







目录
【深基6.例1】自动修正
题目描述
大家都知道一些办公软件有自动将字母转换为大写的功能。输入一个长度不超过 100 100 100 且不包括空格的字符串。要求将该字符串中的所有小写字母变成大写字母并输出。
输入格式
输入一行,一个字符串。
输出格式
输出一个字符串,即将原字符串中的所有小写字母转化为大写字母。
样例 #1
样例输入 #1
Luogu4!
样例输出 #1
LUOGU4!
题解
s = input()
print(s.upper())
小书童——凯撒密码
题目背景
某蒟蒻迷上了 “小书童”,有一天登陆时忘记密码了(他没绑定邮箱 or 手机),于是便把问题抛给了神犇你。
题目描述
蒟蒻虽然忘记密码,但他还记得密码是由一个字符串组成。密码是由原文字符串(由不超过 50 个小写字母组成)中每个字母向后移动
n
n
n 位形成的。z 的下一个字母是 a,如此循环。他现在找到了移动前的原文字符串及
n
n
n,请你求出密码。
输入格式
第一行: n n n。第二行:未移动前的一串字母。
输出格式
一行,是此蒟蒻的密码。
样例 #1
样例输入 #1
1
qwe
样例输出 #1
rxf
提示
字符串长度 ≤ 50 \le 50 ≤50, 1 ≤ n ≤ 26 1 \leq n \leq 26 1≤n≤26。
题解
n = int(input())
s = input()
for i in s:
x = ord(i) + n
if x > 122:
x = x - 26
print(chr(x), end='')
[NOIP2008 提高组] 笨小猴
题目描述
笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼。但是他找到了一种方法,经试验证明,用这种方法去选择选项的时候选对的几率非常大!
这种方法的具体描述如下:假设 maxn \text{maxn} maxn 是单词中出现次数最多的字母的出现次数, minn \text{minn} minn 是单词中出现次数最少的字母的出现次数,如果 maxn − minn \text{maxn}-\text{minn} maxn−minn 是一个质数,那么笨小猴就认为这是个 Lucky Word,这样的单词很可能就是正确的答案。
输入格式
一个单词,其中只可能出现小写字母,并且长度小于 100 100 100。
输出格式
共两行,第一行是一个字符串,假设输入的的单词是 Lucky Word,那么输出 Lucky Word,否则输出 No Answer;
第二行是一个整数,如果输入单词是 Lucky Word,输出
maxn
−
minn
\text{maxn}-\text{minn}
maxn−minn 的值,否则输出
0
0
0。
样例 #1
样例输入 #1
error
样例输出 #1
Lucky Word
2
样例 #2
样例输入 #2
olympic
样例输出 #2
No Answer
0
提示
【输入输出样例 1 解释】
单词 error 中出现最多的字母
r
\texttt r
r 出现了
3
3
3 次,出现次数最少的字母出现了
1
1
1 次,
3
−
1
=
2
3-1=2
3−1=2,
2
2
2 是质数。
【输入输出样例 2 解释】
单词 olympic 中出现最多的字母
i
\texttt i
i 出现了
1
1
1 次,出现次数最少的字母出现了
1
1
1 次,
1
−
1
=
0
1-1=0
1−1=0,
0
0
0 不是质数。
(本处原题面错误已经修正)
noip2008 提高第一题
题解
def zhishu(n):
if n == 0 or n == 1:
return False
for i in range(2, n):
if n % i == 0:
return False
else:
return True
s = input()
d = {}
for i in s:
d[i] = d.get(i,0) + 1
ma = 0
mi = 100
for val in d.values():
if val > ma:
ma = val
if val < mi:
mi = val
if zhishu(ma-mi):
print('Lucky Word')
print(ma-mi)
else:
print('No Answer')
print(0)
口算练习题
题目描述
