









一、关系
关系模型建立在严格的数学概念之上,包含单一的数据结构——关系,可看作一张二维表
1、域
域:一组有相同数据类型的值的集合
(包含自然数、整数、实数)
2、笛卡尔积
笛卡尔积:一种与上面的集合运算,得到每个域中元素的所有可能组合,可看作二维表
其中,包含两个概念:元组和分量
元组:每一行是一个元组
分量:每一行中每一个元素都是一个分量
笛卡尔积运算实例:
D1=导师集合SUPERVISOR={张清玫,刘毅}
D2=专业集合SPECIALITY={计算机专业,信息专业}
D3=研究生集合POSTGRADUATE={李勇,刘晨,王敏}
笛卡尔积:D1*D2*D3*...Dn={(d1,d2,...,dn)|di∈Di,i=1,2,...}[小程序]【专栏必读】(考研复试)数据库系统概论第五版(王珊)专栏学习笔记目录导航及课后习题答案详解
| SUPERVISOR | SPECIALITY | POSTGRADUATE |
| 张清玫 | 计算机专业 | 李勇 |
| 张清玫 | 计算机专业 | 刘晨 |
| 张清玫 | 计算机专业 | 王敏 |
| 张清玫 | 信息专业 | 李勇 |
| 张清玫 | 信息专业 | 刘晨 |
| 张清玫 | 信息专业 | 王敏 |
| 刘毅 | 计算机专业 | 李勇 |
| 刘毅 | 计算机专业 | 刘晨 |
| 刘毅 | 计算机专业 | 王敏 |
| 刘毅 | 信息专业 | 李勇 |
| 刘毅 | 信息专业 | 刘晨 |
| 刘毅 | 信息专业 | 王敏 |
此笛卡尔积的基数为:2*2*3=12,即12个元组
(3)关系
A:基本概述
关系:笛卡尔积(D1×D2....×Dn)的子集叫做在域D1,D2,...,Dn的关系,表示为R(D1,D2,...,Dn),其中
R:关系名
n:关系的目或度(n=1时称为单元关系,n=2时称为二元关系)
关系既然是笛卡尔积的子集(有限子集),所以关系也是一张二维表
表的每一行对应一个元组,表的每一列对应一个域
由于域可以相同,为了区分,必须对每列起一个名字,称为属性(比如上面的表中研究生和导师都是人,为了区分,所以才取了不同的名字)
B:码相关概念
以下面关系为例:R(学号,姓名,性别,课程名,期末分数)
候选码:若关系中的某一属性组(注意是组不是某单个属性,当然有时属性组也可能只有一个属性)能唯一地标识一个元组,而其子集不能,则该属性组称之为候选码
上面关系中,学号是无法区分的,因为学号虽然不重复,但一个学生可能会对应多个课程,这就导致学号无法唯一标识一个元组。因此这里(学号,课程名)可以作为一个候选码
需要注意的是候选码不一定只有一个,可能有多个,只要满足条件即可,但在本例中确实只有一个
超码:能够唯一标识一条记录的属性或属性集,超码是候选码的扩充,候选码是最小的超码
上面关系中,(学号、课程名)是候选码,那么它的超集,例如(学号、课程名、姓名)、(学号、课程名、性别)就是超码
主码:某个能够唯一标识一条记录的最小属性集(候选码中的“人选之子”)
候选码可能有多个,但是数据库设计者在设计时会根据实际需求选择一个候选码作为主码
外码:是本关系的属性且不是码,而是另一个关系的主码(后续会详细介绍)
全码:这是一种特殊情况:关系的所有属性组是这个关系模式的候选码
主属性和非属性:包含在候选码中的属性(注意是集合,不是某个候选码)称为主属性;不包含在候选码中的属性称为非主属性
上面关系中,姓名、性别和期末分数都是非主属性
C:关系的三种类型
关系可以有三种类型
基本关系(又称为基本表):实际存在的表,是实际存储数据的逻辑表示
查询表:查询结果对应的表
视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
其中基本关系满足以下性质(作了解即可)
(1)列是同质的
(2)不同的列可以出自同一个域
