







由于刷算法题常常可以用到STL中的类和函数,所以做一个总结。
容器类通用
迭代器:
都有 begin(),end() 函数来返回指向第一个、最后一个元素的下一个(这个要注意)的迭代器
使用时,迭代器的类型统一用 auto 即可,方便操作
不同容器的迭代器不一样,有的支持随机访问,有的不能随机访问,但是能双向访问
insert() && erase():
大多数容器类都能通过迭代器进行插入,删除。不过不同容器类的时间复杂度不一样。
输出格式
头文件:
#include<iomanip>
设置精度:
setprecision()
设置宽度:
setw()
设置对齐方式:
left,right,internal
设置输出格式:
fixed,scientific
设置填充:
setfill()
设置基数:
dec,hex,oct
标准输入
cin:
cin >> a 返回的是cin自身的引用(cin是istream类的对象)
不过在条件表达式中,返回值会被隐式地转化为布尔值,如果输入成功,则为true,否则为false
getline:
定义在<string>中。
istream& getline(std::istream& input, std::string& str, char delim = '\n')
第一个参数是一个流对象,第二个参数是输入到的字符串,第三个参数是分割符。
返回也是流对象的引用,与 cin 的返回值类似
流对象
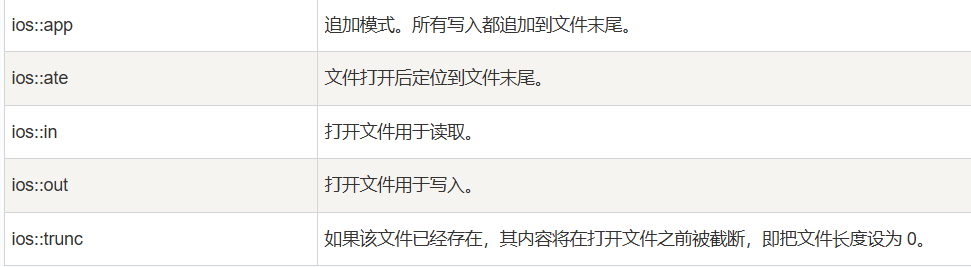
读写文件:
#include<fstream>
ifstream是只读的流,ofstream是只写的流,fstream是可读可写的流
// 打开文件(读文件类似)
// 要注意,在默认模式下写文件是会清空文件的,所以要指定app的模式写
ifstream inputFile("data.txt");
if (!inputFile.is_open()) {
cerr << "无法打开文件 data.txt" << endl;
return 1;
}
// 从文件第二个字符之后开始写
// 打开文件,同时指定读写模式
fstream file("example.txt", ios::in | ios::out);
if (!file.is_open()) {
cerr << "无法打开文件 example.txt" << endl;
return 1;
}
// 定位到第二个字符之后(索引为 2 的位置)
file.seekp(2);
// 写入内容
file << "XY";
命令行操作
编译:g++ -o 输出文件名 输入文件名
运行:./output
传参:首先要定义好main函数
int main(int argc, char* argv[]) {
// 打印程序名
cout << "程序名: " << argv[0] << endl;
// 遍历所有参数
for (int i = 1; i < argc; ++i) {
cout << "参数 " << i << ": " << argv[i] << endl;
}
return 0;
}
其中argc是参数的个数,argv是参数数组,argv[0]为程序的名称,从argv[1]开始才是程序真正的参数
最大最小值
#include<climits>;
INT_MIN 表示int类型的最小值。
INT_MAX 表示int类型的最大值。
从而避免对最大最小值进行硬编码
常用计算函数
头文件:
#include<algorithm>
min(),max()函数定义在这个头文件
#include<cmath>
pow(),sqrt()函数定义在这个头文件
1. sort()函数
头文件:
#include<algorithm>
特性:
仅支持随机访问迭代器的类,如list,map,set等底层使用链表、红黑树的容器是不能直接使用的。
底层的原理叫做Introsort,其思想为:
首先使用快速排序:利用快速排序的高效性对数据进行排序。
监控递归深度:如果快速排序的递归深度超过了某个阈值(通常是 2×logn),则切换到堆排序,以避免快速排序在最坏情况下的性能退化。
处理小数组:对于小规模的子数组(通常小于某个阈值,如16或32),使用插入排序进行优化,因为插入排序在小数据量时效率更高
用法:
sort(a.begin(),a.end()); //a是一个容器类,不指定第三个参数 默认升序排序<
sort(a.begin(),a.end(),greater<int>()); //greater<int>()指定使用 >的降序排序
class people{
public:
string name;
int age;
people(string name,int age){
this->name = name;
this->age = age;
}
};
static bool cmp(const people& p1,const people& p2){ // people对象数组根据age来升序排序
return p1.age < p2.age;
}
static bool compare(const vector<int>& v1,const vector<int>& v2){ // vector<vector<int>>根据每个vector第一个元素升序排序
