









目录
1. 认识域名信息
1.1 根域名
baidu.com
1.2 子域名
类似于下面的域名的样式的是子域名,当然是否是目标网站的资产,还需要查看备案信息
www.baidu.com
a.baidu.com
xyz.baidu.com
bc.baidu.com
2. 子域名信息收集
域名收集分为主动信息收集和被动信息收集
2.1 被动信息收集
通过第三方资产测绘平台或者通过bing或者google等浏览器对子域名进行信息收集,不与目标系统直接进行交互,留下的痕迹较少不易于被发现,这里用百度进行示例
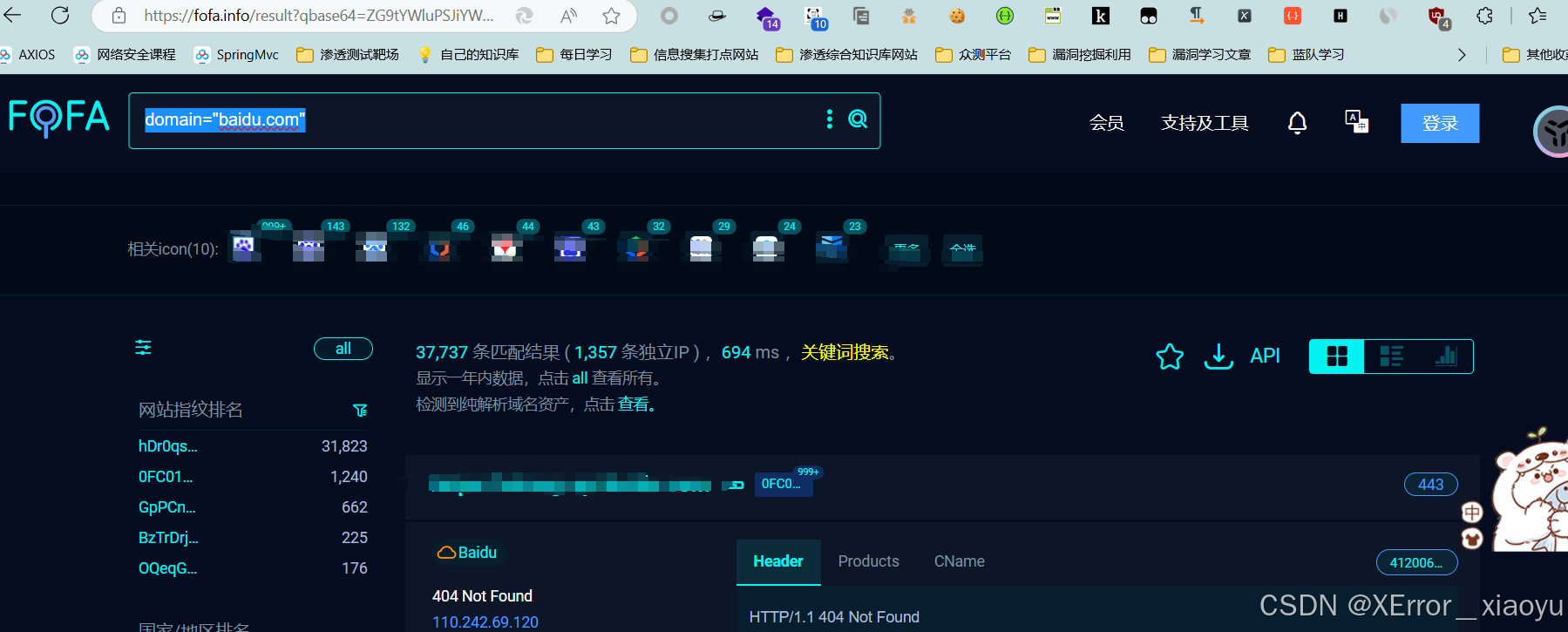
2.1.1.fofa
domain="baidu.com"
