






目录
一、引言:Linux 系统编程的核心价值
在服务器开发、嵌入式系统、云计算等领域,Linux 系统编程能力是开发者的核心竞争力。本文将从文件操作、进程管理、线程同步三个维度,深入解析 Linux 内核机制,并结合实战经验分享优化策略,帮助读者构建高性能系统级应用
二、文件操作:内核视角的 I/O 管理
1. 文件描述符的本质
- 内核存储结构:每个进程维护独立的
files_struct结构体,包含文件描述符表(FD Table)和打开文件对象指针数组。 - 生命周期管理:通过
dup/dup2复制文件描述符,fcntl设置标志位(如FD_CLOEXEC)。 - 性能优化点:合理复用文件描述符,避免频繁打开 / 关闭操作。
2. 文件系统交互机制
- 页缓存(Page Cache):内核通过 LRU 算法管理内存缓存,
read优先从缓存读取数据。 - 直接 I/O(O_DIRECT):绕过页缓存,适用于数据库等对缓存敏感的场景。
- 异步 I/O(AIO):通过
io_submit提交批量请求,配合事件通知实现高并发。
3. 原子操作与竞争控制
- 追加原子性:
O_APPEND标志保证多进程安全,内核通过file->f_pos原子递增实现。 - 文件锁粒度:
fcntl支持字节范围锁(如F_RDLCK),适用于细粒度资源控制。
4.基于文件操作的一些案例实现
4.1文件打开操作:open
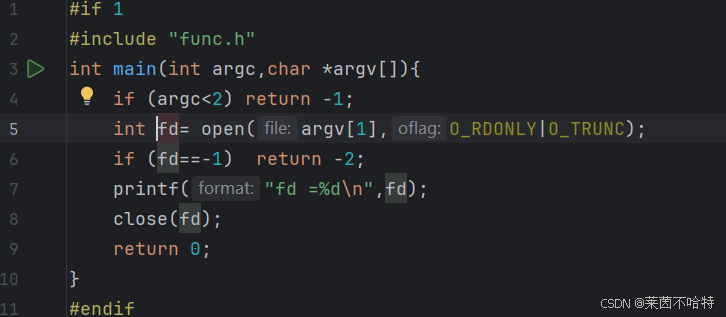
Linux 中的open函数是用于打开或创建文件的系统调用,通过传入文件路径、打开标志(如读 / 写模式)及创建权限(创建文件时用),成功时返回文件描述符(非负整数),失败则返回 - 1,是文件操作的核心基础接口。
文件描述符FD
文件描述符(FD,File Descriptor)是 Linux 系统中标识进程已打开文件(如普通文件、管道、套接字等)的非负整数,作为进程访问文件资源的句柄。内核为每个进程维护文件描述符表,FD 充当表的索引,关联文件的内核对象(如struct file),像标准输入(0)、标准输出(1)、标准错误(2)是进程默认打开的 FD,程序通过open等函数获取 FD 后,借助它执行read、write等文件操作。
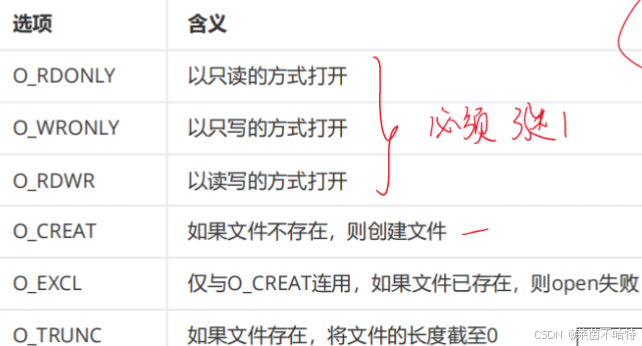
open中的flag属性介绍
4.2文件的读操作:read
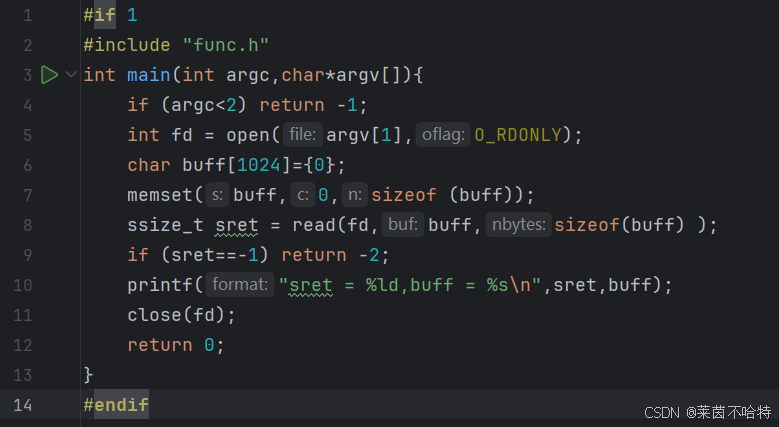
Linux 的read函数是系统调用接口,用于从文件描述符关联的文件、管道、套接字等读取数据到用户缓冲区,返回实际读取字节数,失败时返回 - 1 并更新errno标识错误类型。
代码段的内容是把文件描述符fd指向的文件对象的内容读到buff里面并检查报错 最后打印出来
4.3文件的写操作:write
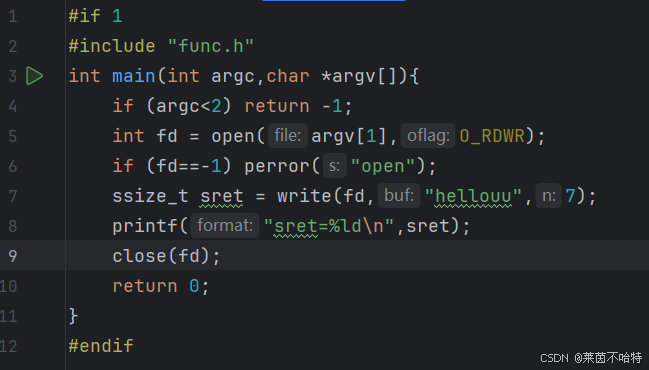 Linux 的
Linux 的write函数是系统调用接口,用于将指定缓冲区数据写入文件描述符关联的文件、管道等对象,返回实际写入字节数,执行失败时返回 - 1 并通过errno标识错误原因。
代码段的内容是把hellouu这个字符串写入到文件描述符fd所指向的文件对象中
4.4二进制文件的读取
*文本文件和二进制文件的区别
①文本文件:ASCII码序列 读写文本文件可以用字符数组 也配合命令cat和vim进行读取
②二进制文件:不会是ASCII码序列 写用什么类型 读就用什么类型
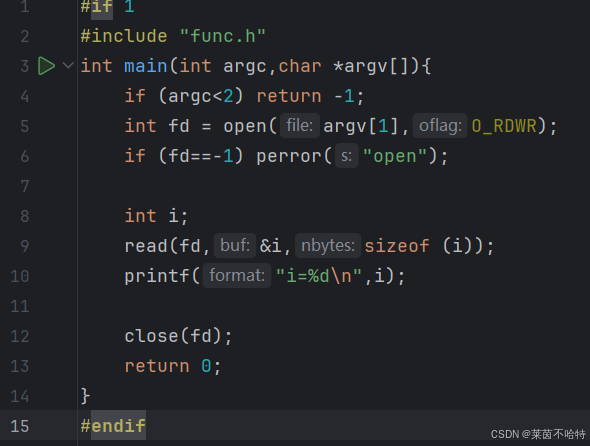
4.5基于open read write三个系统调用实现一个copy命令
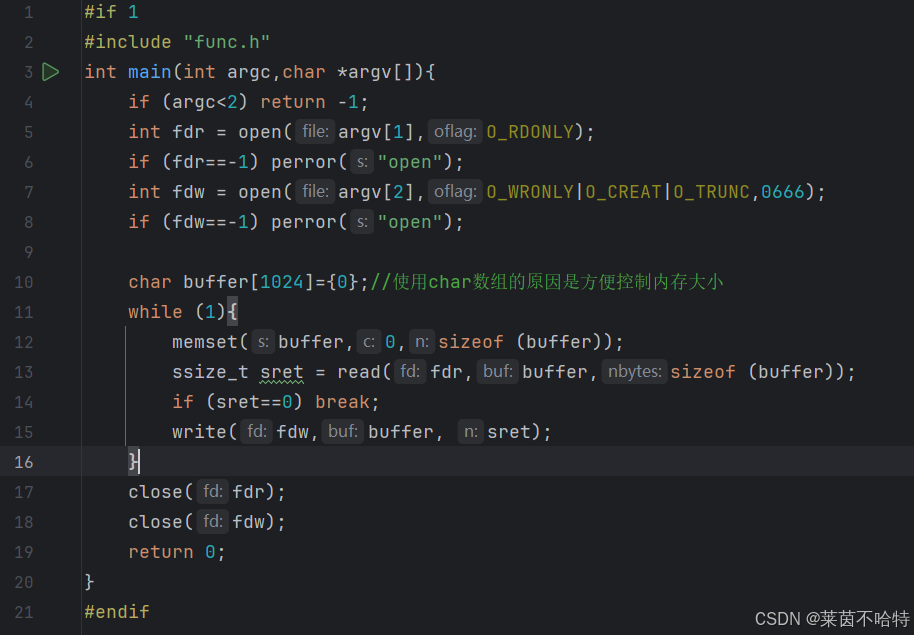
代码内容是通过open的系统调用打开两个文件分别是一号文件和二号文件 目的是把一号文件的内容copy到二号文件 操作是读取一号文件的内容到字符串数组buffer中 再把字符串数组buffer的内容写到二号文件中 从而通过系统调用实现了copy的命令
4.6 ftruncate 截断文件函数
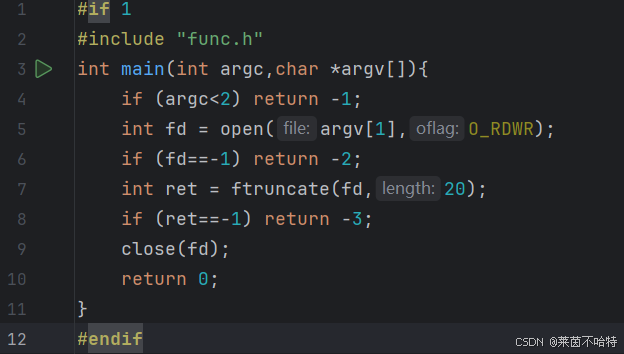
使用 ftruncate 将文件截断为 20 字节,最后关闭文件描述符
情况① 大->小 保留前面
情况②小->大 补二进制的0
4.7 mmap文件映射
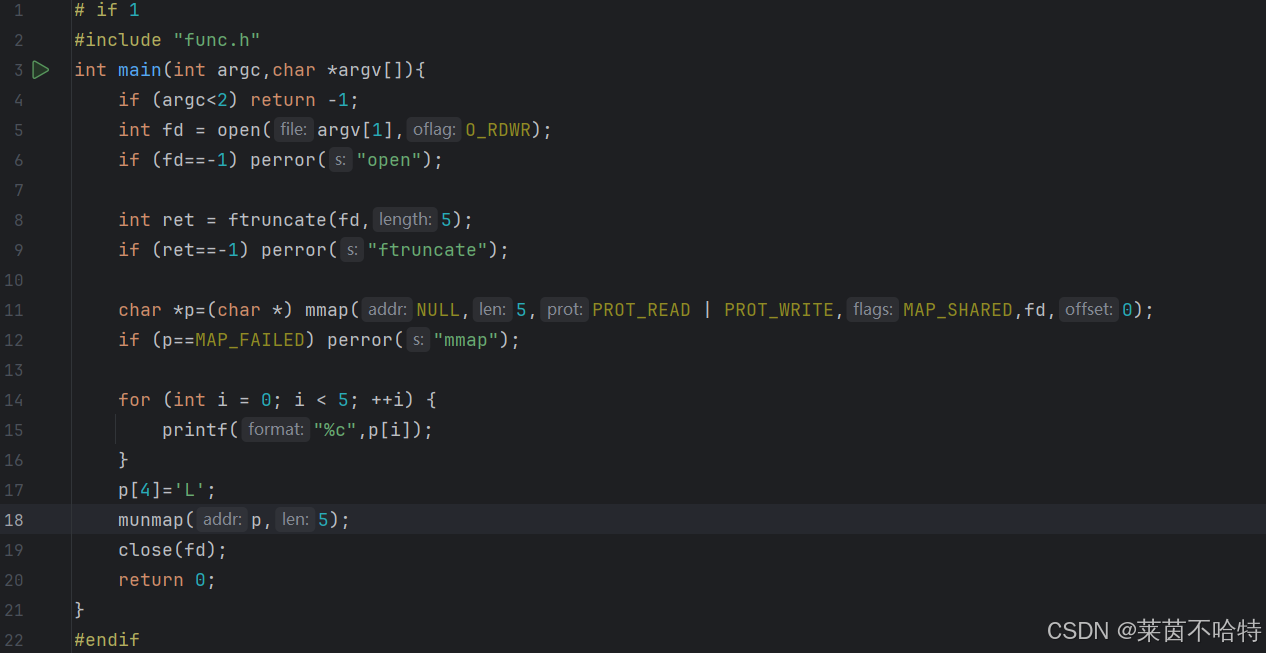
通过p 指向 mmap 映射的内存区域,用于后续读写操作
p[4]='L'这个对内存的操作从而改变文件对象里面的内容
4.8 将小写字母改写成大写字母
方法一:通过mmap映射实现
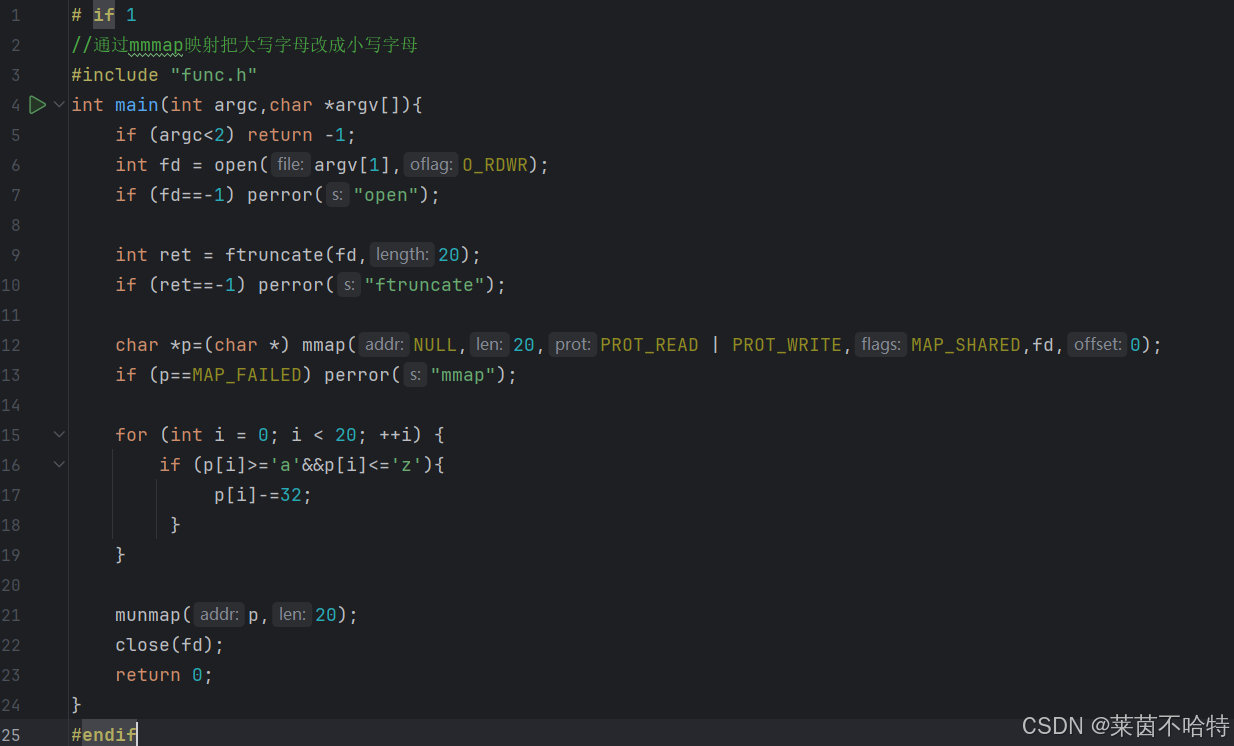
通过mmap对20个字节的文件内容进行大小写字母切换功能
方法二:通过read和write实现
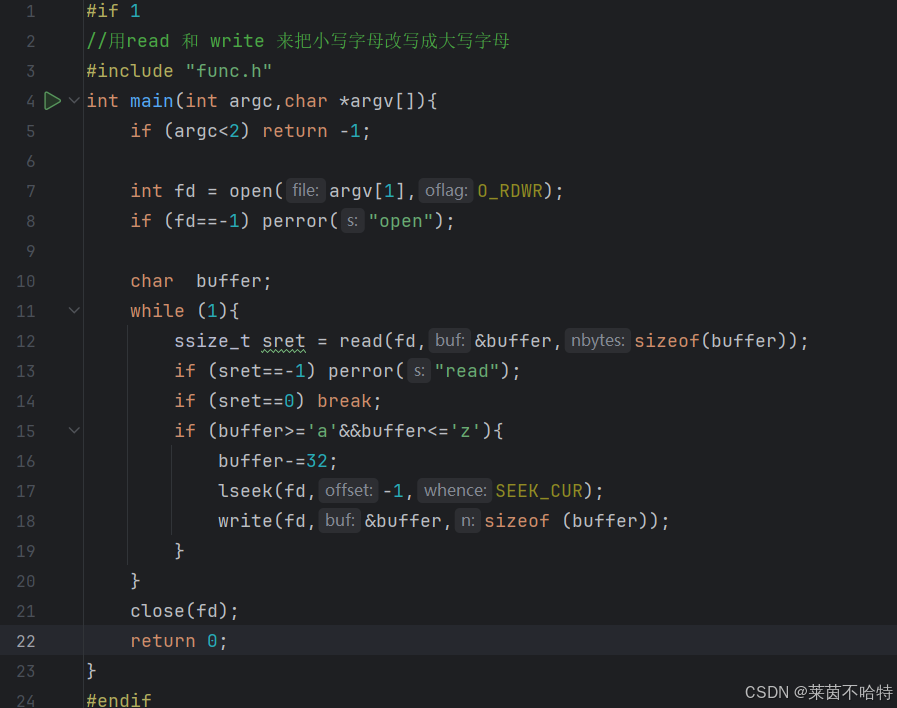
