




1 嘈杂的训练数据
- 某些样本的输入本身没有任何的实际意义。例如,在MNIST数据集中输入一张全黑的图片,其不能代表任何数字。
- 输入是有效的,但是标签是错误的。这样的输入会极大的影响训练过程。
2 模糊特征
- 问题没有一个明确的界限,即标签没有办法清晰的界定。例如,如果单从图像来看,是没有办法清晰地区分苹果是未成熟的、成熟的还是腐烂的。
- 问题是没有办法解决的,其随机性较大。造成如此的原因大概是没有收集到足够多的数据,或者没有将问题进行更详细地拆分。例如,即使是相同的前一天的气温气压输入,也没有办法确定下一天的温度。也就是说,会出现前一天相同的气温气压输入但是下一天出现不同的温度。
3 罕见特征
- 机器学习的是数据整体的数据分布情况。如果机器学习模型在包含罕见特征的数据集上进行训练,那么模型很容易出现过拟合。你可以这样理解,你可以把过拟合理解为模型只是记住了训练样本的种种细节,而不是数据整体的分布。罕见样本的出现本就不在探究目的内,但是其出现会诱导模型更容易记住训练样本的具体形状,从而导致过拟合。
4 虚假的相关性
- 虚假的相关性侧重于描述样本到标签的映射。一些样本的某部分的特征可能会由于抽样方法的偏差而使得模型训练出不合理的模型。例如,假设在100个样本中(每个样本是一段文本),词表中有一个单词,这个单词在100个样本中均出现,对于标签来说,这100个样本中有60个是正面标签,40个是反面标签。这样模型在训练的过程中就会训练出这样的模型,一旦这个单词出现,那么模型就会更倾向将这句话分配到正面标签中,即使这个单词与正面还是反面标签无关!
5 如何去证明上述数据问题会对模型的训练产生影响?
上述4个方面的数据问题可以抽象为噪声数据对模型训练以何种方式产生影响。那么,我们假设噪声数据为白噪声,利用对比实验来证明噪声数据对模型训练确实有影响。
我们的基本流程是在mnist的每个样本的特征后加入白噪声通道。例如一个样本有784个特征,那么我再增加784个随机特征来进行干扰,最终形成1568个特征用于表示一个样本,从而去测噪声数据对模型训练的影响。为了更科学的进行对比实验,我们同样引入784个没有意义的全零特征用于保持数据在训练时的输入形状的一致。
from tensorflow.keras.datasets import mnist
import numpy as np
(train_images,train_labels),_=mnist.load_data()
发现其是一个三维张量,并且每个数字的取值范围是0-255,所以要对张量的形状进行改变并且要对里面的数值进行归一化处理从而辅助模型训练。
train_images = train_images.reshape(60000,28*28)
train_images = train_images.astype('float32')/255接下来进行输入数据的构建。
train_images_with_noise_channels = np.concatenate(
[train_images,np.random.random((len(train_images),784))],
axis=1
)
train_images_with_zeros_channels = np.concatenate(
[train_images,np.zeros((len(train_images),784))],
axis=1
)接下来构建模型。
from tensorflow import keras
from tensorflow.keras import layers
def get_model():
model = keras.Sequential(
[
layers.Dense(512,activation='relu'),
layers.Dense(10,activation='softmax')
]
)
model.compile(
optimizer='rmsprop',
loss="sparse_categorical_crossentropy",
metrics=['accuracy']
)
return model分别训练两个模型。
model = get_model()
history_noise=model.fit(
train_images_with_noise_channels,train_labels,
epochs=10,
batch_size=128,
validation_split=0.2
)model = get_model()
history_zeros=model.fit(
train_images_with_zeros_channels,train_labels,
epochs=10,
batch_size=128,
validation_split=0.2
)进行数据可视化。
val_acc_noise = history_noise.history['val_accuracy']
val_acc_zeros = history_zeros.history['val_accuracy']
epochs = range(1,11)
plt.plot(epochs,
val_acc_noise,
'b-',
label="val_acc_noise"
)
plt.plot(epochs,
val_acc_zeros,
'b--',
label="val_acc_zeros"
)
plt.title('Effect of noise channels on validation accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()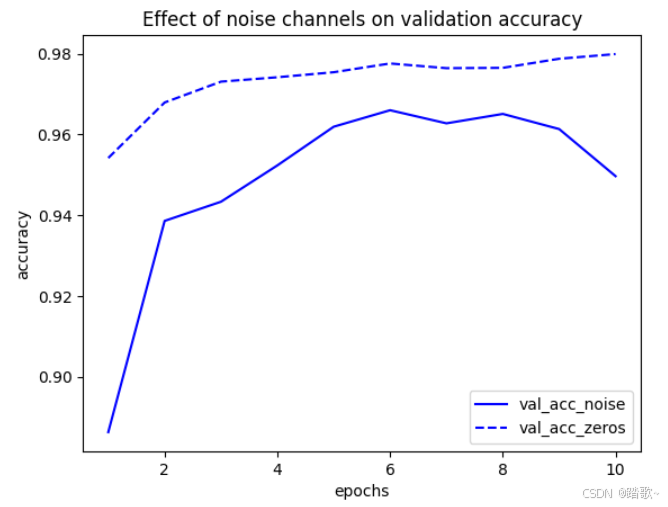
可以看到,添加了噪声的数据在训练时在验证集产生的表现要普遍低于没有添加噪声的数据。
为此,可以使用特征选择的方法确定哪些特征是有用的哪些特征是无用的。有用性分数是衡量特征对于任务来说所包含信息量的大小,可以用来进行特征选择。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