(3)列的顺序无所谓
(4)任意两个元素的候选码不能取相同值
(5)行的顺序无所谓
(6)分量必须去原子值
二:关系模式
型(type):对某一类数据的结构和属性的说明
值(value):是型的一个具体赋值
在关系数据库中,关系模式就是型,关系就是值,关系模式是对关系的描述,具体来说要描述以下方面
元组集合的结构(由哪些属性构成、这些属性来自哪些域、属性与域之间的映像关系)
元组语义以及完整性约束
属性之间的数据依赖关系
关系模式:关系模式就是对关系的描述,可以表示为R(U,D,DOM,F)
R:关系名
U:组成该关系的属性名集合
D:U UU中属性所来自的域
DOM:属性向域的映像集合
F:属性间数据的依赖关系集合(此部分属于第六章:关系数据理论的内容)
关系模式通常可以简记为(重点用):R(U)或R ( A 1 , A 2 , . . . , A n )
R:关系名
A 1 , A 2 , . . . , A n :属性名
“域名”及“属性向域的映像”常常直接说明为属性的类型和长度
三:关系数据库
(1)基本概念
关系数据库:在一个给定的应用领域中,所有关系的集合构成的一个关系数据库
(2)关系数据库的型与值
关系数据库的型:也称为关系数据库模式,是对关系数据库的描述,包括
若干域的定义
在这些域上定义的若干关系模式
关系数据库的值:这些关系模式在某一时刻对应的关系的和,通常就叫做关系数据库
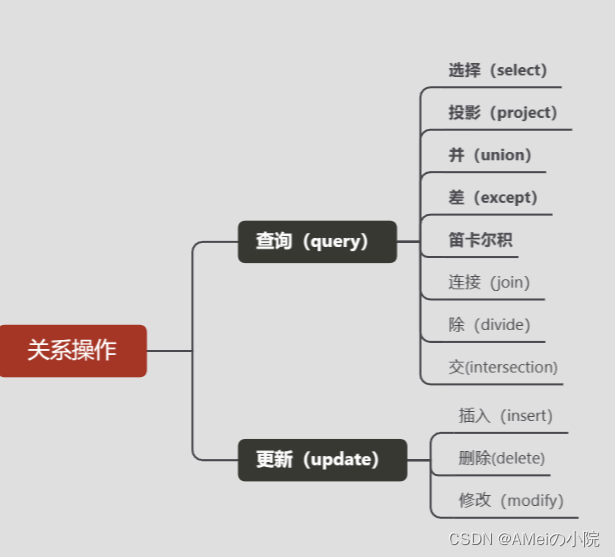
四:关系操作
(1)基本的关系操作
关系模型常用关系操作如下。
关系操作的特点是集合操作方式,也即操作的对象和结果都是集合。也称为一次一集合(set-at-a-time)的方式
非关系数据模型的数据操作方式称为一次一记录(record-at-a-time)
五:关系完整性约束
关系完整性规则是对关系的某种约束条件,这些约束条件实际上是现实世界的要求,例如性别只能有男、女两种取值
关系模型中有如下三类完整性约束
实体完整性(entity integrity)
参照完整性(referential integrity)
用户自定义完整性(user-defined integrity)
其中实体完整性和参照完整性是关系模型必须满足的完整性约束条件,被称为关系的两个不变性
(1)实体完整性
实体完整性:若属性A是基本关系R的主属性,则属性A不能取空值
例如“选修(学号,课程号,成绩)”关系中,若(学号,课程号)为主码,则学号和课程号都不能取空值
(2)参照完整性
A:参照关系
(注意在关系表示中,下划线表示主码)
【例1】如下两个关系中,学生关系引用了专业关系的主码“专业号”,也就是说,学生关系中的某个属性的取值需要参照专业关系的属性取值
学生(学号,姓名,性别,专业号,年龄)
专业(专业号,专业名)
【例2】如下三个关系中,选修关系引用了学生关系的主码“学号”和课程关系的主码“课程号”,也就是说,选修关系中某些属性的取值需要参照其他关系的属性取值
学生(学号,姓名,性别,专业号,年龄)
课程(课程号,课程名,学分)
选修(学号,课程号,成绩)
【例3】还有,同一关系内部也可能存在引用关系。比如在学生(学号,姓名,性别,专业号,年龄,班长)关系中,“学号”属性是主码,“班长”属性表示该学生所在班级的班长的学号,它引用了本关系“学号”属性,即“班长”必须是确实存在的学生的学号
| 学号 | 姓名 | 性别 | 专业号 | 年龄 | 班长 |
| 801 | 张三 | 女 | 01 | 19 | 802 |
| 802 | 李四 | 男 | 01 | 20 | |
| 803 | 王五 | 男 | 01 | 20 | 802 |
| 804 | 赵六 | 女 | 02 | 20 | 805 |
| 805 | 钱七 | 男 | 02 | 19 |
B:外码