王老师正在教简单算术运算。细心的王老师收集了 i i i 道学生经常做错的口算题,并且想整理编写成一份练习。 编排这些题目是一件繁琐的事情,为此他想用计算机程序来提高工作效率。王老师希望尽量减少输入的工作量,比如 5+8 \texttt{5+8} 5+8 的算式最好只要输入 5 \texttt 5 5 和 8 \texttt 8 8,输出的结果要尽量详细以方便后期排版的使用,比如对于上述输入进行处理后输出 5+8=13 \texttt{5+8=13} 5+8=13 以及该算式的总长度 6 6 6。王老师把这个光荣的任务交给你,请你帮他编程实现以上功能。
输入格式
第一行一个整数 i i i。
接着的 i i i 行为需要输入的算式,每行可能有三个数据或两个数据。
若该行为三个数据则第一个数据表示运算类型, a \texttt a a 表示加法运算, b \texttt b b 表示减法运算, c \texttt c c 表示乘法运算,接着的两个数据表示参加运算的运算数。
若该行为两个数据,则表示本题的运算类型与上一题的运算类型相同,而这两个数据为运算数。
输出格式
输出 2 × i 2\times i 2×i 行。对于每个输入的算式,输出完整的运算式及结果,第二行输出该运算式的总长度。
样例 #1
样例输入 #1
4
a 64 46
275 125
c 11 99
b 46 64
样例输出 #1
64+46=110
9
275+125=400
11
11*99=1089
10
46-64=-18
9
提示
【数据规模与约定】
对于 50 % 50\% 50% 的数据,输入的算式都有三个数据,第一个算式一定有三个数据。
对于所有数据, 0 < i ≤ 50 0<i\leq 50 0<i≤50,运算数为非负整数且小于 10000 10000 10000。
题解
n = int(input())
d = {}
for i in range(n):
ls = input().split()
n = len(ls)
if n == 3:
q = ls[0]
if ls[0] == 'a':
s = ls[1] + '+' + ls[2] + '=' + str(int(ls[1])+int(ls[2]))
d[s] = len(s)
elif ls[0] == 'b':
s = ls[1] + '-' + ls[2] + '=' + str(int(ls[1]) - int(ls[2]))
d[s] = len(s)
elif ls[0] == 'c':
s = ls[1] + '*' + ls[2] + '=' + str(int(ls[1]) * int(ls[2]))
d[s] = len(s)
else:
if q == 'a':
s = ls[0] + '+' + ls[1] + '=' + str(int(ls[1])+int(ls[0]))
d[s] = len(s)
elif q == 'b':
s = ls[0] + '-' + ls[1] + '=' + str(int(ls[0]) - int(ls[1]))
d[s] = len(s)
elif q == 'c':
s = ls[0] + '*' + ls[1] + '=' + str(int(ls[1]) * int(ls[0]))
d[s] = len(s)
for key, val in d.items():
print(key)
print(val)
[NOIP2018 普及组] 标题统计
题目背景
NOIP2018 普及组 T1
题目描述
凯凯刚写了一篇美妙的作文,请问这篇作文的标题中有多少个字符? 注意:标题中可能包含大、小写英文字母、数字字符、空格和换行符。统计标题字符数时,空格和换行符不计算在内。
输入格式
输入文件只有一行,一个字符串 s s s。
输出格式
输出文件只有一行,包含一个整数,即作文标题的字符数(不含空格和换行符)。
样例 #1
样例输入 #1
234
样例输出 #1
3
样例 #2
样例输入 #2
Ca 45
样例输出 #2
4
提示
样例 1 说明
标题中共有 3 个字符,这 3 个字符都是数字字符。
样例 2 说明
标题中共有 $ 5$ 个字符,包括 1 1 1 个大写英文字母, 1 1 1 个小写英文字母和 2 2 2 个数字字符, 还有 1 1 1 个空格。由于空格不计入结果中,故标题的有效字符数为 4 4 4 个。
数据规模与约定
规定
∣
s
∣
|s|
∣s∣ 表示字符串
s
s
s 的长度(即字符串中的字符和空格数)。
对于
40
%
40\%
40% 的数据,
1
≤
∣
s
∣
≤
5
1 ≤ |s| ≤ 5
1≤∣s∣≤5,保证输入为数字字符及行末换行符。
对于
80
%
80\%
80% 的数据,
1
≤
∣
s
∣
≤
5
1 ≤ |s| ≤ 5
1≤∣s∣≤5,输入只可能包含大、小写英文字母、数字字符及行末换行符。
对于
100
