里,我指导过不少同行后辈,经常会收到一些问题,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题,也不是三言两语啊就能讲明白的。
所以呢,我专为各位开发者设计了一套全网最全最细的大模型零基础教程,从基础到应用开发实战训练,旨在将你打造成一名兼具深度技术与商业视野的AI大佬,而非仅仅是“调参侠”。
同时,这份精心整理的AI大模型学习资料,我整理好了,免费分享!只希望它能用在正道上,帮助真正想提升自己的朋友。让我们一起用技术做点酷事!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!

※大模型全套学习资料展示
通过与MoPaaS魔泊云的强强联合,我们的课程实现了质的飞跃。我们持续优化课程架构,并新增了多项贴合产业需求的前沿技术实践,确保你能获得更系统、更实战、更落地的大模型工程化能力,从容应对真实业务挑战。
 资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
Part 1 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。希望这份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
👇微信扫描下方二维码即可~

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
Part2 全套AI大模型应用开发视频教程
包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点。剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
01 大模型微调
- 掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
- 学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
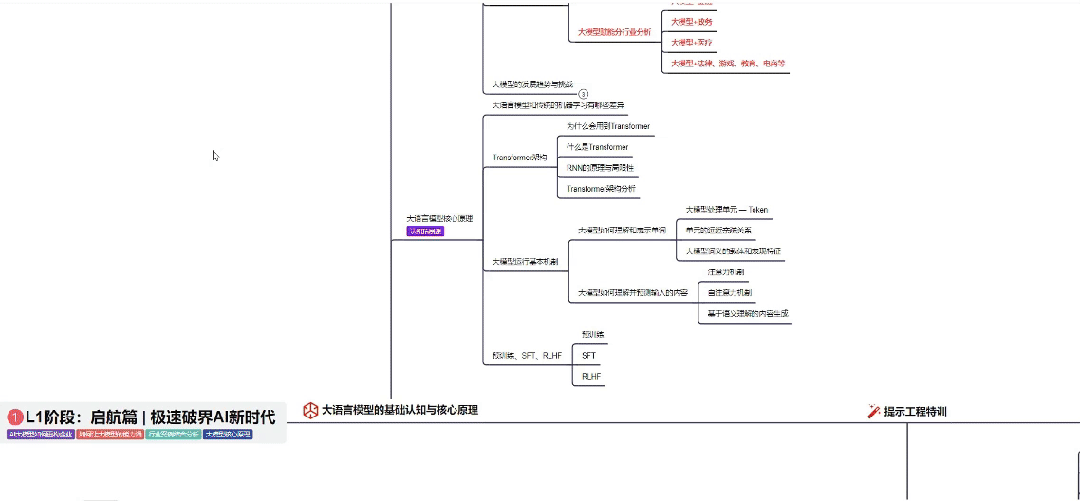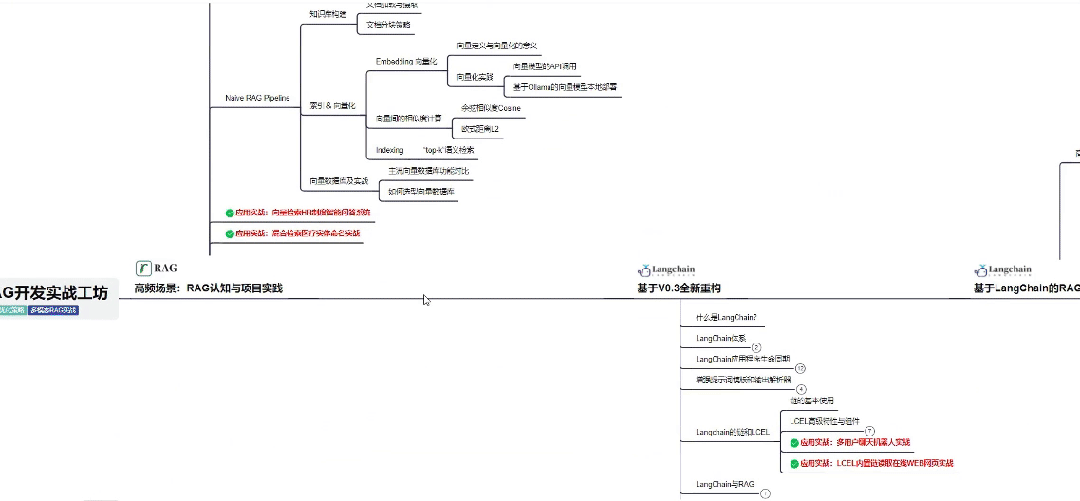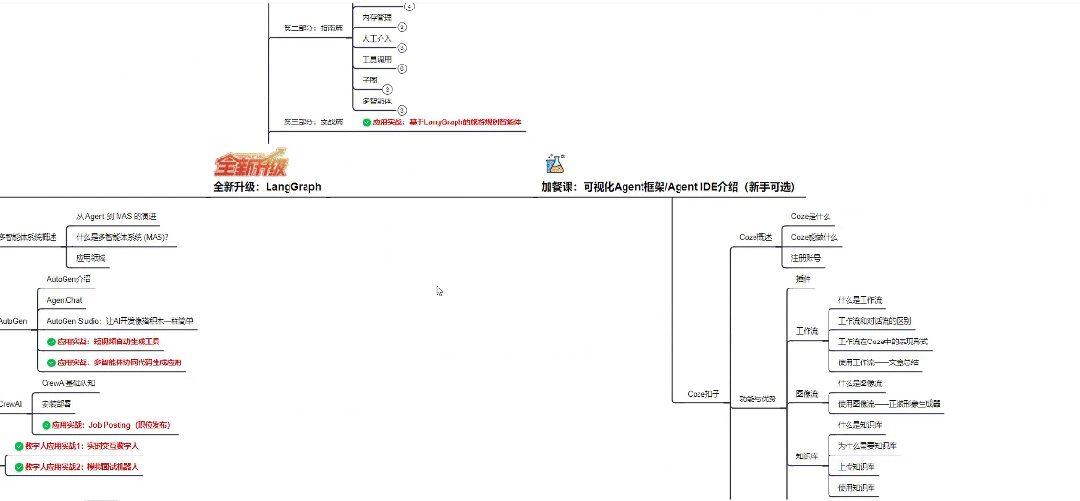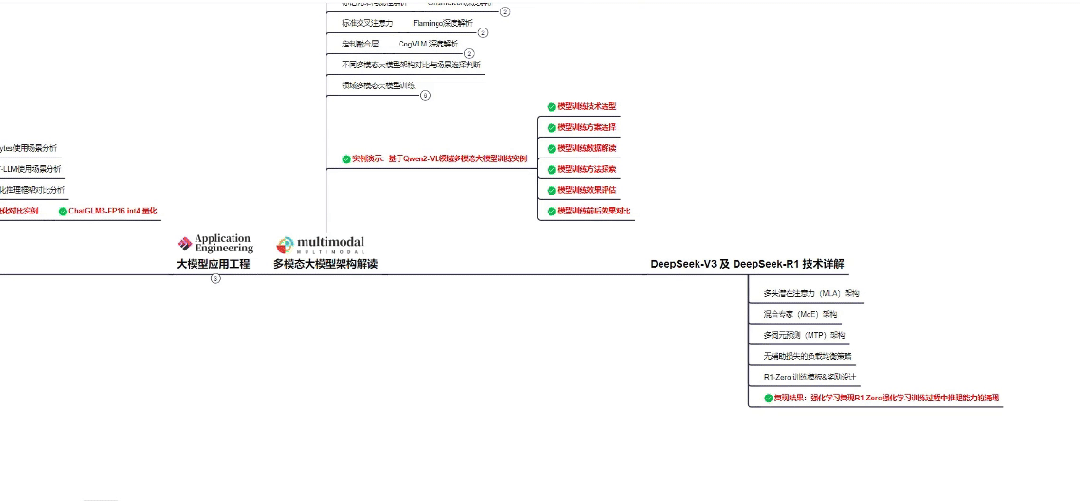
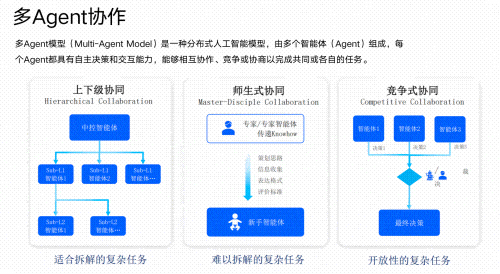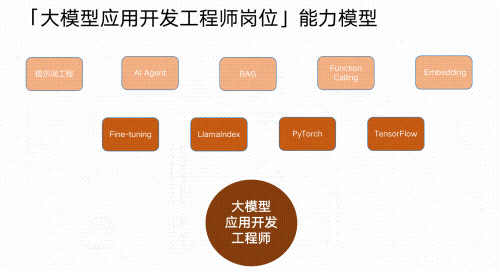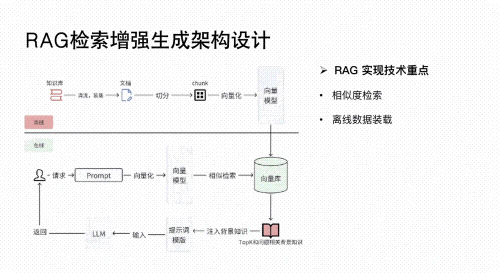
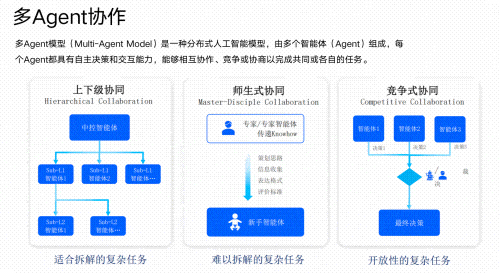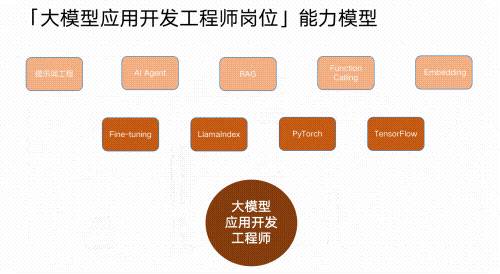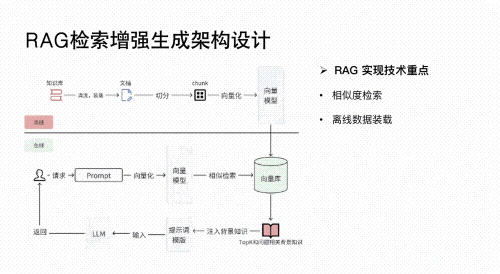
02 RAG应用开发
-
深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
-
应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
03 AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。
Part3 大模型学习书籍&文档
新手必备的权威大模型学习PDF书单来了!全是一系列由领域内的顶尖专家撰写的大模型技术的书籍和学习文档(电子版),从基础理论到实战应用,硬核到不行!
※(真免费,真有用,错过这次拍大腿!)

Part4 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
Part5 大模型项目实战&配套源码
学以致用,热门项目拆解,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
学完项目经验直接写进简历里,面试不怕被问!👇
Part6 AI产品经理+大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

最后,如果你正面临以下挑战与期待:
- 渴望转行进入AI领域,顺利拿下高薪offer;
- 即将参与核心项目,急需补充AI知识补齐短板;
- 拒绝“35岁危机”,远离降薪裁员风险;
- 持续迭代技术栈,拥抱AI时代变革,创建职业壁垒;
- ……
那么这份全套学习资料是一次为你量身定制的职业破局方案!
ps:微信扫描即可获取
加上后我将逐一发送资料
与志同道合者共勉
真诚无偿分享!!!
与其焦虑……
不如成为「掌握AI大模型的技术人」!
毕竟AI时代,谁先尝试,谁就能占得先机!
最后,祝大家学习顺利,抓住机遇,共创美好未来!

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