外码:设F是基本关系R RR的一个或一组属性,但不是关系R 的码【例如这里F是学生关系的专业号】,Ks是基本关系S的主码【例如这里Ks是专业关系的主码】。若F和Ks 相对应,则称F是R 的外码(foreign key)【则称专业号是学生关系的外码】,并称基本关系R为参照关系(referencing relation)【这里学生关系就是参照关系】,基本关系S为被参照关系(referenced relation)【这里专业关系就是被参照关系】。关系R和S不一定是不同的关系
注意:外码并不一定要与相应的主码同名,如上面第三个例子中,学生关系的主码为学号,外码为班长。不过,在实际应用中为了便于识别,当外码与相应的主码属于不同关系时,往往给它们取相同的名字。
上面三个例子的参照关系表示如下
C:参照完整性规则
参照完整性:若属性或属性组F是基本关系R的外码,它与基本S的主码相对应(关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须
要么取空值(此时F的每个属性值均为空值)
要么等于S中某个元组的主码值
因此对于【例1】,学生关系中每个元组的专业号只能取下面两类值
空值:表示该学生尚未分配专业
非空值(且该值必须是专业关系中某个元组的专业号值):表示该学生不能分配到一个不存在的专业中
而对于【例2】,按照道理来说“学号”和“课程号”也可以取两类值,但是“学号”和“课程号”它作为的是选修关系的主码,所以如果取空值的话将会违背实体完整性规则
对于【例3】,R和S是同一个关系,“班长”可以取两类值
空值:该班还没有选出班长
非空值:班长必须是班里的同学
(3)用户自定义完整性
用户自定义完整性1针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求,例如某个属性必须取唯一值,某个非主属性不能取空值等等
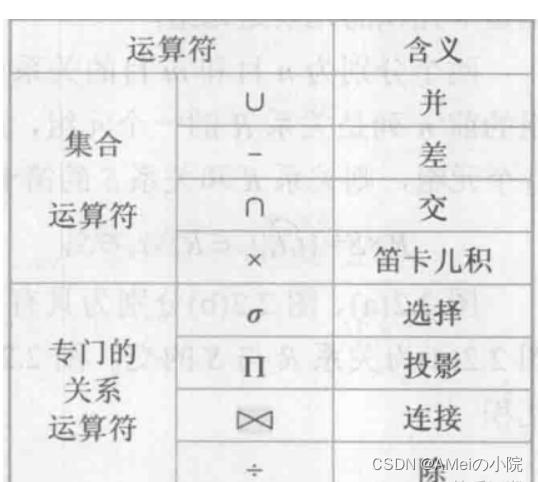
六:关系代数的基本概念
关系代数:是一种抽象的查询语言,用于对关系运算来表达查询
关系代数的运算对象和运算结果都是关系,所用到运算符可分为如下两种
- 传统的集合运算:运算从行的角度进行
- 专门的关系运算:运算同时涉及行和列
七:传统的集合运算
严格的定义这里不再给出,可借助课本。我的目的就是能帮助快速理解即可
(1)并(union)
并:对于关系R和S,并操作就是将两个关系上下拼在一起形成一个新的关系,记为R∪S
所以两个关系具有相同数目的属性
| A | B | C |
| 3 | 8 | 1 |
| 5 | 4 | 2 |
| 7 | 3 | 6 |
| 9 | 7 | 4 |
| 2 | 3 | 5 |
| A | B | C |
| 1 | 5 | 7 |
| 4 | 6 | 8 |
| 2 | 3 | 5 |
| 5 | 4 | 2 |
| 3 | 4 | 6 |
| A | B | C |
| 3 | 8 | 1 |
| 5 | 4 | 2 |
| 7 | 3 | 6 |
| 9 | 7 | 4 |
| 2 | 3 | 5 |
| 1 | 5 | 7 |
| 4 | 6 | 8 |
| 2 | 3 | 5 |
| 5 | 4 | 2 |
| 3 | 4 | 6 |
(2)差(except)
差:对于关系R 和S,求他们的差,就是在R 中去掉两个关系中所有相同的行,形成一个新的关系,记为R -S
| A | B | C |
| 3 | 8 | 1 |
| 7 | 3 | 6 |
| 2 | 3 | 5 |
(3)交(intersection)
交:对于关系R和S,求他们的交,就是选出两个关系中所有相同的行,形成一个新的关系,记为R ∩S
所以R∩S=R-(R−S)
| A | B | C |
| 2 | 3 | 5 |
| 5 | 4 | 2 |
