






1. Maven
-
Apache Maven是一个项目管理和构建工具,它基于项目对象模型(POM[Project Object Model])的概念,通过一小段描述信息来管理项目的构建
-
Apache软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性组织
-
官网:http://maven.apache.org/
-
开源项目:https://www.apache.org/index.html#projects-list
1.1 maven的作用
- 依赖管理:方便快捷的管理项目依赖的资源(jar包),避免版本冲突问题
- 统一项目结构:提供标准,统一项目结构
- 项目构建:标准跨平台(Linux,windows,MacOS)的自动化项目构建方式
maven项目目录:
| main | 实际项目资源 |
|---|---|
| java | Java源代码目录 |
| resources | 配置文件目录 |
| test(java,resources) | 测试项目资源 |
| pom.xml | 项目配置文件 |
1.1.2 仓库
用于存储资源,管理各种jar包
- 本地仓库:自己计算机上的一个目录
- 中央仓库:由Maven团队维护的全球唯一的,仓库地址:https://repo1.maven.org/maven2/
- 远程仓库(私服):一般由公司团队搭建的私有仓库
1.2 IDEA集成
1.2.1 安装maven
-
解压apache-maven-3.5.3-bin.zip
-
配置本地仓库:修改conf/settings.xml中的为一个指定目录
<localRepository>D:\maven\repository</localRepository> -
配置阿里云私服(用来提高下载速度):修改conf/settings.xml中的标签,为其添加如下子标签:
<mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> -
配置环境变量:MAVEN_HOME为maven的解压目录,并将其bin目录加入PATH环境变量
1.2.2 配置Maven环境
- 选择IDEA中File–>Settings–>Build,Execution,Deployment–>Build Tools–>Maven
- 设置IDEA使用本地安装的Maven,并修改配置文件及本地仓库
1.2.3 IDEA创建Maven项目
- 创建模块,选择Maven,点击Next
- 填写模块名称,坐标信息,点击finish,创建完成
- 编写代码并运行,进行测试
1.2.4 IDEA导入Maven项目
方式一:打开IDEA,选择右侧Maven面板,点击+号,选中对应项目的pom.xml文件,双击即可
方式二:打开IDEA,选择File–>Project Structure–>Modules,点击+号,选择import Module,选中对应项目的pom.xml文件,点击apply
1.3 maven坐标
- maven中的坐标是资源的唯一标识,通过该坐标可以唯一定位资源位置
- 使用坐标来定义项目或引入项目中需要的依赖
1.3.1 maven坐标主要组成
- groupld:定义当前Maven项目隶属组织名称(通常是域名反写)
- artifactld:定义当前Maven项目名称(通常是模块名称)
- version:定义当前项目版本号
2. 依赖管理
2.1 依赖配置
- 依赖:指在当前项目运行所需要的jar包,一个项目中可以引入多个依赖
- 配置:
- 在pom.xml中编写标签
- 在标签中使用引入坐标
- 定义坐标的groupld,artifactld,version
- 点击刷新按钮,引入最新加入的坐标
如果引入依赖,在本地的仓库不存在,将会连接远程仓库/中央仓库,然后下载依赖
如果不知道依赖的坐标信息,可以到https://mvnrepository.com/中搜索
2.2 依赖传递
依赖具有传递性
- 直接依赖:在当前项目中通过依赖配置建立的依赖环境
- 间接依赖:被依赖的资源如果依赖其他资源,当前项目间接依赖其他资源
2.3 排除依赖
排除依赖指主动断开依赖的资源,被排出的依赖无需指定版本
<exclusion>
<groupld>被排除的依赖</groupld>
<artifactld>被排除的依赖</artifactld>
</exclusion>
2.4 依赖范围
依赖的jar包,默认情况下,可以在任何地方使用,可以通过…设置其作用范围
作用范围:
- 主程序范围有效(main文件夹范围内)
- 测试程序范围有效(test文件夹范围内)
- 是否参与打包运行(package指令范围内)
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
2.5 生命周期
Maven的生命周期就是为了对所有的maven项目构建过程进行抽象和统一
Maven中有3套相互独立的生命周期:
- clean:清理工作
- default:核心工作,如:编译,测试,打包,安装,部署等
- site:生成报告,发布站点等
每一套生命周期包含一些阶段(phase),阶段是由顺序的,后面的阶段依赖于前面的阶段
生命周期阶段:
- clean:移除上一次构建生成的文件
- compile:编译项目源代码
- test:使用合适的单元测试框架进行测试(junit)
- package:将编译后的文件打包,如:jar,war等
- install:安装项目到本地仓库
执行指定生命周期的两种方式:
- 在IDEA中,右侧的maven工具栏,选中对应的生命周期,双击执行
- 在命令行中,通过命令执行
2. HTTP
- Hyper Text Transfer Protocol,超文本传输协议,规定了浏览器和服务器之间数据传输的规则
- 特点:
- 支持客户/服务器模式。
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有
GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。 - 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由
Content-Type加以标记。 - 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。早期这么做的原因是请求资源少,追求快。后来通过
Connection: Keep-Alive实现长连接 - 无状态:
HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快
2.1 请求协议
HTTP-请求数据格式
- 请求行:请求数据第一行(请求方式,资源路径,协议)
- 请求头:第二行开始,格式key:value
| Host | 请求的主机名 |
|---|---|
| User-Agent | 浏览器版本,例如Chrome浏览器的标识类似Mozilla/5.0…Chrome/79 |
| Accept | 表示浏览器能接收的资源类型 |
| Accept-Language | 表示浏览器偏好的语言,服务器可以据此返回不同语言的网页 |
| Accept-Encoding | 表示浏览器可以支持的压缩类型,如gzip,deflate等 |
| Content-Type | 请求主体的数据类型 |
| Content-Length | 请求主体的大小(单位:字节) |
- 请求体:POST请求,存放请求参数
请求方式
- 请求方式-GET:请求参数在请求行中,没有请求体,如:/brand/findAll?name=OPPO&status=1,GET请求大小是有限制的
- 请求方式-POST:请求参数在请求体中,POST请求大小是没有限制的
2.2 响应协议
HTTP-响应格式
- 响应行:响应数据第一行(协议,状态码,描述)
- 响应头:第二行开始,格式key:value
- 响应体:最后一部分,存放响应数据
| 1xx | 响应中-临时状态码,表示请求已经接收,告诉客户端应该继续请求或者 |
|---|---|
| 2xx | 成功-表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向-重定向到其他地方,让客户端再发起一次请求以完成整个处理 |
| 4xx | 客户端错误-处理发生错误,责任在客户端,如:请求了不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器错误-处理发生错误,责任在服务端,如:程序抛出异常 |
| Content-Type | 表示该响应内容的类型,例如text/html,application/json |
|---|---|
| Content-Length | 表示该响应内容的长度(字节数) |
| Content-Encoding | 表示该响应压缩算法,例如gzip |
| Cache-Control | 指示客户端应如何缓存,例如max-age=300表示最多缓存300秒 |
| Set-Cookie | 告诉浏览器为当前页面所在的域设置cookie |
常见的响应状态码:
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| 200 | OK | 客户端请求成功,即处理成功 |
| 302 | Found | 指示所请求的资源已移动到Location响应头给定的URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified | 告诉客户端,所请求的资源至上次取得后,服务端并未更改(隐式重定向) |
| 400 | Bad Request | 客户端请求有语法错误,不能被服务端所理解 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务 |
| 404 | Not Found | 请求资源不存在,一般是URL输入有误,或网站资源被删除 |
| 405 | Method Not Allowed | 请求方式有误,比如应该用GET请求方式的资源,用来POST |
| 428 | Precondition Required | 服务器要求有条件的请求,告诉客户端要想访问该资源,必须携带特定的请求头 |
| 429 | Too Many Requests | 指示用户在给定时间内发送了太多请求(限速),配合Retry-After(多长时间后可以请求)响应头一起使用 |
| 431 | Request Header Fields Too Large | 请求头太大,服务器不愿意处理请求,因为头部字段太大,请求可以在减少请求头域的大小后重新提交 |
| 500 | Internal Server Error | 服务器发生不可预期的错误,查看日志 |
| 503 | Service Unavailable | 服务器尚未准备好处理请求,服务器刚启动,还未初始化好 |
状态码大全:https://cloud.tencent.com/developer/chapter/13553
3. Web服务器
- 对HTTP协议操作进行封装,简化web程序开发
- 部署web项目,对外提供网上信息浏览服务
3.1 Tomcat
- Tomcat是Apache软件基金会一个核心项目,是一个开源免费的轻量级Web服务器,支持Servlet/JSP少量JavaEE规范
- JavaEE:Java Enterprise Edition,Java企业版。指Java企业级开发的技术规范总和,包含13项技术规范:JDBC,JNDI,EJB,PMI,JSP,Servlet,XML,JMS,Java IDL,JTS,JTA,JavaMail,JAE
- Tomcat也称为Web容器,Servlet容器,Servlet程序需要依赖Tomcat才能运行
- 官网:https://tomcat.apache.org/
3.1.1 Tomcat基本使用
-
启动:双击:bin\startup.bat
-
控制台中文乱码:修改conf/logging.properties
java.util.logging.ConsoleHandler.level = FINE java.util.logging.ConsoleHandler.formatter = org.apache.juli.OneLineFormatter java.util.logging.ConsoleHandler.encoding = (UTF-8)->GBK
-
-
关闭:
- 直接x掉运行窗口:强制关闭
