






 本文介绍了Java中JDBC与SQL的数据类型转换,详细解析了ResultSet与ResultSetMetaData的使用,包括如何获取列信息。此外,还探讨了德鲁伊数据库连接池的使用,如DataSource、ResultSetHandler接口及其子类,以及DbUtils工具类的功能。
本文介绍了Java中JDBC与SQL的数据类型转换,详细解析了ResultSet与ResultSetMetaData的使用,包括如何获取列信息。此外,还探讨了德鲁伊数据库连接池的使用,如DataSource、ResultSetHandler接口及其子类,以及DbUtils工具类的功能。

基本的类的关系和操作流程;

最终的替换的流程;
Java与SQL对应数据类型转换表

ResultSet与ResultSetMetaData
- PreparedStatement 的 executeQuery() 方法,查询结果是一个ResultSet 对象
- ResultSet 返回的实际上就是一张数据表。有一个指针指向数据表的第一条记录的前面。
- ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象
的 next() 方法移动到下一行。调用 next()方法检测下一行是否有效。若有效,该方法返回 true,且指针下移。
相当于Iterator对象的 hasNext() 和 next() 方法的结合体。- 指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值。
- 注意:操作数据库都是索引是从1开始的;
- ResultSet 接口的常用方法:
boolean next()
getString()- 可用于获取关于 ResultSet 对象中列的类型和属性信息的对象
ResultSetMetaData meta = rs.getMetaData();(rs是ResultSet)
getColumnName(int column):获取指定列的名称
getColumnLabel(int column):获取指定列的别名- 总结:. 1,如何获取 ResultSetMetaData: 调用 ResultSet 的 getMetaData() 方法即可
2. 获取 ResultSet 中有多少列:调用 ResultSetMetaData 的 getColumnCount() 方法
3. 获取 ResultSet 每一列的列的别名是什么:调用 ResultSetMetaData 的getColumnLabel() 方法
总结:
两种思想
面向接口编程的思想
