






1、各个软件为了防止数据丢失都有哪些解决方案
- a. 操作日志:将内存变化操作日志追加记录在一个文件中,下一次读取文件对内存重新操作
- NAMENODE:元数据的操作日志记录在edits
- MySQL:日志记录binlog ()
- b. 副本机制:将数据构建多份冗余副本
- HDFS:构建每个数据块的3个副本
- c. 依赖关系:每份数据保留与其他数据之间的一个转换关系
- RDD:保留RDD与其他RDD之间的依赖关系2、Spark如何保障数据的安全
每个RDD在构建数据时,会根据自己来源一步步倒 导 到数据来源,然后再一步步开始构建RDD数据。
问题:如果一个RDD被触发多次,这个RDD就会按照依赖关系被构建多次,性能相对较差,怎么解决?
例如:日志分析的时候,三个问题,tupleRdd 之前的所有操作都要执行三次,每次读取100M多的数据,效率非常的低
- 第一次:一定会通过血脉构建这个RDD的数据
- 希望从第二次开始,就不要重复构建,直接使用第一个构建的内容
- 实现:Spark持久化机制:主动将RDD进行保存,供多次使用,避免重复构建
1、RDD容错机制:persist持久化机制
1)cache算子
- 功能:将RDD缓存在内存中
- 语法:cache()
- 本质:底层调用的还是persist(StorageLevel.MEMORY_ONLY),但是只缓存在内存,如果内存不够,缓存会失败
- 场景:资源充足,需要将RDD仅缓存在内存中2)persist算子
- 功能:将**RDD**【包含这个RDD的依赖关系】进行缓存,可以**自己指定缓存的级别**【和cache区别】
- 语法:`persist(StorageLevel)`
- 级别:StorageLevel决定了缓存位置和缓存几份StorageLevel 有哪些级别:
# 将RDD缓存在磁盘中
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.DISK_ONLY_3 = StorageLevel(True, False, False, False, 3)
# 将RDD缓存在内存中
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
# 将RDD优先缓存在内存中,如果内存不足,就缓存在磁盘中
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
# 使用堆外内存
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
# 使用序列化
StorageLevel.MEMORY_AND_DISK_DESER = StorageLevel(True, True, False, True)Spark的StorageLevel共有9个缓存级别:
DISK_ONLY:缓存入硬盘。这个级别主要是讲那些庞大的Rdd,之后仍需使用但暂时不用的,放进磁盘,腾出Executor内存。
DISK_ONLY_2:多一个缓存副本。
MEMORY_ONLY:只使用内存进行缓存。这个级别最为常用,对于马上用到的高频rdd,推荐使用。
MEMORY_ONLY_2:多一个缓存副本。
MEMORY_AND_DISK:先使用内存,多出来的溢出到磁盘,对于高频的大rdd可以使用。
MEMORY_AND_DISK_2:多一个缓存副本。
OFF_HEAP:除了内存、磁盘,还可以存储在OFF_HEAP常用的:
MEMORY_AND_DISK_2
MEMORY_AND_DISK_DESER场景:根据资源情况,将RDD缓存在不同的地方或者缓存多份
3)unpersist 算子 --释放缓存
- 功能:将缓存的RDD进行释放
- 语法:`unpersist`
- unpersist(blocking=True):等释放完再继续下一步
- 场景:明确RDD已经不再使用,后续还有很多的代码需要执行,将RDD的数据从缓存中释放,避免占用资源
- 注意:如果不释放,这个Spark程序结束,也会释放这个程序中的所有内存示例代码:
import os
import time
# 导入pyspark模块
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
"""
------------------------------------------
Description : TODO:
SourceFile : day05
Author : yange
Date : 2024/11/1 星期五
-------------------------------------------
"""
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("spark的持久化机制")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
print(sc)
fileRdd = sc.textFile("../resources/1.dat")
# cache 是转换算子
#cacheRdd = fileRdd.cache()
cacheRdd = fileRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
print(type(cacheRdd))
cacheRdd.foreach(lambda x: print(x))
time.sleep(20)
cacheRdd.unpersist(blocking=True)
time.sleep(10)
# 使用完后,记得关闭
sc.stop()
# unpersist(blocking=True):等RDD释放完再继续下一步
# blocking = True:阻塞将日志分析案例进行优化:
import os