- bin\shutdown.bat:正常关闭
- Ctrl+C:正常关闭
常见问题
-
启动窗口一闪而过:检查JAVA_HOME环境变量是否正确配置
-
端口号冲突:找到对应程序,将其关掉
-
配置Tomcat端口号(conf/server.xml)
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />HTTP协议默认端口号为80,如果将Tomcat端口号改为80,则将来访问Tomcat时,将不用输入端口号
部署项目
- 将项目放置到web apps目录下,即部署完成
3.1.2 SPringBootWeb
起步依赖
- spring-boot-starter-web:包含了web应用开发所需要的常见依赖
- spring-boot-starter-test:包含了单元测试所需要的常见依赖
- 官方提供的starter:https://docs.spring.io/spring-boot/docs/2.7.4/reference/htmlsingle/#using.build-systems.starters
内嵌Tomcat服务器
- 基于Springboot开发的web应用程序,内置了tomcat服务器,当启动类运行时,会自动启动内嵌的tomcat服务器
4. 请求响应
- 请求(HttpServletRequest):获取请求数据
- 响应(HttpServletRequest):设置响应数据
- BS架构:Browser/Server,浏览器/服务器架构模式,客户端指需要浏览器,应用程序的逻辑和数据都存储在服务端(维护比较方便,但是速度取决于带宽,可能影响体验)
- CS架构:Client/Server,客户端/服务器架构模式,需要单独下载对应客户端(开发和维护比较麻烦,不同的系统需要不同的版本,但是本地体验更流畅)
4.1 简单参数
4.1.1 原始方式获取请求参数
- Controller方法形参中声明HttpServletRequest对象
- 调用对象的getParameter(参数名)
4.1.2 SpringBoot中接收简单参数
- 请求参数名与方法形参变量名相同
- 会自动进行类型转换
4.1.3 @RequestParam注解
- 方法形参名称与请求参数名称不匹配,通过该注解完成映射
- 该注解的required属性默认是true,代表请求参数必须传递
4.1.4 实体参数
- 简单实体参数:请求参数名与形参对象属性名相同,定义POJO接收即可
- 复杂实体对象:请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套POJO属性参数
4.1.5 数组集合参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
- 数组:请求参数名与形参中数组变量名相同,可以直接使用数组封装
- 集合:请求参数名与形参中集合变量名相同,通过@RequestParam绑定参数关系
4.1.6 日期参数
- 日期参数:使用@DateTimeFormat注解完成日期参数格式转换
4.1.7 JSON参数
- JSON参数:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数,需要使用@RequestBody标识
4.1.8 路径参数
- 路径参数:通过请求URL直接传递参数,使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
4.2 响应数据
4.2.1 @ResponseBody
- 类型:方法注解,类注解
- 位置:Controller方法上/类上
- 作用:将方法返回值直接响应,如果返回值类型是实体对象/集合,将会转换为JSON格式响应
- 说明:@RestController=@Controller + @ResponseBody
4.2.2 统一响应结果
Result(code,msg,data)
5. 分层解耦
- 内聚:软件中各个功能模块内部的功能联系
- 耦合:衡量软件中各个层/模块之间的依赖,关联程度
- 软件设计原则:高内聚低耦合
5.1 三层架构
- controller:控制层,接收前端发送的请求,对请求进行处理,并响应数据
- service:业务逻辑层,处理具体的业务逻辑
- dao:数据访问层(Data Access Object)(持久层),负责数据访问操作,包括数据的增删改查。
5.2 IOC & DI
- 控制反转:Inversion Of Control,简称IOC,对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转
- 依赖注入:Dependency Injection,简称DI,容器为应用程序提供运行时,所依赖的资源,称之为依赖注入
- Bean对象:IOC容器中创建,管理的对象,称之为bean
步骤:
-
Service层及Dao层的实现类,交给IOC容器管理(添加@Component注解)
-
为Controller及Service注入运行时,依赖的对象(在成员变量上添加@Autowired注解)
-
运行测试
5.2.1 Bean的声明
要把某个对象交给IOC容器管理,需要在对应的类上加上如下直接之一:
| 注解 | 说明 | 位置 |
|---|---|---|
| @Component | 声明bean的基础注解 | 不属于以下三类时,用此注解 |
| @Controller | @Component的衍生注解 | 标注在控制器上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,使用较少) |
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认类名首字母小写
- 使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller
5.2.2 Bean组件扫描
- 前面声明bean的四大注解,要想生效,还需要被组件扫描注解@ComponentScan扫描
- @ComponentScan注解虽然没有显式配置,但实际上已经包含在了启动类声明注解@SpringBootApplication中,默认扫描的范围是启动类所在包及其子包
5.2.3 Bean注入
- Autowired注解,默认是按照类型进行,如果存在多个相同类型的bean,将会报错
- 解决方案:
- @Primary
- @Autowired+@Qualifier(“bean的名称”)
- @Resource(name=“bean的名称”)
- 解决方案:
5.2.4 @Resource与@Autowired区别
- @Autowired是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired默认是按照类型注入,而@Resource默认是按照名称注入
6. MyBatis
- MyBatis是一款优秀的持久层框架,用于简化JDBC的开发
- MyBatis是Apache的一个开源项目IBatis,2010年这个项目由apache迁移到了Google code,并且改名MyBatis,2013年11月迁移到Github
- 官网:https://mybatis.org/mybatis-3/zh/index.html
6.1 MyBatis环境准备
-
准备工作(创建spring boot工程,数据库表user,实体类User)
-
引入MyBatis的相关依赖,配置MyBatis(数据库连接信息)(连接自己的数据库和密码)
#驱动类名称 spring.datasource.driver-class-name=com.mysql.jdbc.Driver #数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/db1 #连接数据库的用户名 spring.datasource.username=root #连接数据库的密码 spring.datasource.password=123456 -
编写SQL语句(注解/XML)
@Mapper //在运行时,会自动生成该接口的实现类对象(代理对象),并且将该对象交给IOC容器管理 public interface UserMapper { //查询全部用户信息 @Select("select * from user") public List<User> list(); } -
单元测试
@SpringBootTest class SpringbootMybatisQuickstartApplicationTests { @Autowired private UserMapper userMapper; @Test public void testListUser(){ List<User> userList = userMapper.list(); userList.stream().forEach(user -> { System.out.println(user); }); } }
6.2 配置SQL提示
-
默认在mybatis中编写SQL语句是不识别的,可以做如下配置:
右键->Show Context Actions->Inject Language or reference ->MySQL
-
数据库名称爆红:
- 产生原因:IDEA和数据库没有建立连接,不识别表信息
- 解决方法:在IDEA 中配置MySQL数据库连接
6.3 JDBC
- JDBC:(Java DataBase Connectivity),就是使用Java语言操作关系型数据库的一套API
- sun公司官方定义的一套操作所有关系型数据库的规范,即接口
- 各个数据库厂商去实现这套接口,提供数据库驱动jar包
- 可以使用这套接口(JDBC)编程,真正执行的代码时驱动jar包中的实现类
6.4 数据库连接池
- 数据库连接池是个容器,负责分配,管理数据库连接(Connection)
- 它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个
- 释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
数据库连接池优势:
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
标准接口:DataSource
-
官方(sun)提供的数据库连接池接口,由第三方组织实现此接口
-
功能:获取连接
Connection getConnection() throws SQLException;
常见产品:
- C3P0
- DBCP
- Druid
- Druid连接池是阿里巴巴开源的数据库连接池项目
- 功能强大,性能优秀,是Java语言最好的数据库连接池之一
- HiKari(springboot默认)
6.4.1 切换Druid数据库连接池
官方地址:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
<dependency>
<groupld>com.alibaba</groupld>
<artifactld>druid-spring-boot-starter</artifactld>
<version>1.2.8</version>
</dependency>
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.druid.url=jdbc:mysql://localhost:3306/数据库名
spring.datasource.druid.username=root
spring.datasource.druid.password=123456
6.5 版本选择
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
6.6 Lombok
- lombok是一个实用的Java类库,能通过注解的形式自动生成构造器,getter/setter,equals,hashcode,toString等方法,并可以自动化生成日志变量,简化Java开发,提高效率
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的toString方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段重写equals方法和hashcode方法 |