%
100\%
100% 的数据,
1
≤
∣
s
∣
≤
5
1 ≤ |s| ≤ 5
1≤∣s∣≤5,输入可能包含大、小写英文字母、数字字符、空格和行末换行符。
题解
s = input()
n = 0
for i in s:
if i != ' ' and i != '\n':
n = n+1
print(n)
【深基6.例6】文字处理软件
题目描述
你需要开发一款文字处理软件。最开始时输入一个字符串作为初始文档。可以认为文档开头是第 0 0 0 个字符。需要支持以下操作:
1 str:后接插入,在文档后面插入字符串 str \texttt{str} str,并输出文档的字符串;2 a b:截取文档部分,只保留文档中从第 a a a 个字符起 b b b 个字符,并输出文档的字符串;3 a str:插入片段,在文档中第 a a a 个字符前面插入字符串 str \texttt{str} str,并输出文档的字符串;4 str:查找子串,查找字符串 str \texttt{str} str 在文档中最先的位置并输出;如果找不到输出 − 1 -1 −1。
为了简化问题,规定初始的文档和每次操作中的 str \texttt{str} str 都不含有空格或换行。最多会有 q q q 次操作。
输入格式
第一行输入一个正整数 q q q,表示操作次数。
第二行输入一个字符串 str \texttt{str} str,表示最开始的字符串。
第三行开始,往下 q q q 行,每行表示一个操作,操作如题目描述所示。
输出格式
一共输出 q q q 行。
对于每个操作 1 , 2 , 3 1,2,3 1,2,3,根据操作的要求输出一个字符串。
对于操作 4 4 4,根据操作的要求输出一个整数。
样例 #1
样例输入 #1
4
ILove
1 Luogu
2 5 5
3 3 guGugu
4 gu
样例输出 #1
ILoveLuogu
Luogu
LuoguGugugu
3
提示
数据保证, 1 ≤ q ≤ 100 1 \leq q\le 100 1≤q≤100,开始的字符串长度 ≤ 100 \leq 100 ≤100。
题解
#include<stdio.h>
#include<string.h>
#define MAXN 101
char str[MAXN], in[MAXN];
int main(void)
{
int q;
scanf("%d\n%s", &q, str);
for (int i = 1; i <= q; i++) {
int opt;
scanf("%d", &opt);
if (opt == 1) {
scanf("%s", in);
strcat(str, in);
printf("%s\n", str);
}
else if (opt == 2) {
int a, b;
scanf("%d %d", &a, &b);
str[a + b] = '\0';
strcpy(in, &str[a]);
strcpy(str, in);
printf("%s\n", str);
}
else if (opt == 3) {
int a;
scanf("%d %s", &a, in);
strcat(in, &str[a]);
str[a] = '\0';
strcat(str, in);
printf("%s\n", str);
}
else {
scanf("%s", in);
char *ans = strstr(str, in);
printf("%d\n", ans != NULL ? (int)(ans - str) : -1);
}
}
return 0;
}
[NOIP2011 普及组] 统计单词数
题目描述
一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数。
现在,请你编程实现这一功能,具体要求是:给定一个单词,请你输出它在给定的文章中出现的次数和第一次出现的位置。注意:匹配单词时,不区分大小写,但要求完全匹配,即给定单词必须与文章中的某一独立单词在不区分大小写的情况下完全相同(参见样例 1),如果给定单词仅是文章中某一单词的一部分则不算匹配(参见样例 2)。
输入格式
共 2 2 2 行。
第 1 1 1 行为一个字符串,其中只含字母,表示给定单词;
第 2 2 2 行为一个字符串,其中只可能包含字母和空格,表示给定的文章。
输出格式
一行,如果在文章中找到给定单词则输出两个整数,两个整数之间用一个空格隔开,分别是单词在文章中出现的次数和第一次出现的位置(即在文章中第一次出现时,单词首字母在文章中的位置,位置从 0 0 0 开始);如果单词在文章中没有出现,则直接输出一个整数 − 1 -1 −1。