return v1[0] < v2[0];
}
int main(){
vector<vector<int>>v;
vector<int>v1 = {1,2,3};
vector<int>v2 = {2,2,3};
v.push_back(v2);
v.push_back(v1);
sort(v.begin(),v.end(),compare);
for(int i = 0;i < v.size();i++){
cout << v[i][0] << " " << v[i][1] << " " << v[i][2] << endl;
}
}
reverse()函数
头文件:
#include<algorithm>
原理:
实现逻辑是通过两个迭代器分别指向范围的起始位置和结束位置(不包括结束位置),然后逐步交换这两个位置的元素,直到两个迭代器相遇,时间复杂度是O(n)
用法:
reverse(a.begin(),a.end()); //a是一个容器类,反转其中所有元素的顺序
reverse(first,last); // 准确来说是反转first到last-1这个范围内的元素
2. vector类
头文件:
#include<vector>
原理:vector类底层是一片连续的内存空间,这就意味着在中间插入和删除都要移动大量的元素,时间复杂度为O(n)
初始化:
vector<int> a(10); //包含十个元素的动态数组
修改:
a.push_back(1); //末尾添加一个
a.pop_back(); //末尾删除一个
a.empty() //是否为空
访问:
a[1]; // 直接通过下标
a.at(1); // 通过函数进行安全访问
a.front(); // 访问第一个元素
a.back(): // 访问最后一个元素
a.size(): // 获取长度
3. string类
头文件:
#include<string>
输入:
cin >> s; //从键盘读取不带空格的字符串
getline(cin,s); //从键盘读取带空格的字符串(getline函数暂时不深究)
s = s1+s2; //可以直接拼接
s += s1;
访问
s[1]; // 使用下标访问
s.at(1); // 安全访问
s.size(); // 获取长度
s.find("hello"); // 查找子串
s.substr(7,5); // 获取从第7个字符开始,后面5个字符的子串
s.back(); // 访问最后一个字符
修改:
s.replace(7,5,"hello"); //从第7个字符开始,将后面5个字符替换为hello
s.clear(); // 清空字符串
s.pop_back(); // 弹出最后一个字符
s.push_back(); // 在末尾加一个字符
在C++11后,引入了to_string()函数,可以将值转化为string.
在C++11后,引入了stoi()函数,可以将string转化为int类型.(也有stof,stol)
4. set类
set类主要分为两种:底层为红黑树,与底层为哈希表的,对应其底层数据结构的特性
| 集合 | 底层实现 | 是否有序 | 查询效率 | 增删效率 | 元素是否可重复 |
|---|---|---|---|---|---|
| set | 红黑树 | 有序 | O(logn) | O(logn) | 否 |
| multiset | 红黑树 | 有序 | O(logn) | O(logn) | 是 |
| unordered_set | 哈希表 | 无序 | O(1) | O(1) | 否 |
set:
头文件:
#include<set>
插入删除:
set<int>s;
s.insert(10); // 由于元素不重复,所以每个元素在set中是唯一的,可能插入失败
s.erase(10); // 删除元素10
查找:
auto it = s.find(10); // 查找成功则返回对应的迭代器,查找失败则返回s.end()
s.size(); // 查找长度
s.empty(); // 是否为空
遍历:
for(const auto& u : s){...} // 这个&是有说法的(不用拷贝一份新的对象,减少内存开销),而且const也是有说法的,因为容器内部使用红黑树或者哈希表,如果修改了元素值就会影响到底层的数据结构,所以是不允许修改的,一定要加const
mutiset:
头文件:
#include<set>
操作与set基本一致,但是count()函数的作用就不可以忽略了
unordered_set:
头文件:
#include<unordered_set>
操作与set一致
5.map类
map类与set类类似,也是主要分为两种:底层为红黑树,与底层为哈希表的,对应其底层数据结构的特性
| 集合 | 底层实现 | key是否有序 | 查询效率 | 增删效率 | key是否可重复 |
|---|---|---|---|---|---|
| map | 红黑树 | 有序 | O(logn) | O(logn) | 否 |
| multimap | 红黑树 | 有序 | O(logn) | O(logn) | 是 |