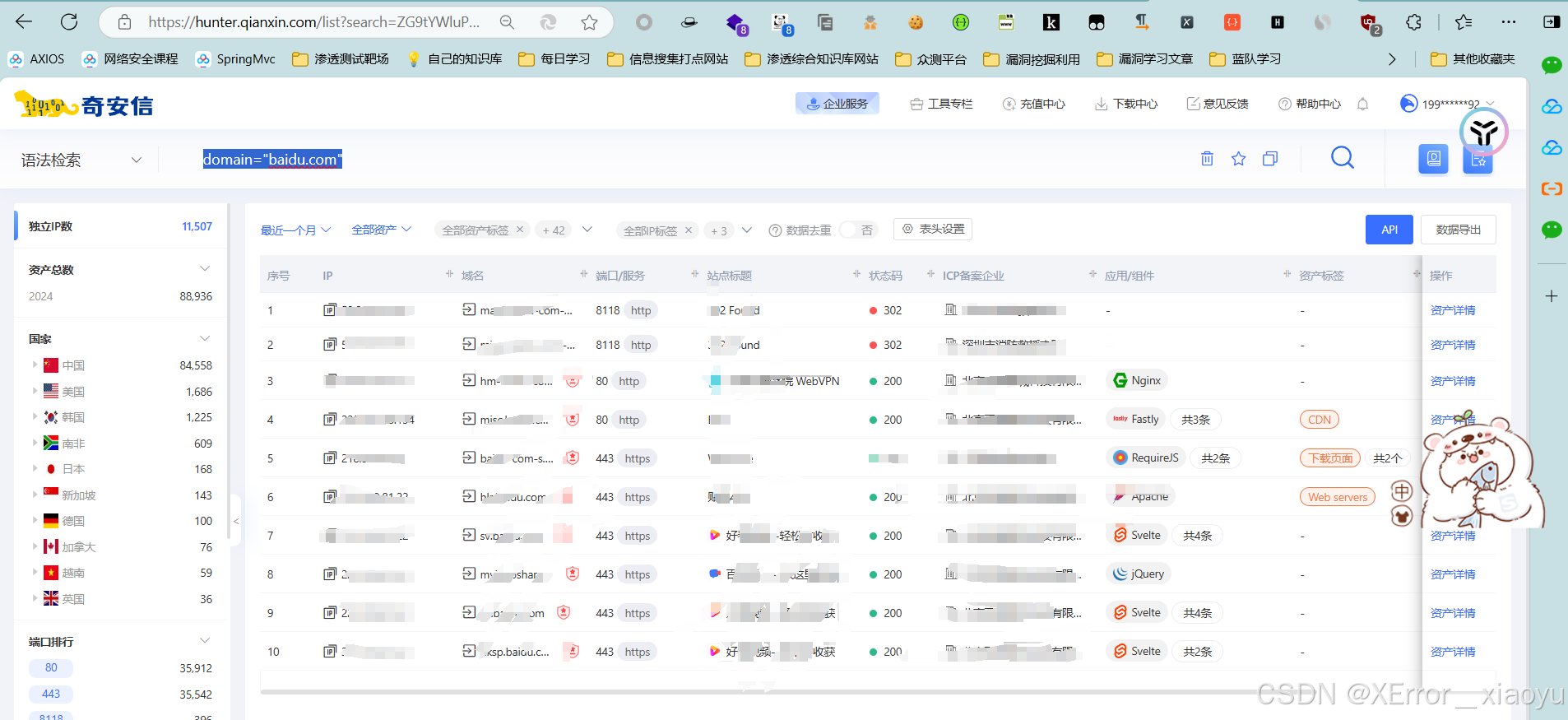
2.1.2 鹰图
domain="baidu.com"
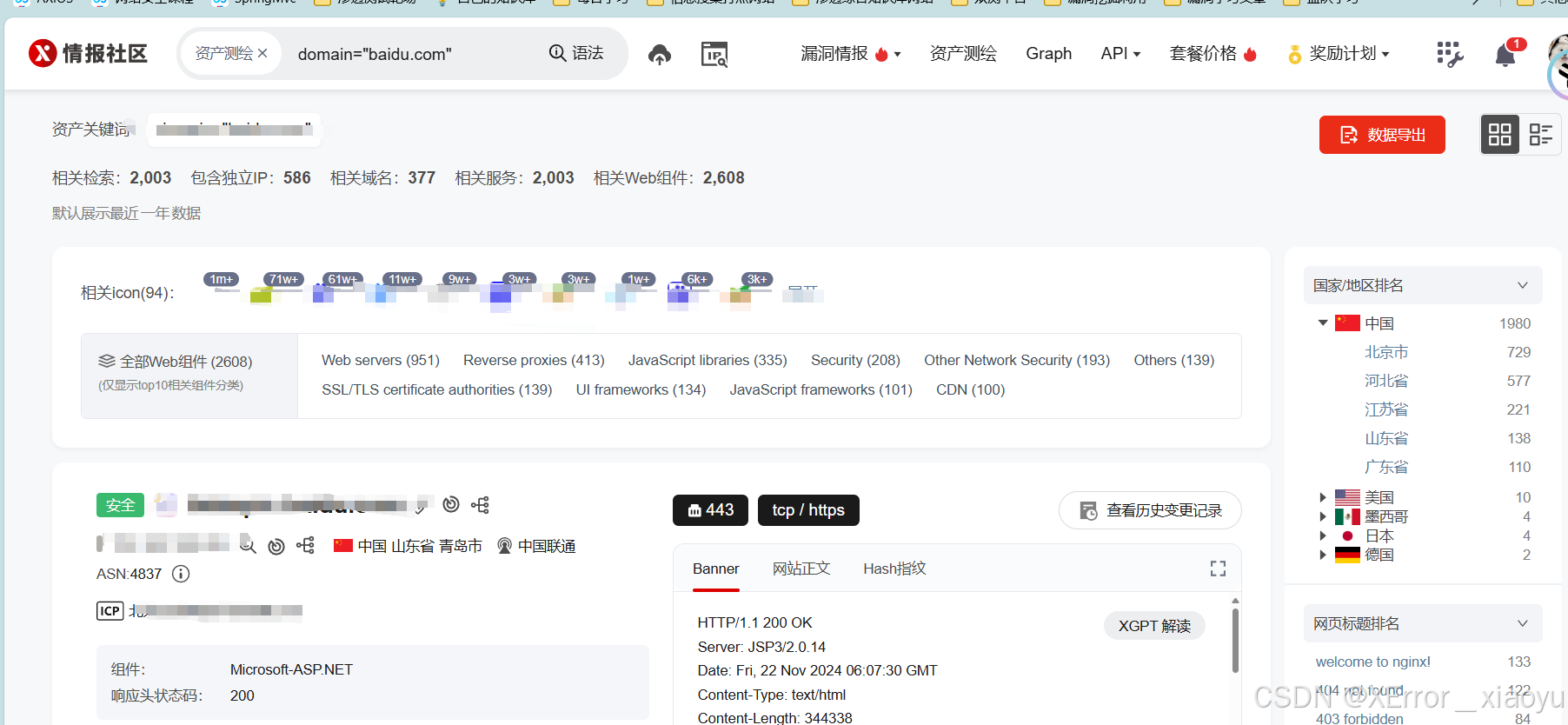
2.1.3.微步社区
domain="baidu.com"
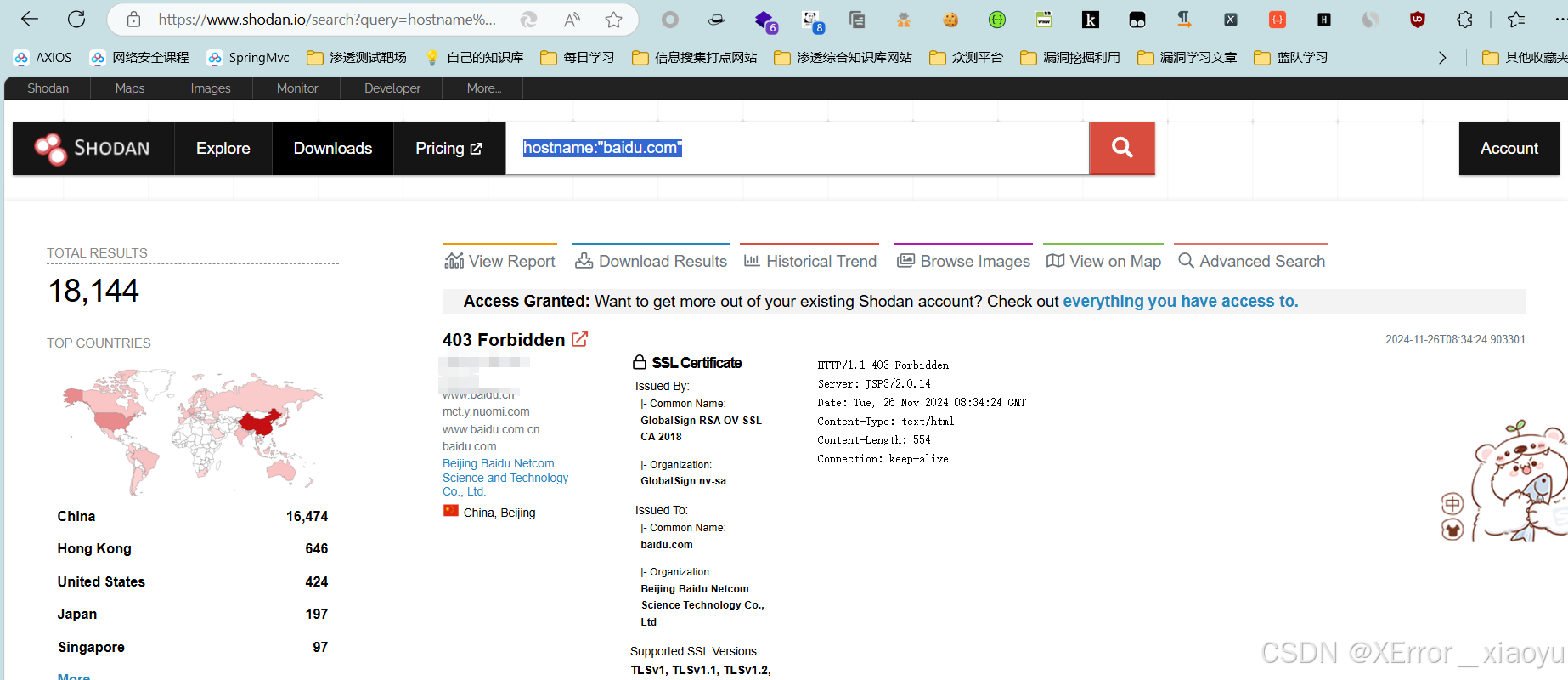
2.1.4.shodan(收集隐藏端口和摄像头好用)
hostname:"baidu.com"
2.1.5.搜索引擎和仓库信息收集
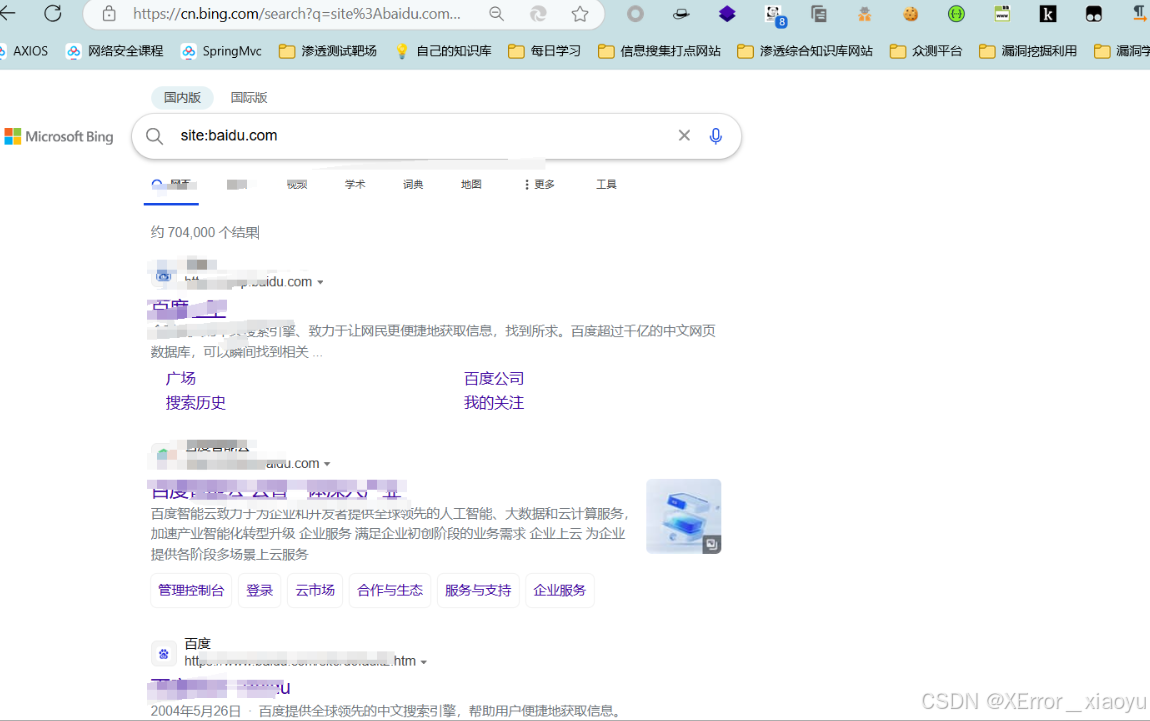
5.1 bing进行信息收集
site:baidu.com