| @Data | 提供了更综合的生成代码功能(@Getter+@Setter+@ToString+@EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造方法 |
Lombok的依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
lombok会在编译时,自动生成对应的Java代码,我们使用Lombok时,还需要安装一个Lombok的插件(Java自带)
6.7 Mybatis基本操作
6.7.1 环境准备
- 准备数据库表
- 创建一个新的springboot工程,选择引入对应的起步依赖(mybatis、mysql驱动、lombok)
- application.properties中引入数据库连接信息
- 创建对应的实体类 Emp(实体类属性采用驼峰命名)
- 准备Mapper接口 EmpMapper
1.准备数据库表
create table user(
id int unsigned primary key auto_increment comment 'ID',
name varchar(100) comment '姓名',
age tinyint unsigned comment '年龄',
gender tinyint unsigned comment '性别, 1:男, 2:女',
phone varchar(11) comment '手机号'
) comment '用户表';
insert into user(id, name, age, gender, phone) VALUES (null,'白眉鹰王',55,'1','18800000000');
insert into user(id, name, age, gender, phone) VALUES (null,'金毛狮王',45,'1','18800000001');
insert into user(id, name, age, gender, phone) VALUES (null,'青翼蝠王',38,'1','18800000002');
insert into user(id, name, age, gender, phone) VALUES (null,'紫衫龙王',42,'2','18800000003');
insert into user(id, name, age, gender, phone) VALUES (null,'光明左使',37,'1','18800000004');
insert into user(id, name, age, gender, phone) VALUES (null,'光明右使',48,'1','18800000005');
select * from user;
-- 部门管理
create table dept(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
insert into dept (id, name, create_time, update_time) values(1,'学工部',now(),now()),(2,'教研部',now(),now()),(3,'咨询部',now(),now()), (4,'就业部',now(),now()),(5,'人事部',now(),now());
-- 员工管理
create table emp (
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
INSERT INTO emp(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()),
(12,'hebiweng','123456','鹤笔翁',1,'12.jpg',5,'2008-08-18',3,now(),now()),
(13,'fangdongbai','123456','方东白',1,'13.jpg',5,'2012-11-01',3,now(),now()),
(14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2010-01-01',2,now(),now()),
(17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
-- 根据ID删除数据
delete from emp where id = 17;
-- 登录
select count(*) from emp where username = 'zhangwuji' and password = '123456';
select count(*) from emp where username = 'zhangwuji' and password = '111';
select count(*) from emp where username = 'wuieuwiueiwuiew' and password = '' or '1' = '1';
3.application.properties中引入数据库连接信息:
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/emp
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=123456
4.创建对应的实体类 Emp(实体类属性采用驼峰命名):
package com.example.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.time.LocalDate;
import java.time.LocalDateTime;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp {
private Integer id;
private String username;
private String password;
private String name;
private String gender;
private String image;
private Short job;
private LocalDate entrydata;
private Integer deptId;
private LocalDateTime createTime;
private LocalDateTime updatetime;
}
5.准备Mapper接口 EmpMapper:
package com.example.mapper;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface EmpMapper {
}
6.7.2 删除操作
-
SQL语句:
delete from emp where id = 17; -
接口方法:
@Mapper public interface EmpMapper { //根据ID删除数据 @Delete("delete from emp where id = #{id}") public void delete(Integer id); }如果mapper接口方法形参只有一个普通类型的参数,#{…}里面的属性名可以随便写,如:#{id},#{value}
6.7.3 预编译SQL
优势:
- 性能更高
- 更安全(防止SQL注入)
- SQL注入是通过操作输入的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法
6.7.3.1 参数占位符
#{…}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
${…}
- 拼接SQL,直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名,列表进行动态设置时使用
6.7.4 新增操作
-
SQL语句:
-- 插入 insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) VALUE ('Tom','汤姆','1','1.jpg',1,'2005-01-01',1,now(),now()) -
接口方法:
//新增员工 @Insert("insert into emp (username, name, gender, image, job, entrydate, dept_id, create_time, update_time) " + " values (#{username},#{name},#{gender},#{image},#{job},#{entrydate},#{deptId},#{createTime},#{updateTime})") public void insert(Emp emp);在测试类中实现:
@Test public void testInsert(){ //构造员工对象 Emp emp = new Emp(); emp.setUsername("Tom"); emp.setName("汤姆"); emp.setImage("1.jpg"); emp.setGender(String.valueOf((short)1)); emp.setJob((short)1); emp.setEntrydate(LocalDate.of(2000,1,22)); emp.setCreateTime(LocalDateTime.now()); emp.setUpdateTime(LocalDateTime.now()); emp.setDeptId(1); //执行新增员工信息操作 empMapper.insert(emp); }
6.7.5 新增(主键返回)
- 在数据添加成功后,需要获取插入数据库数据的主键
如何实现在插入数据之后返回所插入行的主键值?
- 默认情况下,执行插入操作时,是不会主键值返回的。如果我们想要拿到主键值,需要在Mapper接口中的方法上添加一个Options注解,并在注解中指定属性useGeneratedKeys=true和keyProperty=“实体类属性名”
主键返回代码实现:
@Mapper
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}
6.7.6 更新操作
-
SQL语句:
-- 更新员工 update emp set username = '',name='',gender='',image='', job='',entrydate='',dept_id='',update_time='' where id=1; -
接口方法:
@Update("update emp set username =#{username},name=#{name},gender=#{gender},image=#{image}," + " job=#{job},entrydate=#{entrydate},dept_id=#{deptId},update_time=#{updateTime} where id= #{id} ;") public void update(Emp emp);在测试类中实现:
//更新员工 @Test public void testUpdate(){ //构造员工对象 Emp emp = new Emp(); emp.setId(18); emp.setUsername("Tom1"); emp.setName("汤姆1"); emp.setImage("1.jpg"); emp.setGender(String.valueOf((short)1)); emp.setJob((short)1); emp.setEntrydate(LocalDate.of(2000,1,1)); emp.setUpdateTime(LocalDateTime.now()); emp.setDeptId(1); //执行更新员工操作 empMapper.update(emp); }
6.7.7 查询
6.7.7.1 根据ID查询
-
SQL语句:
select * from emp where id = 18; -
接口方法:
//根据ID查询员工 @Select("select * from emp where id = #{id}") public Emp testGetById(Integer id);在测试类中实现:
//根据ID查询员工 @Test public void testGetById(){ Emp emp = empMapper.testGetById(18); System.out.println(emp); }