| unordered_map | 哈希表 | 无序 | O(1) | O(1) | 否 |
map:
头文件:
#include<map>
插入删除:
map<int,string> m;
m.insert<make_pair(1,"one")>; // 通过insert插入
m[1] = "one"; // 通过下标插入,若键 1 不存在则插入,若存在则覆盖
m.erase(1); // 删除键为1的键值对
查找:
auto it = m.find(1); // 与set中的find函数是一样的,查找成功返回迭代器,查找失败返回m.end()
string v = m[1]; // 通过下标访问键为1的键值对,获取值,若键不存在,就插入默认值,这里是{1,""}
string v = m.at(1) // 安全访问,键不存在则抛出异常
multimap和unordered_map也是差不多的
6.stack类
头文件:
#include<stack>
原理:stack是一个容器适应类,由底层的deque,vector或者list来实现
初始化:
stack<int>s;
stack<int,vector<int>>s; //因为栈默认的底层实现是双端队列deque,但是也可以用数组或者链表来实现
增删改查:
s.push(); // 入栈一个元素
s.pop(); // 出栈一个元素,不返回任何值
s.top(); // 返回栈顶元素
s.size(); // 栈中元素个数
s.empty(); // 是否为空
7.queue类
头文件:
#include<queue>
原理:queue是一个容器适应类,由底层的deque或者list来实现
初始化:
queue<int>q;
queue<int,list<int>>q; // 底层默认使用deque,也可以使用list
增删改查:
q.front(); // 获取队头元素的引用
q.back(); // 获取队尾元素的引用
q.push(); // 队尾入队
q.pop(); // 队头出队
q.emplace(); // 在队尾直接构造一个元素
q.size(); // 元素个数
q.empty(); // 是否为空
8.deque类
头文件:
#include<deque>
原理:内部是一个双向队列。使用分段的连续内存块。它将数据存储在多个固定大小的内存块中,这些内存块通过指针连接。这种设计使得deque在两端操作时效率很高,但在中间插入或删除元素的效率较低
增删改查:
deque<int>deq;
deq.push_back(); // 尾部插入
deq.push_front(); // 头部插入
deq.pop_back(); // 尾部删除
deq.pop_front(); // 头部删除
deq.front(); // 获取队头元素
deq.back(); // 获取队尾元素
9.list类
头文件:
#include<list>
原理:内部是一个双向链表
增删改查:
list<int>l;
l.push_back(); // 尾部插入
l.push_front(); // 头部插入
l.inset(); // 通过迭代器插入元素
l.erase(); // 通过迭代器删除元素
10.priority_queue类
头文件:
#include<queue>
priority_queue<int,vector<int>,greater<int>>pq; // 三个参数都要指明,这是建立一个小根堆
priority_queue<int,vector<int>>pq; // 不指定第三个参数,默认是大根堆
class people{
public:
string name;
int age;
people(string name,int age){
this->name = name;
this->age = age;
}
};
class MyCmp{ // 对于自定义对象people建立小根堆
public:
bool operator()(const people& p1,const people& p2){
return p1.age > p2.age;
}
};
int main(){
priority_queue<people,vector<people>,MyCmp>pq;
pq.push(people("lear1",12));
pq.push(people("lear2",15));
pq.push(people("lear3",10));
cout << pq.top().name << endl;
}
还有一种构造方式,使用Lambda表达式:
vector<int>counts(26,0);
auto cmp = [&](const char& c1,const char& c2){
return counts[c1-'a'] < counts[c2-'a'];
};
priority_queue<char,vector<char>,decltype(cmp)> que{cmp};

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