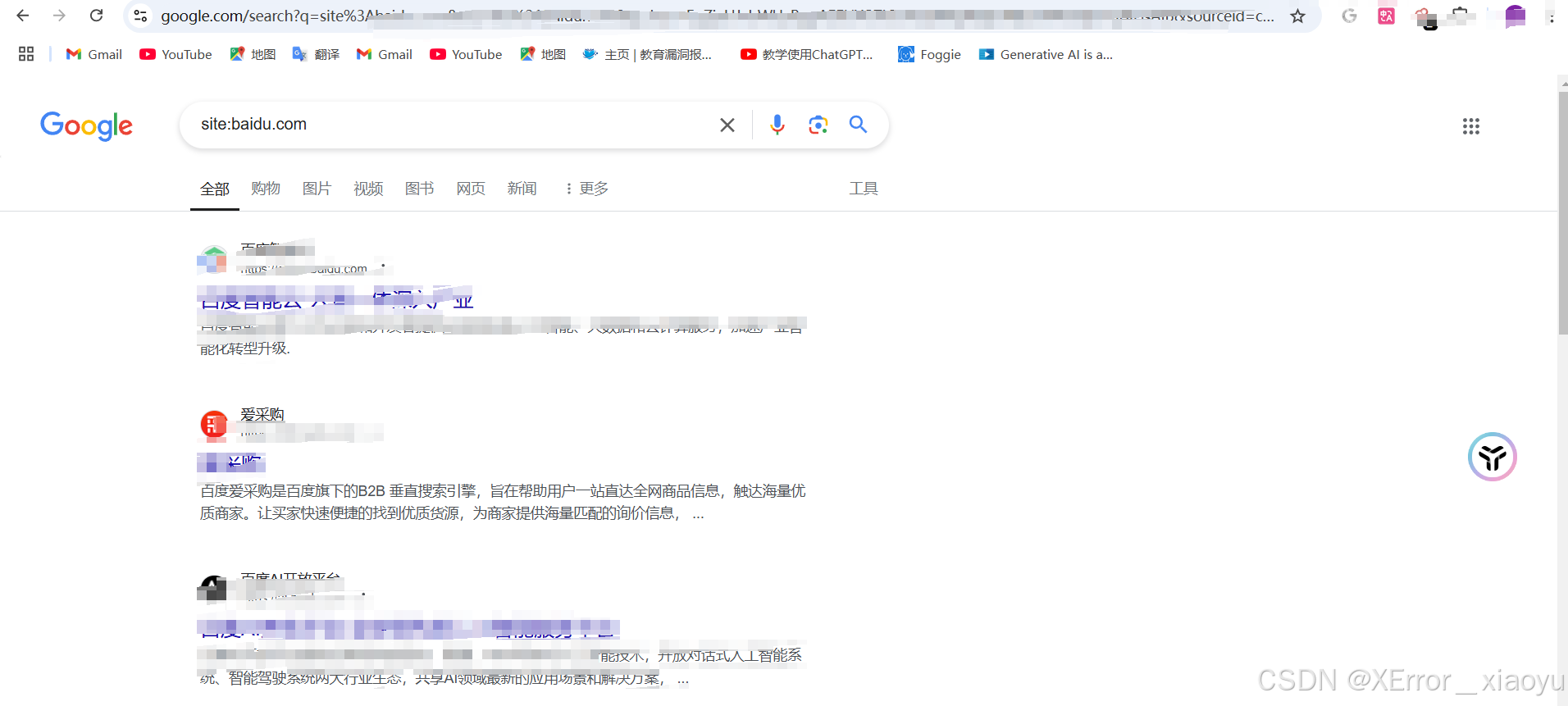
5.2 google(挂代理)
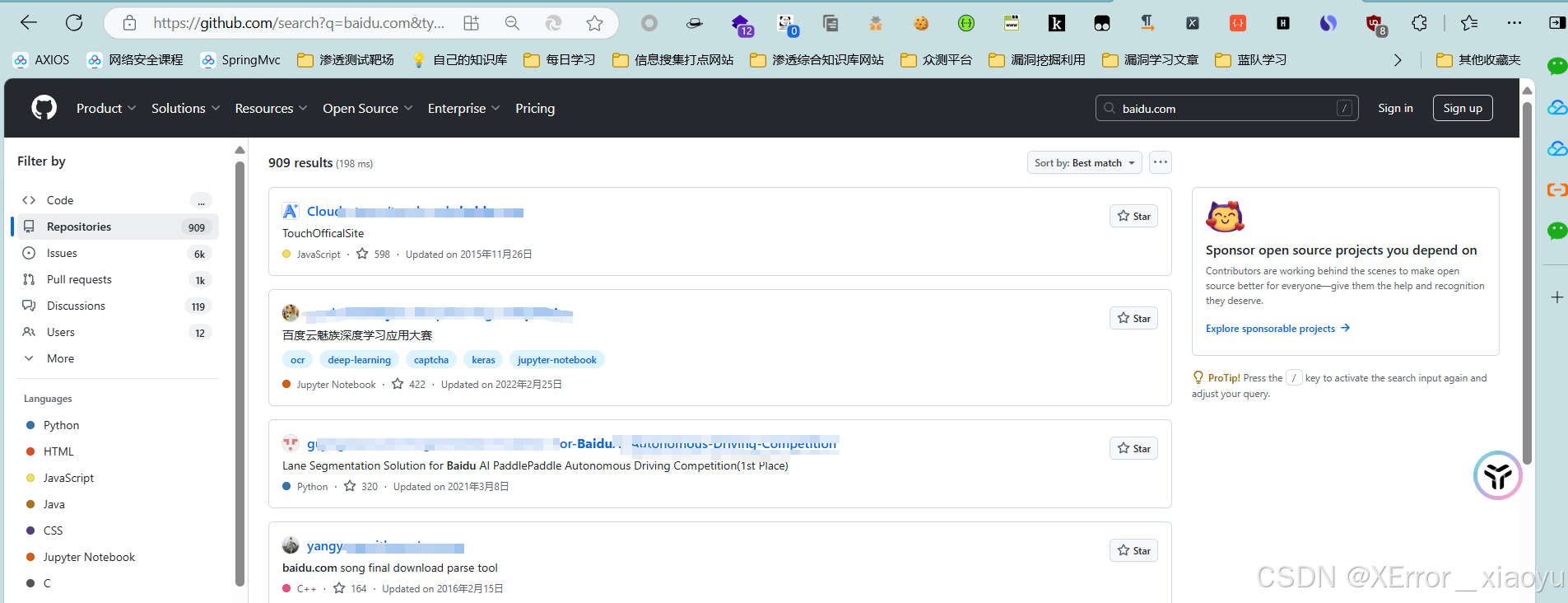
5.3 github信息收集
直接搜百度即可,当然也可以通过工具对目标进行信息收集
手工方式进行搜索
in:name baidu #标题搜索含有关键字baidu
in:descripton baidu #仓库描述搜索含有关键字
in:readme baidu #Readme文件搜素含有关键字
stars:>3000 baidu #stars数量大于3000的搜索关键字
stars:1000..3000 baidu #stars数量大于1000小于3000的搜索关键字