6.7.7.2 数据封装
- 实体类属性名 和 数据库表查询返回的字段名一致,mybatis会自动封装
- 如果实体类属性名 和 数据库查询返回的字段名不一致,不能自动封装
解决方案:
- 起别名
- 手动结果映射
- 开启驼峰命名
方案一:给字段起别名,让别名与实体类属性一致
@Select("select id,username,password,name,gender,image,job,entrydate," +
"dept_id deptId,create_time createTime,update_time updateTime from emp where id = #{id}")
public Emp getById(Integer id);
方案二:通过@Results,@Result注解手动映射封装
@Results({
@Result(column = "dept_id", property = "deptId"),
@Result(column = "create_time", property = "createTime"),
@Result(column = "update_time", property = "updateTime")
})
@Select("select * from emp where id = #{id}")
public Emp getById(Integer id);
方案三:开启mybatis的驼峰命名自动映射开关 —a_cloumn ----->aCloumn
//根据ID查询员工
@Select("select * from emp where id = #{id}")
public Emp getById(Integer id);
在application.properties中添加:
#开启mybatis的驼峰命名自动映射开关 ---a_cloumn ----->aCloumn
mybatis.configuration.map-underscore-to-camel-case=true
6.7.7.3 条件查询
-
SQL语句:
-- 条件查询员工 select * from emp where name like '%张%' and gender = 1 and entrydate between '2010-01-01' and '2020-01-01' order by update_time desc ; -
接口方法:
//条件查询员工 @Select("select * from emp where name like '%${name}%' and gender =#{gender} and " + "entrydate between #{begin} and #{end} order by update_time desc ") public List<Emp> list(String name, Short gender, LocalDate begin,LocalDate end);在上述接口方法中,使用了${name},则生成的不是预编译的SQL,会有性能低,不安全,存在SQL注入问题。
解决方法:使用concat()字符串拼接函数
- SQL语句:
-- concat 字符串拼接函数
select * from emp where name like concat('%',?,'%') and gender = 1 and entrydate between '2010-01-01' and '2020-01-01' order by update_time desc ;
- 接口方法:
@Select("select * from emp where name like concat('%',#{name},'%') and gender =#{gender} and " +
"entrydate between #{begin} and #{end} order by update_time desc ")
public List<Emp> list(String name, Short gender, LocalDate begin,LocalDate end);
6.8 XML映射文件
1.规范:
- XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
- XML映射文件的namespace属性为Mapper接口全限定名一致
- XML映射文件中SQL语句的id与Mapper接口中的方法名一致,并保持返回类型一致
2.MybatisX:一款基于IDEA的快速开发Mybatis的插件,提高效率。
3.关于选择Mybatis注解或映射:
使用Mybatis的注解,主要是来完成一些简单的增删改查功能,如果需要实现复杂的SQL功能,建议使用XML来配置映射语句。使用注解来映射简单语句会使代码显得更加简洁,但对于稍微复杂一点的语句,Java 注解不仅力不从心,还会让你本就复杂的 SQL 语句更加混乱不堪。 因此,如果你需要做一些很复杂的操作,最好用 XML 来映射语句。
官方说明:https://mybatis.net.cn/getting-started.html
4.约束(可以直接去官网入门查询)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
6.9 动态SQL
- 随着用户的输入或外部条件的变化而变化的SQL语句,称为动态SQQL
<if>:用于判断条件是否成立,使用test属性进行条件判断,如果条件为true,则拼接SQL。
<where>:where元素只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的and或or。
<set>:动态地在行首插入SET关键字,并会删除额外的逗号。(用于update语句中)
6.9.1 条件查询
动态SQL语句:
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
where
<if test="name != null">
name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
order by update_time desc
</select>
测试方法:
@Test
public void testList(){
//性别数据为null、开始时间和结束时间也为null
List<Emp> list = empMapper.list("张", null, null, null);
for(Emp emp : list){
System.out.println(emp);
}
}
使用<where>标签代替SQL语句中的where关键字:
<!--resultType:单条记录所封装的类型 -->
<select id="list" resultType="com.example.pojo.Emp">
select *
from emp
<where>
<if test="name != null">
name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender =#{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
order by update_time desc
</where>
</select>
6.9.2 更新
- 动态更新员工信息,如果更新时传递有值,则更新;如果更新时没有传递值,则不更新
修改Mapper接口:
@Mapper
public interface EmpMapper {
//删除@Update注解编写的SQL语句
//update操作的SQL语句编写在Mapper映射文件中
public void update(Emp emp);
}
修改Mapper映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.EmpMapper">
<!-- 动态更新员工-->
<update id="update2">
update emp
set
<if test="username != null">username =#{username},</if>
<if test="name != null">name =#{name},</if>
<if test="gender != null">gender =#{gender},</if>
<if test="image != null">image =#{image},</if>
<if test="job != null">job =#{job},</if>
<if test="entrydate != null">entrydate =#{entrydate},</if>
<if test="deptId != null">dept_id =#{deptId},</if>
<if test="updateTime != null">update_time =#{updateTime}</if>
where id = #{id};
</update>
</mapper>
测试方法:
@Test
public void testUpdate2(){
//要修改的员工信息
Emp emp = new Emp();
emp.setId(18);
emp.setUsername("Tom111");
emp.setName("汤姆111");
emp.setUpdateTime(LocalDateTime.now());
//调用方法,修改员工数据
empMapper.update(emp);
}
使用<set>标签代替SQL语句中的set关键字:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.EmpMapper">
<!-- 动态更新员工-->
<update id="update2">
update emp
<set>
<if test="username != null">username =#{username},</if>
<if test="name != null">name =#{name},</if>
<if test="gender != null">gender =#{gender},</if>
<if test="image != null">image =#{image},</if>
<if test="job != null">job =#{job},</if>
<if test="entrydate != null">entrydate =#{entrydate},</if>
<if test="deptId != null">dept_id =#{deptId},</if>
<if test="updateTime != null">update_time =#{updateTime}</if>
where id = #{id};
</set>
</update>
</mapper>
6.9.3 批量删除
-
SQL语句:
delete from emp where id in(18,19); -
接口方法:
//批量删除员工 public void deleteByIds(List<Integer> ids); -
XML映射文件:
<!-- 批量删除员工--> <!-- collection:遍历的集合 item:遍历出来的元素 separator:分隔符 open:遍历开始前拼接的SQL片段 close:遍历结束后拼接的SQL片段 --> <delete id="deleteByIds"> delete from emp where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete>
6.9.4 SQL片段
可以对重复的代码片段进行抽取,将其通过<sql>标签封装到一个SQL片段,然后再通过<include>标签进行引用。
<sql>:定义可重用的SQL片段<include>:通过属性refid,指定包含的sql片段
SQL片段: 抽取重复的代码
<sql id="commonSelect">
select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp
</sql>
然后通过<include> 标签在原来抽取的地方进行引用。操作如下:
<select id="list" resultType="com.itheima.pojo.Emp">
<include refid="commonSelect"/>
<where>