由于对文件对象的读写 PC指针会产生向后偏移一位 所以我们需要一个lseek函数来控制指针的读写位置
lseek函数的第一个参数fd是文件描述符,表示要操作的文件。第二个参数-1表示要移动的字节数,负数表示向前移动,正数表示向后移动。第三个参数SEEK_CUR表示从当前位置开始移动。
通过使用lseek函数,我们可以灵活地控制文件读写指针的位置,从而实现对文件内容的精确操作。
4.9 fileno函数
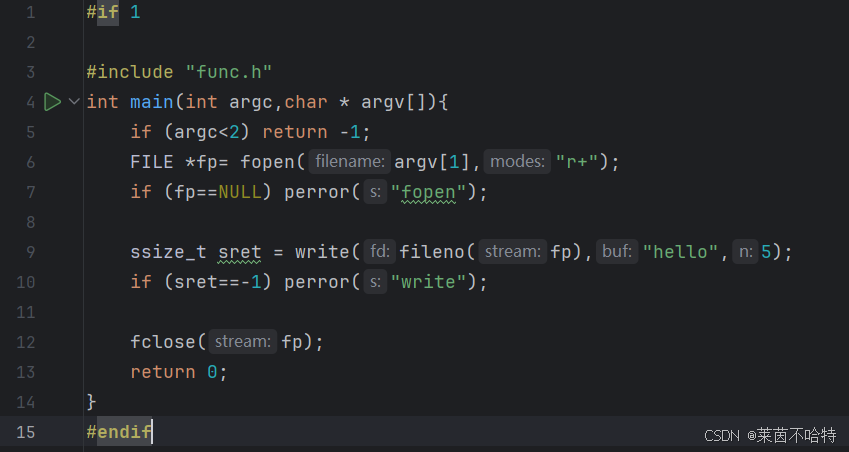
我们如果需要用fopen非系统调用的函数 获取他的文件描述符的话需要用到flieno函数 再进行read操作 关于该函数详细介绍如下
fileno 是 C 语言标准库(stdio.h)中的函数,作用是获取 FILE* 文件流指针对应的 文件描述符(File Descriptor,FD)。在同时使用标准 I/O 函数(如 fopen)和系统调用(如 read、write)时,需通过 fileno 从 FILE* 中提取底层文件描述符,使系统调用能操作该文件
程序每次启动都会打开三个文件流 分别是 stdin stdout stderr
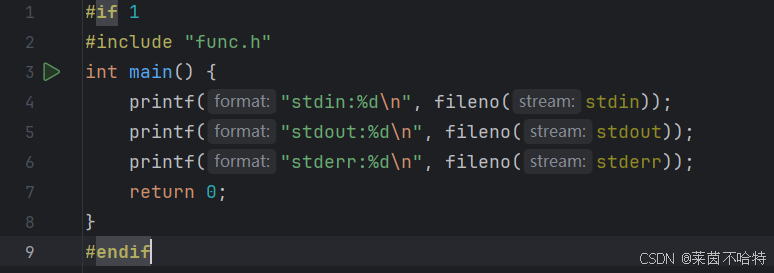
我们可以通过fileno函数对它们进行文件描述符的获取
在 C 语言中,stdin、stdout和stderr被定义在stdio.h头文件中,与它们关联的整数形式的文件描述符分别是 0、1 和 2。
时候可以手动设置代码来改变三者的方向,让输出到文件中,这就需要设置重定向。例如,在 Linux 系统中,使用重定向符号<可以将文件内容作为stdin输入给程序,使用>可以将程序的stdout输出结果保存到文件中,使用2>可以将程序的stderr输出结果保存到文件中。
4.10重定向
对于stdout文件流的重定向
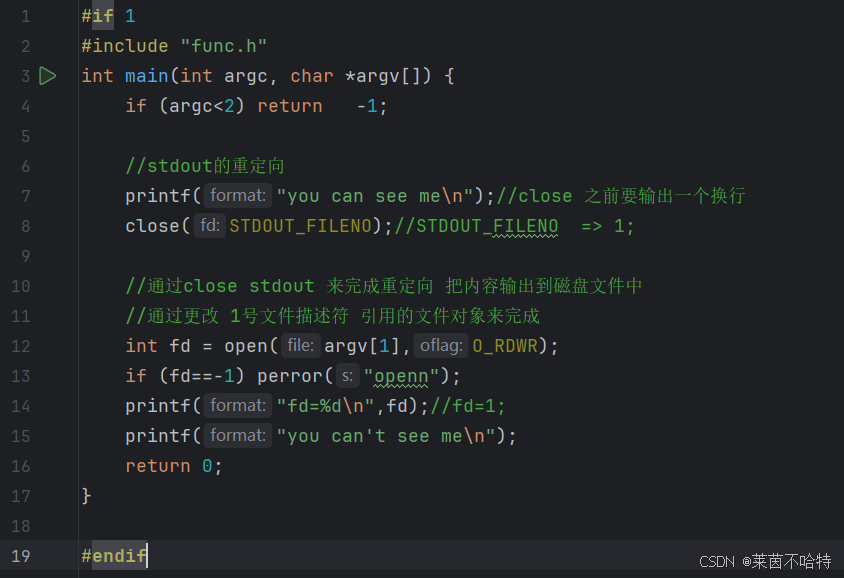
先对close掉sdtout的文件描述符 再打开系统调用open的文件描述符 此时open的文件描述符就会占据本来属于stdout的文件描述符也就是1 最后printf本来应该输出到屏幕上结果会输出到我们打开的第一个文件里
dup函数完成重定向
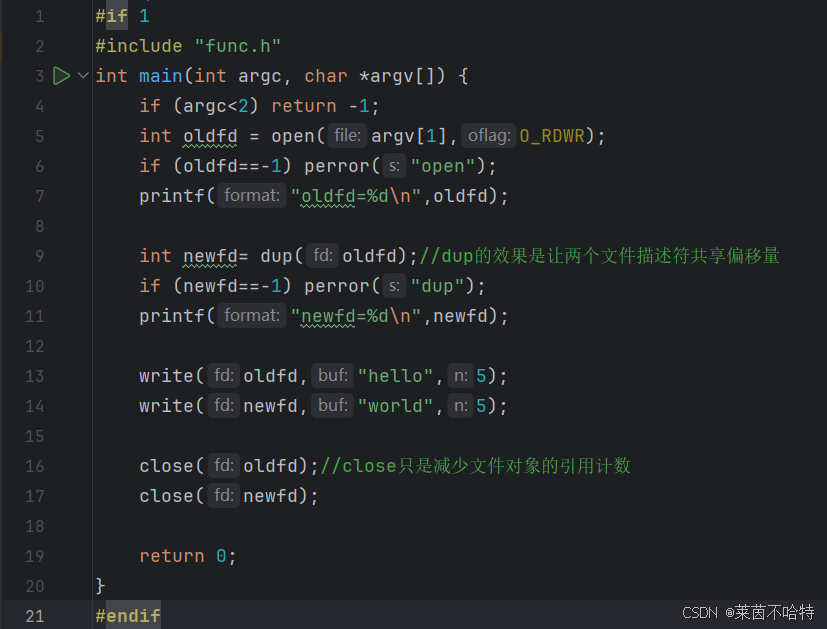
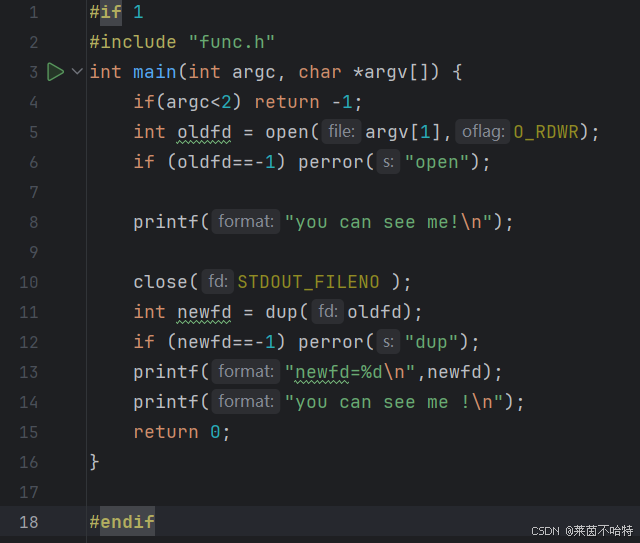
Linux 中的 dup 是系统调用函数,用于复制文件描述符,生成一个新文件描述符,与原文件描述符指向同一文件内核对象(共享文件偏移量、读写权限等),新描述符是当前最小未使用的非负整数,调用失败时返回 -1,常用于文件描述符重定向(如重定向标准输出到文件)。
上述代码中通过关闭stdout文件流 从而让newfd占据1号文件描述符 后通过dup函数改变1号文件描述符的指向 最终pirntf输出的内容会输出在第一个打开的文件中
dup2函数完成重定向
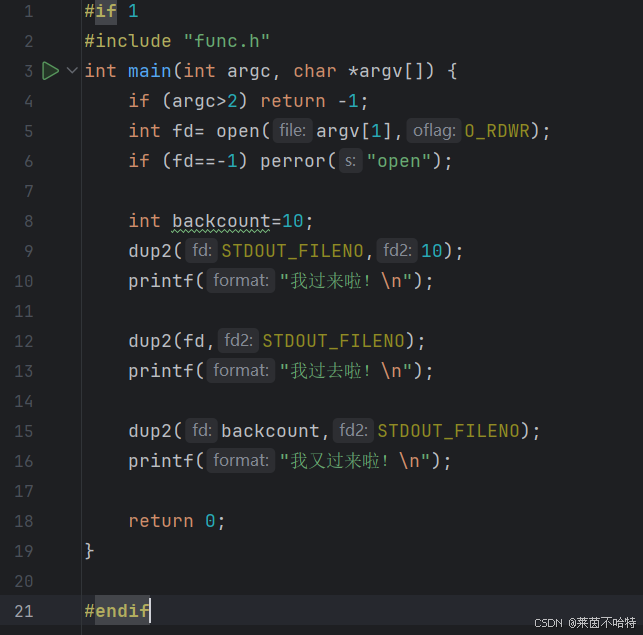
在 Linux 系统编程中,dup2是一个用于复制文件描述符的系统调用,其功能与dup类似,但允许显式指定新文件描述符的值。
通过dup2函数更改文件描述符的指向
代码解释:三个步骤
①先把backcount的指向标准输出
②再把stdout指向磁盘
③最后再把stdout的指向改回来
4.11管道通信机制
①通过对一个管道文件进行读写操作从而达到通信的功能
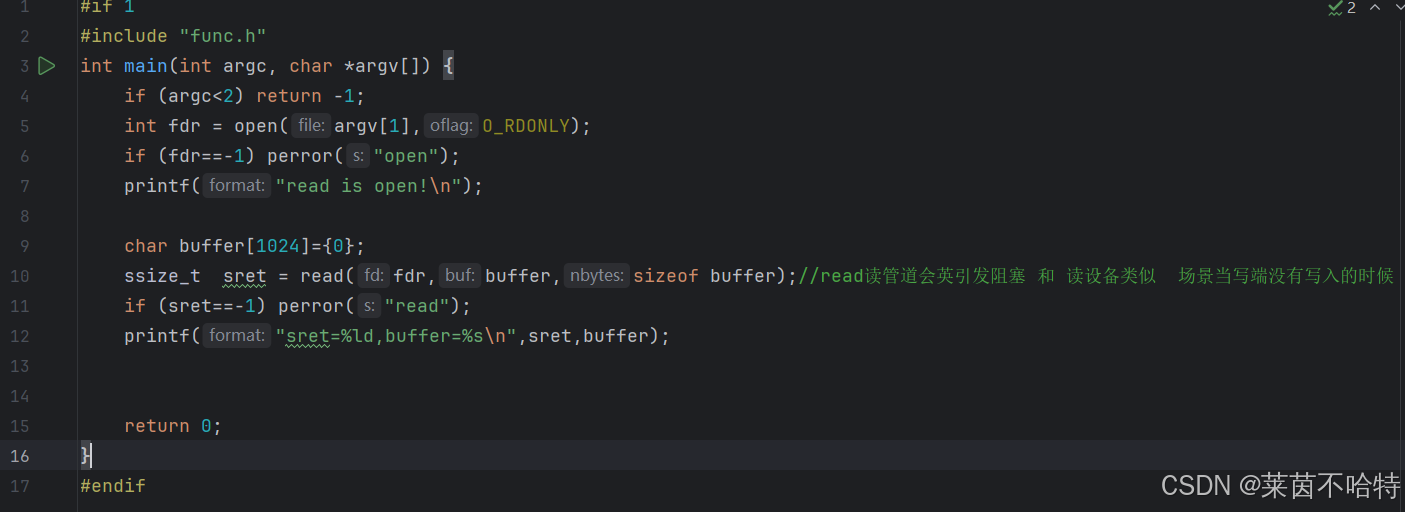
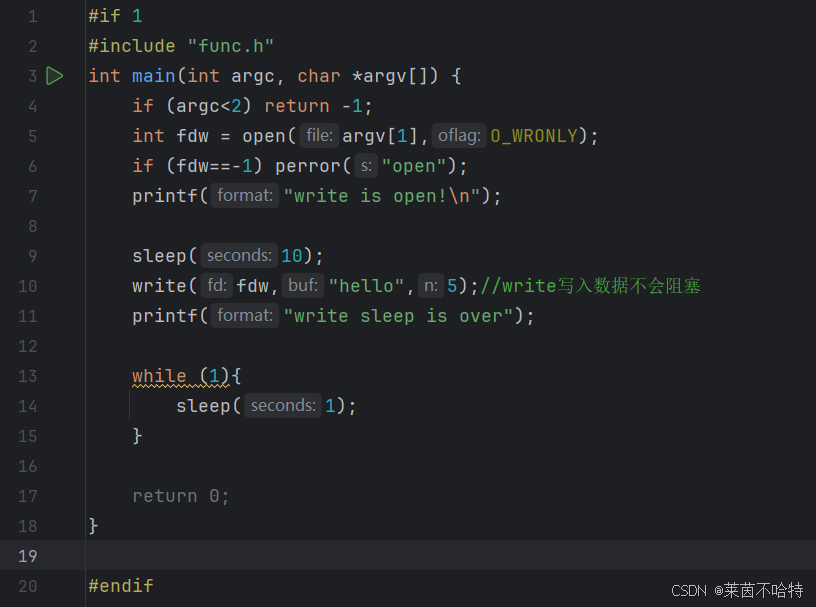
上述代码中对 一个管道文件进行只读的话 会造成阻塞现象,对管道文件只写的话则不会造成阻塞现象
②通过对两个管道文件进行读写操作从而达到通信的功能
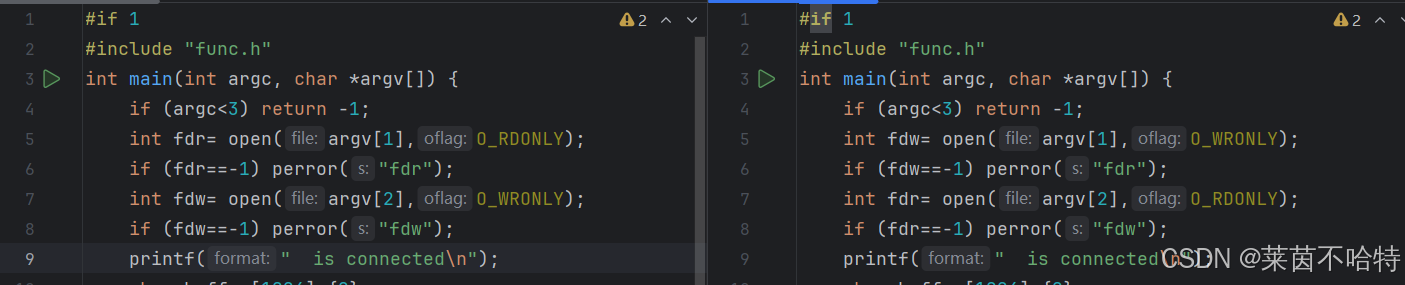
我们通过两个进程对一号管道文件分别打开了只读 和 只写 对二号管道打开了只写和只读 从而避免了死锁现象 最终达到了全双工通信
4.12 IO多路复用 select函数
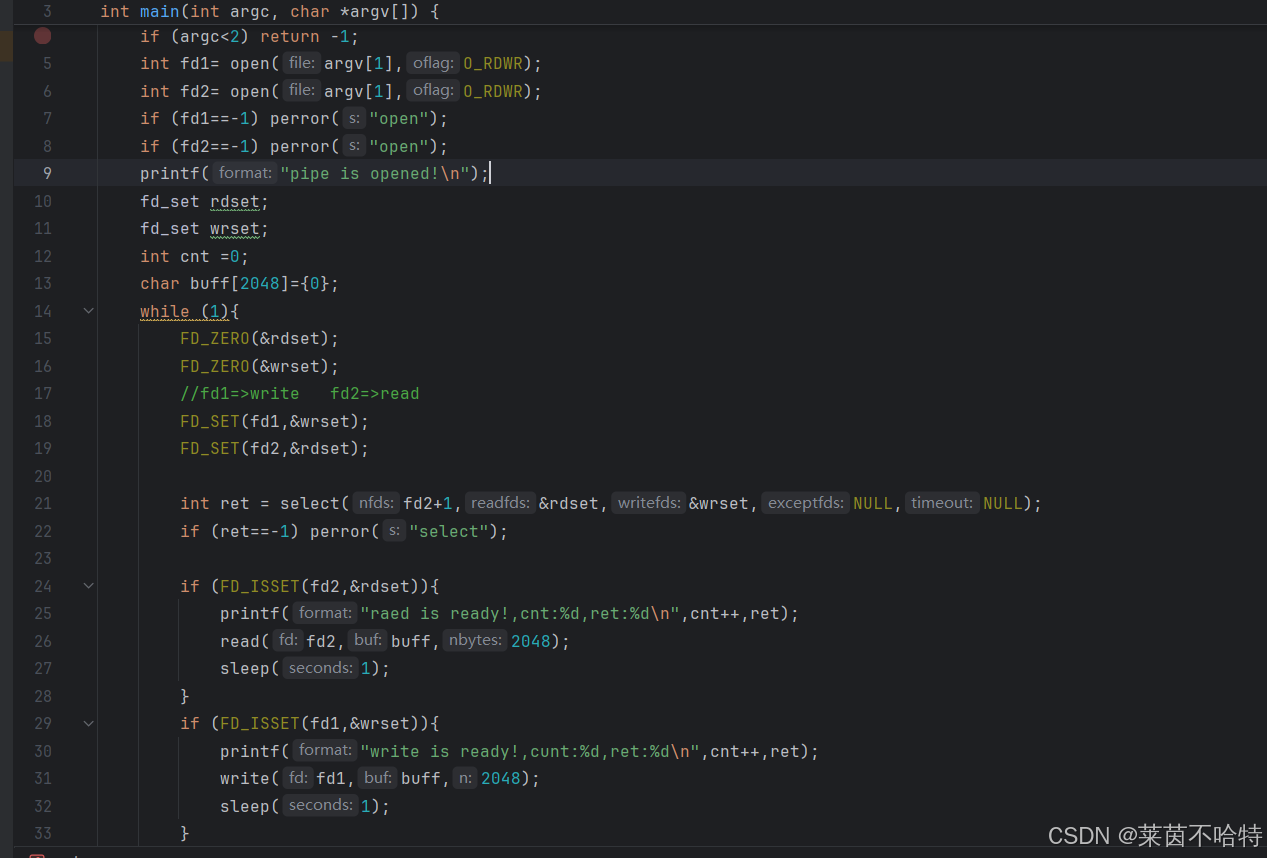
select 函数是一种 I/O 多路复用技术,允许程序同时监视多个文件描述符,检测它们的状态变化,从而高效地管理多个 I/O 操作,而不需要为每个操作创建独立线程或进程。该函数最早出现在 Unix 系统的 BSD 版本中,后被 POSIX 标准采纳,在网络通信和服务器编程中能显著提高并发性能。
使用select函数的前置步骤如下
①使用fd_set类型的集合来监控不同的 I/O 操作(读、写、异常)
上述代码中使用了fd_set类型的集合来监控读和写操作
②FD_ZERO:是一个宏,用于将fd_set集合清空,即将所有文件描述符的状态设置为未选中。
上述代码中的FD_ZERO对读集合和写集合进行了清空
③FD_SET:也是一个宏,用于将指定的文件描述符添加到fd_set集合中。
