






 本文详细介绍了HUNST数据挖掘课程中的实验一——使用Apriori算法设计与应用。主要内容包括Apriori算法的工作原理、程序流程图、Java代码实现、实验步骤、结果分析以及算法在大规模数据处理中的效率挑战。
本文详细介绍了HUNST数据挖掘课程中的实验一——使用Apriori算法设计与应用。主要内容包括Apriori算法的工作原理、程序流程图、Java代码实现、实验步骤、结果分析以及算法在大规模数据处理中的效率挑战。
HNUST 数据挖掘课设 《实验一 Apriori算法设计与应用》
实验所有代码数据链接:https://pan.quark.cn/s/a8309767fd94
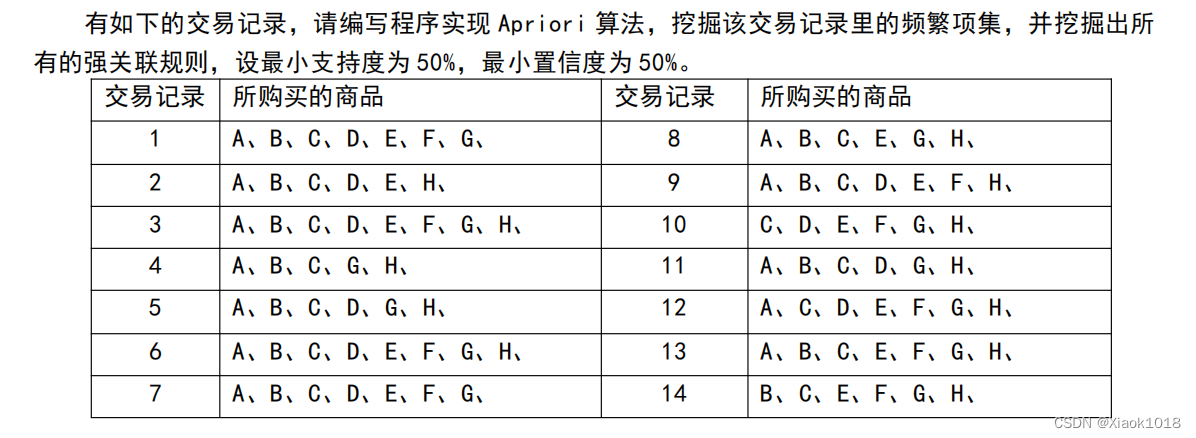
一、实验内容
1.实验要求
- 实验原理
Apriori算法通过对数据库的多次扫描来计算项集的支持度,发现所有的频繁项集从而生成关联规则。Apriori算法对数据集进行多次扫描,第一次扫描得到频繁1-项集,第k(k>1)次扫描首先利用第(k-1)次扫描的结果来产生候选k-项集的集合,然后在扫描过程中确定中元素的支持度,最后在每一次扫描结束时计算频繁k-项集的集合,算法在当候选k-项集的集合为空时结束。
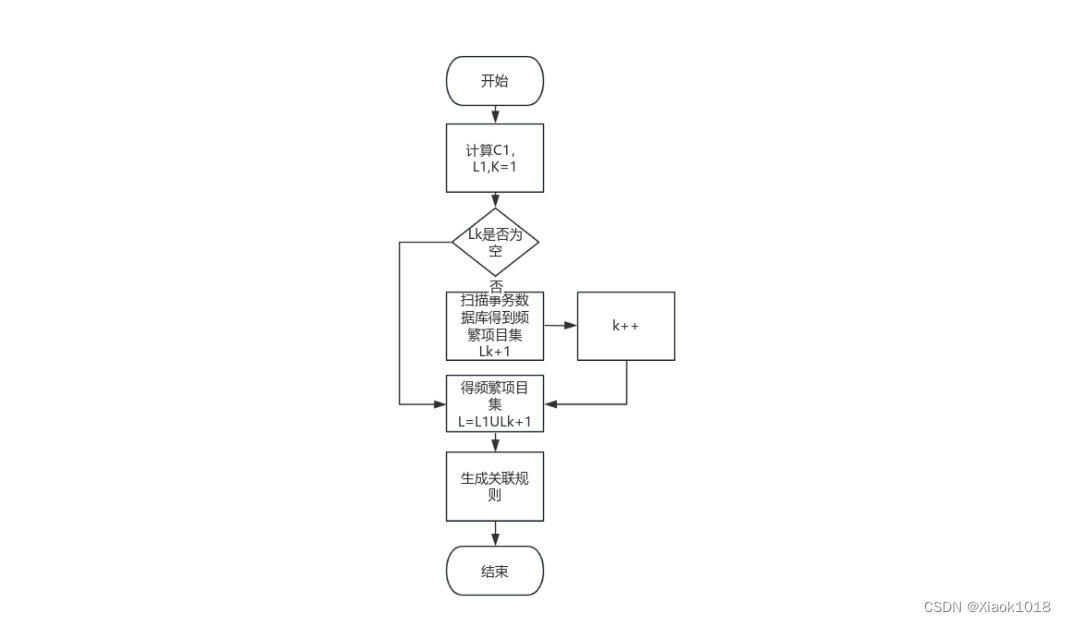
3.程序流程图
二、代码
```java
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
/**
* Created by 23222 on 2023/12/11.
