







一、进程间通信介绍
1.进程间为什么要进行通信?
进程间通信的是为了协调不同的进程,使之能在一个操作系统里同时运行,并相互传递、交换信息。
2.进程间通信的目的包括:
数据传输:一个进程需要将它的数据发送给另一个进程;
资源共享:多个进程间共享同样的资源;
通知事件:一个进程需要向另一个或一组进程发送消息,通知它们发生了某种事情,比如进程终止时需要通知其父进程;
进程间通信(IPC)是一组编程接口,让程序员能够协调不同的进程,使之能在一个操作系统里同时运行,并相互传递、交换信息;
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
3.进程间通信的分类:
(1)管道:1、匿名管道pipe;2、命名管道mkfifo
(2)System V IPC:1、System V 消息队列;2、System V 共享内存;3、System V 信号量。
(3) POSIX IPC:1、消息队列;2、共享内存;3、信号量;4、互斥量;5、条件变量;6、读写锁。
那么管道是如何进行通信的?
二、管道
什么是管道?
管道是一种通信机制,通常用于进程间的通信,它表现出来的形式将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
1.匿名管道
匿名管道是一种进程间通信机制,它仅限于本地父子进程之间通信,结构简单,类似于一根水管,一端进水另一端出水(单工)也就是只能够单向通信。匿名管道的作用之一是输出重定向。
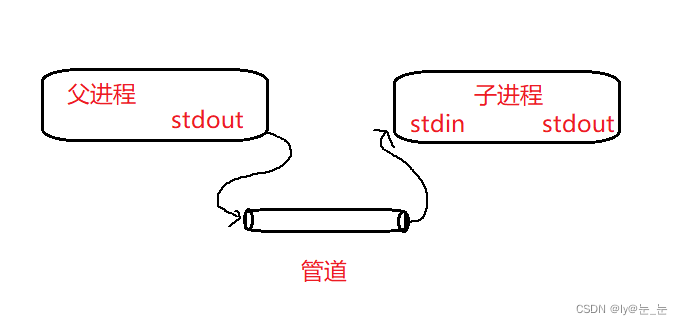
所以用匿名管道pipe通信大概分为四部:1、创建匿名管道;2、创建子进程;3、关闭不需要的文件描述符;4、进行通信。
pipe函数,linux中输入 man 2 pipe,可以查看pipe函数,如下:

#include <unistd.h>
功能:创建一无名管道
原型
int pipe(int pipefd[2]);
参数
pipefd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回-1和错误代码
1.1父进程和一个子进程之间的通信
接下来试着写一下,父进程向管道当中写“i am father”, 子进程从管道当中读出内容, 并且打印到标准输出;先创建管道, 进而创建子进程, 父子进程使用管道进行通信。
#include <iostream>
#include <cstring>
#include <cerrno>
#include <cassert>
#include <cstdio>
#include <unistd.h>
using namespace std;
int main()
{
//创建匿名管道
int pipefd[2] = {0}; //文件描述符数组
int n = pipe(pipefd);
if (n < 0) //如果失败,则打印错误码
{
cout << "pipe error, " << errno << ": " << strerror(errno) << endl;
}
cout << "读端:" << pipefd[0] << endl;
cout << "写端:" << pipefd[1] << endl; //打印出读写端的文件描述符
//创建子进程
pid_t id = fork(); //子进程中返回0,父进程返回子进程id,出错返会-1
assert(id != -1);
if (id == 0)
{
// child(子进程)
close(pipefd[1]); //关闭不需要的文件描述符,子进程需要读,所以关闭管道写端
//pipefd数组中0表示读端;1表示写端
char buffer[1024];//不管读数据还是写数据,都需要缓冲区,所以buffer相当于一个缓冲区
while (true)
{
sleep(1);
int n = read(pipefd[0], buffer, sizeof(buffer) - 1); //read函数
//sizeof为什么-1? 从文件中读取数据到buffer中,因为c语言中字符串的结束
//标志是'\0',而文件中的数据结束尾不需要'\0',所以buffer的内存要比读出
//数据内存大'\0';相反,往文件中写入数据时,要注意去掉字符串末尾的'\0',
//字符串末尾的'\0'在文件中会变成乱码(^@)
if (n > 0)
{
buffer[n] = '\0';
cout << "我是子进程,读取到父进程的数据: " << buffer << endl;
}
else if (n == 0)
{
cout << "我是子进程,读到了文件结尾" << buffer << endl;
break;
}
else
{
cout << "我是子进程,读取异常" << endl;
}
}
close(pipefd[0]); //关闭子进程中管道的读端
exit(0);
}
// father(父进程)
close(pipefd[0]); //父进程写入,关闭读端