上述代码中的FD_SET将写文件描述符fd1和读文件描述符fd2分别添加到了写集合wrset和读集合rdset中
④FD_ISSET:是一个宏,用于检查指定的文件描述符是否在fd_set集合中
对于通过 open 以 O_RDWR 模式打开的普通文件,其写操作在以下情况会被 select 判定为 “就绪”
开始调用select函数进行监听
-
select进入内核后,会遍历所有被监控的文件描述符(从 0 到maxfd),逐个检查其对应的 I/O 状态:- 读就绪条件:文件描述符可读(如管道有数据、套接字接收到数据、普通文件非空)。
- 写就绪条件:文件描述符可写(如管道缓冲区未满、普通文件未被锁定、套接字连接正常)。
- 异常条件:发生错误(如连接断开)。
-
阻塞等待
若当前没有任何文件描述符就绪,内核会将进程挂起,直到以下情况发生:- 至少一个文件描述符就绪。
- 超时时间到达(若设置了超时参数)。
- 进程被信号中断。
- 用户程序解析结果
-
select返回后,用户程序通过FD_ISSET检查哪些文件描述符就绪
-
select函数是 Unix/Linux 系统中实现 I/O 多路复用的经典方法,其优缺点如下:
优点
-
跨平台兼容性
支持几乎所有操作系统(如 Linux、Windows、macOS),代码可移植性强。 -
简单易用
通过文件描述符集合(fd_set)统一管理 I/O 事件,接口简洁。 -
同时监控多类事件
可同时监听读、写、异常三类事件,适用于多种场景(如网络通信、管道操作)。 -
无需额外内核资源
内核无需为每个文件描述符维护状态,实现轻量。
缺点
-
文件描述符数量限制
受限于FD_SETSIZE(通常为 1024),无法应对高并发场景。 -
性能随描述符数量下降
采用轮询方式遍历所有文件描述符,时间复杂度为 O (n),效率低。 -
重复初始化集合
每次调用select需重新设置文件描述符集合(FD_SET),增加代码冗余。 -
无就绪事件通知机制
返回后需遍历所有描述符判断就绪状态,无法直接定位就绪事件。 -
普通文件行为特殊
对普通文件的读 / 写检测始终返回就绪(除非磁盘空间满或文件被锁定),导致逻辑误判。
总结与替代方案
- 适用场景:小规模并发、跨平台需求、简单 I/O 监控。
- 替代方案:
poll:基于链表而非固定数组,突破FD_SETSIZE限制。epoll(Linux):采用事件驱动,支持百万级连接,性能更高。kqueue(BSD/macOS):类似 epoll 的高效事件通知机制。
在用户提供的代码中,select始终判定写集合就绪,正是因为普通文件的写操作不会阻塞,导致内核误认为其 “始终可写”。若需处理真实 I/O 设备(如套接字、管道),需结合实际场景设计逻辑。
三、进程的本质:程序的动态化身
1.1 进程 vs 程序
- 程序:静态的二进制文件(如
.elf),存储于磁盘。 - 进程:程序的一次执行实例,具有独立的内存空间、资源和生命周期。
- 类比:程序是菜谱,进程是按照菜谱烹饪的整个过程。
1.2 进程的核心组件
- 进程控制块(PCB):操作系统为每个进程维护的结构体,包含 PID、状态、文件描述符表等。
- 内存空间:分为代码段、数据段、堆、栈四部分。
- 资源:文件描述符、信号处理函数、CPU 时间片等。
2.1 进程的三种基本状态
- 运行态(Running):进程正在 CPU 上执行。
- 就绪态(Ready):进程已准备好运行,等待调度。
- 阻塞态(Blocked):进程因 I/O、信号等事件暂停执行
3 通过不同的案例实现对进程进行阐述
3.1获取当前进程的PID 和 PPID
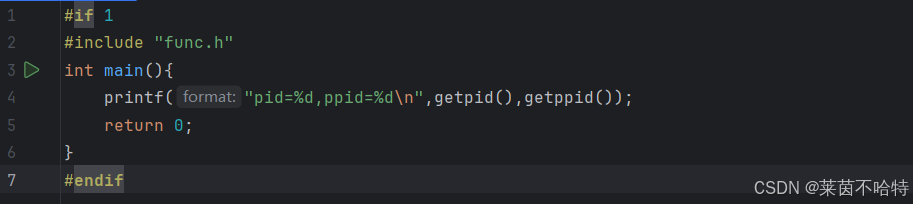
我们通过函数getpid()和getppid()可以获取当前进程和父进程的ID值
3.2 system函数
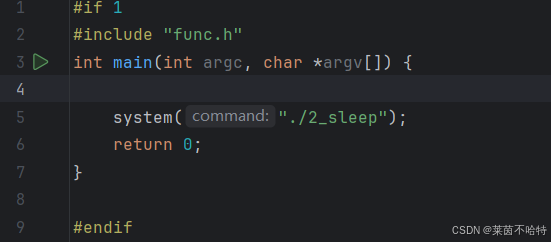
我们可以通过system("可执行文件名");通过调用系统命令执行另一个可执行文件./2_sleep
3.3fork函数
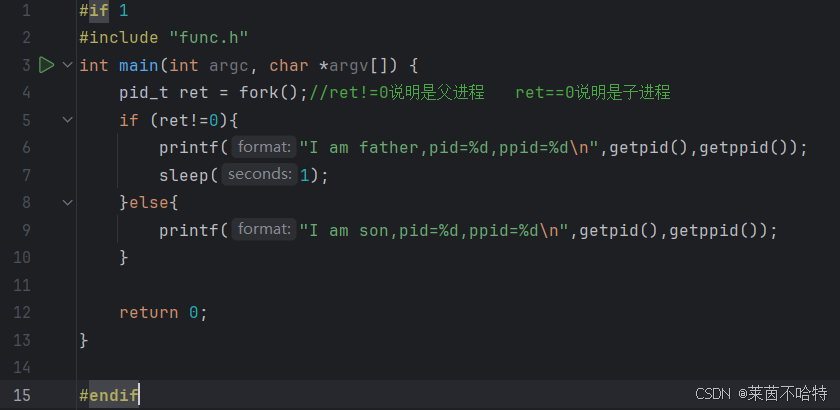
fork 是 Linux/Unix 系统中用于创建子进程的核心系统调用
我们可以通过fork函数的返回值来判断是父进程还是子进程 当fork的返回值是非0说明是父进程
当fork的返回值是0则说明是子进程
3.31于是我们可以用fork进行分流操作 从而对父进程和子进程分别进行操作如下
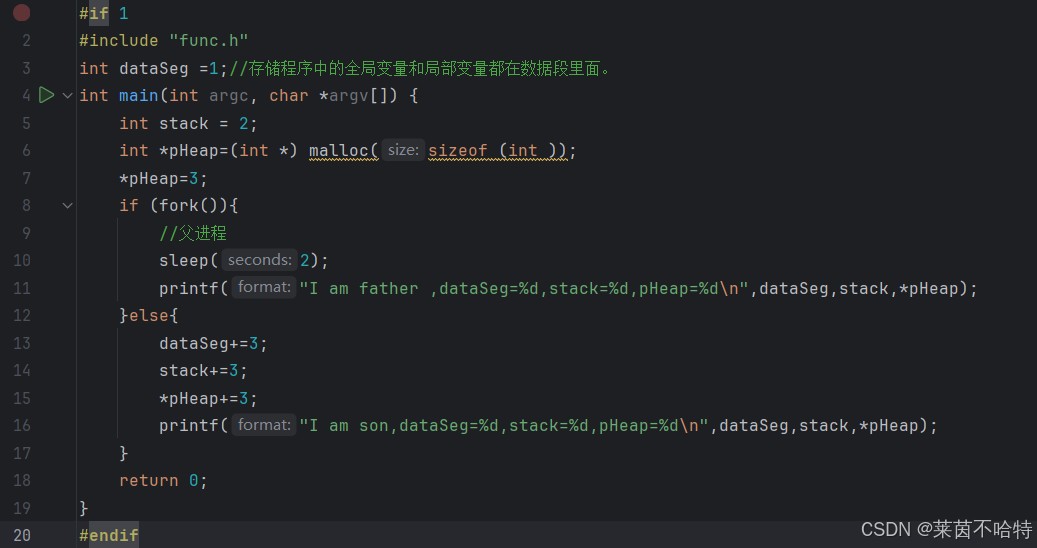
上述代码中分别在全局dataSeg 和 栈区satck 和堆区pheap 分别开辟了内存
父子进程分别对三个数据进行打印输出,父子各自拥有自己的独立空间
看代码里的变量:dataSeg 是全局变量,子进程修改后,自己的数据段变化,父进程没改。stack 是局部变量,在栈区,子进程修改自己的副本。pHeap 指向堆内存,子进程修改 * pHeap,因为写时拷贝,父子的堆空间分开了。