import re
# 导入pyspark模块
from pyspark import SparkContext, SparkConf
import jieba
from pyspark.storagelevel import StorageLevel
"""
------------------------------------------
Description : TODO:
SourceFile : _11案例
Author : admin
Date : 2023/11/7
-------------------------------------------
"""
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("第一个Spark程序")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
fileRdd = sc.textFile("../datas/sogou.tsv")
print(fileRdd.count())
print(fileRdd.first())
listRdd = fileRdd.map(lambda line: re.split("\\s+", line))
filterList = listRdd.filter(lambda l1: len(l1) == 6)
# 这个结果只获取而来时间 uid 以及热词,热词将左右两边的[] 去掉了
tupleRdd = filterList.map(lambda l1: (l1[0], l1[1], l1[2][1:-1]))
# 将tupleRdd 缓存到内存中
tupleRdd.cache()
#tupleRdd.persist(storageLevel=StorageLevel.MEMORY_AND_DISK)
# 求热词
wordRdd = tupleRdd.flatMap(lambda t1: jieba.cut_for_search(t1[2]))
filterRdd2 = wordRdd.filter(lambda word: len(word.strip()) != 0 and word != "的").filter(
lambda word: re.fullmatch("[\u4e00-\u9fa5]+", word) is not None)
# filterRdd2.foreach(print)
result = filterRdd2.map(lambda word: (word, 1)).reduceByKey(lambda sum, num: sum + num).sortBy(
keyfunc=lambda tup: tup[1], ascending=False).take(10)
"""
('的', 94084)
('地震', 90529)
('救灾', 71890)
('物资', 69240)
('救灾物资', 69092)
('哄抢', 69084)
('汶川', 68722)
('原因', 62695)
('下载', 40222)
('图片', 33283)
"""
for ele in result:
print(ele)
# 第二问: ((uid,"功夫") 10)
# [(time,uid,"中华人民"),()]
def splitWord(tupl):
li1 = jieba.cut_for_search(tupl[2]) # 中国 中华 共和国
li2 = list()
for word in li1:
li2.append(((tupl[1], word),1))
return li2
newRdd = tupleRdd.flatMap(splitWord)
#newRdd.foreach(print)
reduceByUIDAndWordRdd = newRdd.reduceByKey(lambda sum,num : sum + num)
# reduceByUIDAndWordRdd.foreach(print)
valList =reduceByUIDAndWordRdd.values()
"""
666
1
2.5522753151149264
2.5522753151149242
"""
print(valList.max())
print(valList.min())
print(valList.mean()) # 中位数
print(valList.sum() / valList.count()) #
# 第三问 统计一天每小时点击量并按照点击量降序排序
reductByKeyRDD = tupleRdd.map(lambda tup: (tup[0][0:2],1)).reduceByKey(lambda sum,num : sum + num)
sortRdd = reductByKeyRDD.sortBy(keyfunc=lambda tup:tup[1],ascending=False)
listNum = sortRdd.take(24)
for ele in listNum:
print(ele)
tupleRdd.unpersist(blocking=True)
# 使用完后,记得关闭
sc.stop()
将任务运行,运行过程中,发现内存中存储了50M的缓存数据
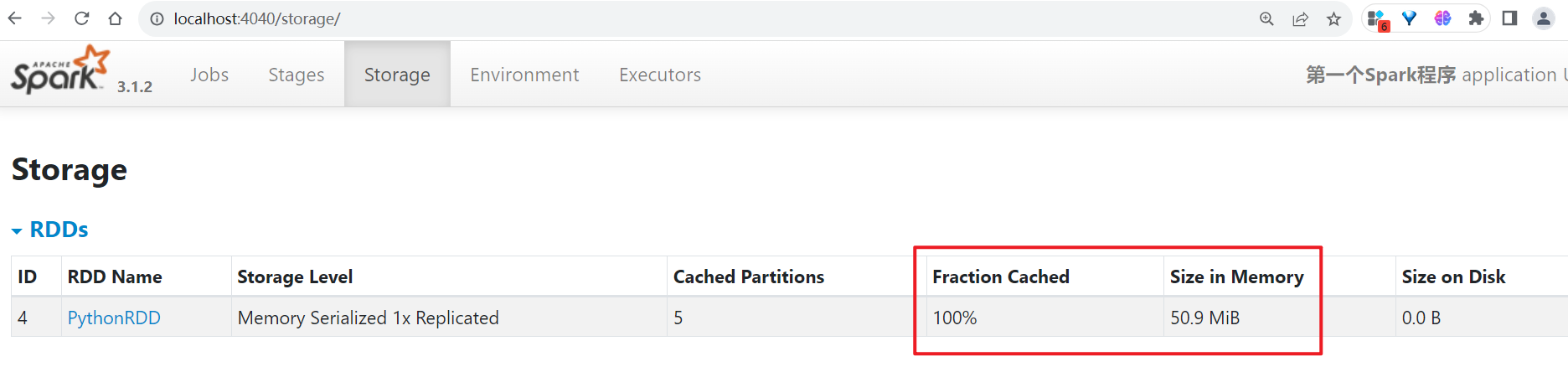
适用场景:RDD需要多次使用,或者RDD是经过非常复杂的转换过程所构建。
一般缓存的RDD都是经过过滤,经过转换之后重复利用的rdd,可以添加缓存,否则不要加。
2、RDD容错机制:checkpoint检查点机制
问题:为了避免重复构建RDD,可以将RDD进行persist缓存,但是如果缓存丢失,还是会重新构建RDD,怎么解决?