int cnt = 1; //用来记录写了多少次
const string str = "i am father"; //要写入的内容
char buffer[1024];
while (true)
{
sleep(1);
snprintf(buffer, sizeof(buffer), "%s, 计数器:%d", str.c_str(), cnt++);//将数据写入到buffer中
write(pipefd[1], buffer, strlen(buffer));//再将buffer中的数据写入管道中
}
close(pipefd[1]); //关闭父进程中管道的写端
return 0;
}
下面是一些open,write,close等函数和文件描述符等有关概念:
系统方面对文件的打开,读写和关闭(open,write,close等用法)
文件描述符
运行结果如下:
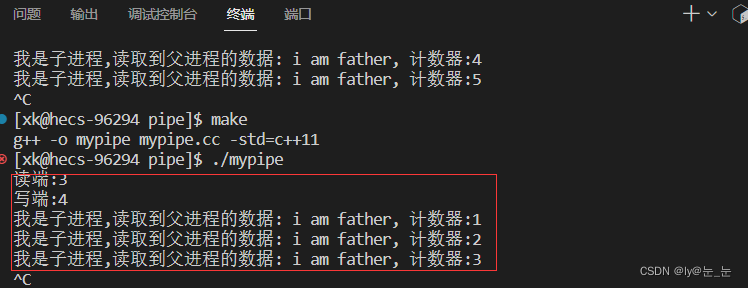
由下述代码看现象:
#include <iostream>
#include <cstring>
#include <cerrno>
#include <cassert>
#include <cstdio>
#include <unistd.h>
using namespace std;
int main()
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n < 0)
{
cout << "pipe error, " << errno << ": " << strerror(errno) << endl;
}
pid_t id = fork();
assert(id != -1);
if (id == 0)
{
// child
int cnt = 5;
close(pipefd[1]);
char buffer[1024];
while (--cnt)
{
sleep(1);
int n = read(pipefd[0], buffer, sizeof(buffer) - 1);
if (n > 0)
{
buffer[n] = '\0';
cout << buffer << endl;
}
else if (n == 0)
{
cout << "我是子进程,读到了文件结尾" << buffer << endl;
break;
}
else
{
cout << "我是子进程,读取异常" << endl;
}
}
close(pipefd[0]);
exit(0);
}
// father
close(pipefd[0]);
int cnt = 1;
const string str = "i am father";
char buffer[1024];
while (true)
{
sleep(1);
snprintf(buffer, sizeof(buffer), "%s, 计数器:%d", str.c_str(), cnt++);
write(pipefd[1], buffer, strlen(buffer));
}
close(pipefd[1]);
return 0;
}
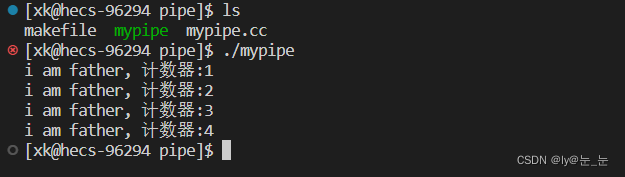
由上可知:
写端一直写,读端关闭OS会杀死一直在写入的进程。
将上述代码进行小的修改,就可以得到如下现象,代码就不在展示了,四种现象如下:
1.如果read读取完毕了所有的管道数据,如果对方不发,那么就只能等待;
2.如果我们writer端将管道写满了,那么就不能再写。管道的内存是有一定大小的;
3.如果我关闭了写端,读取完毕管道数据,再读,就会read返回0,表明读到了文件结尾;
4.写端一直写,读端关闭,会发生什么呢?没有意义。OS不会维护无意义,低效率,或者浪费资源的事情。OS会杀死一直在写入的进程! OS会通过信号来终止进程,13) SIGPIPE。
1.2父进程和多个子进程之间的通信
父进程写数据,子进程读取数据,父进程和多个子进程之间的通信,首先创建管道,代码如下:
void createProcess(vector<EndPoint> &end_points)
{
for (int i = 0; i < CHILDNUMS; ++i)
{
// 1.先创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0); // pipe函数成功返回0
(void)n; // linux中,定义一个变量,但是没使用,所以强转为void。(gcc编译可能报错)
// 2.创建子进程
pid_t id = fork();
assert(id != -1); // fork失败返回-1
if (id == 0)
{
// 子进程
// 关闭不需要的文件描述符,假设父进程写,子进程读
close(pipefd[1]); // pipe中1 为写端
char buffer[1024];
while (true)
{
//...进行读取
......
