






 本文详细介绍了Java中的数据结构,包括基本数据类型的包装类、集合与数组的区别、ArrayList和LinkedList的特点以及它们的特有方法。还深入讨论了Set集合,如HashSet和TreeSet,以及Map集合,如HashMap和TreeMap的底层原理。同时,文章提到了比较器的概念及其在自然排序和自定义排序中的应用。
本文详细介绍了Java中的数据结构,包括基本数据类型的包装类、集合与数组的区别、ArrayList和LinkedList的特点以及它们的特有方法。还深入讨论了Set集合,如HashSet和TreeSet,以及Map集合,如HashMap和TreeMap的底层原理。同时,文章提到了比较器的概念及其在自然排序和自定义排序中的应用。
目录
java的部分数据结构:
- 栈(弹夹):先进后出
- 队列(隧道):先进先出
- 数组:内存地址连续,有索引,增删慢(数组长度不可变,若要增删,就要对整个数组进行复值,再修改),查询快。
- 链表:内存地址分散,每个元素分为两部分(存储内容+下一个元素地址),没有索引,查询慢,增删快。
基本数据类型的包装类:
int -> Integer; cahr -> Character;其它的都是把首字母大写,基本没变
集合与数组的区别:
集合与数组的相同点:
都是容器,可以存储多个数据。
集合与数组的不同点:
- 数组的长度不可变的,集合的长度是可变的。
- 数组可以存储基本数据类型和引用数据类型,集合只能存储引用数据类型,如果要存储基本数据类型,需要存对应的包装类。
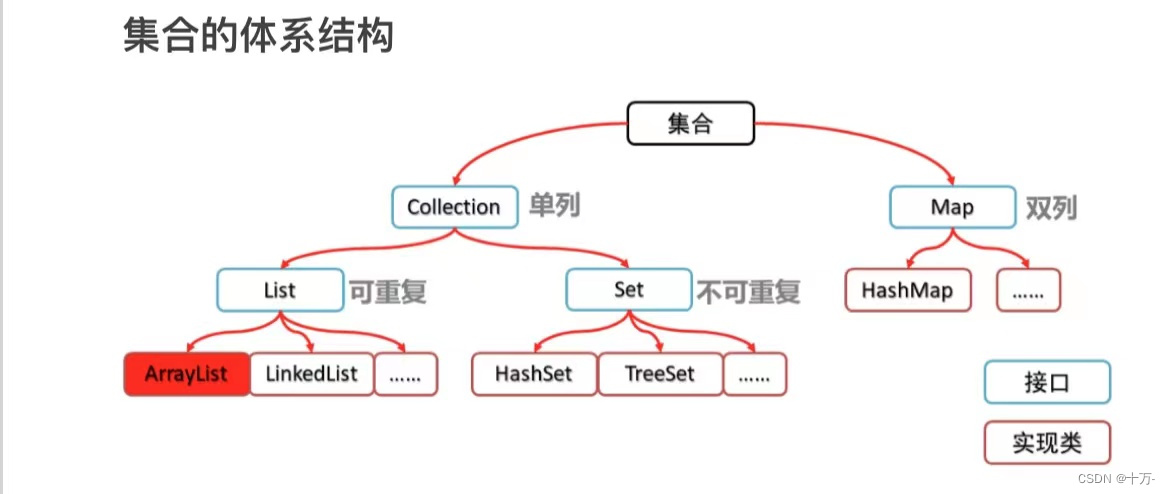
Collection常用方法:
ArrayList<String> list = new ArrayList();
//添加元素
list.add("aa");
//删除元素
list.remove(aa);
//1清空集合所有元素
lsit.clear();
//判断集合是否为空
list.isEmpty();
//判断是否包含某个元素
lsit.contains("aa");
迭代器的使用:
- 通过集合对象获取迭代器对象
- 通过hasNext()方法循环判断迭代器对象中是否还有元素
- 如果有元素,通过next()方法获取迭代器中的元素
迭代器原理分析:
- Iterator<E> iterator(): 获取迭代器对象,默认指向0索引
- boolean hasNext():判断当前位置是否有元素可以取出
- E.next(0:获取当前位置元素,将迭代器对象移向下一个索引位置
集合遍历方式使用场景:
三种遍历方式使用场景:
增强for循环:
对集合进行遍历时使用,遍历过程中如要增删元素不能使用,
普通for循环:
遍历过程中需要增删元素或操作索引时使用
迭代器:
遍历过程中删除元素使用
List:
list集合概述:
list集合是单列集合体系之一
list集合特点:
- list集合及其实现类全部都有索引
- list集合及其实现类全部都是可以存储重复元素
- list集合及其实现类全部都是元素存取有序
ArrayList<String> list = new ArrayList();
//list特有方法,可以根据索引删除添加指定位置
//修改指定位置元素
lsit.set(2,"ee");
//根据索引获取指定元素
list.get(2);ArrayList特点:
底层数据结构是数组:查询快,增删慢
LinkedList特点:
底层数据结构是链表:查询慢,增删快
查询慢:因为需要从一侧开始依次查询
增删快;增删元素后,不需要动元素位置,只需要修改元素指向
LinkedList特有方法:

Set集合:
set集合的特点:
- 不能存储重复元素
- 没有索引
哈希值;
哈希值是JDK根据对象的地址或者字符串或者数字计算出来的int类型的数值。
获取哈希值对象:int hascCode();返回对象的哈希码值。
HeshSet集合:
- 底层数据结构是哈希表
- 对集合的迭代顺序不作保证,不保证存储与取出的元素顺序一致
- 没有索引,所以不能使用普通for循环遍历
- 由于是set集合的实现类,所以不能有重复元素(去重)

数据结构之哈希表:
- JDK8之前,底层采用数组+链表实现(链表的数组)
- JDK8之后,在长度较大的时候,底层进行了优化,
TreeSet集合:
特点:
- 元素有序,这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法
TreeSet():根据其元素的自然顺序进行排序
TreeSet(Comparator<?superE> compartor):根据指定的比较器进行排序
- 没有索引,所以不能通过普通for循环遍历
- 不包含重复元素
比较器:
自然排序:Comparable
- 使用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序
- 自然排序就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写方法时,一定要注意排序规则,必须按照要求的主要条件和次要条件来写
/用接口实现排序规则,不用在treeset后面new Comparator<Student>
//this:前,o:后
@Override
public int compareTo(Student o) {
int age = this.getAge() - o.getAge();
if (age == 0){
age = this.getName().length() - this.getName().length();
}
return age;
}选择排序:comparator
- 使用TreeSet集合存储自定义对象,有参构造方法使用的是比较器排序对元素进行排序
/比较器
//要求,字符串按照升序排列
//自定义排序规则
public class demo2 {
public static void main(String[] args) {
TreeSet<String> set = new TreeSet<>(new Comparator<String>() {
//在方法里面自定义排序规则
//口诀:前减后升(从小到大),后减前降(从大到小)
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length();//升序
}
});
set.add("aa");
set.add("aaa");
set.add("ddd");
set.add("ggggg");
System.out.println(set);
}
}
前减后升(从小到大),后减前降(从大到小)
两种排序方式的比较:
自然排序:
- 自定义类实现Comparable接口
- 重写compareTo方法,根据返回值进行排序
选择排序:
- 创建TreeSet对象的时候传递Comparator的实现类对象
- 重写compare方法,根据返回值进行排序
在使用的时候,默认使用自然排序,如果无法满足需求时,必须使用比较器排序。
Map集合:
map集合的特点:
- 双利集合,一个键对应一个值
- 键不可以重复,值可以重复
map集合常用方法:
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
//添加数据
map.put("杨过","小龙女");
map.put("郭靖","黄蓉");
map.put("李白","凤求凰");
//清空集合
//map.clear();
//集合元素长度
int size = map.size();
System.out.println("size = " + size);
//判断是否没有元素
boolean empty = map.isEmpty();
System.out.println("empty = " + empty);//没有元素就是true有元素就是false
//判断集合是否包含某个key
boolean a = map.containsKey("aa");
System.out.println("a = " + a);
//判断是否包含某个value
boolean s = map.containsValue("小龙女");
System.out.println("s = " + s);
//size和length获取长度的区别
int[] arr = new int[3];
System.out.println("arr = " + arr.length);//没有小括号是属性
int size1 = map.size();//有小括号是方法
System.out.println("size1 = " + size1);
System.out.println(map);
}map集合遍历方式:
//1.遍历集合
//keyset方法获取所有键的值,返回set集合
Set<String> keys = map.keySet();
//循环set集合得到每一个key
for (String key : keys) {
//根据key获取value
String s = map.get(key);
System.out.println( s);
}
System.out.println("-------------");
//2.entrySet遍历集合(不常用)
//获取键值对的set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
//遍历set集合,在得到每一个键值对
for (Map.Entry<String, String> entry : entries) {
//根据
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+":"+value);HashMap集合底层原理:
HashMap底层是哈希表,依赖HashCode和equals方法保证方法的唯一
TreeMap底层原理:
TreeMap底层是红黑树,依赖自然排序和比较器进行排序,对键进行排序

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