注意:空格占一个字母位
样例 #1
样例输入 #1
To
to be or not to be is a question
样例输出 #1
2 0
样例 #2
样例输入 #2
to
Did the Ottoman Empire lose its power at that time
样例输出 #2
-1
提示
数据范围
$1\leq $ 第一行单词长度 ≤ 10 \leq10 ≤10。
$1\leq $ 文章长度 ≤ 1 0 6 \leq10^6 ≤106。
noip2011 普及组第 2 题
题解
a = input().strip().lower()
b = input().lower() # 考虑到首尾的空格会单词首次出现的位置有影响,在此不能去除
b_list = b.split()
count = 0
first = 0
if a not in b_list:
print(-1)
else:
for i in b_list:
if i == a:
count += 1
for j in range(len(b) - len(a)):
if (b[j:j + len(a)] == a):
first = j
# 若单词首次出现在字符串首,则只需判断单词后的字符是否为分隔符(空格)
if (j == 0) and (b[j + len(a)] == ' '):
break
# 若单词在字符串尾才出现,则需要判断单词前的字符是否为分隔符
elif (j == (len(b) - len(a)) and b[j - 1] == ' '):
break
# 若单词出现在字符串中,则需要同时满足单词前后字符均为空格
elif (j != 0) and (j != len(b) - len(a)) and (b[j - 1] == ' ') and (b[j + len(a)] == ' '):
break
print(count, first)
手机
题目描述
一般的手机的键盘是这样的:
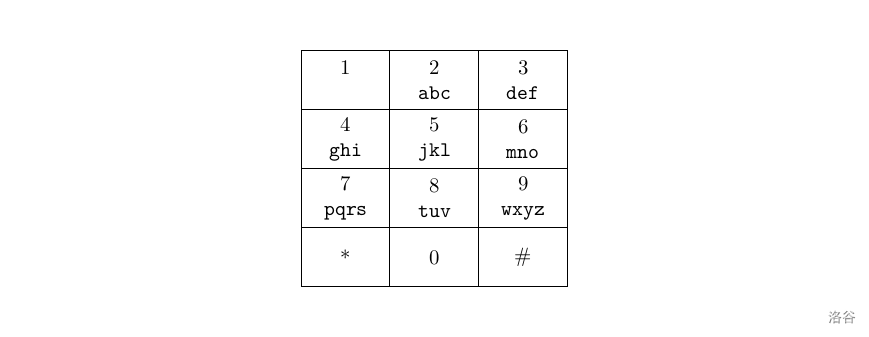
要按出英文字母就必须要按数字键多下。例如要按出 x \tt x x 就得按 9 9 9 两下,第一下会出 w \tt w w,而第二下会把 w \tt w w 变成 x \tt x x。 0 0 0 键按一下会出一个空格。
你的任务是读取若干句只包含英文小写字母和空格的句子,求出要在手机上打出这个句子至少需要按多少下键盘。
输入格式
一行句子,只包含英文小写字母和空格,且不超过 200 个字符。
输出格式
一行一个整数,表示按键盘的总次数。
样例 #1
样例输入 #1
i have a dream
样例输出 #1
23
提示
NOI 导刊 2010 普及(10)
题解
str1 = input()
tab = ["abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"," "]
c = 0
for i in str1:
for j in tab:
if i in j:
c += j.index(i) + 1
print(c)
小果的键盘
题目背景
小果有一个只有两个键的键盘。
题目描述
一天,她打出了一个只有这两个字符的字符串。当这个字符串里含有 VK 这个字符串的时候,小果就特别喜欢这个字符串。所以,她想改变至多一个字符(或者不做任何改变)来最大化这个字符串内 VK 出现的次数。给出原来的字符串,请计算她最多能使这个字符串内出现多少次 VK(只有当 V 和 K 正好相邻时,我们认为出现了 VK。)
输入格式
第一行给出一个数字 n n n,代表字符串的长度。
第二行给出一个字符串 s s s。
输出格式
第一行输出一个整数代表所求答案。
样例 #1
样例输入 #1
2
VK
样例输出 #1
1
样例 #2
样例输入 #2
2
VV
样例输出 #2
1
样例 #3
样例输入 #3
1
V
样例输出 #3
0
样例 #4
样例输入 #4
20
VKKKKKKKKKVVVVVVVVVK
样例输出 #4
3
样例 #5
样例输入 #5
4
KVKV
样例输出 #5
1
提示
对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 100 1\le n\le 100 1≤n≤100。
题解
n = int(input())
s = input().strip()
a = s.count('VK')
ss = s.split('VK')
for i in ss:
if 'VV' in i or 'KK' in i:
a = a+1
break
print(a)
单词覆盖还原
题目描述
我有一个长度为
l
l
l 的字符串,最开始时,这个字符串由
l
l
l 个句号(.)组成。
我在这个字符串中,将多次把 boy 或者 girl 两单词,依次贴到这个字符串中。
后贴上单词,会覆盖之前贴上的单词,或者覆盖句号。最终,每个单词至少有一个字符没有被覆盖。
请问,一共贴有几个 boy 几个 girl?
输入格式
一行被反复贴有 boy 和 girl 两单词的字符串。
输出格式
两行,两个整数。第一行为 boy 的个数,第二行为 girl 的个数。
样例 #1
样例输入 #1
......boyogirlyy......girl.......
样例输出 #1
4
2
提示
数据保证, 3 ≤ l ≤ 255 3\le l\le255 3≤l≤255,字符串仅仅包含如下字符: .bgilory \texttt{.bgilory} .bgilory。
题解
s = input().strip()
b = s.count('boy')
g = s.count('girl')
s = s.replace('boy', '111')
s = s.replace('girl', '1111')
q = s.count('gir') + s.count('irl')
g = g + q
if s.count('gir') != 0:
s = s.replace('gir', '111')
if s.count('irl') != 0:
s = s.replace('irl', '111')
p = s.count('bo') + s.count('oy')
b = b + p
q = s.count('gi') + s.count('ir') + s.count('rl')
g = g + q
if s.count('gi') != 0:
s = s.replace('gi', '11')
if s.count('ir') != 0:
s = s.replace('ir', '11')
if s.count('rl') != 0:
s = s.replace('rl', '11')
if s.count('bo') != 0:
s = s.replace('bo', '11')
if s.count('oy') != 0:
s = s.replace('oy', '11')
b = b + s.count('b') + s.count('o') + s.count('y')
g = g + s.count('g') + s.count('i') + s.count('r') + s.count('l')
print(b)
print(g)
数字反转(升级版)
题目背景
以下为原题面,仅供参考:
给定一个数,请将该数各个位上数字反转得到一个新数。
这次与 NOIp2011 普及组第一题不同的是:这个数可以是小数,分数,百分数,整数。整数反转是将所有数位对调;小数反转是把整数部分的数反转,再将小数部分的数反转,不交换整数部分与小数部分;分数反转是把分母的数反转,再把分子的数反转,不交换分子与分母;百分数的分子一定是整数,百分数只改变数字部分。整数新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零;小数新数的末尾不为 0 0 0(除非小数部分除了 0 0 0 没有别的数,那么只保留1个 0 0 0);分数不约分,分子和分母都不是小数(约分滴童鞋抱歉了,不能过哦。输入数据保证分母不为 0 0 0),本次没有负数。
题目描述
给定一个数,请将该数各个位上数字反转得到一个新数。
这次与 NOIp2011 普及组第一题不同的是:这个数可以是小数,分数,百分数,整数。
-
整数反转是将所有数位对调。
-
小数反转是把整数部分的数反转,再将小数部分的数反转,不交换整数部分与小数部分。
-
分数反转是把分母的数反转,再把分子的数反转,不交换分子与分母。
-
百分数的分子一定是整数,百分数只改变数字部分。
输入格式
一个实数 s s s
输出格式
一个实数,即 s s s 的反转数
样例 #1
样例输入 #1
5087462
样例输出 #1
2647805
样例 #2
样例输入 #2
600.084
样例输出 #2
6.48
样例 #3
样例输入 #3
700/27
样例输出 #3
7/72
样例 #4
样例输入 #4
8670%
样例输出 #4
768%
提示
【数据范围】
- 对于 25 % 25\% 25% 的数据, s s s 是整数,不大于 20 20 20 位;
- 对于 25 % 25\% 25% 的数据, s s s 是小数,整数部分和小数部分均不大于 10 10 10 位;
