



 本文分享了一位非IT背景者学习并制作爬虫的心路历程,使用了Python的Scrapy和Selenium,描述了遇到的挑战、解决方案和学习过程中所需的时间。作者强调了实践和探索的重要性,以及从错误中学习和成长的过程。
本文分享了一位非IT背景者学习并制作爬虫的心路历程,使用了Python的Scrapy和Selenium,描述了遇到的挑战、解决方案和学习过程中所需的时间。作者强调了实践和探索的重要性,以及从错误中学习和成长的过程。
这是一篇记录我做第一个爬虫的心路历程的文章,不是教程,但是可以让所有想要学习爬虫的小白对自己有一点点信心。我的学习背景是景观设计+城市规划,因此也是在告诉大家,小白也能学,只是真的比较花时间。
从打算写爬虫爬数据做我的小项目到真正让爬虫跑起来,花了我近三周的时间,大约是120个小时了。这个速度在专业人员看来并不快,因为我相当于全职两个多星期在学一个新的东西。但是也不要紧,最终是为了让自己能够用起来,因为我的需求并不能被类似于火车头这样的采集软件满足。
我的基础还属于初级中的初级。Python入门是一年前密歇根大学在coursera上开的python for everybody。那时候学了个beautiful soup勉强可以照着教程做一遍爬个经纬度,现在具体怎么做又都忘了。研究生期间在学校又上了一门intro to java,也是个入门水平,之后也没有什么实际编程经验。这次出于实际需要自己写个爬虫,而且需要采集的数据比较多,也没法管自己水平如何就上了。
用的什么IDE:
我用的是Pycharm 的Scrapy + Selenium。选择Pycharm非常偶然,因为我在Youtube看到的爬虫系列视频里的例子用的是Pycharm。后来朋友告诉我Anacond + Jupter也很好用,但我已经上了贼船。
过程:其实这就是一个慢慢探索的过程,伴随着好奇,沮丧,欣喜,失落等等小情绪。
- 盲目探索阶段--我就是照着视频做和学。视频说什么我就做什么。知道自己记忆力差所以把视频的关键点和链接都存储起来,方便回头翻看。(大约3天)
- 对自己的需求做分析--我想要采集的信息,用什么采集方便,需要存储成什么比较好。我开始想存成sqlite,但是后来实践发现csv实在是操作起来更方便。而关于怎么采集数据,是最耗费脑细胞的地方。最开始我的想法是,先自己把局部要实现的功能都自己写出来,然后挪用到scrapy框架里面,这样应该是最稳妥不容易出错的方式。(大约6天)
-这里面出现了很多打脸的情况,也踩了很多坑。
第一个坑就是我明明按照视屏里教的方法去采集标签,但是有些内容在网站上显示却怎么也扒不下来!!这部分内容却是我要采集的核心,为此我一开始以为是自己的代码问题,检查了一天都没搞明白问题出在哪里。晚上老公回来看了看,告诉我是Javascript渲染导致的问题。第二天我顺着这个思路去查,果然有了解决方法,接下来是选择什么路径去解决这个问题。吭哧吭哧装了半天splash和docker,我才发现自己的机器不支持docker。。含泪告别splash,入了Selenium的坑。Selenium实际上是个测试软件,爬虫倒是顺便之举。但是不管怎么说,黑猫白猫能抓老鼠就是好猫。终于爬出了技术路线的坑(2天)
还没喘口气,第二个坑又来了。这次是自己设想的局部模块如何嵌到Scrapy框架里去。我花了大概1天的时间把selenium很好地在自己的一个文件里实现了,可是scrapy是个框架,一打眼6,7 个python文件,它们是怎么互相调用的?我的代码该放在哪?虽然之前看着视频能做出来,可是视频教的实在是太基础了,我又不知道怎么办了。这时候我忽然想起来,类似的问题前人肯定也遇见过,要不改用中文搜搜看,果然有大神提到了类似的例子!这次又离成功近了一小步。(2天)
紧接着是第三个坑。我要爬的网站好巧不巧更新了,我原来设想的依靠Selenium自动输入关键字-点击-搜索-进入下一个页面的方法不能用了。网站现在需要明确搜索的是ID还是地址,而且enter只能是在输入完全符合的关键字,不符合的话连搜索都不进行(手动输入+Enter都不行了)。我绝望地发现自己原来设计的流程又被推翻了。(1天)
- 重新设计流程。实际上这是我之前想过的一种可能方法,因为很早就观察到我需要爬的网站实际上是有规律的,只是里面需要再去寻找关键字(住宅地址)对应的id,一个关键字对一个ID,想想我要爬10万个住宅地址,那就是10万个id。但是反过来想,这个ID我要去哪找呢?所幸我从网站上获取了所有住宅的gis信息(这是个外国网站),而这个网站也提供给地址查id的选项。于是,我的爬虫流程变成了两部分: 第一步是先爬取id,第二步再用住宅地址和id爬取我要的信息。(1天)
- 从框架的角度入手重新写爬虫。这次我听从老公的建议,老老实实去看了一下说明文档。虽然看完依然懵懂,但是比刚开始对着视频做在理解scrapy上还是有了飞跃。我依然无法清楚地解释什么是middlewares什么是pipeline,但它们大概是干什么的,谁把什么传给了谁,大概是清楚了一点。于是折腾了一大圈,我就是要告诉你看说明书操作就好?很不幸是这样,我发现自己要实现自己想要的那个功能,就是绕了这么一大圈还是回到了原点。看完说明书也不是立刻就懂得如何去做,但是我倒回去看别人的例子,才理解为什么他们修改特定文件的用意。当我觉得自己能够理解scrapy基本的运作原理之后,把自己的代码嵌入scrapy也不是那么困难了。(4天)
最后送上一张scrapy 框架的原理图。
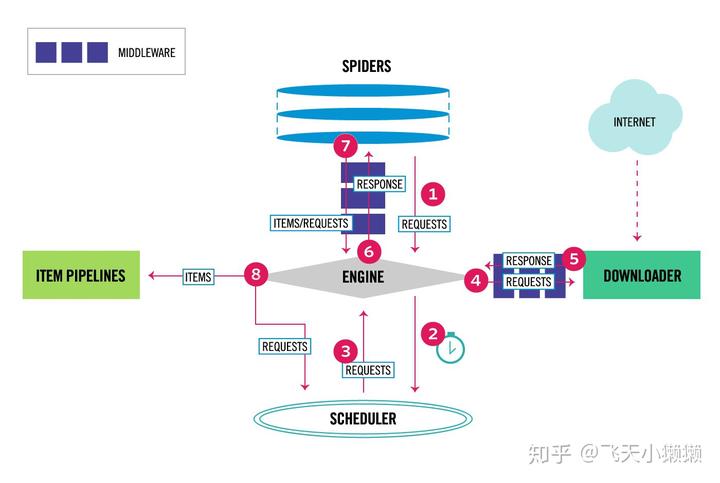
这张图,我看到了不下十次,但是最后才觉得自己“大概”看懂了。也许有一天我真正觉得自己看懂了,回来再看这段文字会想笑吧
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至优快云官方,朋友如果需要可以直接微信扫描下方优快云官方认证二维码免费领取【保证100%免费】。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