forks:>1000 baidu #forks数量大于1000的搜索关键字
forks:1000..3000 baidu #forks数量大于1000小于3000的搜索关键字
size:>=5000 baidu #指定仓库大于5000k(5M)的搜索关键字
pushed:>2019-02-12 baidu #发布时间大于2019-02-12的搜索关键字
created:>2019-02-12 baidu #创建时间大于2019-02-12的搜索关键字
user:name #用户名搜素
license:apache-2.0 baidu #明确仓库的 LICENSE 搜索关键字
language:java baidu #在java语言的代码中搜索关键字
user:baidu in:name baidu #组合搜索,用户名baidu的标题含有baidu的
5.4 GitDorker工具
这个是工具的简介,需要的师傅可以通过下面的链接从github下载 GitDorker 是一款github自动信息收集工具,它利用 GitHub 搜索 API 和作者从各种来源编译的大量 GitHub dorks 列表,以提供给定搜索查询的 github 上存储的敏感信息的概述。
https://github.com/obheda12/GitDorker
2.1.6.其他的第三方查询子域名网站
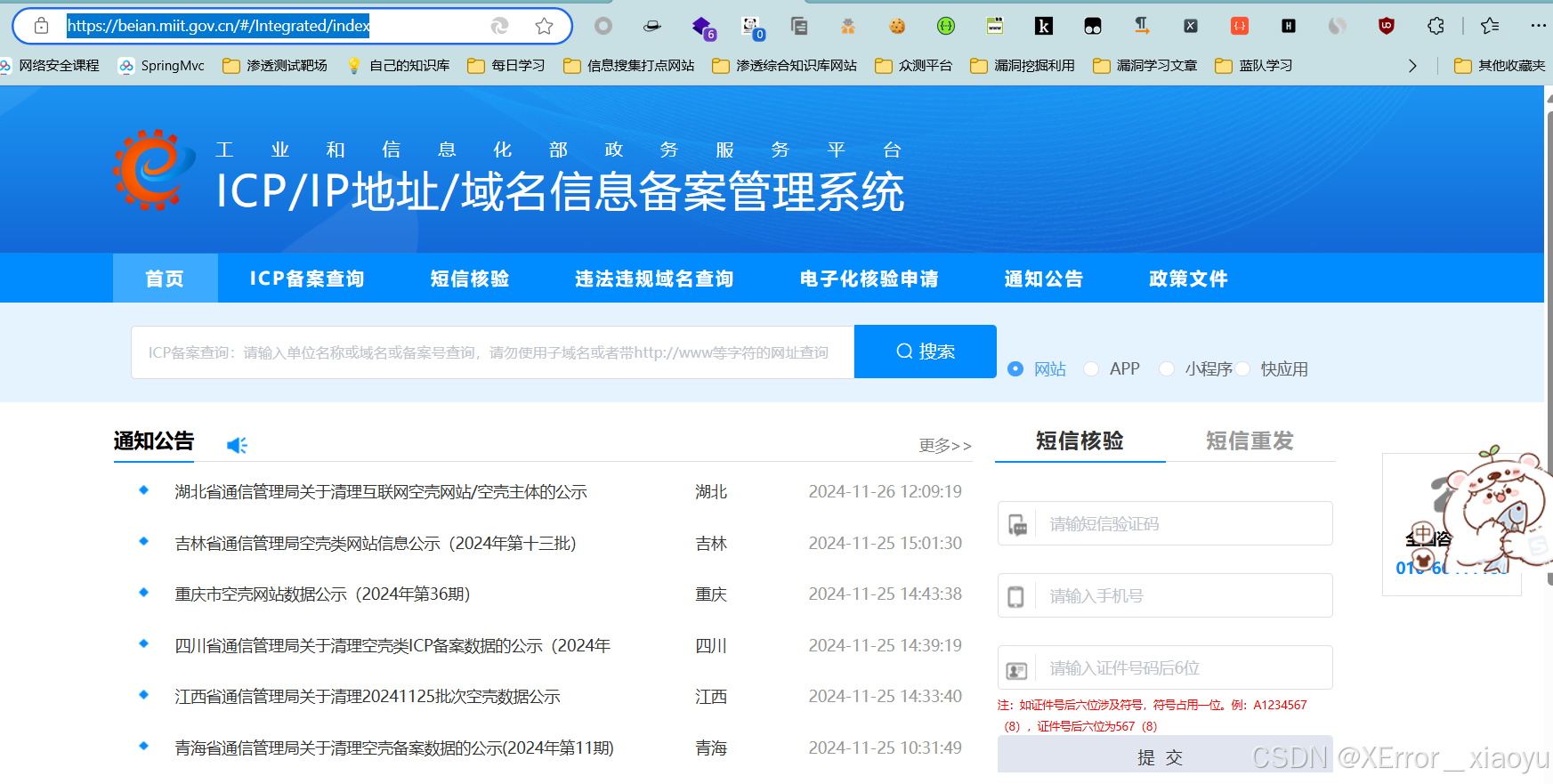