checkpoint:检查点
- 功能:将RDD的数据【不包含RDD依赖关系】存储在可靠的存储系统中:HDFS上
这个检查点有点类似于:虚拟机中的快照,像里程碑。
# 设置一个检查点目录
sc.setCheckpointDir("../datas/chk/chk1")
# 将RDD的数据持久化存储在HDFS
rs_rdd.checkpoint()
一定要在触发算子之前,调用checkpoint() 否则,检查点中没有数据- 注意:在代码中会专门多一个job,用于构建数据
- 测试:开启以后的结果
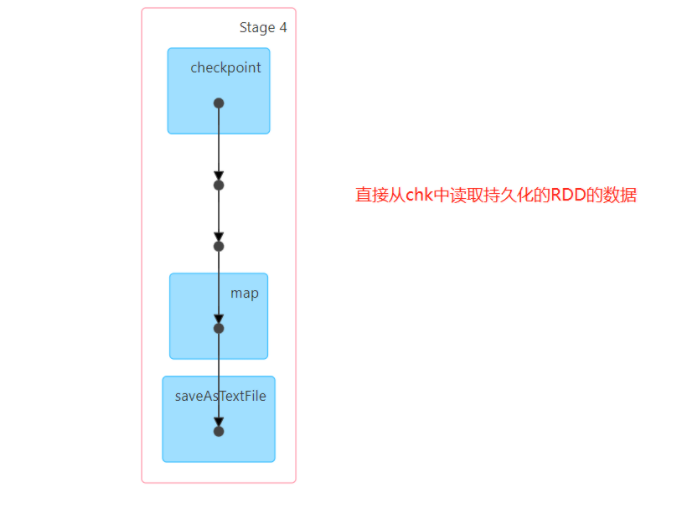
场景:高安全性,适合对RDD的数据安全性要求比较高,对性能要求不是特别高的情况下。
面试:RDD的cache、persist持久化机制和checkpoint检查点机制有什么区别?
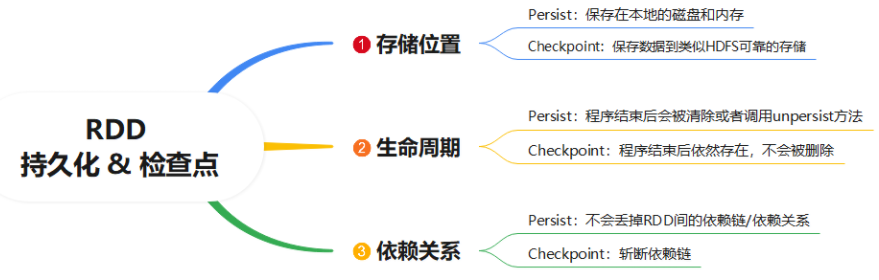
- 存储位置
- persist:将RDD缓存在内存或者磁盘中
- chk:将RDD的数据存储在文件系统磁盘中
- 生命周期
- persist:当代码中遇到了unpersist或者程序结束,缓存就会被自动清理
- chk:检查点的数据是不会被自动清理的,只能手动删除
- 存储内容
- persist:会保留RDD的血脉关系,如果缓存丢失,可以通过血脉进行恢复
- chk:会斩断RDD的血脉关系,不会保留RDD的血脉关系的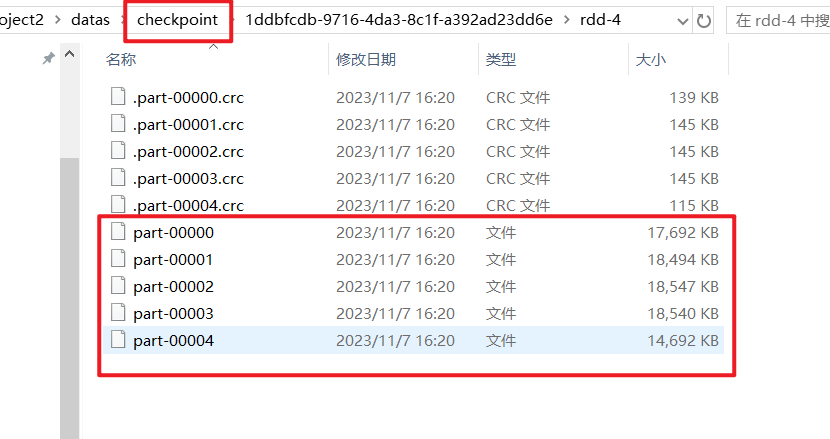

















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