<if test="name != null">
name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
7. 开发
7.1 规范-Restful
- REST(REpresentational State Transfer),表述性状态转换,它是一种软件架构风格
传统URL风格如下:
http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
http://localhost:8080/user/saveUser POST:新增用户
http://localhost:8080/user/updateUser POST:修改用户
http://localhost:8080/user/deleteUser?id=1 GET:删除id为1的用户
原始的传统URL,定义比较复杂,而且将资源的访问行为将会对外暴露出来
基于REST风格URL如下:
http://localhost:8080/users/1 GET:查询id为1的用户
http://localhost:8080/users POST:新增用户
http://localhost:8080/users PUT:修改用户
http://localhost:8080/users/1 DELETE:删除id为1的用户
在REST风格的URL中,通过四种请求方式,来操作数据的增删改查。
- GET : 查询
- POST :新增
- PUT :修改
- DELETE :删除
基于REST风格,定义URL,URL将会更加简洁、更加规范、更加优雅。
注意事项:
- REST是风格,是约定方式,约定不是规定,可以打破
- 描述模块的功能通常使用复数,也就是加s的格式来描述,表示此类资源,而非单个资源。如:users、emps、books…
7.2 开发流程
查看页面原型明确需求 --> 阅读接口文档 --> 思路分析 --> 接口开发 --> 接口测试 --> 前后端联调
8. 配置文件
8.1 参数配置化
-
在调用工具类后,可以将参数配置在配置文件中
-
application.properties是springboot项目默认的配置文件,所以springboot程序在启动时会默认读取application.properties配置文件,可以使用一个现成的注解:@Value,获取配置文件中的数据。
-
@Value 注解通常用于外部配置的属性注入,具体用法为: @Value(“${配置文件中的key}”)
8.2 yml配置文件
#数据库连接信息
spring:
profiles:
active: dev
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/tlias
username: root
password: 123456
#文件上传的配置
servlet:
multipart:
max-file-size: 10MB
max-request-size: 100MB
#mybatis配置
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
#开启事务管理日志
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
-
SringBoot提供了多种属性配置方式:
- application.properties
- application.yml
- application.yaml
-
常见配置文件格式对比
-
XML:臃肿
-
properties:层级结构不清晰
-
yml格式的数据有以下特点:
- 容易阅读
- 容易与脚本语言交互
- 以数据为核心,重数据轻格式
-
yml基本语法:
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(Idea 中会自动将Tab转换为空格)
- 所进的空格数目不重要,只要相同层级的元素左侧对齐即可
- #表示注释,从这个字符一直到行尾,都会被解析器忽略
当把application.properties换成application.yml,出现报错信息:No active profile set, falling back to 1 default profile: "default"时,
出现错误的原因为:
properties和yml的语法格式不一样,一般情况下,yml文件要指明是生产环境还是开发环境
(dev:开发环境 prod:生产环境 test:测试环境)
解决方法如下:
方法一:在Configurations中添加--spring.profiles.active=dev
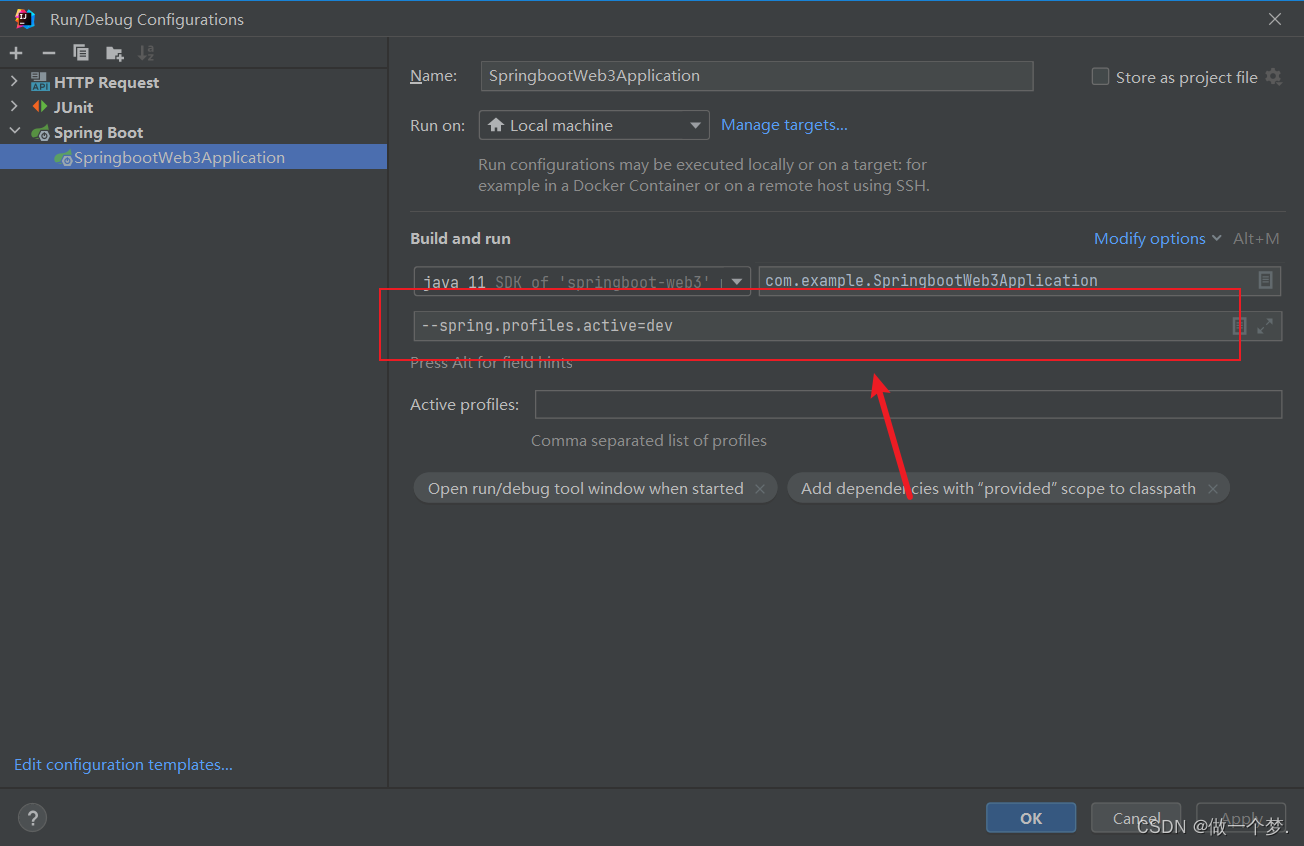
方法二:在配置文件中添加
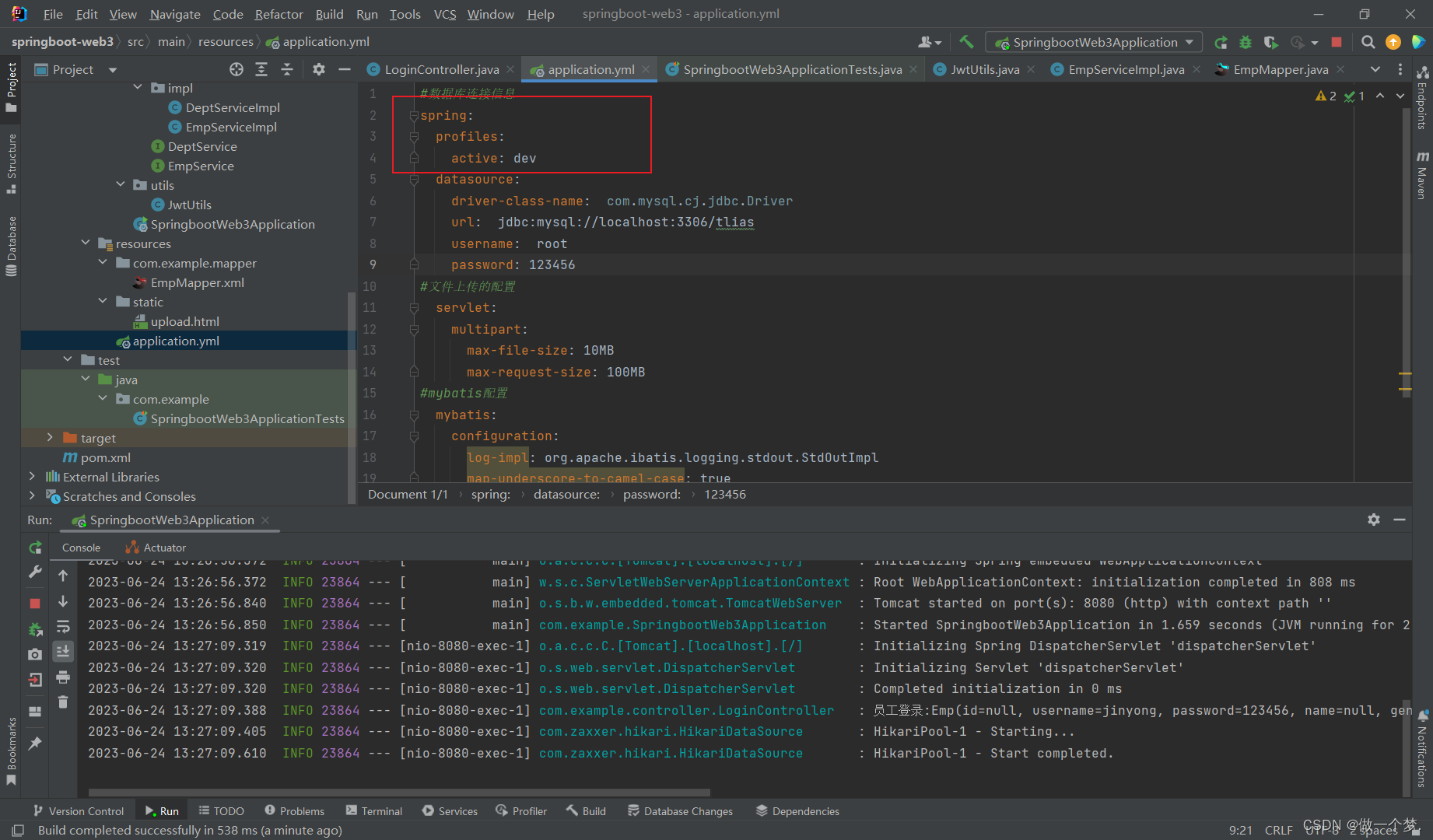
8.3 @ConfigurationProperties
可以直接将配置文件中配置项的值自动的注入到对象的属性中
-
实现过程:
-
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法
-
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象
-
在实体类上添加
@ConfigurationProperties注解,并通过perfect属性来指定配置参数项的前缀
-
@ConfigurationProperties与@Value
相同点:
- 都是用来注入外部配置的属性的
不同点:
- @Value注解只能一个一个的进行外部属性的注入
- @ConfigurationProperties可以进行批量的将外部的属性配置注入到bean对象的属性中
如果要注入的属性非常的多,并且还想做到复用,就可以定义这么一个bean对象。通过 configuration properties 批量的将外部的属性配置直接注入到 bin 对象的属性当中。在其他的类当中,要想获取到注入进来的属性,直接注入 bin 对象,然后调用 get 方法,就可以获取到对应的属性值了
9. 事务管理
事务回滚:
事务回滚是指将该事务已经完成对数据库的更新操作撤销,在事务中,每个正确的原子都会被顺序执行,知道遇到错误的原子操作。
回滚:
回滚是删除由一个或多个部分完成的事务执行的更新,为保证应用程序、数据库或系统错误后还原数据库的完整性,需要使用回滚。
回滚包括程序回滚和数据回滚等类型(泛指程序更新失败,返回上一次正确状态行为)
9.1 Spring事务管理
- 注解:@Transactional
- 在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。
- 位置:业务(service)层的方法上,类上,接口上
- 作用:将当前方法交给spring进行事务管理,方法执行前,开启事务;成功执行完毕后,提交事务;出现异常,回滚事务
@Transactional注解书写位置:
- 方法
- 当前方法交给spring进行事务管理
- 类
- 当前类中所有的方法都交由spring进行事务管理
- 接口
- 接口下所有的实现类当中所有的方法都交给spring 进行事务管理
在配置文件中添加:
#开启事务管理日志
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
9.2 事务属性
9.2.1 回滚
rollbackFor
- 指定回滚事物的范围
- 默认情况下,只有出现RuntimeException(运行时异常)才回滚异常,rollbackFor属性用于控制出现何种异常类型,回滚事务
9.2.2 传播行为
propagation
- 事务传播行为:指的是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】需要事务,有则加入,无则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
| SUPPORTS | 支持事务,有则加入,无则在无事务状态中运行 |
| NOT_SUPPORTED | 不支持事务,在无事务状态下运行,如果当前存在已有事务,则挂起当前事务 |
| MANDATORY | 必须有事务,否则抛异常 |
| NEVER | 必须没事务,否则抛异常 |
| … |
REQUIRED :大部分情况下都是用该传播行为即可。
REQUIRES_NEW :当不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
10. AOP
10.1 AOP概述
- AOP英文全称:Aspect Oriented Programming(面向切面编程、面向方面编程),面向切面编程就是面向特定方法编程。
AOP的作用:在程序运行期间在不修改源代码的基础上对已有方法进行增强(无侵入性: 解耦)
AOP面向切面编程和OOP面向对象编程一样,它们都仅仅是一种编程思想,而动态代理技术是这种思想最主流的实现方式。而Spring的AOP是Spring框架的高级技术,旨在管理bean对象的过程中底层使用动态代理机制,对特定的方法进行编程(功能增强)。
AOP优点:
- 减少重复代码
- 提高开发效率
- 维护方便
10.2 AOP入门
导入依赖:在pom.xml中导入AOP的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
10.3 AOP核心概念
- 连接点:JoinPoint,可以被AOP控制的方法(含方法执行时的相关信息)
- 通知:Advice,指重复的逻辑,即共性功能(最终体现为一个方法)
- 切入点:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用
- 切面:Aspect,描述通知与切入点的对应关系(通知+切入点)
- 目标对象:Target,通知所应用的对象
10.4 AOP进阶
10.4.1 通知类型
- @Around:环绕通知,此注解标注的通知方法在目标方法前,后都执行
- @Before:前置通知,此注解标注的通知方法在目标方法前被执行
- @After:后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会被执行
- @AfterReturning:返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
- @AfterThrowing:异常后通知,此注解标注的通知方法发生异常后执行
- @Around环绕通知需要自己调用ProceedingJoinPoint.proceed()来让原始方法执行,其他通知不需要考虑目标方法执行
- @Around环绕通知方法的返回值,必须指定为Object,来接收原始方法的返回值
10.4.2 通知顺序
当有多个切面的切入点都匹配到了目标方法,目标方法运行时,多个通知方法都会被执行
执行顺序:
-
不同切面类中,默认按照切面类的类名字母排序:
- 目标方法前的通知方法:字母排名靠前的先执行
- 目标方法后的通知方法:字母排名靠后的后执行
-
用@Order(数字)加在切面类上来控制顺序
-
目标方法前的通知方法:数字小的先执行
-
目标方法后的通知方法:数字小的后执行
-
10.4.3 切入点表达式
- 切入点表达式:描述切入点方法的一种表达式
- 作用:主要用来决定项目中的哪些方法需要加入通知
- 常见形式;
- execution(…):根据方法的签名来匹配
- @annotation(…):根据注解匹配
execution
execution主要根据方法的返回值,包名宁,类名,方法名,方法参数等信息来匹配,语法为:
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throw 异常)
-
其中带?的表示可以省略的部分
- 访问修饰符:可省略(如:public,protected)
- 包名.类名:可省略(不建议省略,范围扩大可能会影响实际效果)
- throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
-
可以使用通配符描述切入点
-
*:单个独立的任意符号,可以通配任意返回值,包名,类名,方法名,任意类型的一个参数,也可以通配包,类,方法名的一部分execution(* com.* .service.*.update*(*)) -
..多个连续的任意符号,可以通配任意层级的包,或任意类型,任意个数的参数execution(* com.dream..DeptService.*(..))