}
close(pipefd[0]); // 关闭读端
exit(0); // 关闭读端,子进程退出
}
// 父进程
close(pipefd[0]);
end_points.push_back(EndPoint(id, pipefd[1])); //将文件描述符管理起来
}
}
其中需要注意的是创建子进程,子进程是父进程的拷贝,所以当多次fork后,子进程中含有父进程指向管道的写端,如下图:
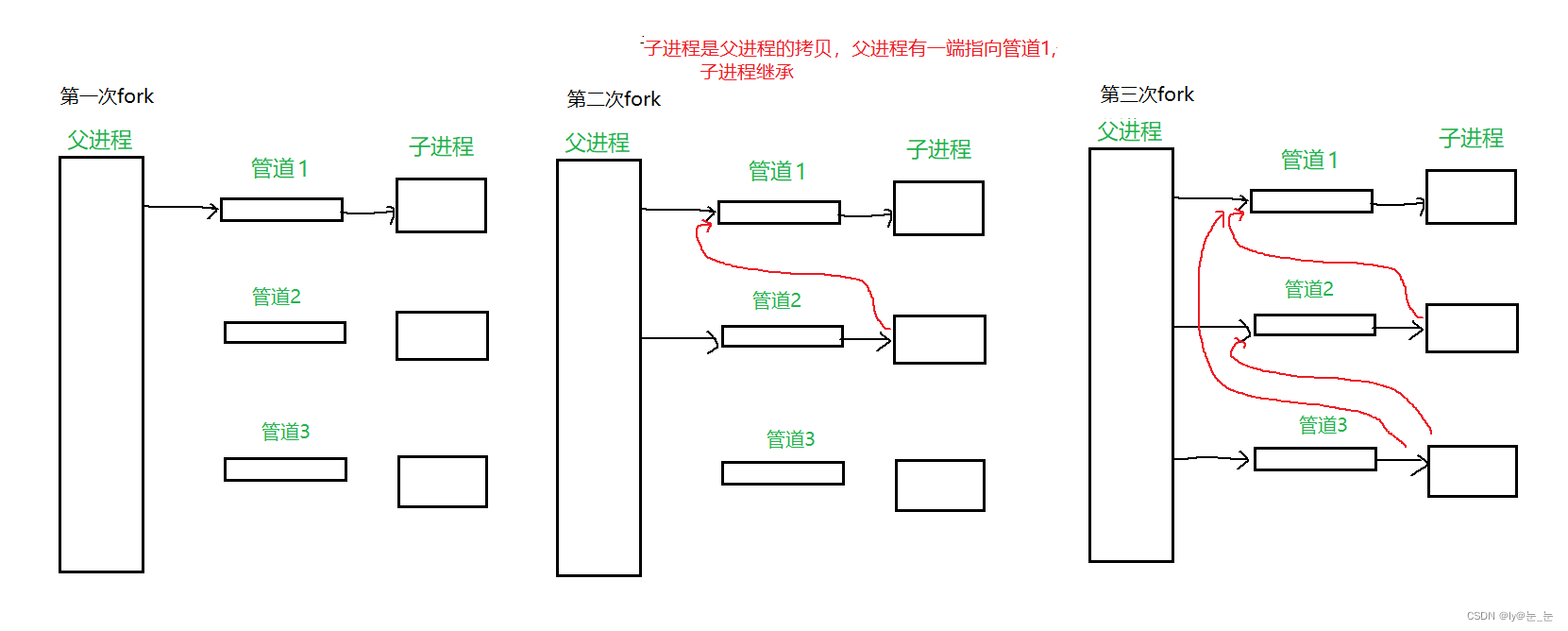
所以在创建管道时,需要关闭多余的管道,改进代码如下:
void createProcess(vector<EndPoint> &end_points)
{
vector<int> fds;
for (int i = 0; i < CHILDNUMS; ++i)
{
// 1.先创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0); // pipe函数成功返回0
(void)n; // linux中,定义一个变量,但是没使用,所以强转为void。(gcc编译可能报错)
// 2.创建子进程
pid_t id = fork();
assert(id != -1); // fork失败返回-1
if (id == 0)
{
//关闭子进程多余的fd
for(auto &fd : fds)
close(fd);
// 子进程
// 关闭不需要的文件描述符,假设父进程写,子进程读
close(pipefd[1]); // pipe中1 为写端
char buffer[1024];
while (true)
{
//...进行读取
......