所以最终结果是,子进程修改了这三个变量,而父进程没有,导致输出不同。
3.32接下来是父子进程对文件对象的操作实现不一样的效果 操作如下
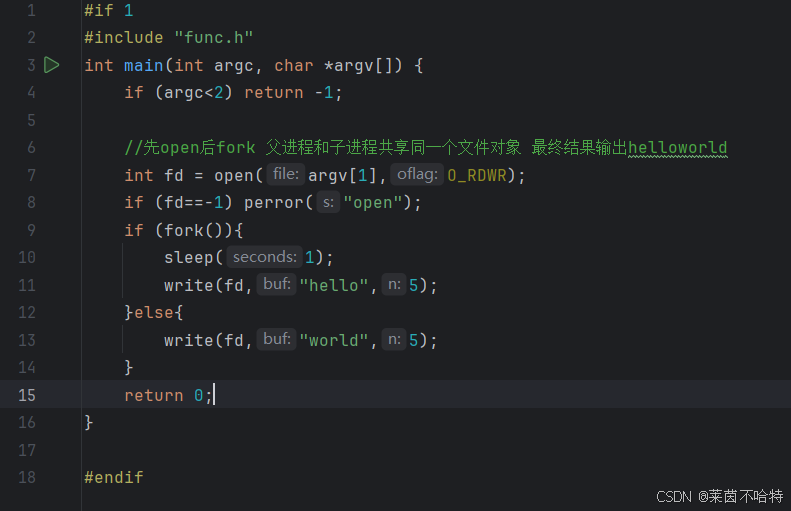
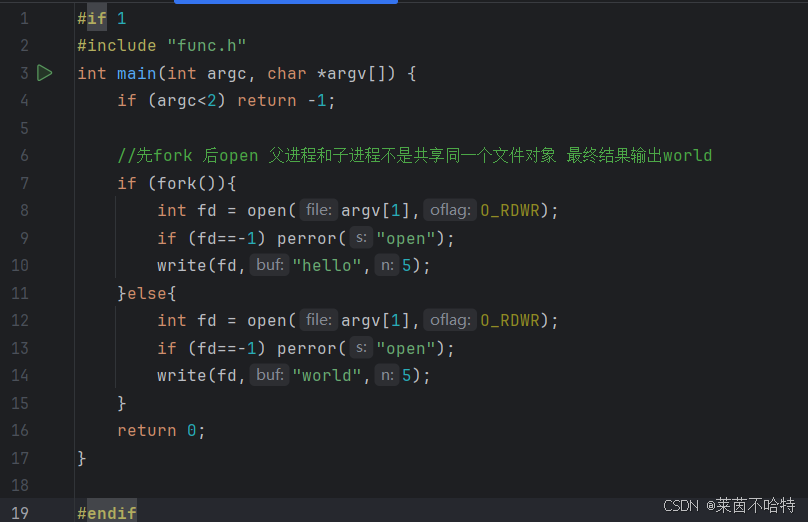
基于上述代码块的实现
情况①:当我们先使用系统调用open再执行fork的时候 父子进程是共享同一个文件对象的最终输入的结果是helloworld
情况②当我们先执行fork再使用系统调用open的时候,父子进程不是共享同一个文件对象后一个进程输入的结果会把前一个进程输入的结果覆盖
3.4execl和execv函数
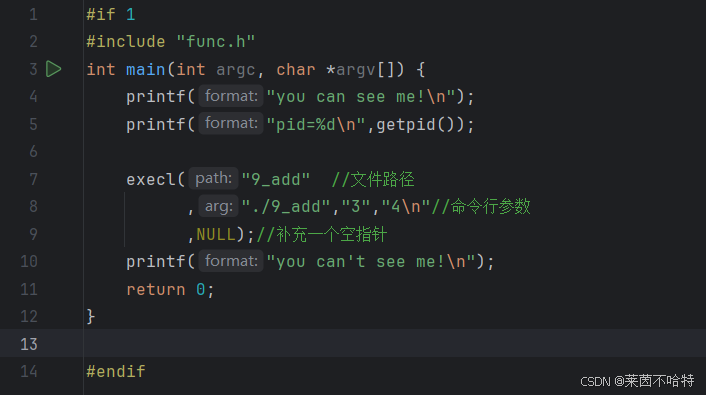
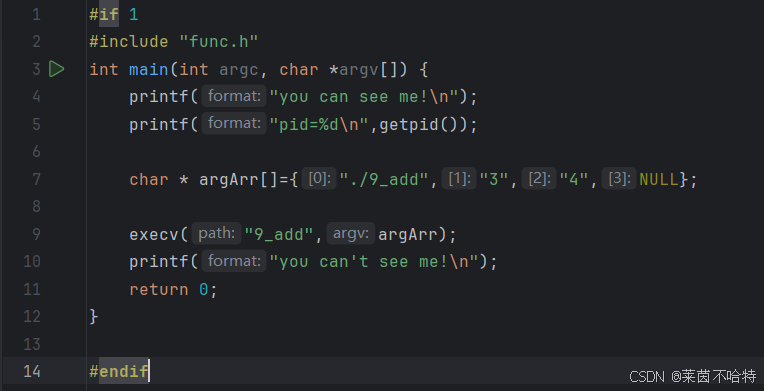
在 Linux 系统编程中,execl和execv是exec函数族中的两个函数,它们的作用是用指定的程序替换当前进程的正文、数据、堆和栈段,也就是在当前进程中执行一个新的程序。
上述两片代码段分别调用了execl 和 execv函数的效果是一样的 相当于对./9_add可执行文件进行了类似修仙小说里面的夺舍操作
3.5 wait函数
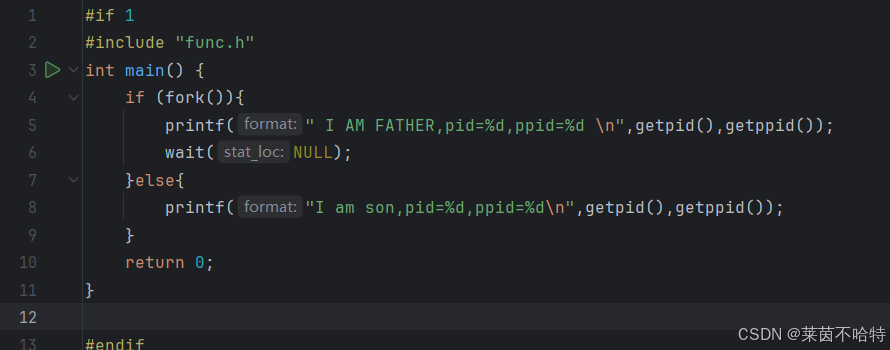
在 Linux 系统编程中,wait 函数是进程控制的重要工具,用于父进程等待子进程终止并回收资源,避免僵尸进程。
3.6 孤儿进程
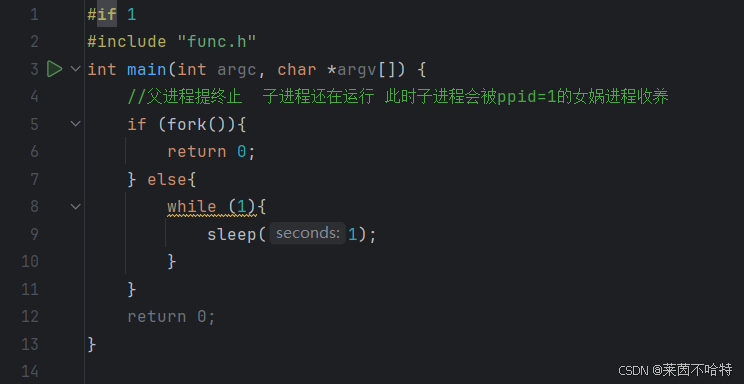
当我们执行上述代码段的时候 父进程会提前终止 导致子进程没有了父亲 成为了孤儿进程 最后子进程会被ppid=1的进程收养。
3.7 僵尸进程
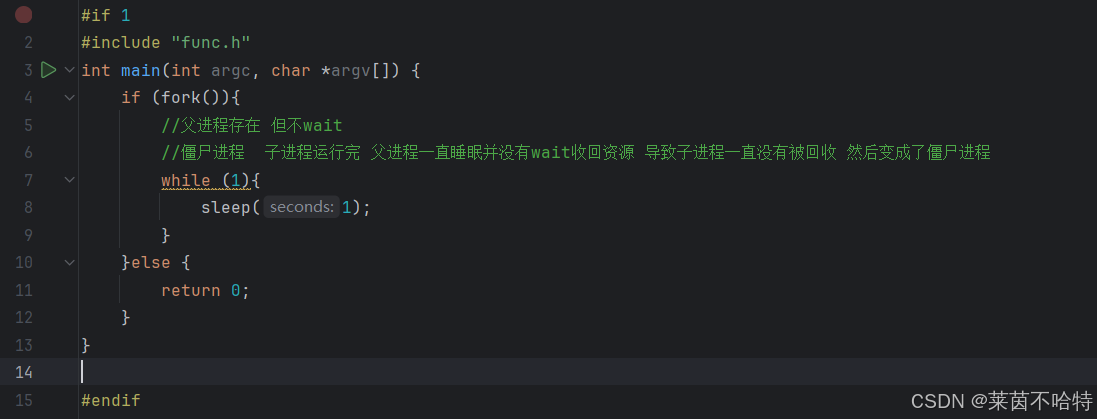
当我们执行上述代码块的时候 子进程运行完 而父进程一直睡眠 没有调用wait函数收回资源 会导致子进程一直没有被回收 最后变成了僵尸进程 大量的僵尸进程会大量占用资源 所以我们要在使用结束进程的时候一定要及时调用wait函数回收进程以免资源的浪费。
3.8WIFEXITED 等宏的用途
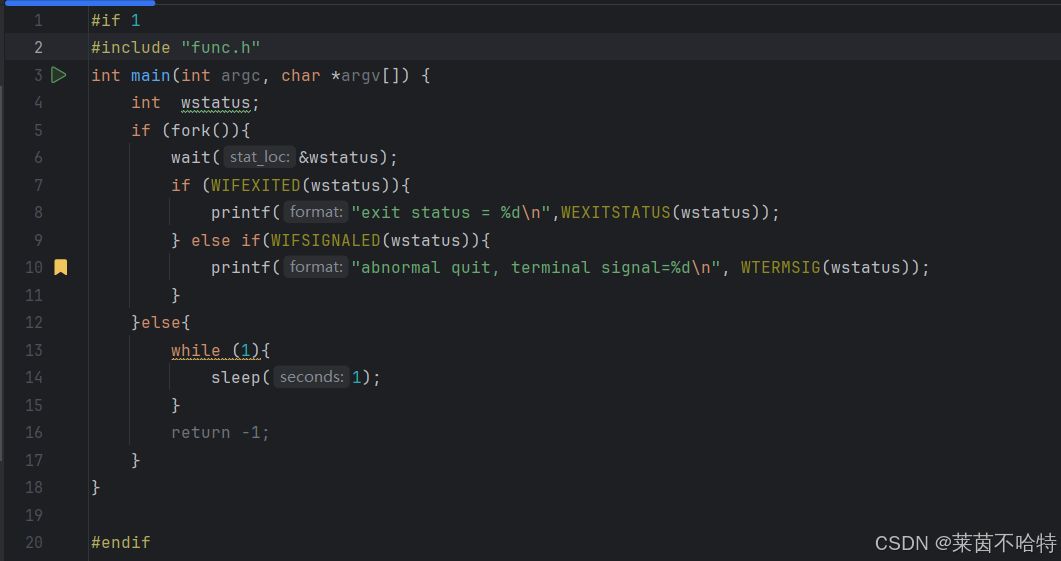
若子进程正常退出,通过 WIFEXITED(wstatus) 解析退出码;若因信号终止,通过 WIFSIGNALED(wstatus) 解析终止信号。
3.9 exit函数和_exit函数
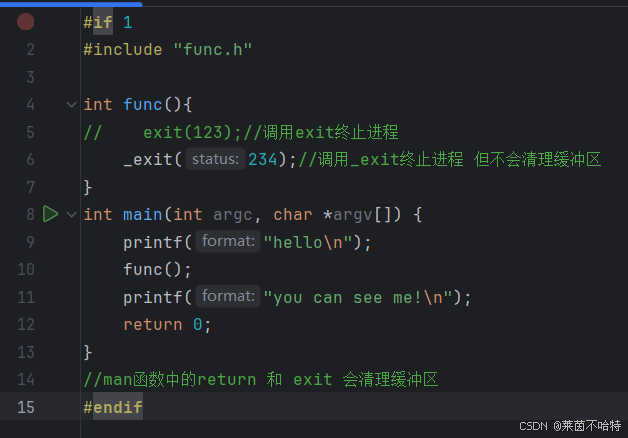
我们可以通过return 和 exit 和_exit 来终止程序的运行
区别:main函数中的return 和 exit 会清理缓冲区 而_exit则不会清理缓冲区
3.10 abort函数
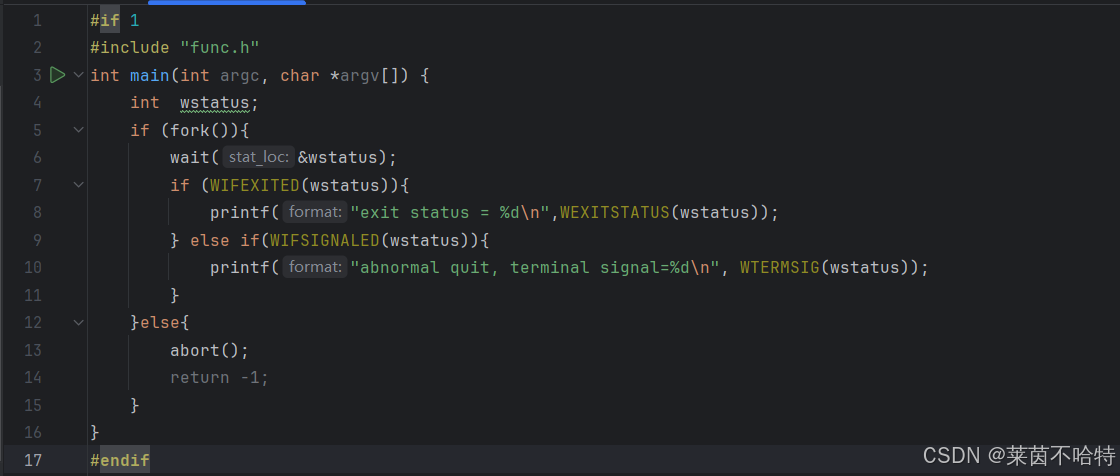
在上述代码中 父进程会等待子进程的结束 并打印子进程的结束信息
我们上述代码中调用了abort()杀死子进程
3.11 getpgid函数
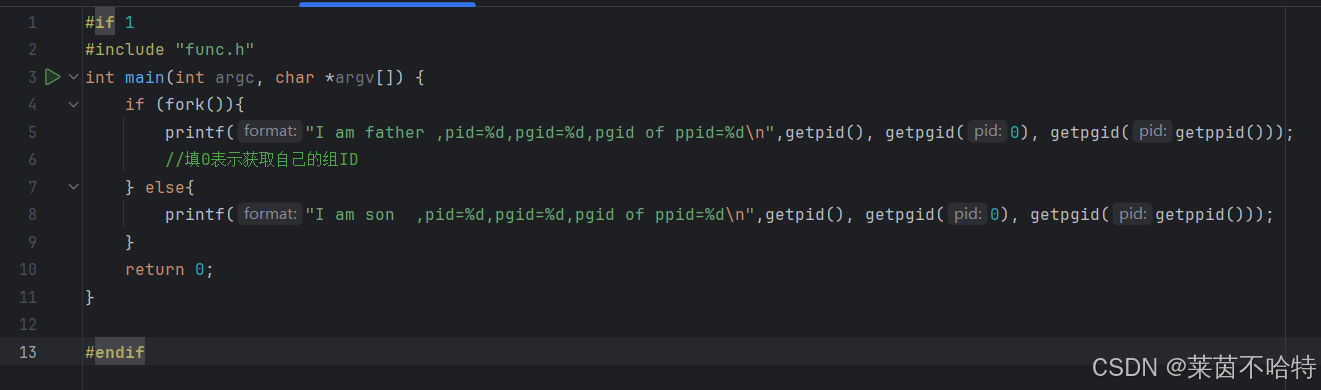

进程组:进程的集合
getpgid()函数的调用填0可以获得自己的组ID
想获取父进程的组ID可以在getpgid()中输入getppid()
最终显示的结果表面了 子进程和父进程属于同一个组的
3.12 setsid函数
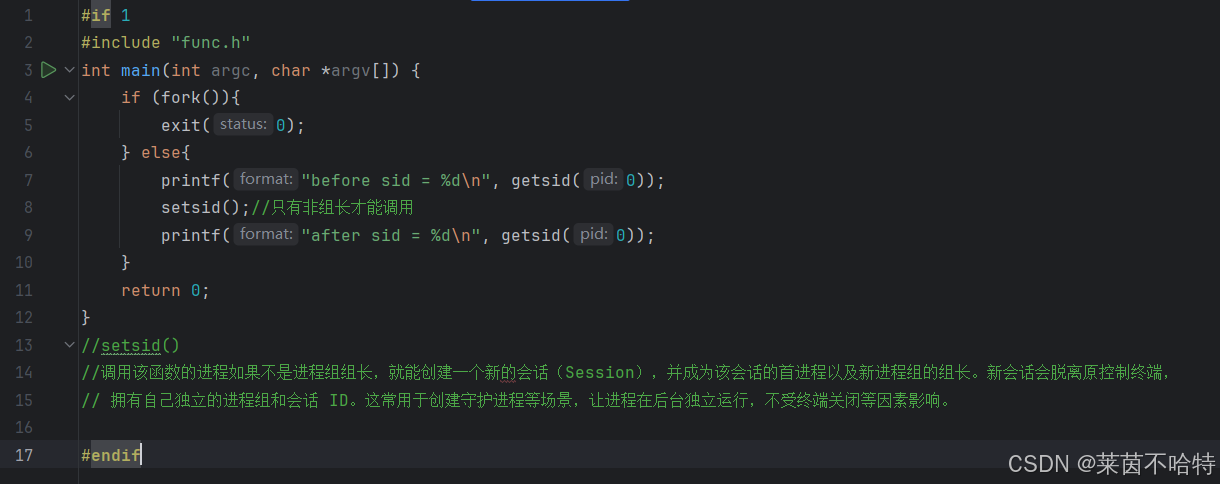
会话:进程组的集合
setsid函数的调用:如果调用该函数的进程不是进程组长,就能创建一个新的会话(session),并成为该会话的首进程以及新进程组的组长。新会话会脱离原控制终端,拥有自己独立的进程组和会话ID。
这常用于创建守护进程等场景,让进程在后台独立运行,不受终端关闭等因素影响。
3.13 守护进程
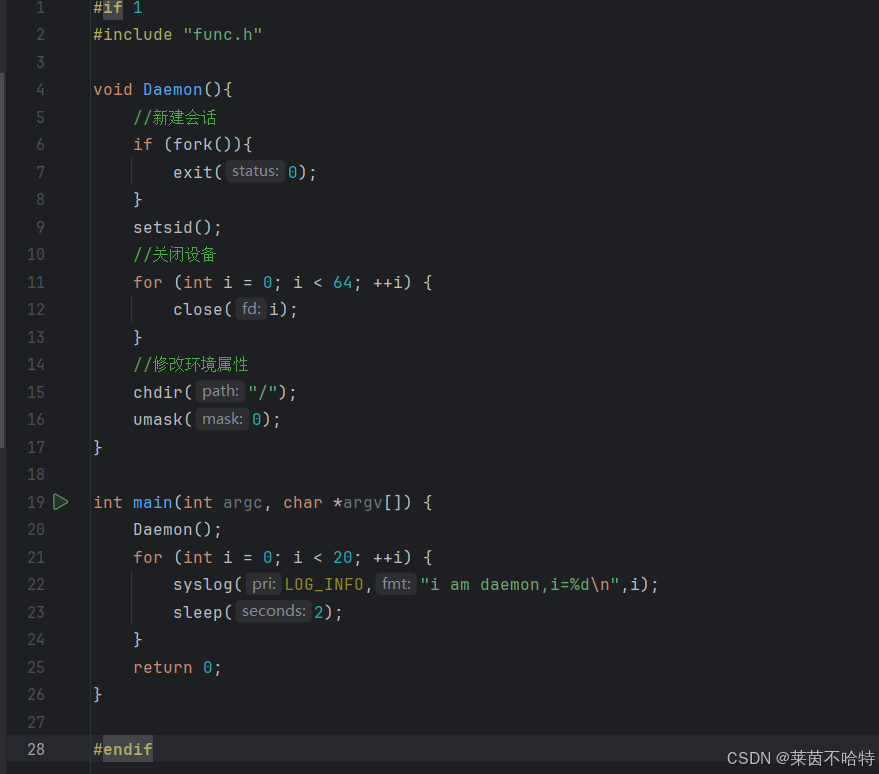
我们通过上述代码的实现把该进程从本终端分离了出来从而达到了守护进程的目的
守护进程拥有以下特点
无终端关联:不依赖终端输入 / 输出,避免被终端信号中断。
生命周期长:通常随系统启动而运行,直到系统关闭。
独立会话组:通过setsid()创建新会话,脱离父进程的控制终端。
工作目录固定:常切换到根目录/,防止挂载点被卸载。
3.14 popen函数和pipe函数 通过管道实现进程间的通信
popen情况①
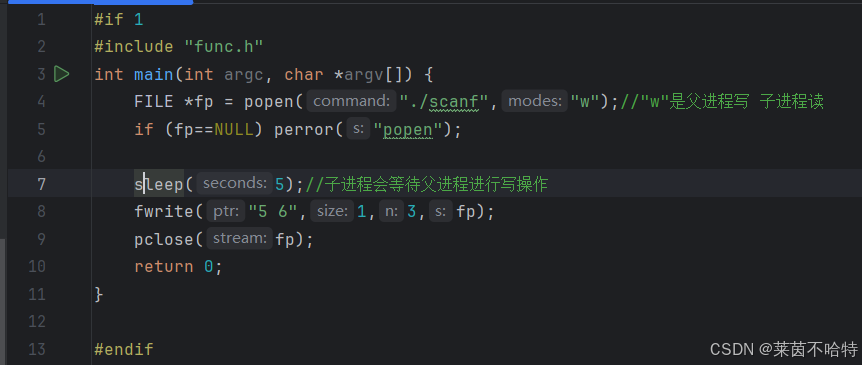
对于popen的属性设置是"w" 代表父进程写 子进程读
popen情况②
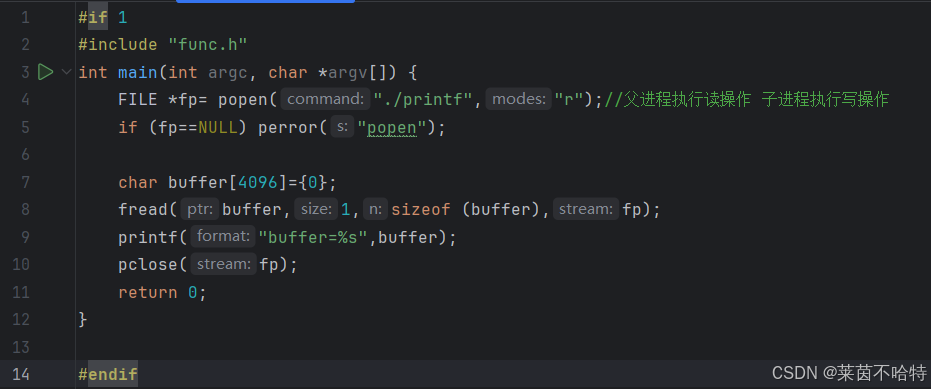
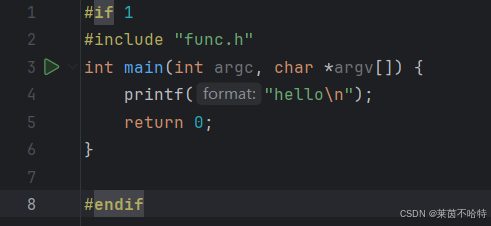
对于popen的属性设置是"r"代表了父进程执行读操作 子进程执行写操作
pipe情况①