-
可以使用 且(&&)、或(||)、非(!)来组合比较复杂的切入点表达式
@annotation
-
@annotation切入点表达式,用于匹配标识有特定注解的方法
-
编写自定义注解
-
在业务类要做为连接点的方法上添加自定义注解
-
-
execution切入点表达式
- 根据所指定的方法的描述信息来匹配切入点方法,这种方式也是最为常用的一种方式
- 如果要匹配的切入点方法的方法名不规则,或者有一些比较特殊的需求,通过execution切入点表达式描述比较繁琐
-
annotation 切入点表达式
- 基于注解的方式来匹配切入点方法。这种方式虽然多一步操作,需要自定义一个注解,但是相对来比较灵活。需要匹配哪个方法,就在方法上加上对应的注解就可以了
10.4.4 连接点
- 在Spring中用JoinPoint抽象了连接点,用它可以获得方法执行时的相关信息,如目标类名,方法名,方法参数等
- 对于@Around通知,获取连接点信息只能使用ProceedingJoinPoint
- 对于其他四种通知,获取连接点信息只能使用JoinPoint,它是ProceedingJointPoint的 父类型
10.5 AOP案例
10.5.1 需求分析
将案例中增、删、改相关接口的操作日志记录到数据库表中
- 就是当访问部门管理和员工管理当中的增、删、改相关功能接口时,需要详细的操作日志,并保存在数据表中,便于后期数据追踪。
操作日志信息包含:
- 操作人、操作时间、执行方法的全类名、执行方法名、方法运行时参数、返回值、方法执行时长
所记录的日志信息包括当前接口的操作人是谁操作的,什么时间点操作的,以及访问的是哪个类当中的哪个方法,在访问这个方法的时候传入进来的参数是什么,访问这个方法最终拿到的返回值是什么,以及整个接口方法的运行时长是多长时间。
10.5.2 步骤
- 准备工作
- 引入AOP的起步依赖
- 导入资料中准备好的数据库表结构,并引入对应的实体类
- 编码实现
- 自定义注解@Log
- 定义切面类,完成记录操作日志的逻辑
10.5.3 具体实现
- AOP起步依赖
<!--AOP起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
- 创建数据表
-- 操作日志表
create table operate_log(
id int unsigned primary key auto_increment comment 'ID',
operate_user int unsigned comment '操作人',
operate_time datetime comment '操作时间',
class_name varchar(100) comment '操作的类名',
method_name varchar(100) comment '操作的方法名',
method_params varchar(1000) comment '方法参数',
return_value varchar(2000) comment '返回值',
cost_time bigint comment '方法执行耗时, 单位:ms'
) comment '操作日志表';
- 实体类
//操作日志实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class OperateLog {
private Integer id; //主键ID
private Integer operateUser; //操作人ID
private LocalDateTime operateTime; //操作时间
private String className; //操作类名
private String methodName; //操作方法名
private String methodParams; //操作方法参数
private String returnValue; //操作方法返回值
private Long costTime; //操作耗时
}
- Mapper接口
@Mapper
public interface OperateLogMapper {
//插入日志数据
@Insert("insert into operate_log (operate_user, operate_time, class_name, method_name, method_params, return_value, cost_time) " +
"values (#{operateUser}, #{operateTime}, #{className}, #{methodName}, #{methodParams}, #{returnValue}, #{costTime});")
public void insert(OperateLog log);
}
- 自定义注解@Lo
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME) //运行时有效
@Target(ElementType.METHOD) //作用在方法上
public @interface Log {
}
- 定义切面类,完成记录操作日志的逻辑
@Slf4j
@Component
@Aspect //切面类
public class LogAspect {
@Autowired
private HttpServletRequest request;
@Autowired
private OperateLogMapper operateLogMapper;
@Around("@annotation(com.example.anno.Log)")
public Object recordLog(ProceedingJoinPoint joinPoint) throws Throwable{
//操作人ID -当前登陆员工ID
//获取请求头中的jwt令牌,解析令牌
String jwt = request.getHeader("token");
Claims claims = JwtUtils.parseJWT(jwt);
Integer operateUser = (Integer) claims.get("id");
//操作时间
LocalDateTime operateTime = LocalDateTime.now();
//操作类名
String className = joinPoint.getTarget().getClass().getName();
//操作方法名
String methodName = joinPoint.getSignature().getName();
//操作方法参数
Object[] args = joinPoint.getArgs();
String methodParams = Arrays.toString(args);
long begin = System.currentTimeMillis();
//调用原始目标方法运行
Object result = joinPoint.proceed();
long end = System.currentTimeMillis();
// 操作耗时
Long costTime = end - begin;
//方法返回值
String returnValue = JSONObject.toJSONString(result);
//记录日志
OperateLog operateLog = new OperateLog(null,operateUser,operateTime,className,methodName,methodParams,returnValue,costTime);
operateLogMapper.insert(operateLog);
log.info("AOP记录操作日志:{}",operateLog);
return result;
}
}
- 修改业务实现类,在增删改业务方法上添加@Log注解
获取request对象,从请求头中获取到jwt令牌,解析令牌获取出当前用户的id
10.5.4 效果

11. SpringBoot原理篇
11.1 配置
-
SpringBoot中支持三种格式的配置文件:
- application.properties
- application.yml
- application.yaml
-
三种配置文件的优先级(从高到低)为:
- properties配置文件
- yml配置文件
- yaml配置文件
虽然Springboot支持多种格式的配置文件,但是在项目开发时,推荐使用统一的一种格式的配置(yml)
在SpringBoot项目当中除了以上3种配置文件外,SpringBoot为了增强程序的扩展性,除了支持配置文件的配置方式以外,还支持另外两种常见的配置方式:
-
Java系统属性
-Dserver.port=9000 -
命令行参数
--server.port=10010
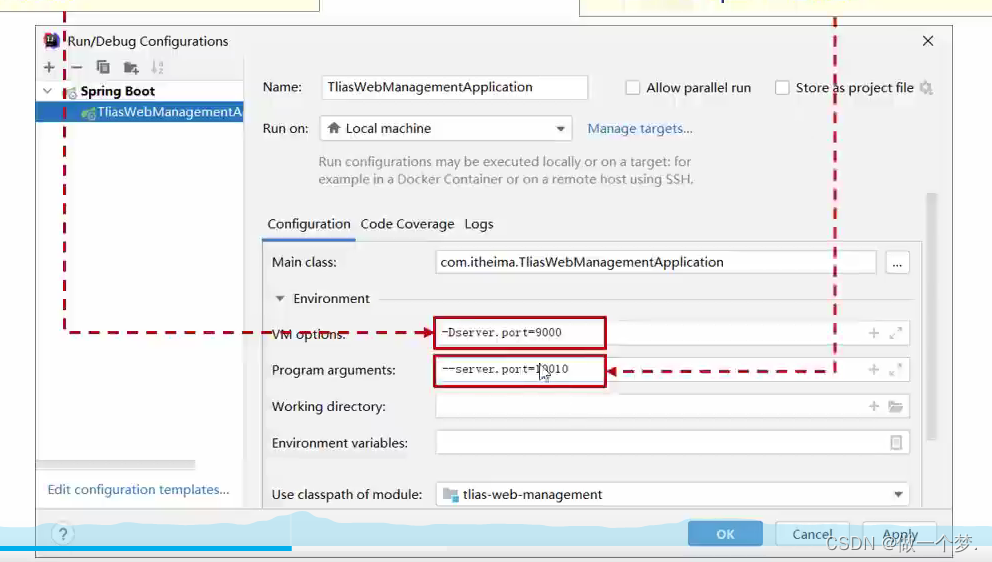
11.1.1 配置优先级
优先级(从低到高):
- application.yaml(忽略)
- application.yml
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(–xxx=xxx)
11.2 Bean管理
11.2.1 Bean是什么
1、Java面向对象,对象有方法和属性,那么就需要对象实例来调用方法和属性(即实例化);
2、凡是有方法或属性的类都需要实例化,这样才能具象化去使用这些方法和属性;
3、规律:凡是子类及带有方法或属性的类都要加上注册Bean到Spring IoC的注解;
4、Bean通过反射、代理来实现,能代表类所拥有的东西;
5、在Spring中,标识一个@符号,那么Spring就会从这里拿到一个Bean或者给出一个Bean
二、注解分为两类:
1、一类是使用Bean,即是把已经在xml文件中配置好的Bean拿来用,完成属性、方法的组装;比如@Autowired , @Resource,可以通过byTYPE(@Autowired)、byNAME(@Resource)的方式获取Bean;
2、一类是注册Bean,@Component , @Repository , @ Controller , @Service , @Configration这些注解都是把你要实例化的对象转化成一个Bean,放在IoC容器中,等你要用的时候,它会和上面的@Autowired , @Resource配合到一起,把对象、属性、方法完美组装。
总结:
1、凡是子类及带属性、方法的类都注册Bean到Spring中,交给它管理;
2、@Bean 用在方法上,告诉Spring容器,可以从下面这个方法中拿到一个Bean
11.2.2 获取Bean
-
默认情况下,Spring项目启动时,会把bean都创建好放在IOC容器中,如果想要主动获取这些bean,可以通过以下三种方式:
-
根据name获取bean:
Object getBean(String name) -
根据类型获取bean
<T> T getBean(Class<T> requiredType) -
根据name获取bean(带类型转换)
<T> T getBean(String name, Class<T> requiredType)
-
11.2.3 Bean作用域
- Spring支持五种作用域,后三种在web环境中才生效
| 作用域 | 说明 |
|---|---|
| singleton | 容器内同名称的bean只有一个实例(单例)(默认) |
| prototype | 每次使用该bean时会创建新的实例(非单例) |
| request | 每个请求范围内会创建新的实例(web环境中) |
| session | 每个会话范围内会创建新的实例(web环境中) |
| application | 每个应用范围内会创建新的实例(web环境中) |
可以借助Spring中的@Scope注解来进行配置作用域:
@Scope("prototype")
- 默认singleton的bean,在容器启动时被创建,可以使用@Lazy注解来延迟初始化(延迟到第一次使用时)
- prototype的bean,每一次使用该bean的时候都会创建一个新的实例
- 实际开发当中,绝大部分的Bean是单例的,也就是说绝大多数的Bean不需要配置scope属性
11.2.4 第三方Bean
- 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Compontent及原生注解声明bean的,需要用到@Bean注解
- 若要管理第三方bean对象,可以对这些bean进行集中分类配置,可以通过@Configuration注解声明一个配置类
注意事项:
- 如果通过@Bean注解的name或value属性可以声明bean的名称,如果不指定,默认bean的名称就算方法名
- 如果第三方bean需要依赖其他bean对象,直接在bena定义方法中设置形参即可,容器会根据类型字段装配
@Component及衍生注解与@Bean注解使用场景?