*/
public class GenerateRules {
public static void main(String[] args){
// double minSupport = 0.4;
// double minConfidence=0.6;
Scanner scanner = new Scanner(System.in);
System.out.print("Enter the minSupport: ");
double minSupport = scanner.nextDouble();
System.out.print("Enter the minConfidence: ");
double minConfidence = scanner.nextDouble();
// 读取事务数据库
String filename = "../1-Aprior/dataset.txt";
List<List<String>> transactions = readTransactions(filename);
for (List<String> transaction : transactions) {
System.out.println(transaction);
}
// 生成频繁项目集
Map<Set<String>, Integer> FrequentItemsets = generateFrequentItemsets(transactions, minSupport);
//生成最大频繁项目集
Map<Set<String>, Integer> maxFrequentItemsets=genrateMaxF(FrequentItemsets);
// 生成关联规则
generateAssociationRules(minConfidence,FrequentItemsets);
}
public static List<List<String>> readTransactions(String filename) {
List<List<String>> transactions = new ArrayList<>();
try (BufferedReader br = new BufferedReader(new FileReader(filename))) {
String line;
boolean firstLine = true;
while ((line = br.readLine()) != null) {
if (firstLine) {
firstLine = false;
continue;
}
String[] parts = line.split("\t");
String[] items = parts[1].split(", ");
transactions.add(Arrays.asList(items));
}
} catch (IOException e) {
e.printStackTrace();
}
return transactions;
}
public static Map<Set<String>, Integer> generateFrequentItemsets(List<List<String>> transactions, double minSupport) {
Map<Set<String>, Integer> FrequentItemsets = new HashMap<>();
// 获取长度为1的项并计算初始支持度
for (List<String> transaction : transactions) {
for (String item : transaction) {
Set<String> candidate = new HashSet<>();
candidate.add(item);
FrequentItemsets.put(candidate, FrequentItemsets.getOrDefault(candidate, 0) + 1);
}
}
// 保留支持度不小于最小支持度的1-项目集
FrequentItemsets.keySet().removeIf(itemset -> {
double support = (double) FrequentItemsets.get(itemset) / transactions.size();
if (support < minSupport) {
return true;
}
return false;
});
Map<Set<String>, Integer> frequentItemsets = new HashMap<>(FrequentItemsets);
System.out.println("-------------------1-item--------------------------------");
for (Map.Entry<Set<String>, Integer> entry : FrequentItemsets.entrySet()) {
Set<String> itemset = entry.getKey();
int support = entry.getValue();
System.out.println(itemset + " => " + support);
}
System.out.println("--------------------------------------------------------");
int k = 2;
while (!frequentItemsets.isEmpty()) {
Map<Set<String>, Integer> candidateItemsets = generateCandidateItemsets(frequentItemsets.keySet(), k);
frequentItemsets.clear();
System.out.println("------------------" + k + "-candidate---------------------------");
if (!candidateItemsets.isEmpty()) {
// 计算k-候选项目集的支持度
for (List<String> transaction : transactions) {
for (Set<String> itemset : candidateItemsets.keySet()) {
if (transaction.containsAll(itemset)) {
candidateItemsets.put(itemset, candidateItemsets.get(itemset) + 1);
}
}
}
for (Map.Entry<Set<String>, Integer> entry : candidateItemsets.entrySet()) {
Set<String> itemset = entry.getKey();
int support = entry.getValue();
System.out.println(itemset + " => " + support);
}
} else System.out.println("【空】");
System.out.println("-------------------------------------------------------");
// 遍历候选项集并删除支持度小于最小支持度的项目