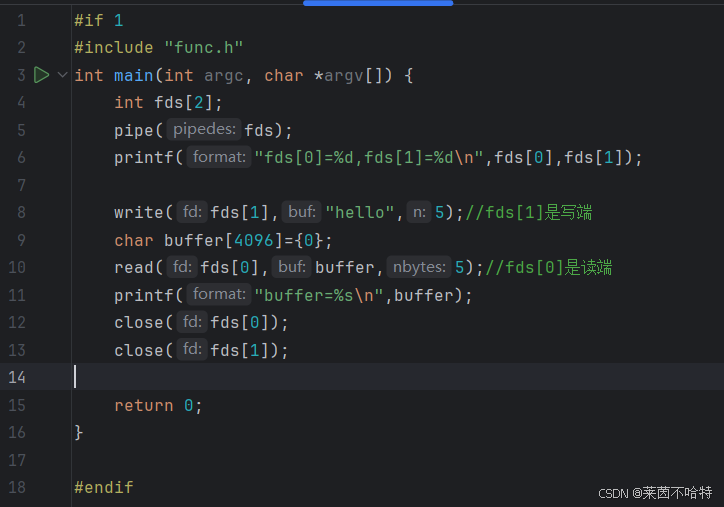
用户申请一个长度为2的数组
创建两个文件对象(管道)
①fds[1] 是写端
②fds[0]是读端
通过写端写入数据 再通过读端读出数据
pipe情况②
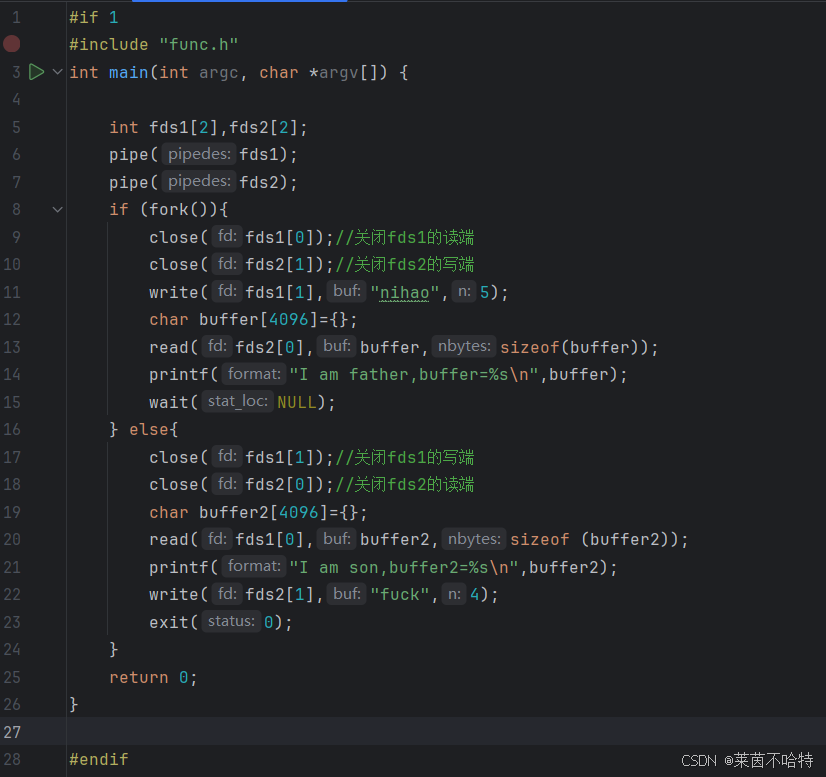
通过两根管道将半双工通信改成了单工通信
总结:管道利用了阻塞从而实现了同步
管道由内核直接管理,数据传输在内核态完成,无需用户态复制,减少了上下文切换开读写操作自动同步,无需额外加锁。
优点
-
。单向通信,简单易用
半双工特性(单向传输)适合 “生产者 - 消费者” 场景,例如父进程发送指令给子进程。无名管道仅需pipe()系统调用即可创建,代码简洁。 -
进程间强关联性
无名管道仅适用于有亲缘关系的进程(如父子进程),天然保证通信安全性,避免无关进程干扰。 -
数据流式传输
数据以字节流形式传输,无需格式化,适合连续数据传输(如日志、命令输出)。 -
资源自动回收
管道生命周期与进程绑定,进程退出后自动销毁,无需手动释放资源。
缺点
-
单向通信限制
半双工特性导致双向通信需创建两个管道,增加复杂度。 -
适用范围有限
无名管道仅支持亲缘进程间通信,无法跨主机或无关联进程。命名管道(FIFO)虽支持无亲缘进程,但仍无法跨网络。 -
缓冲区容量限制
内核为管道分配固定大小的缓冲区(通常为 64KB),若写入数据超过容量,写操作会被阻塞,可能引发性能问题。 -
数据无边界性
字节流特性导致接收方无法区分消息边界,需自行设计协议(如添加长度头)。 -
无法随机访问
数据只能顺序读写,不支持 lseek 等随机访问操作。 -
阻塞语义
读空管道或写满管道时默认会阻塞,可能导致死锁(需配合非阻塞标志使用)。
-
适合场景
- 简单父子进程通信(如 shell 命令
ls | grep)。 - 流式数据传输(如日志处理、实时监控)。
- 需要内核级同步的轻量级 IPC。
- 简单父子进程通信(如 shell 命令
-
不适合场景
- 双向通信或复杂协议。
- 无亲缘关系进程或跨主机通信。
- 需要数据持久化或随机访问。
3.15 共享内存最快的IPC通信机制 shmget函数
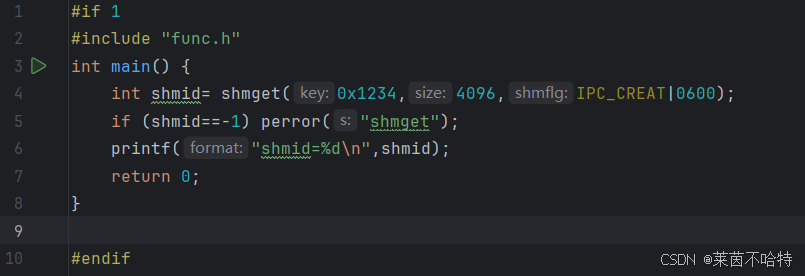
上述代码块创建了一片键为0x1234 大小为 4096 权限为0600 共享内存块
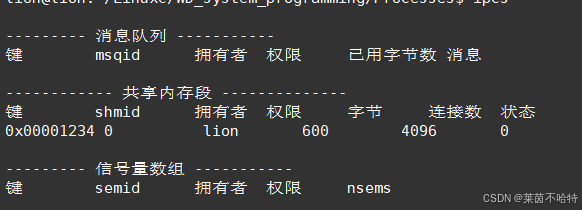
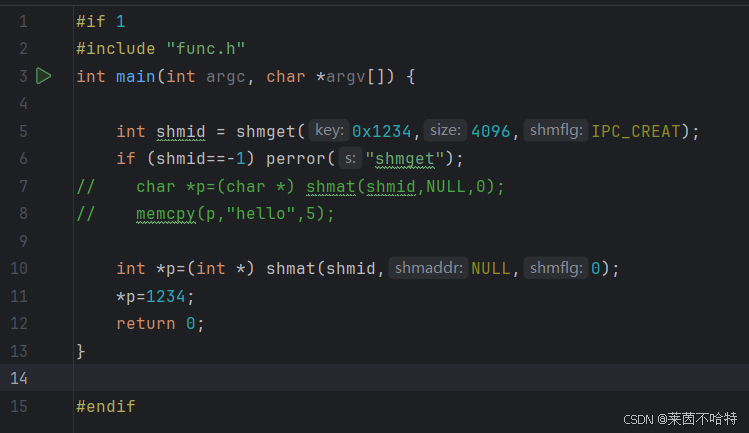
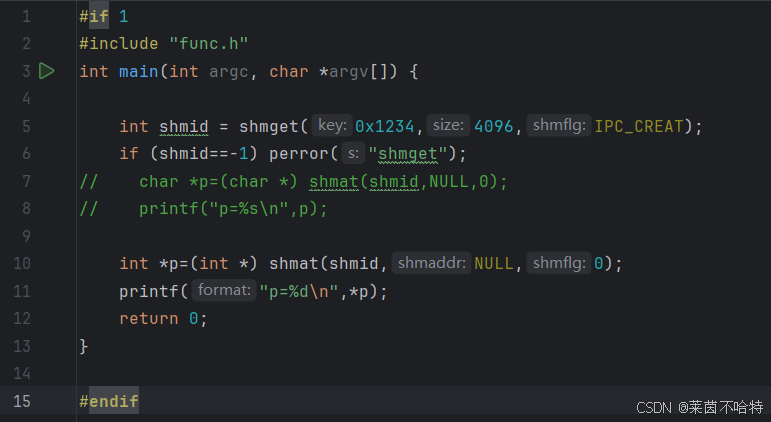
两个进程分别对该共享内存进行读和写操作 从而实现了进程在共享内存之间的通信
共享内存有以下优点和缺点
优点
-
高性能数据传输
数据直接在内存中共享,无需内核缓冲区复制(如管道或消息队列的开销),适合大数据量或高频通信场景。读写速度接近内存访问速度,比其他 IPC 机制快 1-2 个数量级。 -
双向通信支持
允许多个进程同时读写同一块内存,天然支持双向通信,无需像管道那样创建多个通道。 -
灵活的数据结构
可共享任意复杂数据结构(如结构体、数组、链表),无需序列化 / 反序列化,适合复杂应用场景。 -
跨进程无限制
共享内存可被任意进程(无论是否有亲缘关系)访问,只需知道其键值(Key)或 ID。 -
内核级资源管理
-
共享内存由内核统一管理,支持动态调整大小(通过
shmctl()),并在所有进程 detach 后自动销毁。
缺点
-
同步机制复杂
多个进程并发访问时需手动实现同步(如互斥锁、信号量),否则易引发竞态条件(Race Condition)。同步机制的性能可能抵消共享内存本身的优势。 -
生命周期依赖进程
共享内存段只有在最后一个进程 detach 后才会被销毁,若进程崩溃可能导致内存泄漏(需内核干预或ipcrm手动删除)。 -
权限与安全性风险
共享内存的访问权限由文件模式(如0666)控制,若设置不当可能被未授权进程篡改数据。不支持细粒度权限控制(如读写分离)。 -
跨主机不可用
共享内存是单机内存资源,无法直接用于跨主机通信(需结合套接字等网络机制)。 -
内存碎片问题
频繁创建 / 销毁共享内存可能导致内核内存碎片化,影响性能(需系统重启恢复)。
3.16进程间的信号通信(Signal Communication)
-
信号本质
- 信号是内核向进程发送的异步通知(类似硬件中断),用于指示特定事件(如程序错误、定时器超时、用户中断等)。
- 每个信号有唯一编号(如
SIGINT=2,SIGKILL=9)和默认行为(如终止进程、忽略、暂停等)。
-
通信机制
- 发送信号:通过
kill()、raise()、alarm()等系统调用或命令(如kill)发送信号。 - 接收信号:进程通过
signal()或sigaction()注册信号处理函数,自定义响应逻辑。
- 发送信号:通过
信号属于软件层面的事件机制
以下是Linux系统中的信号种类
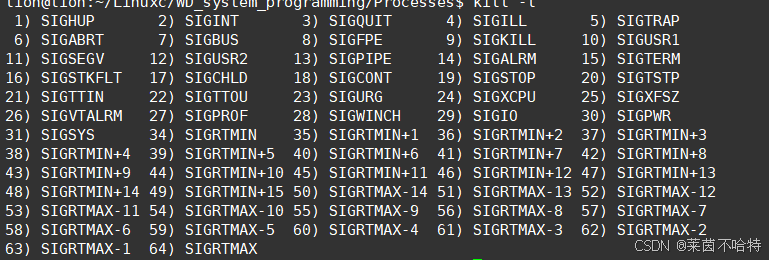
