






 文章介绍了如何使用SparkShell和RDD进行数据处理,包括从HDFS读取数据,通过map和sortBy获取成绩排名前5的学生成绩,使用filter和distinct找出单科成绩为100的学生ID,以及通过union和reduceByKey计算每位学生的总成绩。
文章介绍了如何使用SparkShell和RDD进行数据处理,包括从HDFS读取数据,通过map和sortBy获取成绩排名前5的学生成绩,使用filter和distinct找出单科成绩为100的学生ID,以及通过union和reduceByKey计算每位学生的总成绩。
RDD:弹性分布式数据集 (Resilient Distributed DataSet)。
目录
(二)RDD转换找出单科成绩为100的学生ID,最终的结果需要集合到一个RDD中。
(三)RDD转换输出每位学生的总成绩,要求将两个成绩表中学生ID相同的成绩相加。
(一)RDD转换取出成绩排名前5的学生成绩信息。
1.启动Spark shell交互式命令终端。
bin/spark-shell
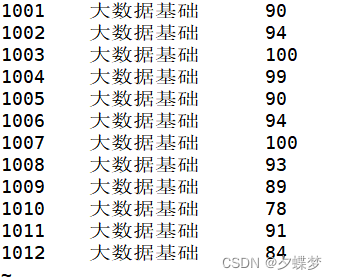
2.使用vi命令编辑三份文件。
vi student.txt
vi result_bigdata.txt
vi result_math.txt
![]()

![]()
![]()

3.将数据上传到HDFS文件系统。
hdfs dfs -put stu
dent.txt /user/root
hdfs dfs -put result_bigdata.txt /user/root
hdfs dfs -put result_math.txt /user/root

4.取出成绩排名前5的学生成绩信息。
val bigdata = sc.textFile("/user/root/result_bigdata.txt")
val math = sc.textFile("/user/root/result_math.txt")
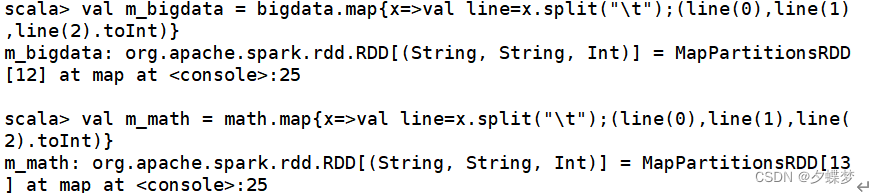
val m_bigdata = bigdata.map{x=>val line=x.split("\t");(line(0),line(1),line(2).toInt)}
val m_math = math.map{x=>val line=x.split("\t");(line(0),line(1),line(2).toInt)}

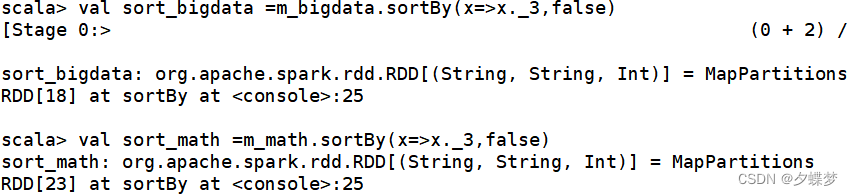
5.通过sortBy对元组中的成绩列降序排序,排序位置是每个元组的第3位的成绩。
val sort_bigdata = m_bigdata.sortBy(x=>x._3,false)
val sort_math = m_math.sortBy(x=>x._3,false)
6.通过take操作取出每个RDD的前5个值就是成绩排在前5的学生。
sort_bigdata.take(5)
sort_math.take(5)

(二)RDD转换找出单科成绩为100的学生ID,最终的结果需要集合到一个RDD中。
1.创建RDD并转换,成绩转化为Int类型。
val bigdata = sc.textFile("result_bigdata.txt").map{x=val line=x.split("\t");(line(0),line(1),line(2).toInt)}
val math = sc.textFile("result_math.txt").map{x=val line=x.split("\t");(line(0),line(1),line(2).toInt)}

2.通过filter操作过滤出成绩为100分的学生数据,并且通过map操作提取学生ID。
val bigdata_Id = bigdata.filter(x=>x._3==100).map{x=>x._1}
val math_Id =math.filter(x=>x._3==100).map{x=>x._1}

3. 将数据上传到HDFS文件系统。
hdfs dfs -put result_bigdata.txt /user/training
hdfs dfs -put result_math.txt /user/training
![]()
4.通过union操作合并所有ID并利用distinct操作去重,得到成绩为100分的学生ID。
val id = bigdata_Id.union(math_Id).distinct()
id.collect

(三)RDD转换输出每位学生的总成绩,要求将两个成绩表中学生ID相同的成绩相加。
1.用union方法将bigdata和math两个RDD合并成一个新的RDD。
val all_score = bigdata union math

2.将数据转换成(ID,score)的键值对,通过reduceByKey的方法统计总成绩并输出结果。
val all_score = all_score.map(x=>(x._1,x._3)).reduceByKey((a,b)=>a+b)
score.collect


















 3389
3389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