- 项目中定义的,使用@Component及其衍生注解
- 项目中引入第三方的,使用@Bean注解
11.3 Springboot原理
11.3.1 起步依赖
-
使用SpringBoot,不需要像繁琐的引入依赖,只需要引入一个依赖就可以了,那就是web开发的起步依赖:springboot-starter-web
-
Maven的依赖传递
-
在SpringBoot给我们提供的这些起步依赖当中,已提供了当前程序开发所需要的所有的常见依赖(官网地址:https://docs.spring.io/spring-boot/docs/2.7.7/reference/htmlsingle/#using.build-systems.starters)。
-
比如:springboot-starter-web,这是web开发的起步依赖,在web开发的起步依赖当中,就集成了web开发中常见的依赖:json、web、webmvc、tomcat等。我们只需要引入这一个起步依赖,其他的依赖都会自动的通过Maven的依赖传递进来。
-
起步依赖的原理就是Maven的依赖传递
11.3.2 自动配置
- SpriingBoot的自动配置就算当spring容器启动后,一些配置类,bean对象就自动存入到了IOC容器中,不需要手动声明,简化了开发,省去了繁琐的配置操作
引入进来的第三方依赖当中的bean以及配置类为什么没有生效?
- 在类上添加@Component注解来声明bean对象时,还需要保证@Component注解能被Spring的组件扫描到。
- SpringBoot项目中的@SpringBootApplication注解,具有包扫描的作用,但是它只会扫描启动类所在的当前包以及子包。
- 当前包:com.itheima, 第三方依赖中提供的包:com.example(扫描不到)
解决问题:
- 方案1:@ComponentScan 组件扫描
- 方案2:@Import 导入(使用@Import导入的类会被Spring加载到IOC容器中)
@ComponentScan 组件扫描
@SpringBootApplication
@ComponentScan({"com.itheima","com.example"}) //指定要扫描的包
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
@Import 导入
导入形式主要有以下几种:
-
导入普通类
-
导入配置类
-
导入ImportSelector接口实现类
-
使用第三方依赖提供的 @EnableXxxxx注解
关于第四种:
- 第三方依赖中提供的注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Import(MyImportSelector.class)//指定要导入哪些bean对象或配置类
public @interface EnableHeaderConfig {
}
- 在使用时只需在启动类上加上@EnableXxxxx注解即可
@EnableHeaderConfig //使用第三方依赖提供的Enable开头的注解
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
自动配置原理
自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是:
- @SpringBootConfiguration
- 声明当前类是一个配置类
- @ComponentScan
- 进行组件扫描(SpringBoot中默认扫描的是启动类所在的当前包及其子包)
- @EnableAutoConfiguration
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
- 在实现类重写的selectImports()方法,读取当前项目下所有依赖jar包中META-INF/spring.factories、META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports两个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)。
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
当SpringBoot程序启动时,就会加载配置文件当中所定义的配置类,并将这些配置类信息(类的全限定名)封装到String类型的数组中,最终通过@Import注解将这些配置类全部加载到Spring的IOC容器中,交给IOC容器管理。
@Conditional
@Conditional注解:
- 作用:按照一定的条件进行判断,在满足给定条件后才会注册对应的bean对象到Spring的IOC容器中。
- 位置:方法、类
- @Conditional本身是一个父注解,派生出大量的子注解:
- @ConditionalOnClass:判断环境中有对应字节码文件,才注册bean到IOC容器。
- @ConditionalOnMissingBean:判断环境中没有对应的bean(类型或名称),才注册bean到IOC容器。
- @ConditionalOnProperty:判断配置文件中有对应属性和值,才注册bean到IOC容器。
11.4 总结
-
web后端开发现在基本上都是基于标准的三层架构进行开发的,在三层架构当中,Controller控制器层负责接收请求响应数据,Service业务层负责具体的业务逻辑处理,而Dao数据访问层也叫持久层,就是用来处理数据访问操作的,来完成数据库当中数据的增删改查操作
-
如果在执行具体的业务处理之前,需要去做一些通用的业务处理,比如:要进行统一的登录校验,要进行统一的字符编码等这些操作时,就可以借助于Javaweb当中三大组件之一的过滤器Filter或者是Spring当中提供的拦截器Interceptor来实现
-
而为了实现三层架构层与层之间的解耦,学习了Spring框架当中的第一大核心:IOC控制反转与DI依赖注入
所谓控制反转,指的是将对象创建的控制权由应用程序自身交给外部容器,这个容器就是我们常说的IOC容器或Spring容器。
而DI依赖注入指的是容器为程序提供运行时所需要的资源。
-
Filter过滤器、Cookie、 Session这些都是传统的JavaWeb提供的技术。