我们从图里的信号里挑常见的。比如 SIGINT、SIGKILL、SIGTERM、SIGCHLD、SIGSTOP 这些。每个信号要讲编号、作用、默认处理、应用场景。现在组织内容:
SIGINT(2):中断信号,用户按 Ctrl+C,默认终止进程,比如终止前台程序。
SIGKILL(9):强制终止,无法捕获忽略,处理僵死进程。
SIGTERM(15):常规终止,程序可自定义处理,优雅退出。
SIGCHLD(17/18/20):子进程状态变化,父进程回收资源,避免僵尸。
SIGSTOP(19):暂停进程,配合 SIGCONT 恢复,调试用。
3.17signal函数
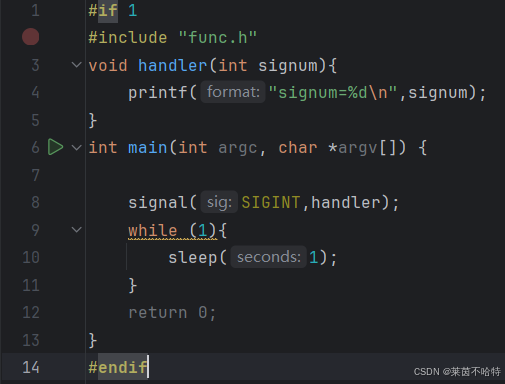
signal 是 C 语言中用于设置信号处理方式的函数,在 Linux/Unix 系统编程中用于管理进程对信号的响应
signum:指定信号编号(如 SIGINT、SIGTERM)。
参数①:信号的种类
参数②:回调函数
通过调用回调函数handler来打印信号的编号
3.18我们通过信号的阻塞来判断mask屏蔽集合来pending未决集合
以下是同种类型的信号
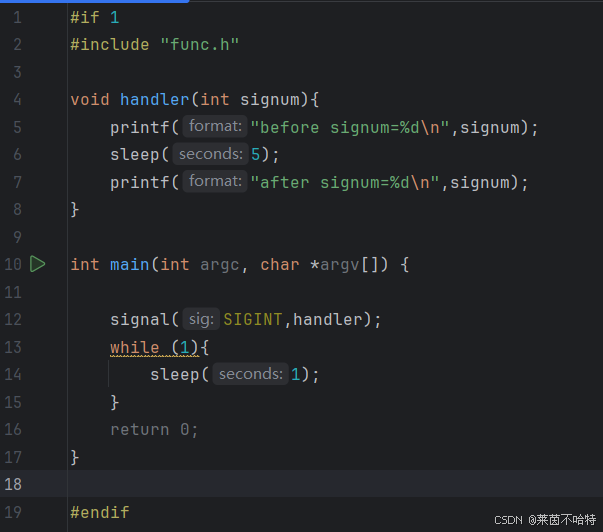
上诉代码通过while(1)的死循环从而造成了阻塞 我们在程序运行的过程中可以输入ctlr+c从而打印信号的编号
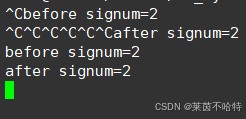
由于我们刚开始输入了ctrl+c导致 2号信号进入了 mask屏蔽集合中
当我们再次输入ctrl+c的时候由于mask屏蔽集合中已经有了2号信号 所以2号信号会加入到未决集合pending当中
直到mask屏蔽集合中的2号信号消失 未决集合中的二号信息则会加入到屏蔽信号mask集合之中
最后执行完最后一个2号信号 屏蔽集合中就没有数据 恢复到阻塞状态之中
接下来我们实现不同类型的信号从而探索屏蔽集合和未决集3.193合之间的关系
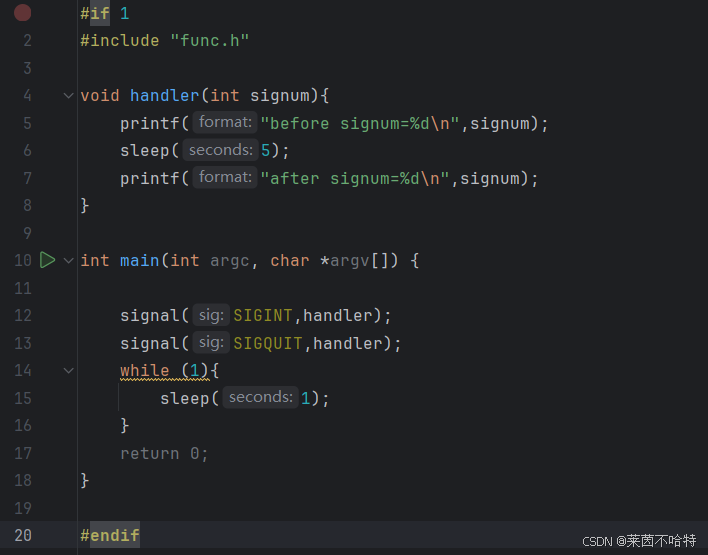

由输出结果我们可以知道 我们刚开始输入了ctrl+c 产生了2号信号加入到了屏蔽集合mask当中
后面我们输入了ctrl+\ 产生了3号信号加入到了屏蔽集合当中
由于我们信号的产生也遵循栈的一个结构 后加入的3号信号 则会先出来
所以先处理了3号信号 再处理了2号信号 最后再重新陷入了阻塞的一个状态!
3.19我们介绍一种能够判断该信号是否在未决集合中的函数sigpending
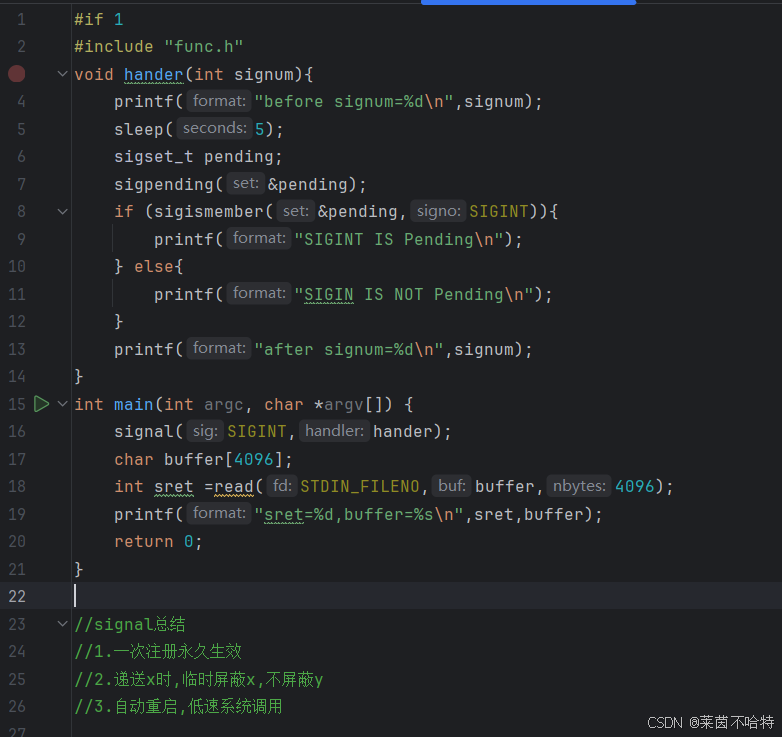
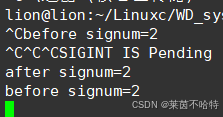
由输出结果我们可以了解到,我们可以将SIGINT信号加入到pending中可以判断SIGINT信号是否在未决集合中。
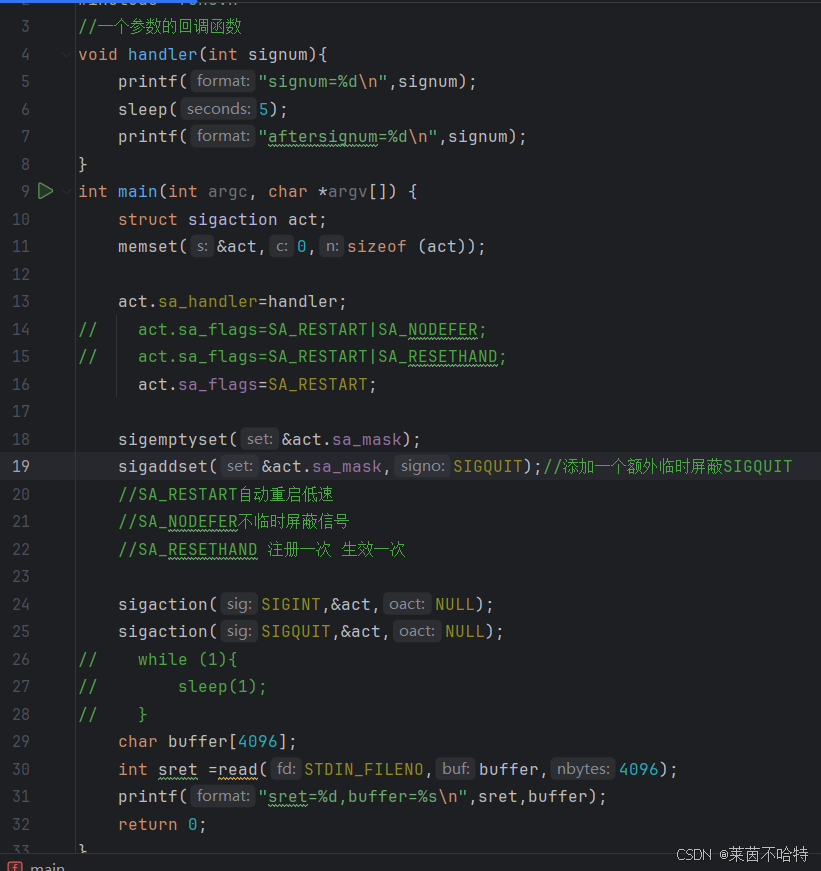
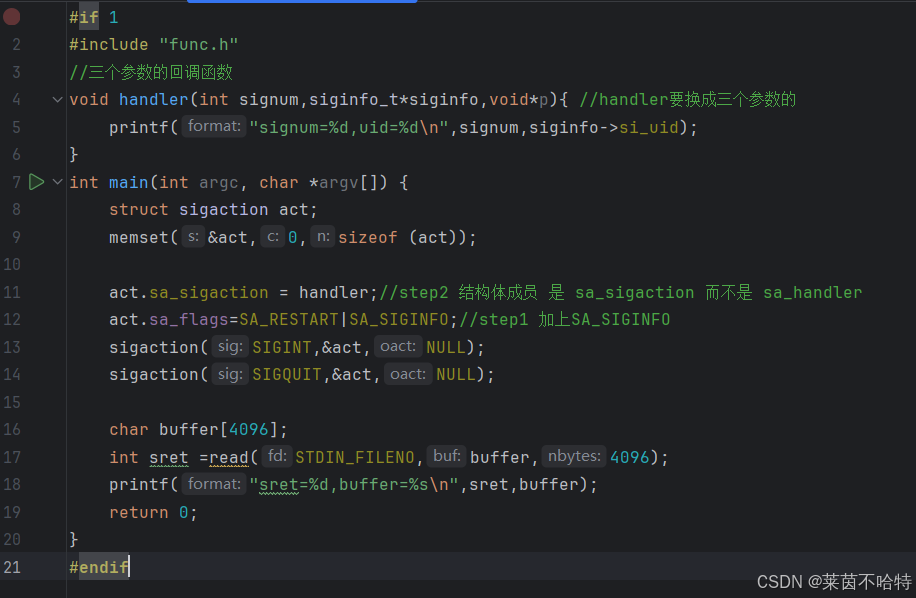
3.20 sigaction函数
sigaction 是 Linux/Unix 系统中用于更精细控制信号处理的函数,相比 signal 更可靠,支持更多高级特性,但使用起来也比signal更加复杂
①一个参数的回调函数
②三个参数的回调函数
③sigpending 获取pending集合
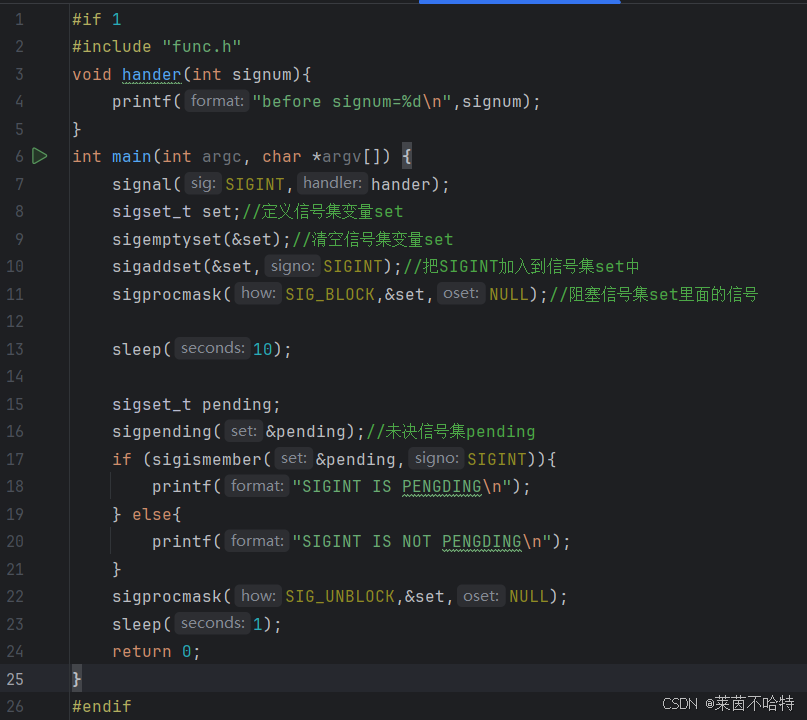
sigaction函数不多赘述 UU们需要自行深入的话 可以多翻阅书籍资料哦
3.21 kill函数
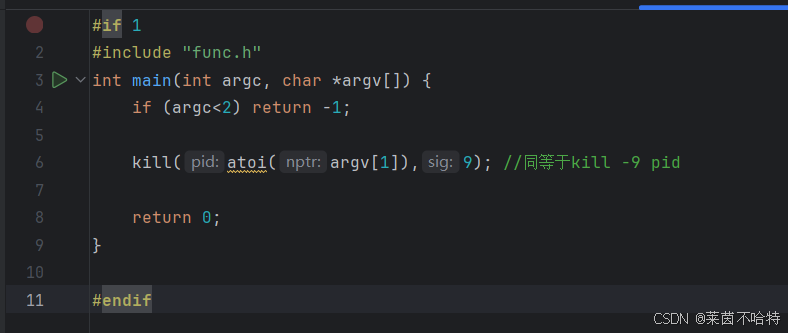
调用上述代码中的kill函数的实现相当于在Linux系统中输入 kill -9 pid 从而对进程进行杀死
3.22 alarm函数
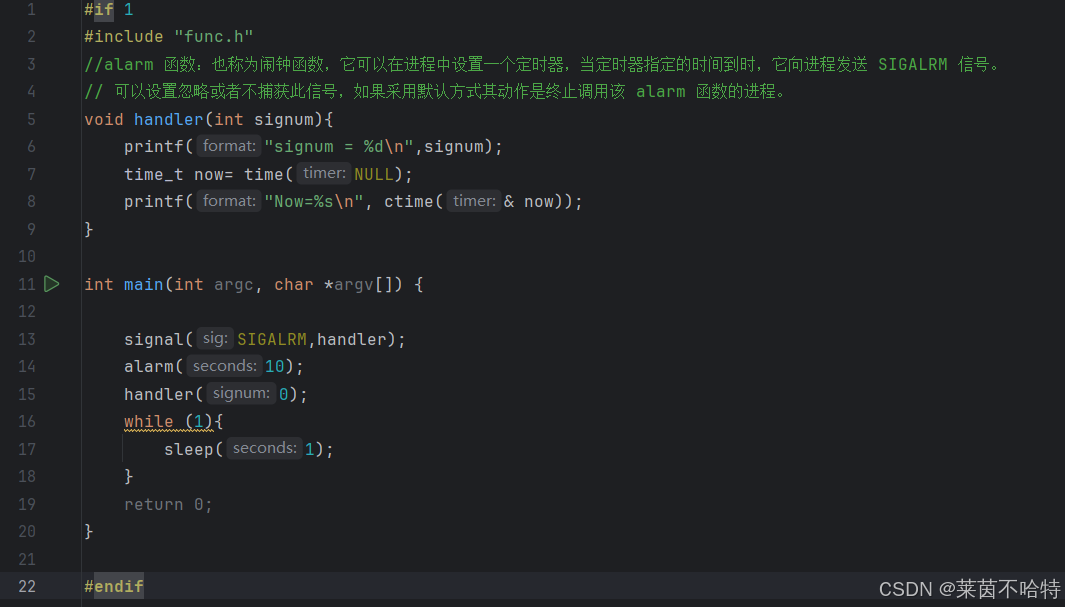
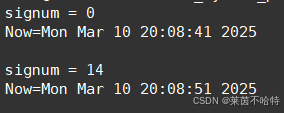
handler函数中的参数设为0 从而先调用一次回调函数 获取当前时间
alarm中的参数设为10 代表10秒后 给进程发送SIGALRM信号调用回调函数打印当前的时间
3.23 pause函数
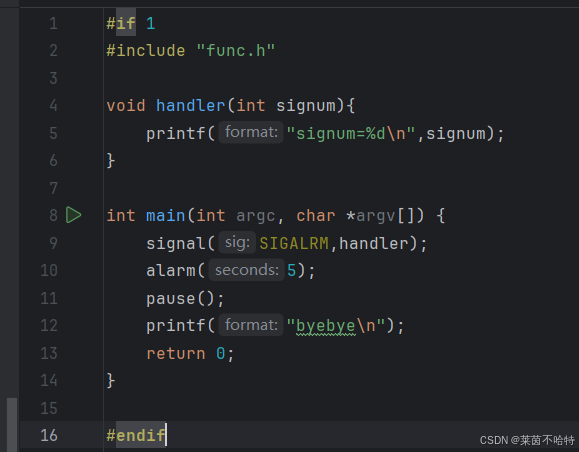
我们通过pause函数和alarm函数之间的配合可以达到一个阻塞的目的
代码段中在pause函数调用前 设置了一个五秒的闹钟也就是 alarm(5),
当五秒钟结束之后也就解除了阻塞状态了。
3.24 setitimer函数
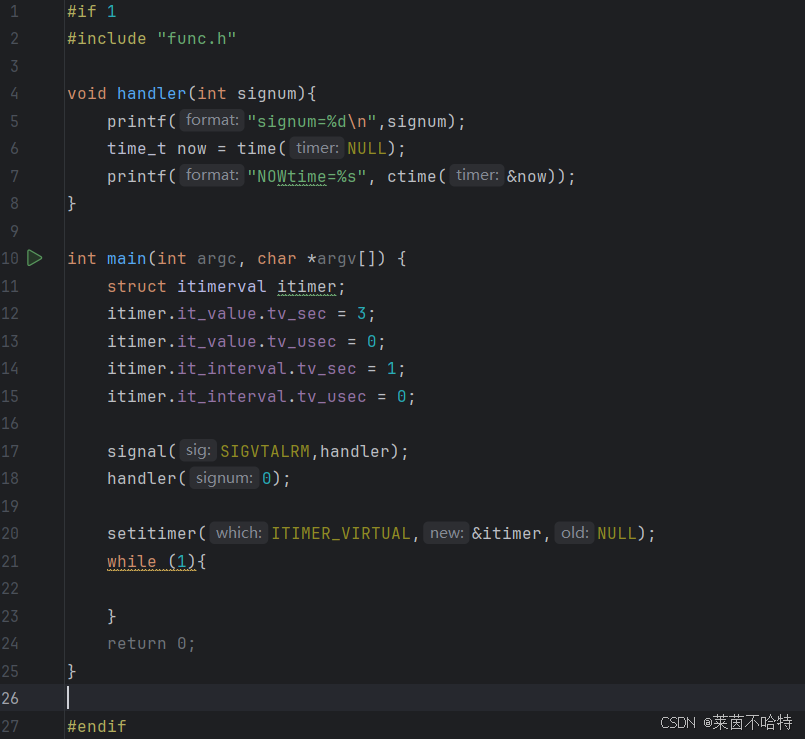
setitimer 是 Linux/Unix 系统中用于设置定时器的函数,可替代传统 alarm 函数,支持更灵活的定时模式
3.25 信号的总结
信号的最明显的特点是一次注册 永久生效
信号这章节对我们最重要的是signal函数 以及 mask屏蔽集合 和 pending未决集合 需要我们牢牢掌握
