







嗨,大家好,我是心海!
在机器学习中,逻辑回归(Logistic Regression)是一种常用的分类算法。虽然名字中有“回归”二字,但它实际上用于二分类问题(例如判断邮件是否为垃圾邮件、疾病是否存在等)。
本文将以通俗易懂的方式,从原理到代码实现,带你完整掌握逻辑回归的核心链条。
当然,本文是结合博主个人理解编写,如有错误,欢迎指正!
目录
1. 从线性回归到逻辑回归
上一篇文章,我们介绍了机器学习最基础的线性回归
线性回归主要用于预测连续变量,例如房价、温度等。它的数学模型通常写作:
当我们已经掌握了线性回归的基本概念后,你可能会问:为什么还需要逻辑回归?
逻辑回归的核心在于分类问题。直接使用线性回归模型会存在两个问题:
- 预测结果可以超出合理的范围(例如预测概率大于1或小于0)。
- 线性模型本质上无法很好地反映类别之间的非线性边界。
为了解决这个问题,逻辑回归引入了一个非线性转换函数——Sigmoid 函数。
2. 数学原理
2.1 Sigmoid函数
逻辑回归的核心在于Sigmoid函数(也称为 logistic 函数):
其中,z 通常是特征的线性组合:
性质:
- 输出范围为 (0, 1),自然适合做概率解释,可以直观地表示样本属于某个类别的概率。
- 当 z 很大时,σ(z) 接近1;当 z 很小时,σ(z) 接近0。
- 函数图形呈“S”型,这种平滑的过渡帮助模型捕捉类别的变化;对于极端的输入,输出趋近于 0 或 1,中间部分较为敏感,便于判断分类边界。
2.2 概率映射模型
在逻辑回归中,我们的假设函数定义为:
其中,。当我们计算出
后:
- 如果
,通常认为样本属于正类(例如“是”)。
- 如果
,则归为负类(例如“否”)。
这种阈值选择(0.5)可以根据具体问题进行调整,但在大多数情况下是默认的分界点。
2.3 代价函数与模型训练
为了训练逻辑回归模型,我们需要定义一个代价函数(Cost Function)来衡量预测值与真实值之间的误差。常用的代价函数是对数损失函数(Log Loss),也叫交叉熵损失函数,其形式为:
这里:
- m 是样本数量;
是第 i 个样本的真实标签(0 或 1);
是模型预测的概率。
该代价函数有几个优点:
- 对于错误分类的样本,代价会非常高,从而推动模型调整参数来降低错误率;
- 数学上是凸函数,使用梯度下降(Gradient Descent)等优化算法能够较容易地找到全局最优解。
3. 实战示例:用Python实现二分类
下面是一个使用 Python 实现逻辑回归二分类的示例(以鸢尾花数据集中的两个类别为例):
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据集,选取前两类(0和1)以及两个特征
iris = datasets.load_iris()
X = iris.data[iris.target != 2, :2] # 取前两列特征
y = iris.target[iris.target != 2]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 使用sklearn实现逻辑回归
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 生成网格以便绘制决策边界
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界和数据点
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, edgecolors='k', label='Train')
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, marker='x', label='Test')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.title('Logistic Regression Decision Boundary')
plt.show()
在这段代码中,我们:
- 使用
sklearn.datasets加载了鸢尾花数据集,并仅选取其中的两个类别和两个特征。 - 划分数据为训练集和测试集,利用
LogisticRegression进行训练。 - 生成网格点来绘制决策边界,最终利用
matplotlib可视化数据点及决策区域。
执行代码,得到下图
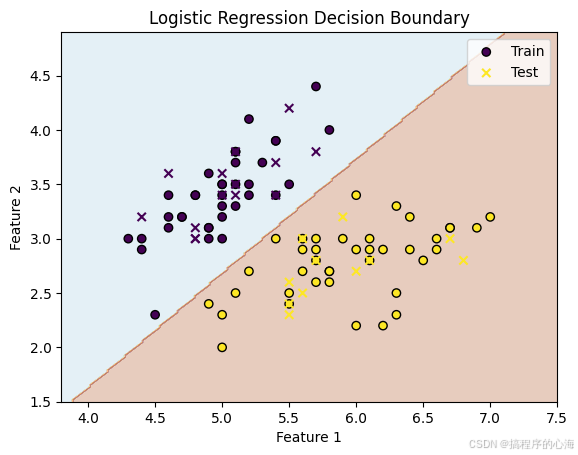
这幅图展示了逻辑回归在一个可线性区分的二分类问题上,学到了一条比较清晰的线性决策边界,并且在训练集和测试集上都有较高的正确分类率,说明模型对该问题具有良好的区分能力。
4. 优化与评估
4.1 梯度下降过程
在训练逻辑回归时,我们通常使用梯度下降来最小化交叉熵损失:
- 梯度计算:
对于每个参数,计算梯度:
- 更新公式:
其中,α是学习率。
- 重复该过程直至损失函数收敛到较低值。
4.2 混淆矩阵
混淆矩阵是评估分类模型的重要工具,它能展示模型的预测结果与真实标签的对应情况:
- 矩阵结构:
- 真阳性(TP):正确预测为正例
- 假阳性(FP):错误预测为正例
- 真阴性(TN):正确预测为负例
- 假阴性(FN):错误预测为负例
- 通过混淆矩阵,我们可以计算出精确度、召回率以及F1分数等指标。
4.3 ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)描述了不同阈值下模型的表现:
- 横轴是假正例率(False Positive Rate),纵轴是真正例率(True Positive Rate)。
- 曲线下的面积(AUC)越大,表示模型的区分能力越强。
- ROC曲线直观展示了模型在不同分类阈值下的性能,帮助我们选择最佳阈值。
5. 局限性讨论
5.1 线性假设的不足
逻辑回归本质上是一个线性分类器,其决策边界是线性的。如果数据本身存在复杂的非线性关系,单纯的逻辑回归可能难以捕捉这种复杂性。
5.2 过渡到非线性模型
为了解决线性模型的局限性,可以考虑以下方法:
- 特征工程:对原始特征进行多项式扩展(例如多项式逻辑回归),使得模型能够捕捉非线性关系。
- 核方法:利用核技巧(如支持向量机中的核方法)来构造非线性决策边界。
- 其他非线性模型:例如决策树、神经网络等,它们在处理复杂数据时往往比线性模型更具优势。
6、总结
通过本文,我们详细介绍了逻辑回归的基本思想、数学原理以及如何在 Python 中实现二分类任务。
我们不仅展示了如何利用 Sigmoid 函数将线性组合映射为概率,还推导了交叉熵损失函数,并讨论了如何利用梯度下降来优化模型。
同时,通过混淆矩阵和 ROC 曲线对模型进行评估,并指出了逻辑回归在面对复杂非线性数据时的局限性和可能的改进方向。
如果这篇文章对您有所启发,期待您的点赞关注!


















 2913
2913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