JWT令牌、阿里云OSS对象存储服务,是现在企业项目中常见的一些解决方案。
IOC控制反转、DI依赖注入、AOP面向切面编程、事务管理、全局异常处理、拦截器等,这些技术都是 Spring Framework框架当中提供的核心功能。
Mybatis就是一个持久层的框架,是用来操作数据库的。
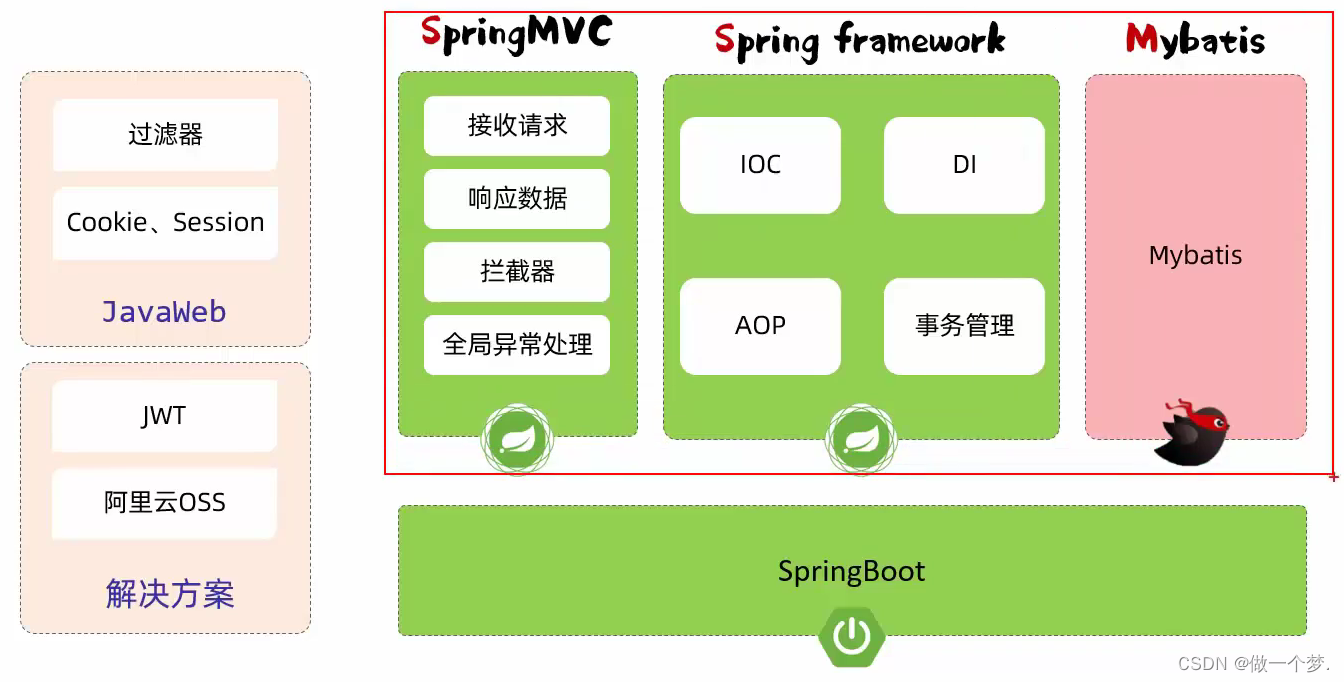
-
在Spring框架的生态中,对web程序开发提供了很好的支持,如:全局异常处理器、拦截器这些都是Spring框架中web开发模块所提供的功能,而Spring框架的web开发模块,也称为:SpringMVC
-
SSM,就是由:SpringMVC、Spring Framework、Mybatis三块组成。
基于传统的SSM框架进行整合开发项目会比较繁琐,而且效率也比较低,所以在现在的企业项目开发当中,基本上都是直接基于SpringBoot整合SSM进行项目开发的。
12. Maven高级
12.1 分模块设计与开发
- 分模块设计,顾名思义指的就是在设计一个 Java 项目的时候,将一个 Java 项目拆分成多个模块进行开发
- 分模块设计就是将项目按照功能/结构拆分成若干个子模块,方便项目的管理维护、拓展,也方便模块键的相互调用、资源共享
- 分模块设计的优点:方便项目的管理维护、扩展,也方便模块间的相互调用,资源共享
- 分模块设计需要先针对模块功能进行设计,再进行编码。不会先将工程开发完毕,然后进行拆分
12.2 继承与聚合
12.2.1 继承
- 概念:继承描述的是两个工程之间的关系,与Java中的继承相似,子工程可以继承父工程中的配置信息,常见于依赖关系的继承
- 作用:简化依赖配置,统一管理依赖
- 实现:
<parent>…</parent>
jar:普通模块打包,springboot项目基本都是jar包(内嵌tomcat运行)
war:普通web程序打包,需要部署在外部的tomcat服务器中运行
pom:父工程或聚合工程,该模块不写代码,仅进行依赖管理
继承关系实现:
- 创建maven模块tlias-parent,该工程为父工程,设置打包方式
pom(默认jar) - 在子工程的pom.xml文件中,配置继承关系
- 在父工程中配置各个过程共有的依赖(子工程会自动继承父工程的依赖)
注意:
- 在子工程中,配置了继承关系之后,坐标中的groupId是可以是可以省略的,因为会自动继承父工程的
- relativePath指定父工程的pom文件的相对位置(如果不指定,将从本地仓库/远程仓库查找该工程)
- 若父子工程都配置了同一个依赖的不同版本,以子工程的为准
12.2.2 版本锁定
<dependencyManagement>
- 在maven中,可以在父工程的pom文件中通过
<dependencyManagement>来统一管理依赖版本 - 子工程引入依赖时,无需指定
<version>版本号,父工程统一管理,变更版本依赖,只需在父工程中统一变更
自定义属性/引用属性

<dependencyManagement>与<dependencies>的区别:
<dependencies>是直接依赖,在父工程配置了依赖,子工程会直接继承下来。<dependencyManagement>是统一管理依赖版本,不会直接依赖,还需要在子工程中引入所需依赖(无需指定版本)
12.2.3 聚合
-
聚合:将多个模块组织成一个整体,同时进行项目的构建
-
聚合工程:一个不具有业务功能的“空”工程(有且仅有一个pom文件)
-
作用:快速构建项目(无需根据依赖关系手动构建,直接在聚合工程上构建即可)
-
maven中可以通过
<modules>设置当前聚合工程所包含的子模块名称 -
聚合工程所包含的模块,在构建时,会自动根据模块间的依赖关系设置构建顺序,与聚合工程中模块的配置书写位置无关
12.3 继承与聚合对比
-
作用
-
聚合用于快速构建项目
-
继承用于简化依赖配置、统一管理依赖
-
-
相同点:
-
聚合与继承的pom.xml文件打包方式均为pom,通常将两种关系制作到同一个pom文件中
-
聚合与继承均属于设计型模块,并无实际的模块内容
-
-
不同点:
-
聚合是在聚合工程中配置关系,聚合可以感知到参与聚合的模块有哪些
-
继承是在子模块中配置关系,父模块无法感知哪些子模块继承了自己
-
12.4 私服
- 私服是一种特殊的远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的中央仓库,用于解决团队内部的资源共享与资源同步问题
- 依赖查找顺序:
- 本地仓库
- 私服
- 中央仓库
12.4.1 资源上传与下载
第一步配置:在maven的配置文件中配置访问私服的用户名、密码。
第二步配置:在maven的配置文件中配置连接私服的地址(url地址)。
第三步配置:在项目的pom.xml文件中配置上传资源的位置(url地址)。
配置好了上述三步之后,要上传资源到私服仓库,就执行执行maven生命周期:deploy。
私服仓库说明:
- RELEASE:存储自己开发的RELEASE发布版本的资源。
- SNAPSHOT:存储自己开发的SNAPSHOT发布版本的资源。
- Central:存储的是从中央仓库下载下来的依赖。
项目版本说明:
- RELEASE(发布版本):功能趋于稳定、当前更新停止,可以用于发行的版本,存储在私服中的RELEASE仓库中。
- SNAPSHOT(快照版本):功能不稳定、尚处于开发中的版本,即快照版本,存储在私服的SNAPSHOT仓库中。
具体操作:
1.设置私服的访问用户名/密码(在自己maven安装目录下的conf/settings.xml中的servers中配置)
2.设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的mirrors、profiles中配置)
3.IDEA的maven工程的pom文件中配置上传(发布)地址(直接在tlias-parent中配置发布地址)
配置完成之后,我们就可以在tlias-parent中执行deploy生命周期,将项目发布到私服仓库中。
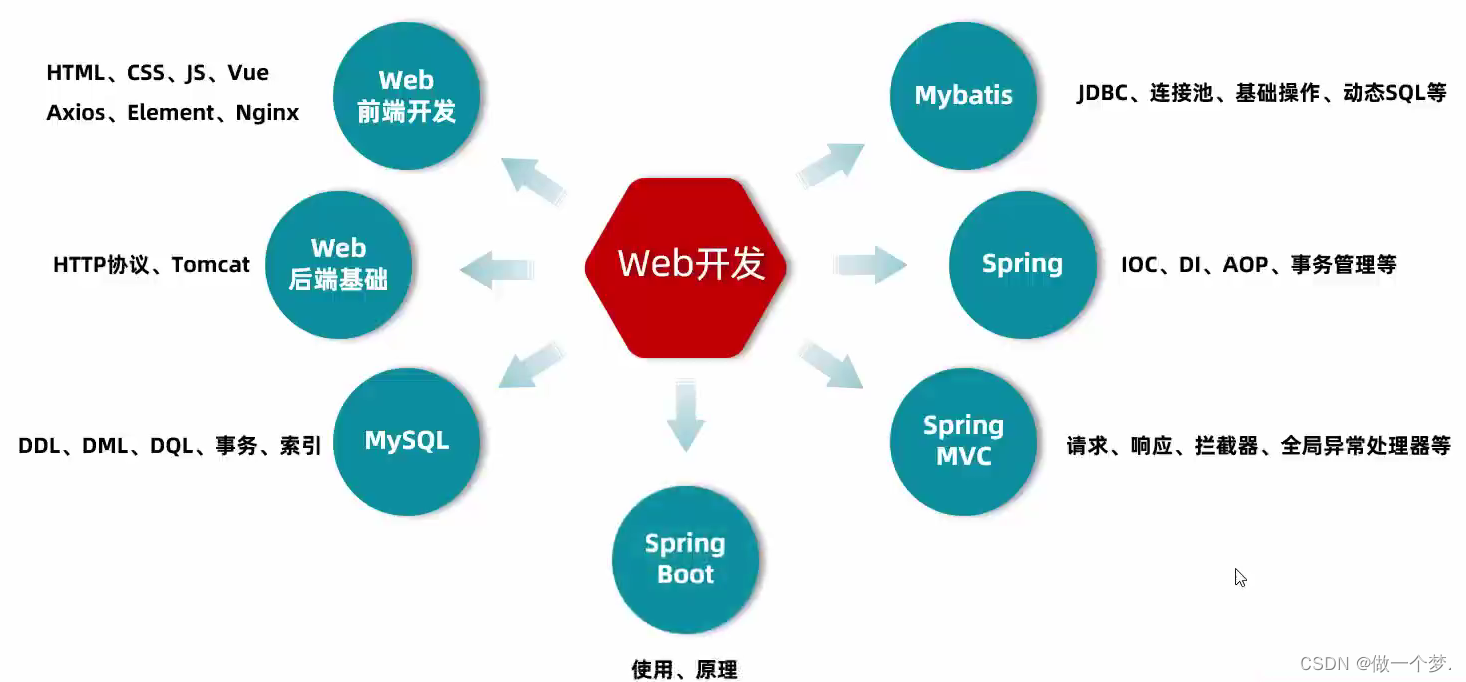
13. 总结

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