(4)笛卡尔积(cartersian product)
笛卡尔积:对于关系R和S,求他们的笛卡尔积,就是两个关系所有元组的不同排列组合,形成一个新的关系,记为R×S
| A | B | C | D | E |
| 1 | 2 | 3 | a | b |
| 1 | 2 | 3 | c | d |
| 4 | 5 | 6 | a | b |
| 4 | 5 | 6 | c | d |
| 7 | 8 | 9 | a | b |
| 7 | 8 | 9 | c | d |
八:专门的关系运算
注意:在下面的叙述中有时会用到如下三种关系
学生关系Student
课程关系Course
选修关系SC
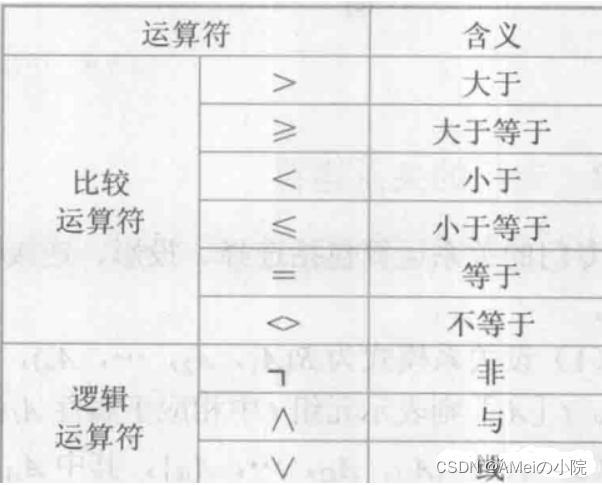
(1)选择(selection)
选择:从行的角度出发,在关系R RR中选择满足条件的元组然后组成新的关系。“满足条件”意味着有条件表达式,其运算符如下
例如可在关系Student中查询所有IS系的学生,查询结果形成一个关系,记为![]()
| 学号Sno | 姓名Student | 性别Ssex | 年龄Sage | 所在系Sdept |
| 201215121 | 李勇 | 男 | 20 | CS |
| 201215122 | 刘成 | 男 | 19 | CS |
| 201215123 | 张立 | 男 | 19 | IS |
-->
| Sno | Sname | Ssex | Sage | Sdept |
| 201215125 | 张立 | 男 | 19 | IS |
再比如可在关系Student中查询所有年龄小于20的学生,查询结果形成一个关系,记为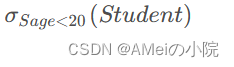
| Sno | Sname | Ssex | Sage | Sdept |
| 201215122 | 刘成 | 男 | 19 | CS |
| 201215123 | 张立 | 男 | 19 | IS |
(2)投影(projection)
选择:从列的角度出发,选择满足条件的若干属性列组成新的关系
投影之后取消了原关系中的某些列,当然也有可能会取消某些元祖(因为一旦取消了某些属性列后就极有可能出现重复行),所以一定注意消除完全相同的行
例如在关系Student中查询姓名和所在系的投影,记为
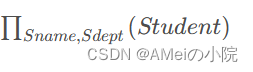
| 学号Sno | 姓名Student | 性别Ssex | 年龄Sage | 所在系Sdept |
| 201215121 | 李勇 | 男 | 20 | CS |
| 201215122 | 刘成 | 男 | 19 | CS |
| 201215123 | 张立 | 男 | 19 | IS |
| 201215125 | 王敏 | 女 | 18 | MA |
| Sname | Sdept |
| 李勇 | CS |
| 刘成 | CS |
| 张立 | MA |
| 王敏 | IS |
再比如在关系Student中查询都有哪些系,记为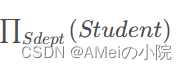
注意投影要取消重复的CS元组
| Sdept |
| CS |
| IS |
| MA |
(3)连接(join)
A:等值连接和自然连接
等值连接:可以按照如下步骤考虑,最终形成新的关系,记为
首先找到关系R和S中属性相同的列
然后找到两列中相同的元素
将相同元素所在的行组成新的一行,需要用【关系.属性】的格式区两个关系中相同的属性
| A | B | C |
| a1 | b1 | 5 |
| a1 | b2 | 6 |
| a2 | b3 | 8 |
| a2 | b4 | 12 |
| B | E |
| b1 | 3 |