}
close(pipefd[0]); // 关闭读端
exit(0); // 关闭读端,子进程退出
}
// 父进程
close(pipefd[0]);
end_points.push_back(EndPoint(id, pipefd[1]));
fds.push_back(pipefd[1]);
}
}
完整代码如下:
#include <iostream>
#include <vector>
#include <string>
#include <string.h> //strlen
#include <assert.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
#define CHILDNUMS 3 // 子进程的个数
class EndPoint
{
public:
EndPoint(pid_t id, int fd)
: _child_id(id), _write_fd(fd)
{
}
public:
pid_t _child_id;
int _write_fd;
};
void createProcess(vector<EndPoint> &end_points)
{
vector<int> fds;
for (int i = 0; i < CHILDNUMS; ++i)
{
// 1.先创建管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0); // pipe函数成功返回0
(void)n; // linux中,定义一个变量,但是没使用,所以强转为void。(gcc编译可能报错)
// 2.创建子进程
pid_t id = fork();
assert(id != -1); // fork失败返回-1
if (id == 0)
{
//关闭子进程多余的fd
for(auto &fd : fds)
close(fd);
// 子进程
// 关闭不需要的文件描述符,假设父进程写,子进程读
close(pipefd[1]); // pipe中1 为写端
char buffer[1024];
while (true)
{
int n = read(pipefd[0], buffer, sizeof(buffer) - 1);
if (n > 0)
{
buffer[n] = '\0';
cout << "我是pid=%d的子进程," << getpid() << ";接受到父进程的指令是:" << buffer << endl;
}
else if (n == 0)
{
cout << "我是子进程pid=" << getpid() << ",读到了文件结尾,并且父进程写端已关闭" << endl;
break;
}
else
{
cout << "我是子进程,读取异常" << endl;
}
sleep(1);
}
close(pipefd[0]); // 关闭读端
exit(0); // 关闭读端,子进程退出
}
// 父进程
close(pipefd[0]);
end_points.push_back(EndPoint(id, pipefd[1]));
fds.push_back(pipefd[1]);
}
}
void ctrlProcess(const vector<EndPoint> &end_points)
{
// 对每个子进程下发任务
char buffer[1024];
int command = 0;
int cnt = 0;
while (true)
{
cnt %= end_points.size();
cout << "输如命令号:";
cin >> command;
if (command == 0)
break;
snprintf(buffer, sizeof(buffer), "pid=%d的子进程处理%d任务", end_points[cnt]._child_id, command);
write(end_points[cnt]._write_fd, buffer, strlen(buffer));
++cnt;
sleep(1);
}
}
void waitProcess(const vector<EndPoint> &end_points)
{
// 需要让子进程全部退出 --- 只需要让父进程关闭所有的write_fd并且要回收子进程的僵尸状态
for (int end = 0; end < end_points.size(); ++end)
{
cout << "父进程让子进程退出:" << end_points[end]._child_id << endl;
close(end_points[end]._write_fd);
waitpid(end_points[end]._child_id, nullptr, 0); //waitpid不需要查看子进程退出信息,所以传nullptr
cout << "父进程回收了子进程:" << end_points[end]._child_id << endl;
}
}
int main()
{
cout << "命令号为0,则退出进程" << endl;
// 需要记录子进程的pid和父进程的写端
vector<EndPoint> end_points;
// 1. 先进行构建控制结构, 父进程写入,子进程读取
createProcess(end_points);
// 2.控制每个子进程
ctrlProcess(end_points);
// 3. 处理所有的退出问题
waitProcess(end_points);
return 0;
}
运行结果如下:

管道的特点:
- 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;
- 通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道;
- 管道提供流式服务;
- 一般而言,进程退出,管道释放,所以管道的生命周期随进程;
- 内核会对管道操作进行同步与互斥;
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。


















 1970
1970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