candidateItemsets.keySet().removeIf(itemset -> {
int count = candidateItemsets.get(itemset);
double support = (double) count / transactions.size();
if (support < minSupport) {
return true;
}
return false;
});
FrequentItemsets.putAll(candidateItemsets);
frequentItemsets.putAll(candidateItemsets);
/* for (Set<String> itemset : frequentItemsets.keySet()) {
int support = frequentItemsets.get(itemset);
System.out.println("f-频繁项集: " + itemset + ", 支持度: " + support);
}*/
System.out.println("-------------------" + k + "-item------------------------------");
if (!candidateItemsets.isEmpty()) {
for (Map.Entry<Set<String>, Integer> entry : frequentItemsets.entrySet()) {
Set<String> itemset = entry.getKey();
int support = entry.getValue();
System.out.println(itemset + " => " + support);
}
} else System.out.println("【空】");
System.out.println("--------------------------------------------------------");
k++;
}
// 输出频繁项目集
List<Map.Entry<Set<String>, Integer>> sortedFrequentItemsets = new ArrayList<>(FrequentItemsets.entrySet());
Collections.sort(sortedFrequentItemsets, new Comparator<Map.Entry<Set<String>, Integer>>() {
@Override
public int compare(Map.Entry<Set<String>, Integer> entry1, Map.Entry<Set<String>, Integer> entry2) {
int length = Integer.compare(entry1.getKey().size(), entry2.getKey().size());
if (length != 0) {
return length; // 先按长度排序
} else {
return entry1.getKey().hashCode() - entry2.getKey().hashCode(); // 长度相同时按哈希值排序
}
}
});
int i=0;
System.out.println("-------------------【所有的频繁项目集】-----------------");
for (Map.Entry<Set<String>, Integer> entry : sortedFrequentItemsets) {
i++;
if (i%9==0) System.out.println();
System.out.print(entry.getKey());
}
System.out.println();
return FrequentItemsets;
}
// 生成K-候选项目集
public static Map<Set<String>, Integer> generateCandidateItemsets(Set<Set<String>> frequentItemsets, int k) {
Map<Set<String>, Integer> candidateItemsets = new HashMap<>();
for (Set<String> itemset1 : frequentItemsets) {
for (Set<String> itemset2 : frequentItemsets) {
if (k == 2) {
Set<String> connection = Connection(itemset1, itemset2);
if (connection.size() == k && hasInfrequentSubsets(connection, frequentItemsets, k - 1)) {
candidateItemsets.put(connection, 0);
}
} else if (k!=1){
List<String> list1 = new ArrayList<>(itemset1);
List<String> list2 = new ArrayList<>(itemset2);
List<String> subList1 = list1.subList(0, k - 2);
List<String> subList2 = list2.subList(0, k - 2);
if (subList1.equals(subList2)) {
Set<String> connection = Connection(itemset1, itemset2);
if (connection.size() == k && hasInfrequentSubsets(connection, frequentItemsets, k - 1)) {
candidateItemsets.put(connection, 0);
}
}
}
}
}
return candidateItemsets;
}
private static Set<String> Connection(Set<String> itemset1, Set<String> itemset2) {
Set<String> connection = new HashSet<>(itemset1);
connection.addAll(itemset2);
return connection;
}
private static boolean hasInfrequentSubsets(Set<String> connection, Set<Set<String>> frequentItemsets, int k) {
List<String> list = new ArrayList<>(connection);
for (int i = 0; i < list.size(); i++) {
// 生成长度为 K-1 的子集
List<String> subList = new ArrayList<>(list);
subList.remove(i);
Set<String> subsetSet = new HashSet<>(subList);
if (!containsSubset(frequentItemsets, subsetSet)) {
return false;
}
}
return true;
}
