







目录
一、主要信息
(一)数据提供者和数据集
University of California Merced、" IDAHO_EPSCOR/TERRACLIMATE"
(二)可用时间
1958年01月01日–2022年12月01日
(三)空间分辨率
4638.3米
(四)所含主要波段
如下表
| 名字 | 单位 | 最小值 | 最大值 | 描述 |
| aet | mm | 0 | 3140 | 实际蒸散量,使用一维土壤水分平衡模型推导 |
| def | mm | 0 | 4548 | 气候缺水,使用一维土壤水分平衡模型推导 |
| pdsi | -4317 | 3418 | 帕尔默干旱严重程度指数 | |
| pet | mm | 0 | 4548 | 参考蒸散 (ASCE Penman-Montieth) |
| pr | mm | 0 | 7245 | 降水累积 |
| ro | mm | 0 | 12560 | 径流,使用一维土壤水分平衡模型推导 |
| soil | mm | 0 | 8882 | 土壤湿度,使用一维土壤水分平衡模型推导 |
| srad | W/米^2 | 0 | 5477 | 向下表面短波辐射 |
| swe | mm | 0 | 32767 | 使用一维土壤水分平衡模型推导的雪水当量 |
| tmmn | ℃ | -770 | 387 | 最低温度 |
| tmmx | ℃ | -670 | 576 | 最高温度 |
| vap | 千帕 | 0 | 14749 | 蒸气压 |
| vpd | 千帕 | 0 | 1113 | 蒸气压不足 |
| vs | 米/秒 | 0 | 2923 | 10米处的风速 |
二、数据集的使用
(一)具体代码
使用此数据集下载一个区域(roi)每隔5年的年总降水的栅格影像(注意:1、这里需要自己定义一个感兴趣区域roi。2、使用此数据集不可超出它的可用时间范围。)
//循环
for(var year = 1985;year <= 2020;year += 5){
//定义初始时间和终止时间
var startdate = year + '-01-01';
var enddate = year + '-12-31';
//定义dataset,选择数据集和波段
var dataset= ee.ImageCollection("IDAHO_EPSCOR/TERRACLIMATE")
.filterBounds(roi)
.select('pr')
.filterDate(startdate, enddate) ;
var data = dataset.filter(ee.Filter.calendarRange(1,1,'month'))
.reduce(ee.Reducer.sum())
.toDouble()
.clip(roi);
//循环一年12个月的降水,计算每个月的总降水再相加
for (var i=1;i<12; i++){
var months=dataset.filter(ee.Filter.calendarRange(i,i,'month'))
.reduce(ee.Reducer.sum());
data=data.add(months);
}
Map.addLayer(data,{min:0,max:3000,palette:['white','black']},'precipitation_'+year);
//导出到云盘
Export.image.toDrive({
image:data,
description:'precipitation_'+year,
folder:'LYM',
fileNamePrefix:'precipitation_'+year,
region: roi,
maxPixels: 1e13,
crs:'EPSG:4326'
});
}
Map.centerObject(roi,8);
(二)结果
这里roi以赣州市(如图1)为例,运行结果如图2所示。
![]()
 (图1)
(图1)
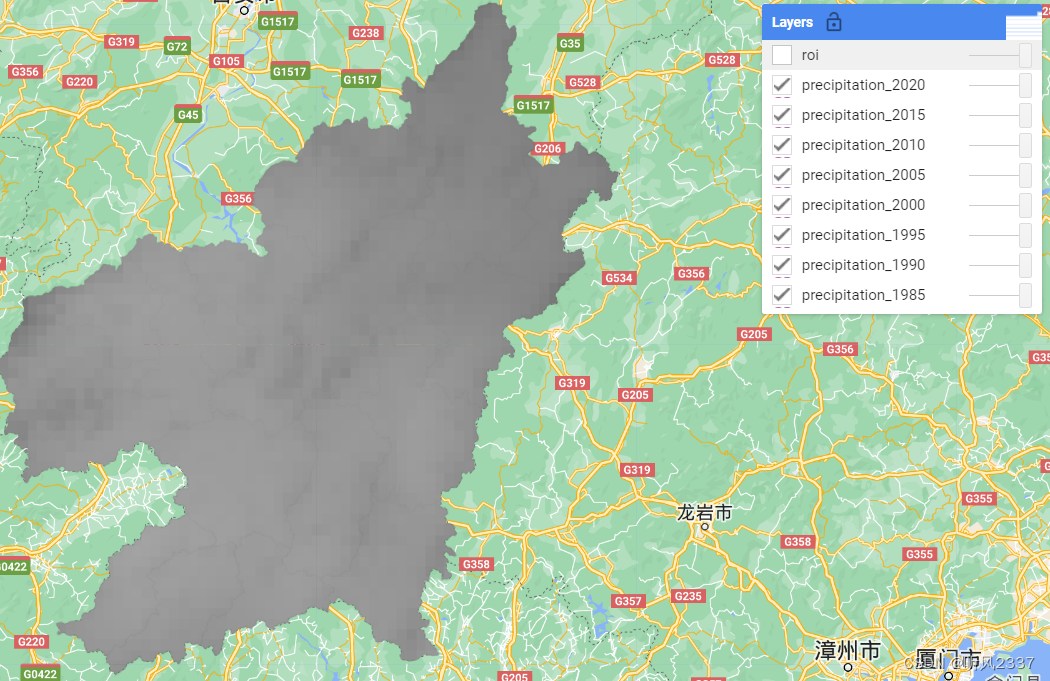 (图2)
(图2)



















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