四.深入理解线程:从基础到高级应用
1.线程与进程的本质区别
线程是进程内的最小执行单元,共享进程内存空间和资源,但拥有独立的栈空间和上下文。与进程相比:
资源共享:线程间通过全局变量直接通信,无需复杂 IPC
调度开销:线程切换仅需保存寄存器和栈指针(1-10μs),进程切换需完整上下文保存(100-1000μs)
独立性:线程崩溃可能导致整个进程终止,进程间则完全隔离
2.线程实现的三种模式
用户级线程(ULT)
由编程语言或库管理(如 Java 线程、Go 协程)优点:调度灵活,适合 CPU 密集型任务缺点:单线程阻塞导致进程挂起
内核级线程(KLT)
由操作系统内核直接调度(如 Linux pthread)优点:支持多核并行,线程阻塞不影响其他线程缺点:调度策略由内核控制
混合模式
典型实现:Linux 的 NPTL(Native POSIX Thread Library)优势:通过内核线程池优化调度效率
3.线程同步机制实战
互斥锁(Mutex)
作用:确保临界区同一时间只有一个线程访问实现方式:通过锁的加锁 / 解锁操作控制访问
读写锁(Read-Write Lock)
优化场景:允许多个读线程并发访问,写线程独占
条件变量(Condition Variable)
用途:线程间协作等待特定条件满足(如任务队列非空)
信号量(Semaphore)
功能:控制同时访问资源的线程数量(如数据库连接池管理
4.线程编程常见陷阱
死锁预防
策略:按顺序加锁、设置超时机制、使用非阻塞锁
竞态条件处理
解决方案:原子操作、无锁数据结构设计
线程安全函数
最佳实践:避免使用非异步安全函数,优先使用 pthread 特定 API
5.线程方方面面的应用情况
5.1线程的创建 pthread_t 与 pthread_create
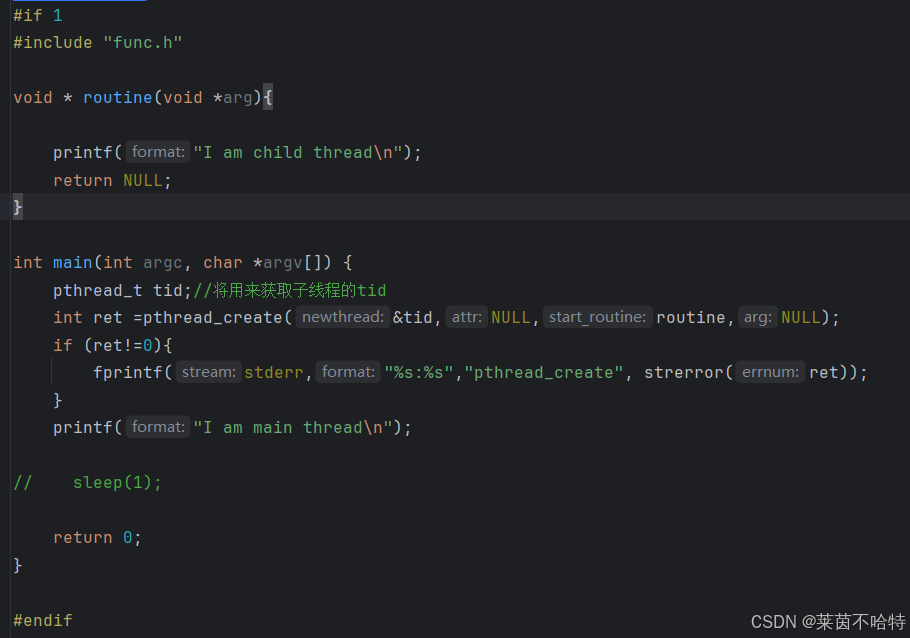
我们通过pthread_t tid ;用来获取子线程的ID
通过pthread_create 创造该线程的ID 和 属性 以及回调函数 和 传入的参数
此处代码块中的线程属性默认是NULL
5.2 我们编写两个while(1)死循环可以达到线程创建的最大值
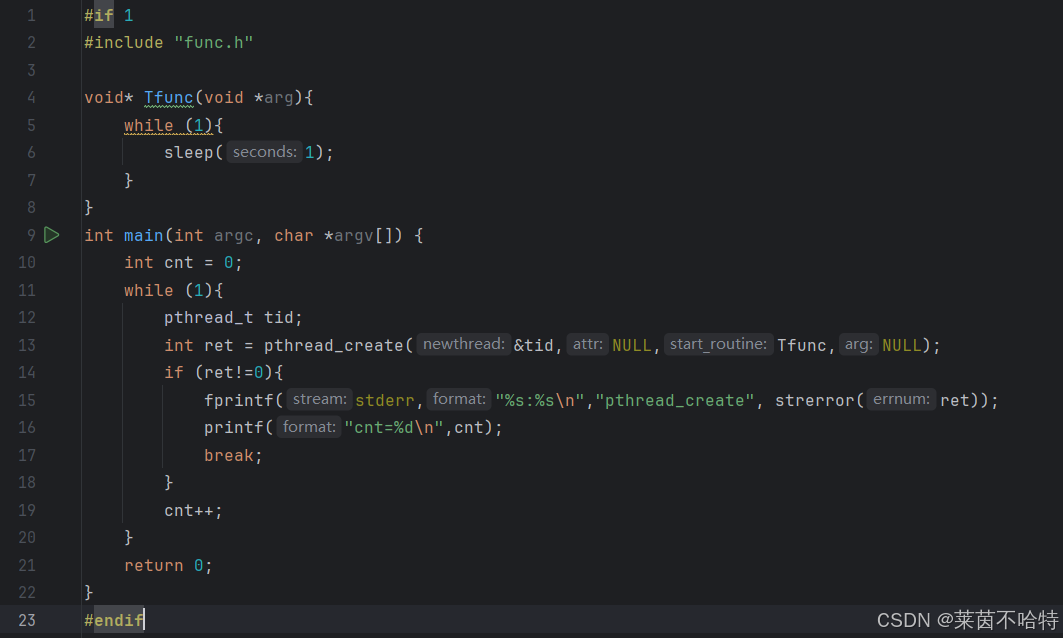

代码块中我们引入了新的报错检测 线程的报错检测机制要用线程专属的报错检测机制哦
解析代码作用:创建线程失败时,输出错误信息。现在组织回应,解释代码功能、各部分作用
fprintf 往 stderr 输出,用 strerror 将 ret 转成错误信息,显示函数名和错误描述。
结果表面 我们一共创建了20277个子线程 最后发送了报错信息 Resource temporarily unavailable
5.3不同的线程对全局变量的共享访问
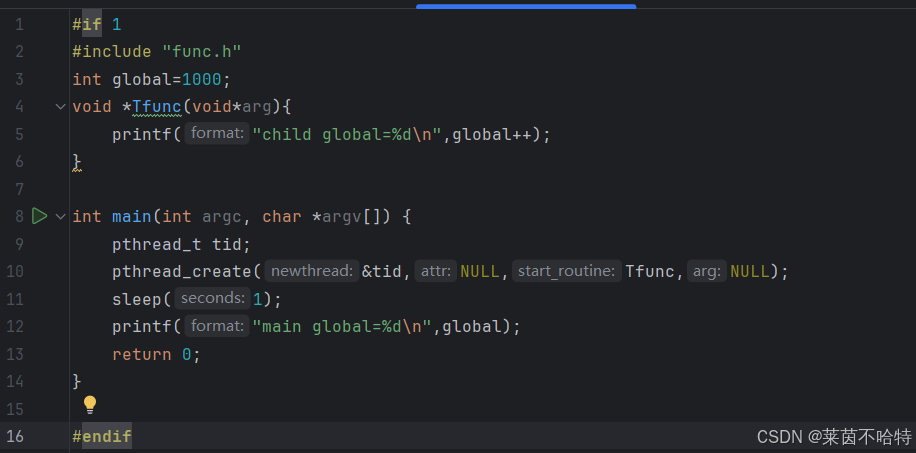
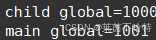
此处的global是全局变量 对于我们 main主线程 和 tid 子线程是共享的
5.4不同线程对堆heap上的数据的共享访问
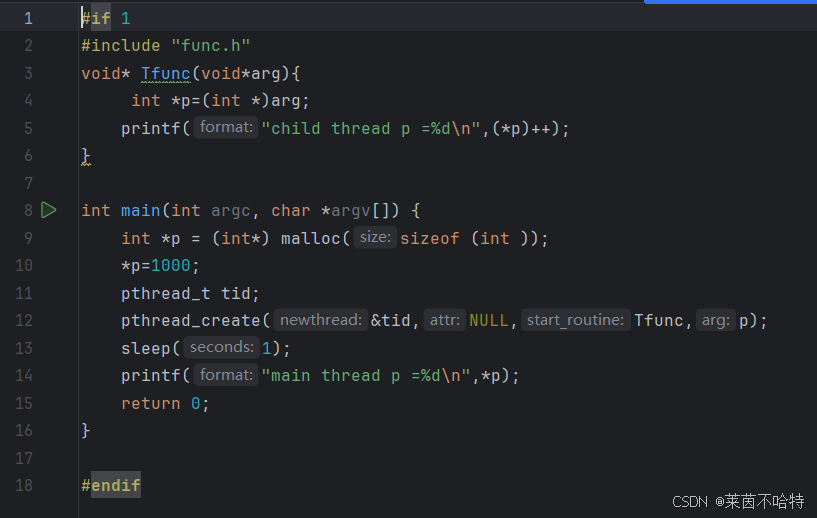

此处的p的内存是开辟在堆上面的 对于我们main主线程 和tid子线程来说都是共享资源
5.5不同线程对栈stack上的数据的共享访问
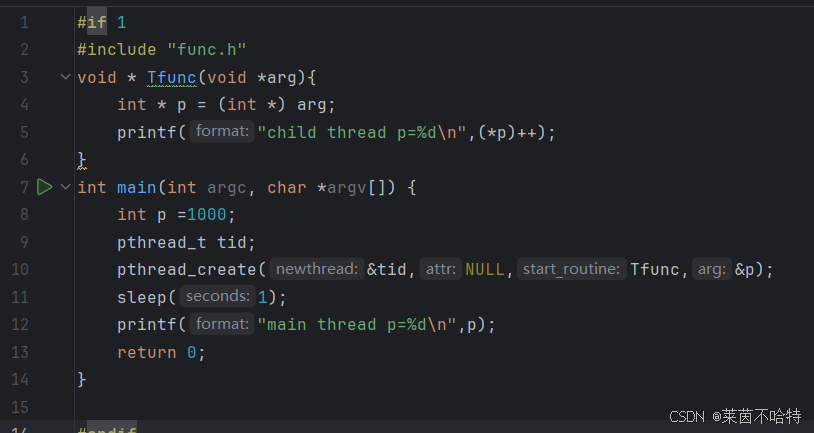
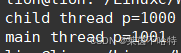
此处的p是开辟在栈上的内存,对于我们main主线程 和tid子线程来说都是共享资源
5.6创建多个子线程共享一个资源
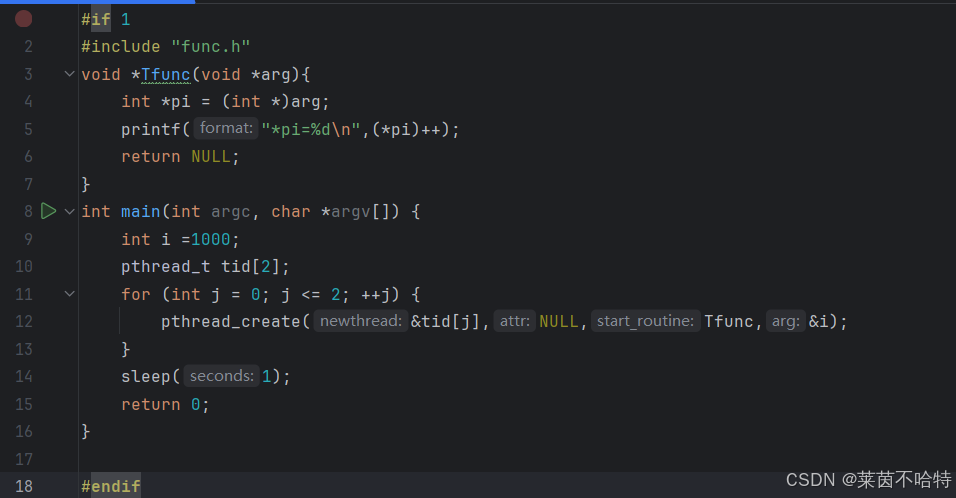
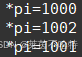
此处代码块我们创建了三个子线程对 共享资源 i的一个 自增操作
5.7 栈报错的一个情况 线程访问非法地址
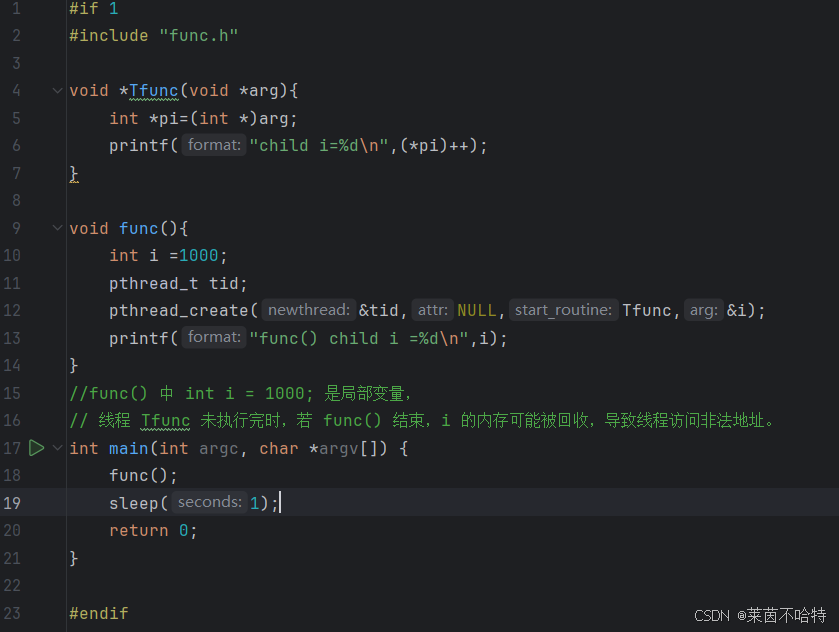
上述代码块中可能发生的一种情况就是线程Tfunc未执行完 结果func()函数先结束了, i的内存可能被回收 导致线程访问非法地址
5.8 堆报错的一个情况 在堆上申请的内存提前free
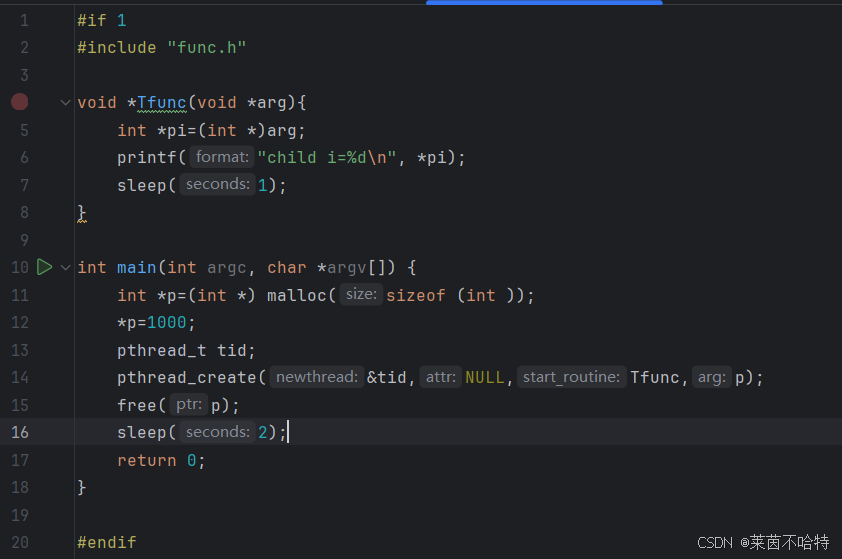

上述代码块中的子线程未开始执行 结果p提前free掉了 从而导致子线程访问非法地址
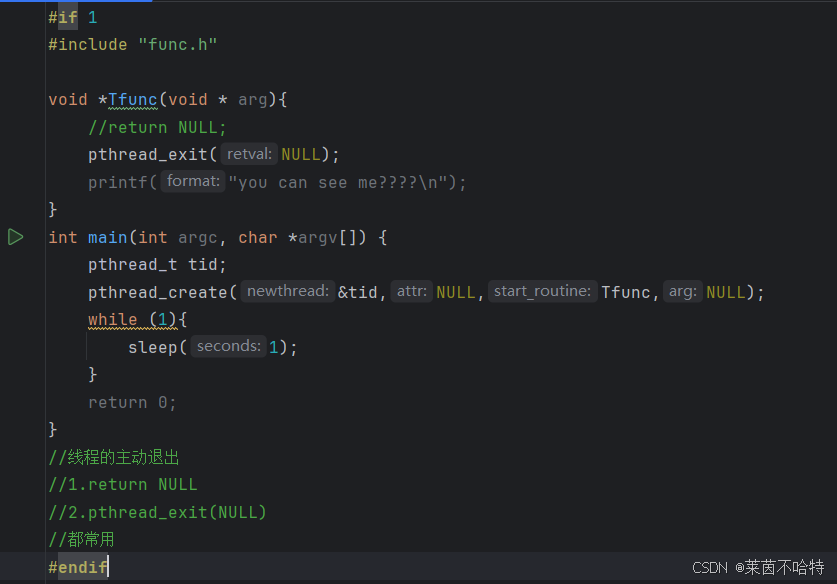
5.9 线程的主动退出 pthread_exit函数
线程的主动拥有退出功能的分别是return NULL 和pthread_exit(NULL)
5.10线程的资源回收机制 pthread_join函数
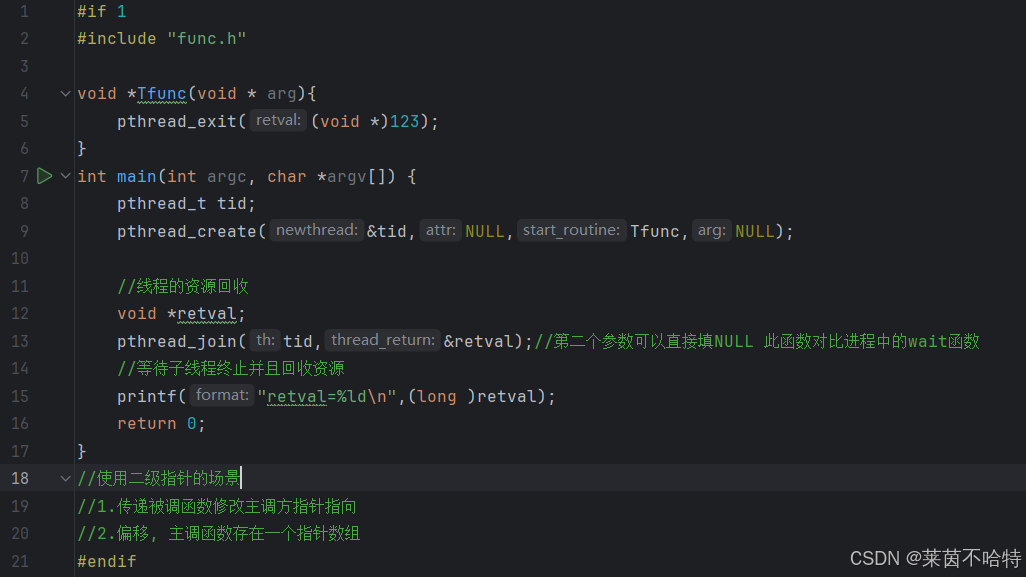