private static boolean containsSubset(Set<Set<String>> frequentItemsets, Set<String> subsetSet) {
for (Set<String> itemset : frequentItemsets) {
if (itemset.containsAll(subsetSet)) {
return true;
}
}
return false;
}
private static List<Set<String>> generateSubsets(Set<String> itemset) {
List<Set<String>> subsets = new ArrayList<>();
for (int i = 0; i < (1 << itemset.size()); i++) {
Set<String> subset = new HashSet<>();
int index = 0;
for (String item : itemset) {
if ((i & (1 << index)) >0) {
subset.add(item);
}
index++;
}
if (subset.size() > 0 && subset.size() <=itemset.size()) {
subsets.add(subset);
}
}
return subsets;
}
public static Map<Set<String>, Integer> genrateMaxF(Map<Set<String>, Integer> FrequentItemsets){
Map<Set<String>, Integer> maxFrequentItemsets=new HashMap<>();
for (Map.Entry<Set<String>, Integer> entry : FrequentItemsets.entrySet()) {
Set<String> itemset = entry.getKey();
int support=entry.getValue();
boolean isMax = true;
// 检查itemset是否被其他频繁项目集包含
for (Map.Entry<Set<String>, Integer> entry2 : FrequentItemsets.entrySet()) {
Set<String> otherItemset = entry2.getKey();
if (otherItemset.equals(itemset)) {
continue;
}
if (otherItemset.containsAll(itemset)) {
isMax = false;
break;
}
}
// 将不被其他频繁项目集包含的itemset添加到最大频繁项目集中
if (isMax) {
maxFrequentItemsets.put(itemset,support);
}
}
System.out.println("-------------------【最大频繁项目集】-----------------");
for (Map.Entry<Set<String>, Integer> entry : maxFrequentItemsets.entrySet()) {
System.out.println(entry.getKey());
}
System.out.println("-----------------------------------------------------------------------------");
return maxFrequentItemsets;
}
public static void generateAssociationRules(double minConfidence,Map<Set<String>, Integer> FrequentItemsets) {
System.out.println("关联规则;");
for (Set<String> itemset : FrequentItemsets.keySet()) {//所有键的 Set 集合
if (itemset.size() > 1) {
List<Set<String>> subsets = generateSubsets(itemset);
System.out.println("------------------------------------------------------------------");
System.out.println(itemset);
for (Set<String> subset : subsets) {
int i=0;
if (subset.equals(itemset)) {
continue;}
Set<String> remaining = new HashSet<>(itemset);
remaining.removeAll(subset);
int subsetSupportCount = FrequentItemsets.get(subset); // 获取子集的支持度计数
double confidence = (double) FrequentItemsets.get(itemset) /subsetSupportCount;
if (confidence >= minConfidence) {
System.out.println(subset + " => " + remaining);
}
}
}
}
}
}
三、实验结果与分析
| LK | 频繁项目集 |
|---|---|
| L1 | A、B、C、D、E、F、G、H |
| L2 | AB、AC、AD、AE、AF、AG、AH、BC、BD、BE、BF、BG、BH、CD、CE、CF、CG、CH、DE、DF、DG、DH、EF、EG、EH、FG、FH、GH |
| L3 | ABC、ABD、ABE、ABG、ABH、ACD、ACE、ACF、ACG、ACH、ADE、ADG、ADH、AEF、AEG、AEH、AGH、BCD、BCE、BCF、BCG、BCH、BEF、BEG、BEH、BGH、CDE、CDF、CDG、CDH、CEF、CEG、CEH、CFG、CFH、CGH、DEF、EFG、EFH、EGH、 |
| L4 | ABCD、ABCE、ABCG、ABCH、ABGH、ACDE、ACDG、ACDH、ACEF、ACEG、ACEH、ACGH、BCEF、BCEG、BCEH、BCGH、CDEF、CEFG、CEFH、CEGH |
| L5 | ABCGH |

利用Aprior算法挖掘交易记录里的频繁项集,并挖掘出强关联规则(部分)如上,Aprior算法是通过项目集元素数目的不断增长来逐步完成频繁项目集的发现,利用频繁项目集生成关联规则就是逐一测试在所有频繁集中可能生成的规则以及参数,在实验中我是通过深度优先搜索的方法来递归生成关联规则的。
四、小结与心得体会
Aprior算法是关联规则挖掘领域中经典的算法,通过挖掘数据中的关联规则,帮助人们理解数据之间的关系,发现潜在的模式和规律。这对于业务决策、优化流程、改进服务等方面都具有实际的应用价值。但是,Apriori 算但在处理大规模数据时可能存在一些效率方面的挑战,它需要多次扫描整个数据集,产生候选项集并计算它们的支持度,这种多次迭代的计算可能导致较大的计算开销。

















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