ORM思想(object relational mapping)
一个数据表对应一个java类
表中的一条记录对应java类的一个对象
表中的一个字段对应java类的一个属性
sql是需要结合列名和表的属性名来写。注意起别名。
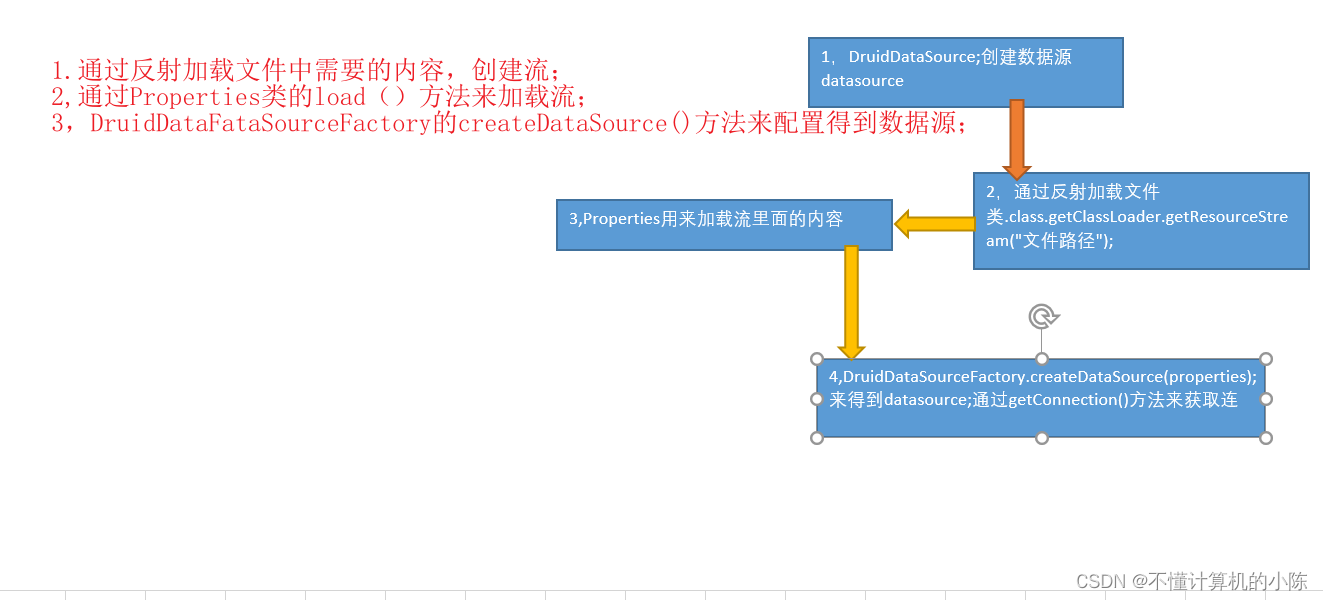
数据库连接池druid的使用
1,DataSource
DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速
数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。(一个DataSource)
常见的类和接口:
1,DruidDataSourceFactory
方法:createDataSourse(propertise);通过加载配置文件来获取数据源;
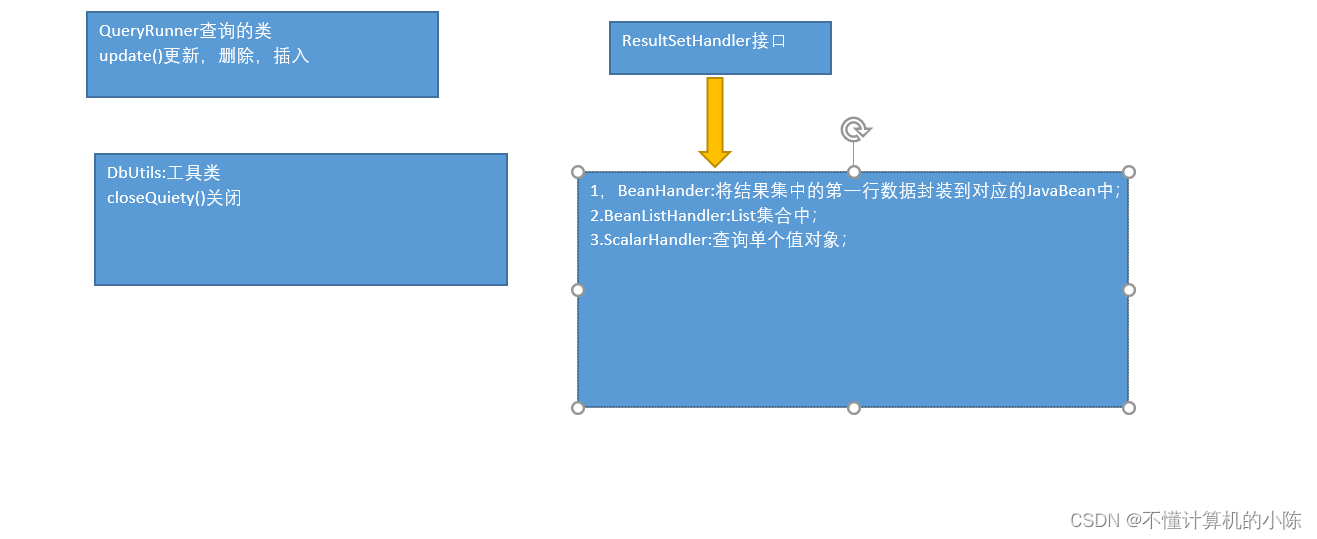
2,ResultSetHander接口;
用来处理数据查询到的结果集;他的子类来实现;
3,QueryRunner
update()和query()操作;
更新:插入,删除,更新;
public int update(Connection conn, String sql, Object... params) throws SQLException:用来执行一个更新(插入、更新或删除)操作。
查询:
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object... params) throwsSQLException:执行一个查询操作,在这个查询中,对象数组中的每个元素值被用来作为查询语句的置换参数。该方法会自行处理 PreparedStatement 和 ResultSet 的创建和关闭。
4,DbUtils
closeQuietly(…)关闭的操做;
5, ResultSetHandler接口及实现类
BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中
BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。
scalar:adj.标量的;数量的;梯状的,分等级的
n.[数] 标量;[数] 数量
ScalarHandler:查询单个值对象
德鲁伊常见的一些类


















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