线程的回收资源机制可以等待子线程终止并且回收资源 该函数类似于进程中的wait函数 并且拥有sleep函数一定的效果
5.11线程的取消机制 pthread_cancel函数
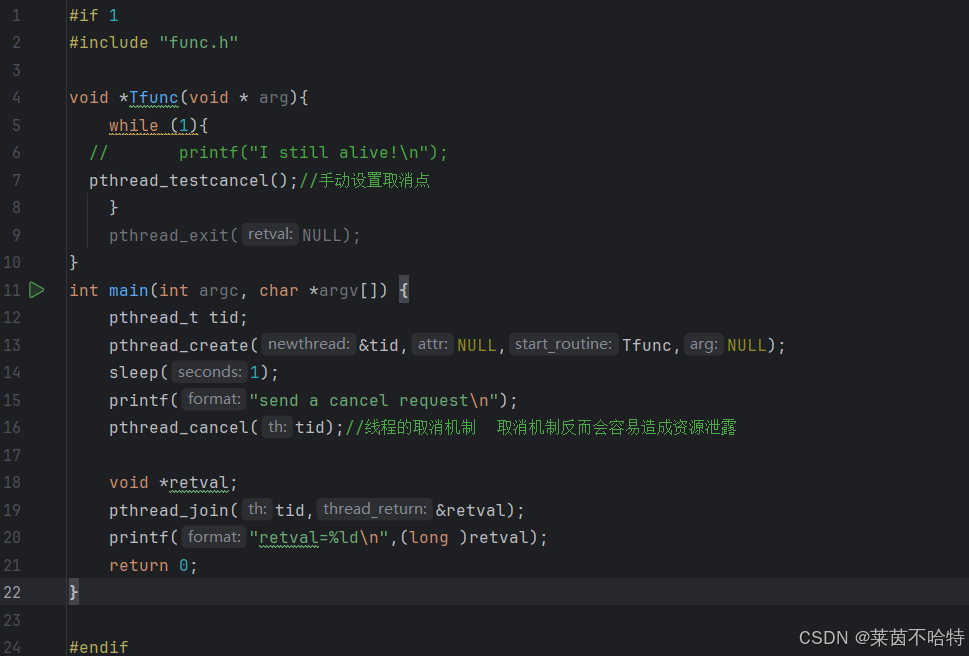
我们可以在线程执行的过程中手动设置取消点 从而达到取消的效果
取消机制的一个很大的弊端就是容易造成资源的泄露
5.12 线程的清理机制 pthread_cleanup_push 与 pthread_cleanup_pop
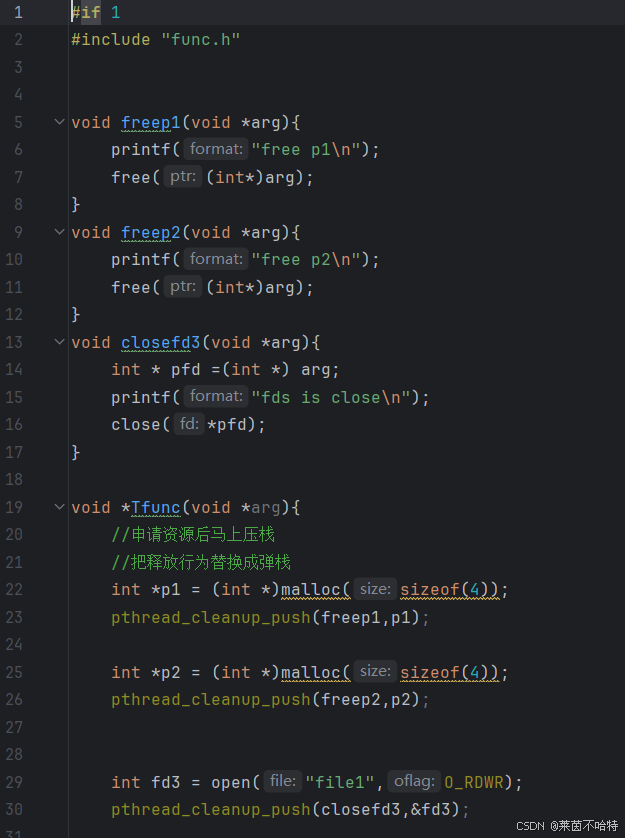
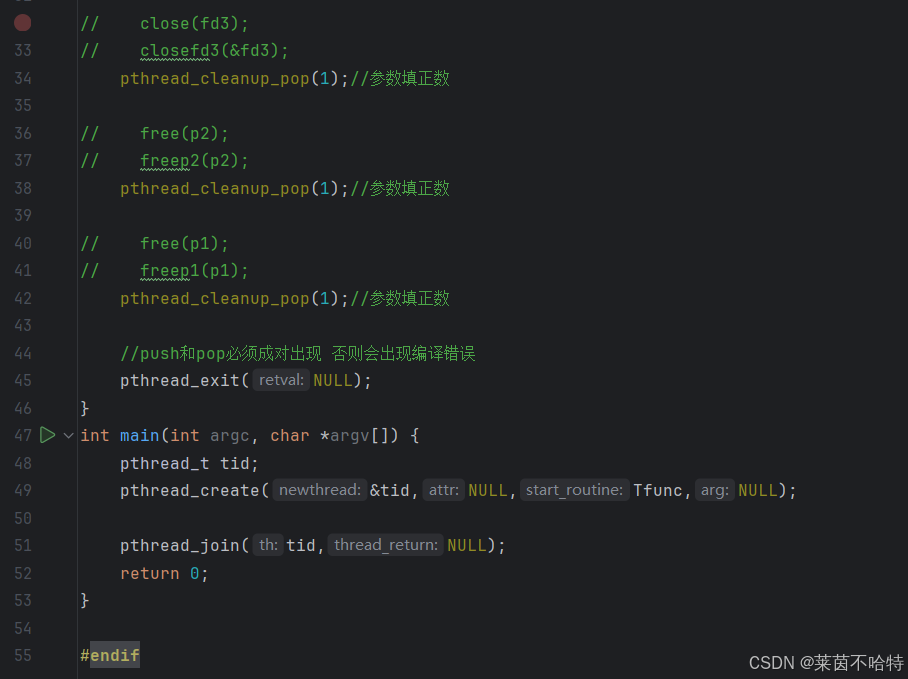
我们子线程在申请资源的时候马上压栈 在 释放的时候马上弹栈
push和pop必须成对出现 否则会出现编译错误
5.13 互斥锁 mutex pthraed_mutex_t 与 pthread_mutex_init
上锁 pthread_mutex_lock
解锁 pthread_mutex_unlock
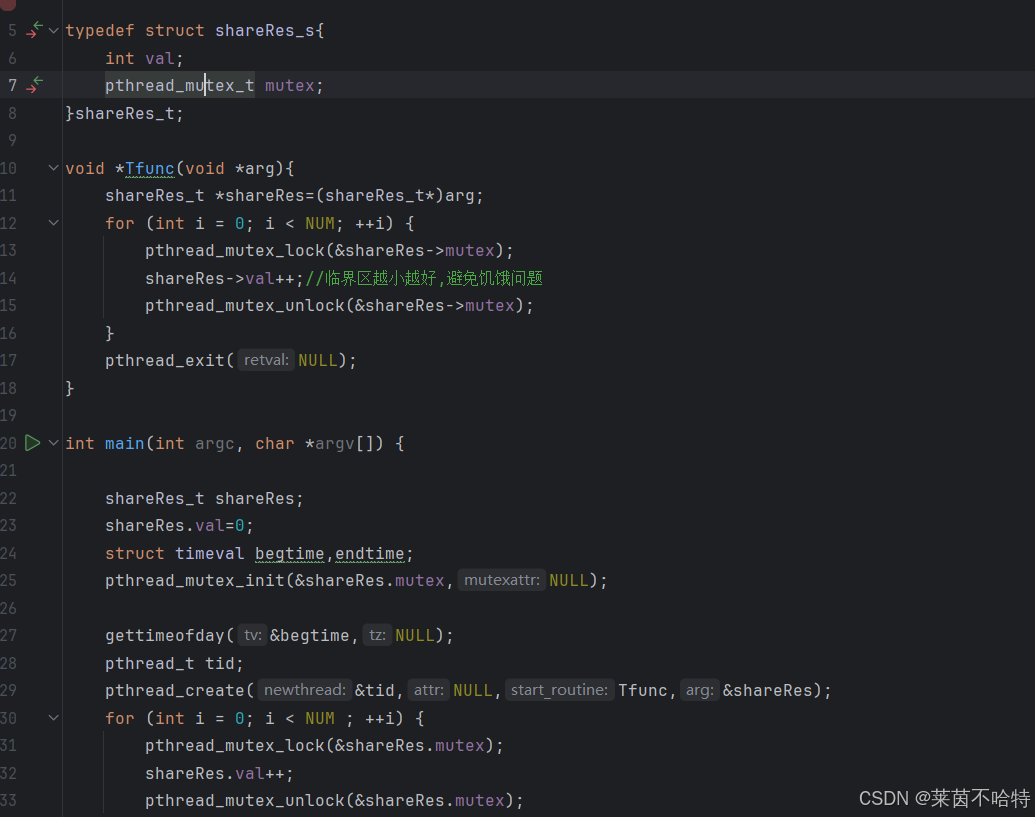
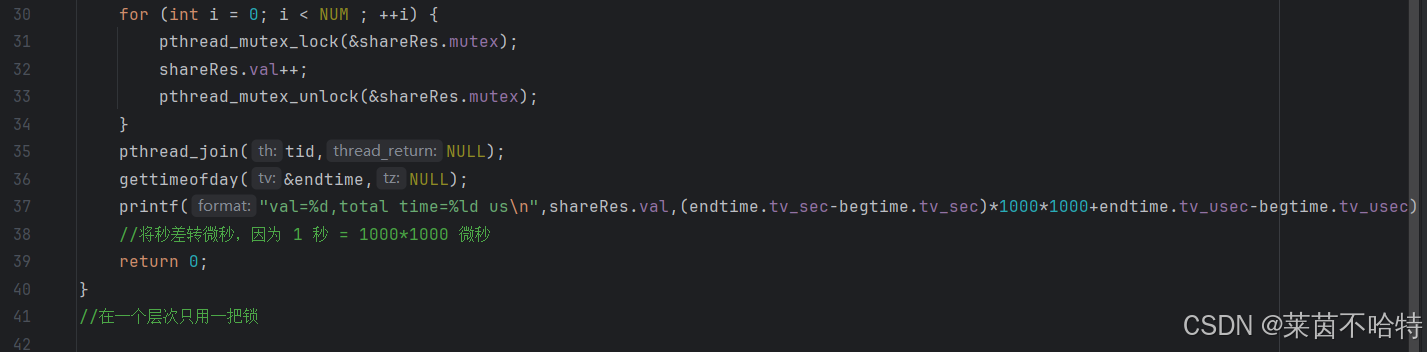
我们通过pthread_mutex_t mutex 和 pthread_mutex_init 定义了一把锁
我们通过上锁和解锁的操作对共享资源的处理进行了保护
① lock:测试并加锁
a.发现未锁则转成已锁
b.发现已锁 则阻塞
② unlock:已锁->解锁
对于锁的处理 临界区越小越好
一个层次建议只用一把锁
5.14死锁的一种情况
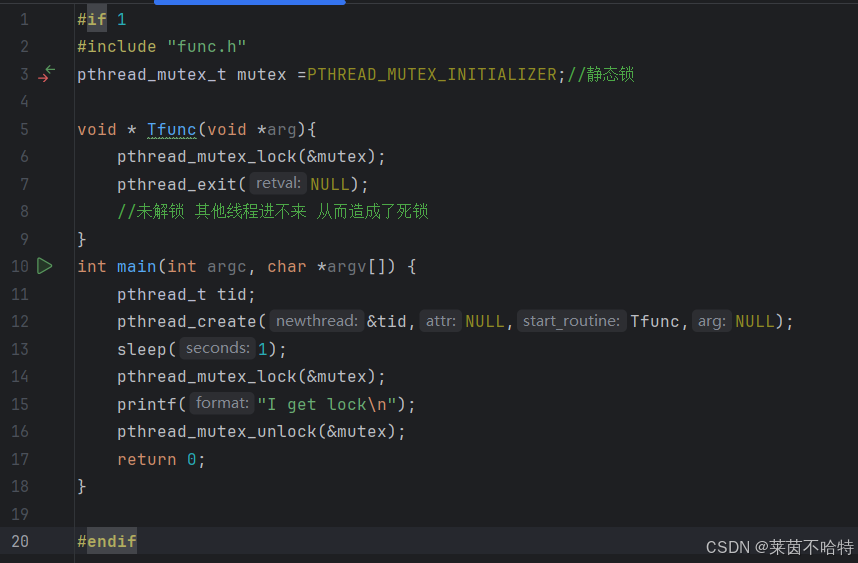
这种死锁的情况是因为 有一个线程在上锁之后 就 exit了 没有进行解锁操作 从而造成了死锁
我们每次上锁的时候 都要记得解锁 避免死锁的发生
5.15死锁的另一种情况
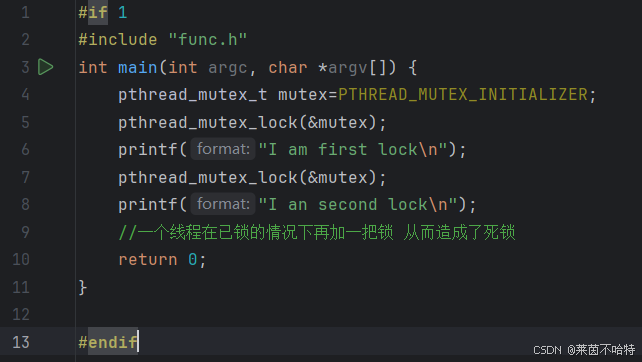
上述代码块的情况就是 一个线程在已锁的情况下 再加一把锁 从而造成了死锁
5.16可以检测报错上锁机制 pthread_mutex_trylock
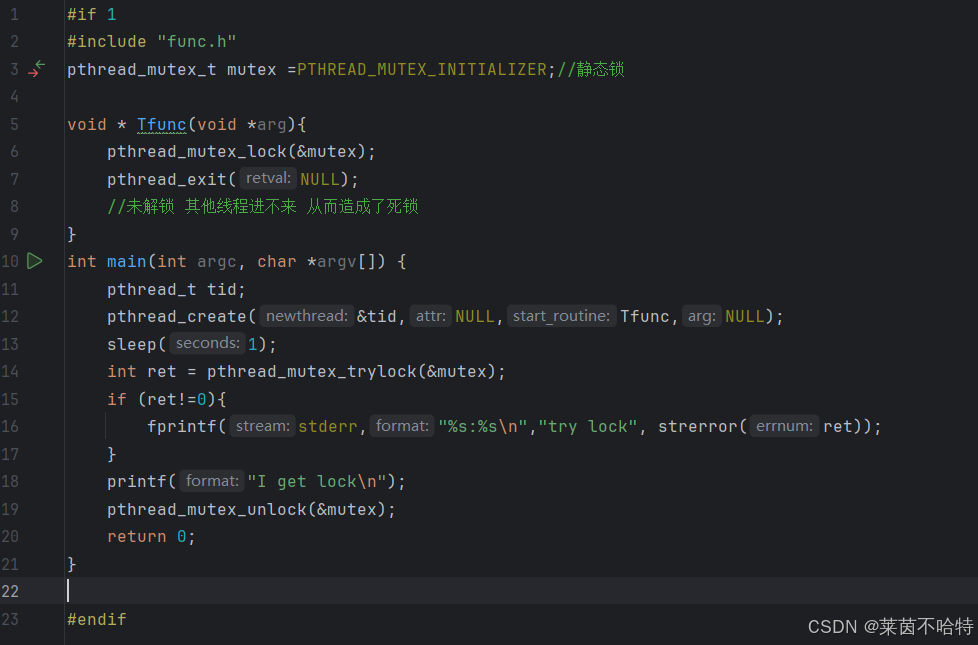
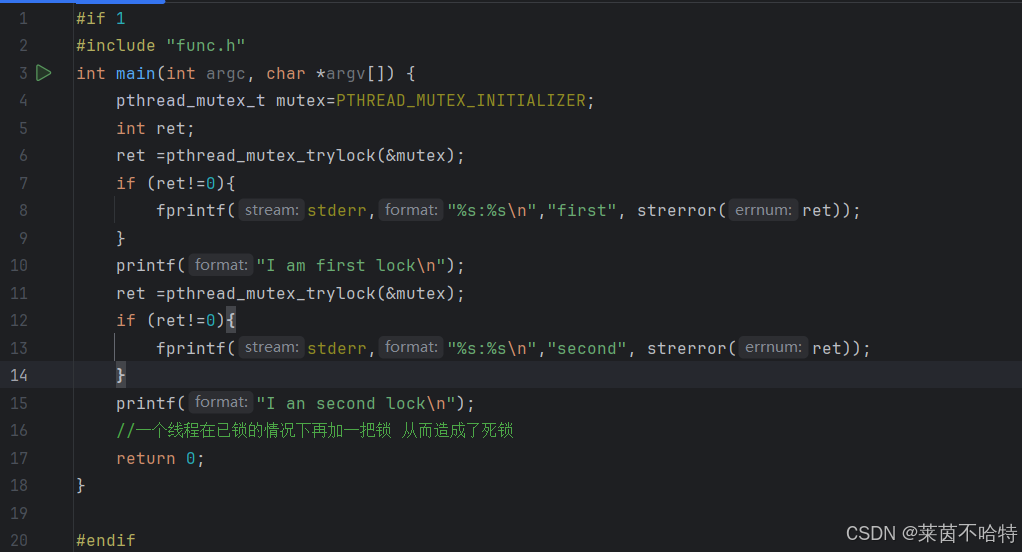
这种上锁机制可以基于以上两种情况的死锁发送报错信息而告诉用户发生了死锁
5.17设置锁的属性 检错锁① pthread_mutexattr_t mutexattr ②pthread_mutexattr_init ③ pthread_mutexattr_settype
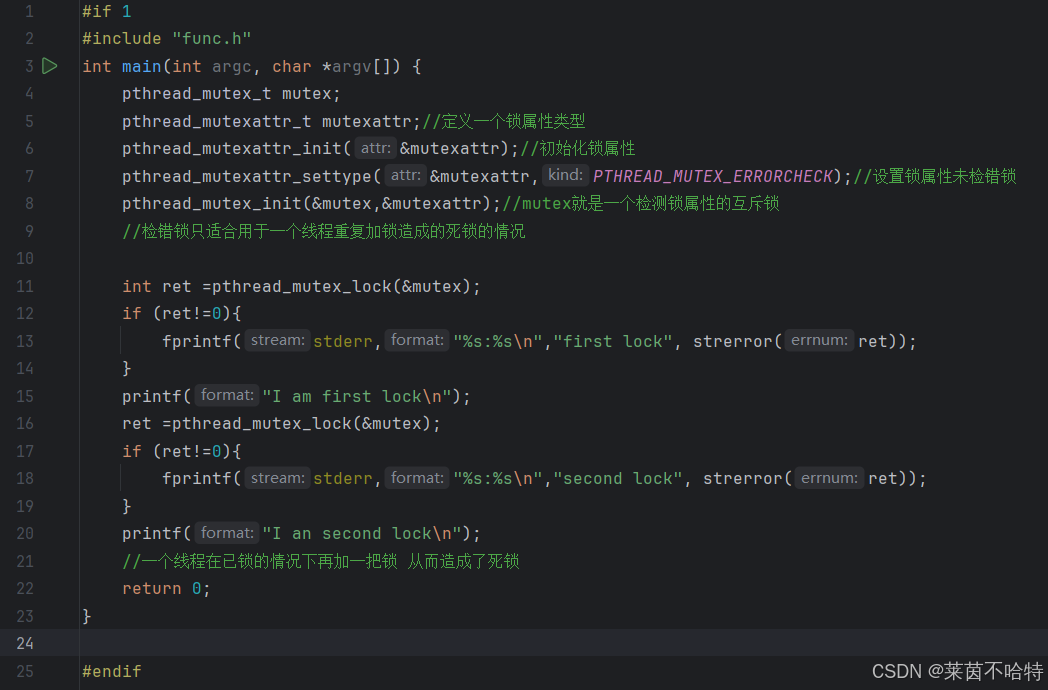
5.18 同步和条件变量
pthread_cond_t pthread_cond_signal pthread_cond_wait
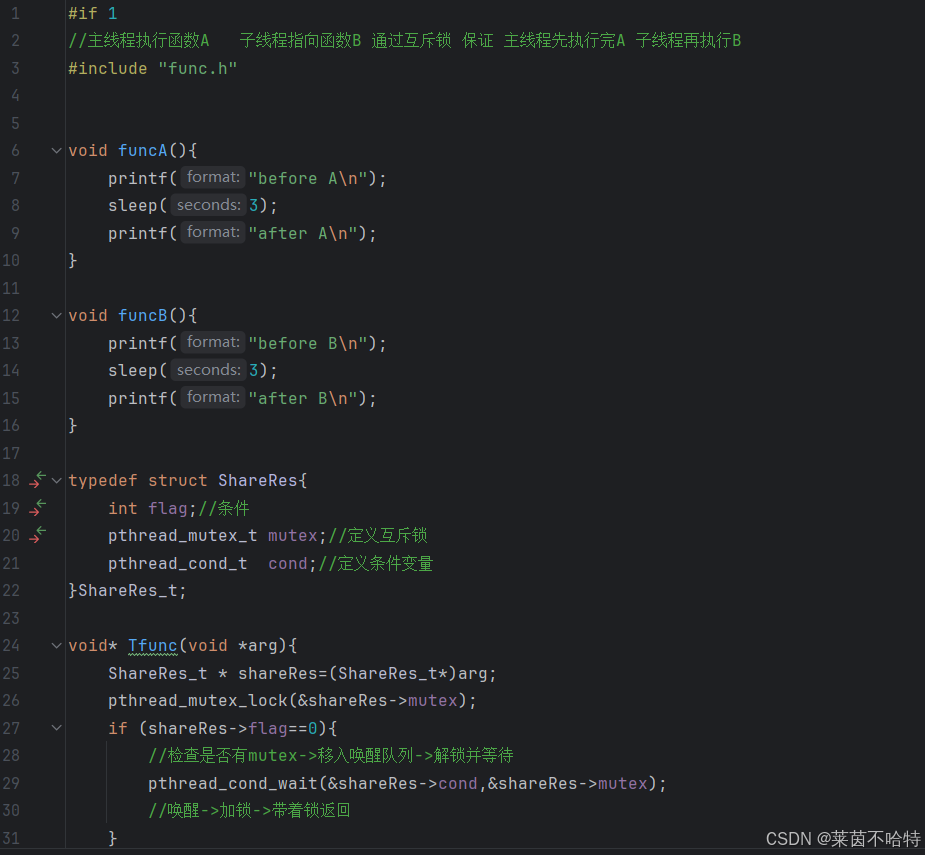
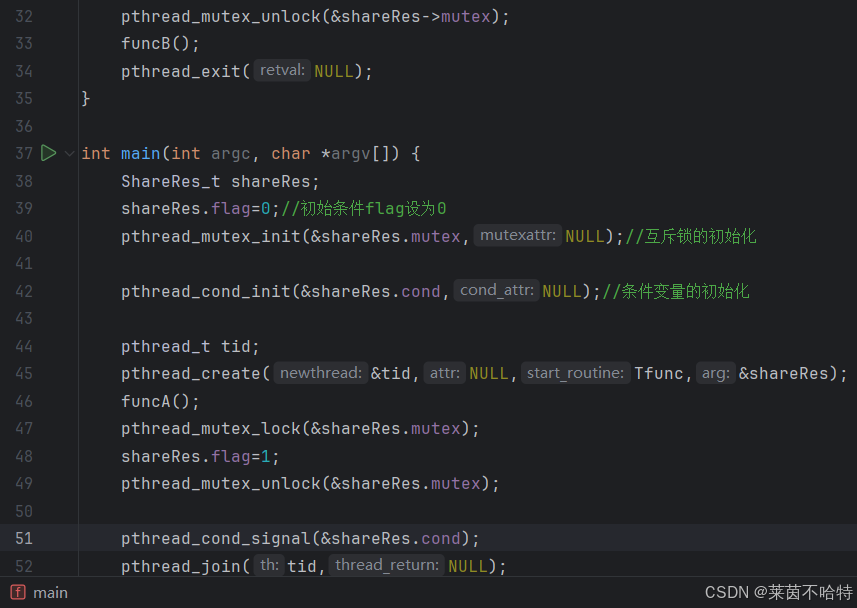
pthread_cond_signal:唤醒操作,触发等待线程。
pthread_cond_wait:等待条件,释放锁并阻塞,直到被唤醒。
5.19 设置线程的属性
pthread_attr_t
pthread_attr_init
pthread_attr_ setdetachstate
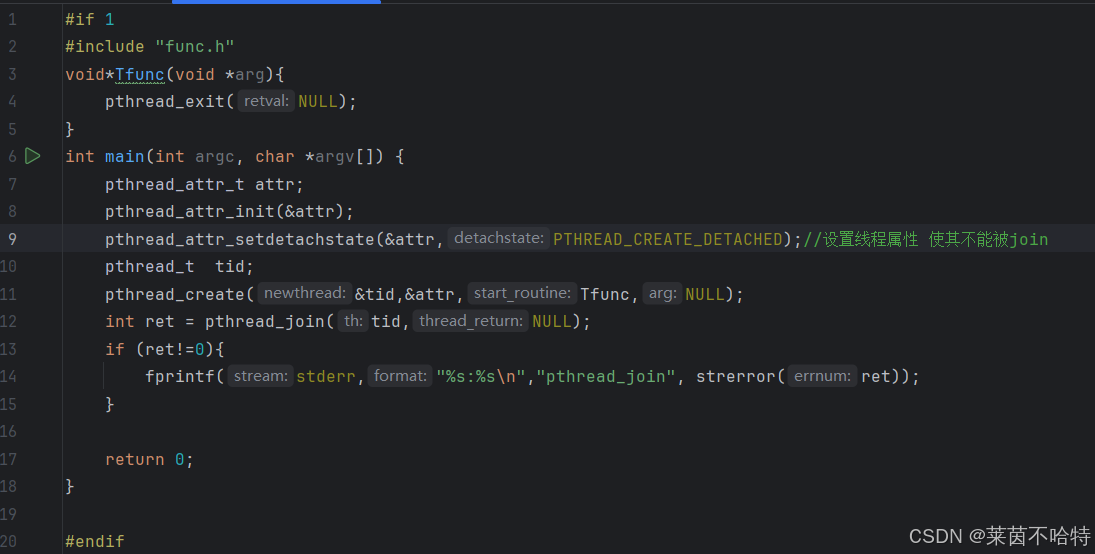
上述代码块通过对线程属性的设置 使其该线程不能被join资源回收
5.20 线程安全 ctime 和 ctime_r 的区别
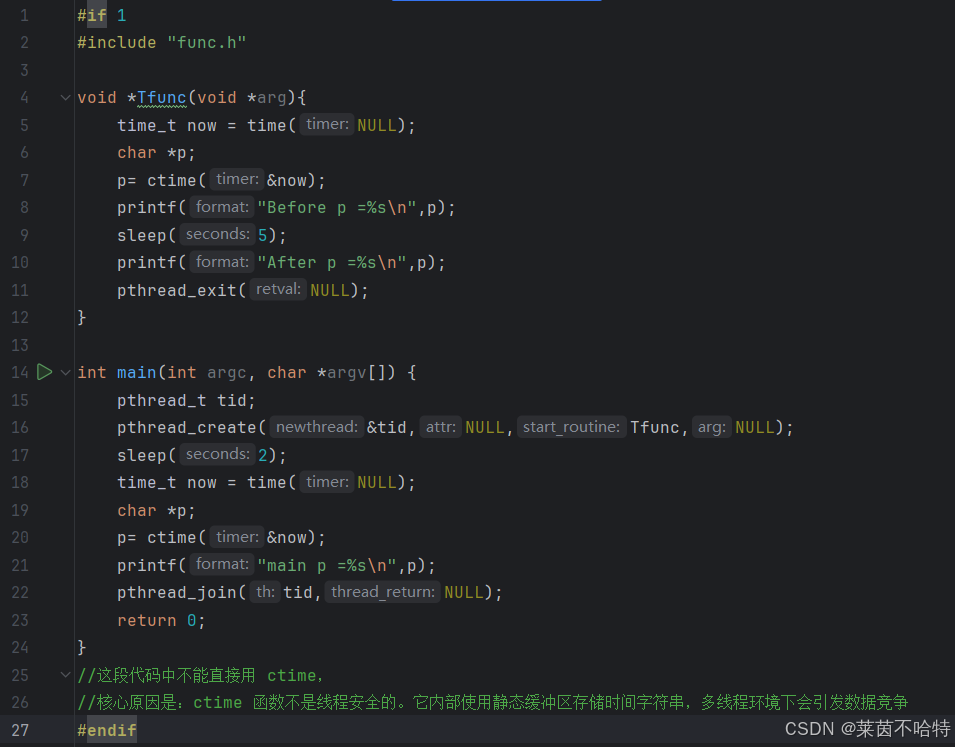
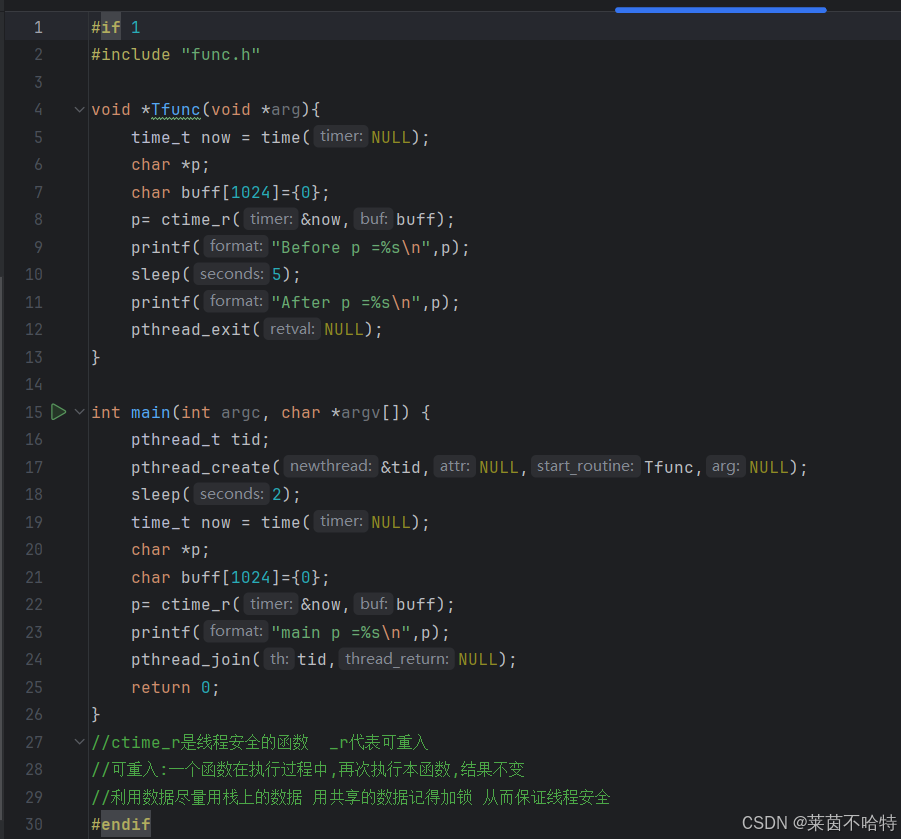
我们在使用一些特别的函数 他们后面带了_r代表的是线程安全的函数
5.21线程的总结
个人认为线程相比于进程最大的区别就是多个线程访问相同的共享资源 因此我们在用线程对各种区域的数据进行访问的时候 我们都需要加上锁来避免数据的污染 从而取得正确的结果
四.Linux系统编程综述
1.在 Linux 系统编程的世界里,从进程线程的资源管理,到文件网络的底层交互,每一次代码的编写都是对系统机制的深度对话。技术的精进离不开持续实践,建议读者多尝试编写小程序、调试疑难问题,在真实场景中打磨对系统接口、内核机制的理解。
2.如果你在 Linux 系统编程中遇到有趣的挑战,或是对某块内容(如更复杂的 IPC 机制、内核模块开发等)想深入探讨,欢迎在评论区留言。让我们一同交流技术细节,分享经验,在 Linux 系统编程的领域中不断探索,解锁更多编程智慧与能力

















 9430
9430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