1. ICP/IP地址/域名信息备案管理系统
https://beian.miit.gov.cn/#/Integrated/index
2. 站长之家
https://tool.chinaz.com/subdomain/
3. 查询网
https://site.ip138.com/
4. 查子域
https://chaziyu.com/
2.2 主动信息收集
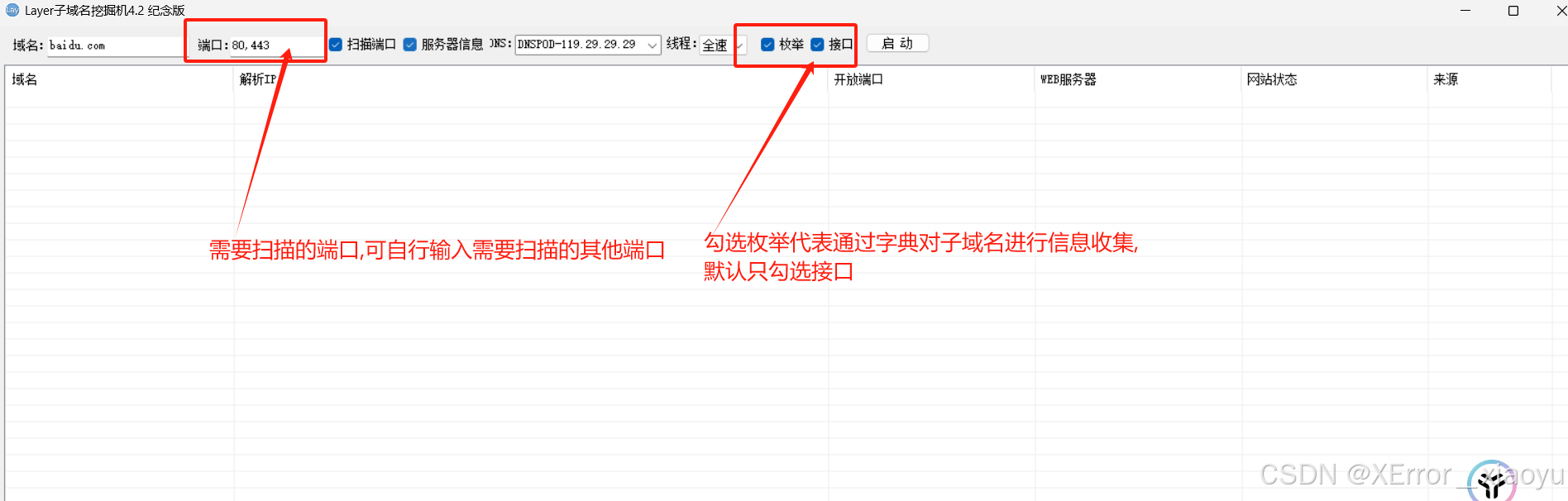
2.2.1 Layer子域名挖掘机4.2纪念版
2.2.2 subDomainsBrute
这个是脚本的作者自己写的内容

在使用之前需要安装库
pip install dnspython