- 对于 25 % 25\% 25% 的数据, s s s 是分数,分子和分母均不大于 10 10 10 位;
- 对于 25 % 25\% 25% 的数据, s s s 是百分数,分子不大于 19 19 19 位。
【数据保证】
-
对于整数翻转而言,整数原数和整数新数满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数和原来的数字的最高位数字不应为零。
-
对于小数翻转而言,其小数点前面部分同上,小数点后面部分的形式,保证满足小数的常见形式,也就是末尾没有多余的 0 0 0(小数部分除了 0 0 0 没有别的数,那么只保留 1 1 1 个 0 0 0。若反转之后末尾数字出现 0 0 0,请省略多余的 0 0 0)
-
对于分数翻转而言,分数不约分,分子和分母都不是小数。输入的分母不为 0 0 0。与整数翻转相关规定见上。
-
对于百分数翻转而言,见与整数翻转相关内容。
数据不存在负数。
题解
def fan(s):
x = len(s) - 1
for i in range(len(s)-1, -1, -1):
if s[i] != '0':
x = i
break
s = s[x::-1]
return s
s = input()
if '/' in s:
a = s.find('/')
s1 = s[:a]
s2 = s[a+1:]
s1 = fan(s1)
s2 = fan(s2)
print(s1+'/'+s2)
elif '%' in s:
s = s[:-1]
s = fan(s)
print(s+'%')
elif '.' in s:
a = s.find('.')
s1 = s[:a]
s2 = s[a + 1:]
s1 = fan(s1)
s2 = fan(s2)
s2 = fan(s2)
s2 = fan(s2)
print(s1 + '.' + s2)
else:
s = fan(s)
print(s)
斯诺登的密码
题目背景
根据斯诺登事件出的一道水题
题目描述
2013 年 X 月 X 日,俄罗斯办理了斯诺登的护照,于是他混迹于一架开往委内瑞拉的飞机。但是,这件事情太不周密了,因为 FBI 的间谍早已获悉他的具体位置——但这不是最重要的——最重要的是如果要去委内瑞拉,那么就要经过古巴,而经过古巴的路在美国的掌控之中。
丧心病狂的奥巴马迫降斯诺登的飞机,搜查时却发现,斯诺登杳无踪迹。但是,在据说是斯诺登的座位上,发现了一张纸条。纸条由纯英文构成:Obama is a two five zero.(以 . 结束输出,只有
6
6
6 个单词+一个句号,句子开头如没有大写亦为合法)这句话虽然有点无厘头,但是警官陈珺骛发现这是一条极其重要的线索。他在斯诺登截获的一台笔记本中找到了一个 C++ 程序,输入这条句子后立马给出了相对应的密码。陈珺鹜高兴得晕了过去,身为警官的你把字条和程序带上了飞机,准备飞往曼哈顿国际机场,但是在飞机上检查的时候发现——程序被粉碎了!飞机抵达华盛顿只剩
5
5
5 分钟,你必须在这
5
5
5 分钟内编写(杜撰)一个程序,免受上司的
10000000000
m
o
d
10
10000000000 \bmod 10
10000000000mod10 大板。破译密码的步骤如下:
(1)找出句子中所有用英文表示的数字 ( ≤ 20 ) (\leq 20) (≤20),列举在下:
正规:one two three four five six seven eight nine ten eleven twelve
thirteen fourteen fifteen sixteen seventeen eighteen nineteen twenty
非正规:a both another first second third。为避免造成歧义,another 算作
1
1
1 处理。
(2)将这些数字平方后对 100 100 100 取模,如 00 , 05 , 11 , 19 , 86 , 99 00,05,11,19,86,99 00,05,11,19,86,99。
(3)把这些两位数按数位排成一行,组成一个新数,如果开头为 0 0 0,就去 0 0 0。
(4)找出所有排列方法中最小的一个数,即为密码。
// 数据已经修正 By absi2011 如果还有问题请联系我
输入格式
一个含有 6 6 6 个单词的句子。
输出格式
一个整型变量(密码)。如果没有符合要求的数字出现,则输出 0 0 0。
样例 #1
样例输入 #1
Black Obama is two five zero .