| b2 | 7 |
| b3 | 10 |
| b3 | 2 |
| b5 | 2 |
| A | R.B | C | S.B | E |
| a1 | b1 | 5 | b1 | 3 |
| a1 | b2 | 6 | b2 | 7 |
| a2 | b3 | 8 | b3 | 10 |
| a2 | b3 | 8 | b3 | 2 |
自然连接:它是一种特殊的等值连接,在等值连接的结果中去掉重复列即可
| A | B | C | E |
| a1 | b1 | 5 | 3 |
| a1 | b2 | 6 | 7 |
| a2 | b3 | 8 | 10 |
| a2 | b3 | 8 | 2 |
B:外连接
悬浮元组的概念:R 和S在做自然连接时,R中某些元组有可能在S中不存在公共属性上值相等的元组,就会造成R中这些元组在操作时被舍弃(反过来S也是这样)。例如上图自然连接中就舍弃了R的第4个元组和S的第5个元组
外连接:若将悬浮元组保留在自然连接的结果中,而在其他属性上填NULL,那么这种连接就叫做外连接,同时
左外连接:只保留左边关系R中的悬浮元组
右外连接:只保留右边关系R中的悬浮元组
| A | B | C |
| a1 | b1 | 5 |
| a1 | b2 | 6 |
| a2 | b3 | 8 |
| a2 | b4 | 12 |
| B | E |
| b1 | 3 |
| b2 | 7 |
| b3 | 10 |
| b3 | 2 |
| b5 | 2 |
| A | B | C | E |
| a1 | b1 | 5 | 3 |
| a1 | b2 | 6 | 7 |
| a2 | b3 | 8 | 10 |
| a2 | b3 | 8 | 2 |
| A | B | C | E |
| a1 | b1 | 5 | 3 |
| a1 | b2 | 6 | 7 |
| a2 | b3 | 8 | 10 |
| a2 | b3 | 8 | 2 |
| a2 | b4 | 12 | NULL |
| NULL | b5 | NULL | 2 |
| A | B | C | E |
| a1 | b1 | 5 | 3 |
| a1 | b2 | 6 | 7 |
| a2 | b3 | 8 | 10 |
| a2 | b3 | 8 | 2 |
| a2 | b4 | 12 | NULL |
| A | B | C | E |
| a1 | b1 | 5 | 3 |
| a1 | b2 | 6 | 7 |
| a2 | b3 | 8 | 10 |
| a2 | b3 | 8 | 2 |
| NULL | b5 | NULL | 2 |
(4)除(division)
除:是笛卡尔积的逆运算,对于关系R和S,求R÷S可按如下步骤考虑
研究对象是R和S中相同的属性列
在R中挑选元祖,所挑选的元组一定满足它的属性均出现在S对应相同属性列的所有属性集合内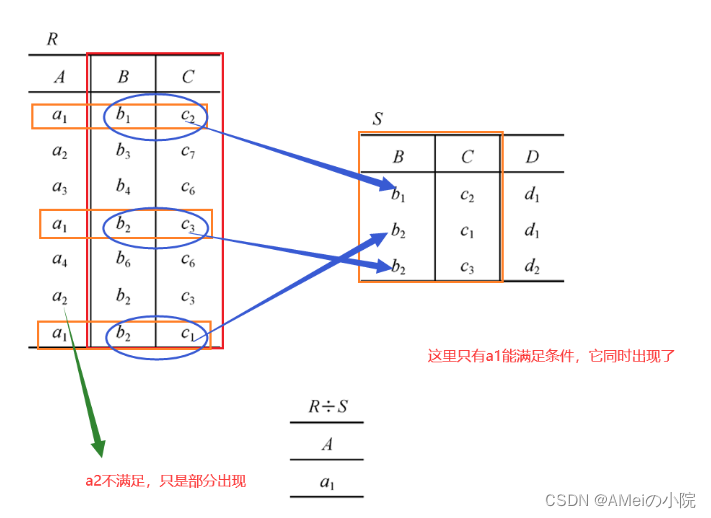
————————————————
版权声明:本文为优快云博主「快乐江湖」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/qq_39183034/article/details/122545467
https://blog.youkuaiyun.com/qq_39183034/article/details/122539916
https://blog.youkuaiyun.com/qq_39183034/article/details/122535012

















 2802
2802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