pip install aiodns
# 使用通过命令
python subDomainsBrute.py
-f 指定扫描子域名前缀的字典
-t 指定扫描的线程数,默认为200
--full 代表完整扫描
-o 代表输出子域名文件名,默认是子域名.txt
# 直接使用
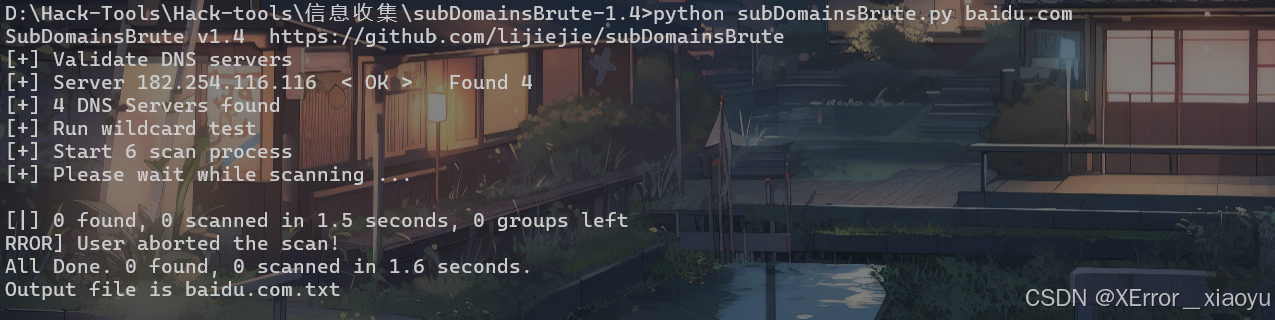
python subDomainsBrute.py baidu.com
# 字典扫描(-o 指定不同的文件输出类型和输出文件名)
python subDomainsBrute.py baidu.com -f subnames_full.txt -o baidu.com.csv
python subDomainsBrute.py baidu.com -f subnames_full.txt -o baidu.com.txt
2.2.3 Sublist3r
# 首先需要安装第三方库文件,保证脚本能够正常运行
pip install -r requirements.txt
# 还需要运行下面的命令对request这个库进行安装,这个库在很多脚本中都是必安的,我就不用安装了
pip install requests在当前目录文件下,运行pip安装所需的脚本文件
3.更详细的信息收集
更详细的子域名和信息收集看之前写的文章即可



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