样例输出 #1
425
题解
ls = 'one two three four five six seven eight nine ten eleven twelve thirteen fourteen fifteen sixteen seventeen eighteen nineteen twenty'.split()
d = {'a':1, 'both':2, 'another':1, 'first':1, 'second':2, 'third':3}
s = input().strip().split()
l = []
for i in s:
if i in ls:
q = ls.index(i) + 1
l.append(q ** 2 % 100)
if i in d.keys():
q = d[i]
l.append(q ** 2 % 100)
l.sort()
if len(l) != 0:
s = str(l[0])
for i in l[1:]:
if i < 10:
s = s + '0' + str(i)
else:
s = s + str(i)
print(s)
else:
print(0)
[USACO1.1] 你的飞碟在这儿 Your Ride Is Here
题目描述
众所周知,在每一个彗星后都有一只 UFO。这些 UFO 时常来收集地球上的忠诚支持者。不幸的是,他们的飞碟每次出行都只能带上一组支持者。因此,他们要用一种聪明的方案让这些小组提前知道谁会被彗星带走。他们为每个彗星起了一个名字,通过这些名字来决定这个小组是不是被带走的那个特定的小组(你认为是谁给这些彗星取的名字呢?)。关于如何搭配的细节会在下面告诉你;你的任务是写一个程序,通过小组名和彗星名来决定这个小组是否能被那颗彗星后面的 UFO 带走。
小组名和彗星名都以下列方式转换成一个数字:最终的数字就是名字中所有字母的积,其中 A \texttt A A 是 1 1 1, Z \texttt Z Z 是 26 26 26。例如, USACO \texttt{USACO} USACO 小组就是 21 × 19 × 1 × 3 × 15 = 17955 21 \times 19 \times 1 \times 3 \times 15=17955 21×19×1×3×15=17955。如果小组的数字 m o d 47 \bmod 47 mod47 等于彗星的数字 m o d 47 \bmod 47 mod47,你就得告诉这个小组需要准备好被带走!(记住“ a m o d b a \bmod b amodb”是 a a a 除以 b b b 的余数,例如 34 m o d 10 34 \bmod 10 34mod10 等于 4 4 4)
写出一个程序,读入彗星名和小组名并算出用上面的方案能否将两个名字搭配起来,如果能搭配,就输出 GO,否则输出 STAY。小组名和彗星名均是没有空格或标点的一串大写字母(不超过
6
6
6 个字母)。
输入格式
第1行:一个长度为 1 1 1 到 6 6 6 的大写字母串,表示彗星的名字。
第2行:一个长度为 1 1 1 到 6 6 6 的大写字母串,表示队伍的名字。
输出格式
样例 #1
样例输入 #1
COMETQ
HVNGAT
样例输出 #1
GO
样例 #2
样例输入 #2
ABSTAR
USACO
样例输出 #2
STAY
提示
题目翻译来自 NOCOW。
USACO Training Section 1.1
题解
s1 = input().strip()
s2 = input().strip()
def zh(s):
q = ord(s) - 64
return q
n1 = 1
n2 = 1
for i in s1:
n1 = n1 * zh(i)
for i in s2:
n2 = n2 * zh(i)
if n1 % 47 == n2 % 47:
print('GO')
else:
print('STAY')

















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









