







目录
在大数据处理领域,SparkSQL 凭借其强大的数据处理能力和高效的计算性能备受青睐。其中,DataFrame 作为重要的数据结构,掌握它与其他数据类型(如 RDD、DataSet)之间的转换操作至关重要。今天,我们就深入探讨在 Spark 中如何进行 DataFrame 的转换,帮助大家更好地驾驭 SparkSQL 处理各类数据场景。
一、Spark 中的数据类型概述
RDD(弹性分布式数据集)
它类似于分布式列表,数据以列表中每个元素作为一行,是一种基础且灵活的数据结构,能处理结构化、非结构化数据,在 SparkCore 中被广泛运用。例如,我们可以从文件读取数据生成 RDD,像通过sc.textFile方法读取文本文件内容转化为 RDD,每个元素对应文件的一行文本数据。
DataFrame
可看作分布式表,包含数据与 Schema(数据模式,即列名、列类型等信息),其本质是DataSet[Row],是 DataSet 的特殊形式,一行数据包含多列。比如处理结构化表格数据时,DataFrame 能很方便地进行列操作、筛选等,像存储用户信息表(含用户 ID、姓名等字段)就适合用 DataFrame 表示。
DataSet
同样是分布式表(数据 + Schema),优势在于支持泛型,泛型中能填入如自定义的User、Car、Dog等实体对象,使用更加灵活强大,不过在 Pyspark 中常不直接显现。

二、DataFrame 的转换方式
自动推断类型转换 DataFrame
在 Spark 里,要将 RDD 自动转换为 DataFrame,核心思路是把 RDD 中每条数据转换成 Row 类型,之后 Spark 可自动完成转换。假设我们有个 RDD 存储用户评分数据(原始格式为字符串,每行含多个字段信息,以特定分隔符分开),通过map操作拆分每行字符串为数组,再进一步转换数组元素类型、整理成元组形式,后续利用 Spark 自动推断机制可转为 DataFrame。例如:
数据
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
核心代码:
Row(userid=item[0], movieid=item[1], rate=float(item[2]), ts=int(item[3]))
df1 = spark.createDataFrame(movie_row_rdd)代码:
with SparkSession.builder.master("local[2]").appName("第一次构建SparkSession").getOrCreate() as spark:
# 通过sparkSession获取 sc 对象
sc = spark.sparkContext
# 通过这个对象可以调用算子 SparkCore
fileRdd = sc.textFile("../../datas/movie/a.data")
mapRdd = fileRdd.map(lambda line: line.split()) \
.map(lambda item: Row(userid=item[0], movieid=item[1], rate=float(item[2]), ts=int(item[3])))
# 如何将一个 RDD变为 DataFrame
df = spark.createDataFrame(mapRdd)
df.printSchema() 这里先读取文件生成fileRdd,经两次map操作整理数据格式,最终调用toDF方法指定列名,自动完成到 DataFrame 的转换并展示数据,让原本松散的 RDD 数据以结构化表格形式呈现,方便后续分析操作。
自定义 Schema 转换 DataFrame
这种方式需手动构建 Schema,明确各列名称、数据类型及是否可为空等属性,再基于该 Schema 将 RDD 转换为 DataFrame。以下是示例代码逻辑:

from pyspark.sql import SparkSession
import os
from pyspark.sql.types import Row, StructType, StructField, StringType, DoubleType, LongType
if __name__ == '__main__':
# 构建环境变量
# 配置环境
os.environ['JAVA_HOME'] = 'D:/Program Files/Java/jdk1.8.0_271'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
with SparkSession.builder.master("local[2]").appName("第一次构建SparkSession").getOrCreate() as spark:
# 通过sparkSession获取 sc 对象
sc = spark.sparkContext
# 通过这个对象可以调用算子 SparkCore
fileRdd = sc.textFile("../../datas/movie/a.data")
mapRdd = fileRdd.map(lambda line: line.split()) \
.map(lambda item:(item[0],item[1],item[2],item[3]))
# 如何将一个 RDD变为 DataFrame
# 创建一个Schema
user_schema = StructType([
StructField(name="userid", dataType=StringType(), nullable=False),
StructField(name="movieid", dataType=StringType(), nullable=True),
StructField(name="rate", dataType=DoubleType(), nullable=True),
StructField(name="ts", dataType=LongType(), nullable=True)
])
# 将数据和schema组合在一起形成df
df = spark.createDataFrame(mapRdd,user_schema)
df.printSchema() 先定义user_schema详细描述数据结构,再借助spark.createDataFrame传入 RDD 和自定义 Schema 创建 DataFrame,适用于对数据列类型把控严格、需精准定义场景,像金融数据处理中对金额字段设为DoubleType且明确不可为空来保障数据规范性。
三、DataFrame 与 RDD 互转
当 RDD 算子中每行都是 Row 对象时可便捷转换。示例如下:
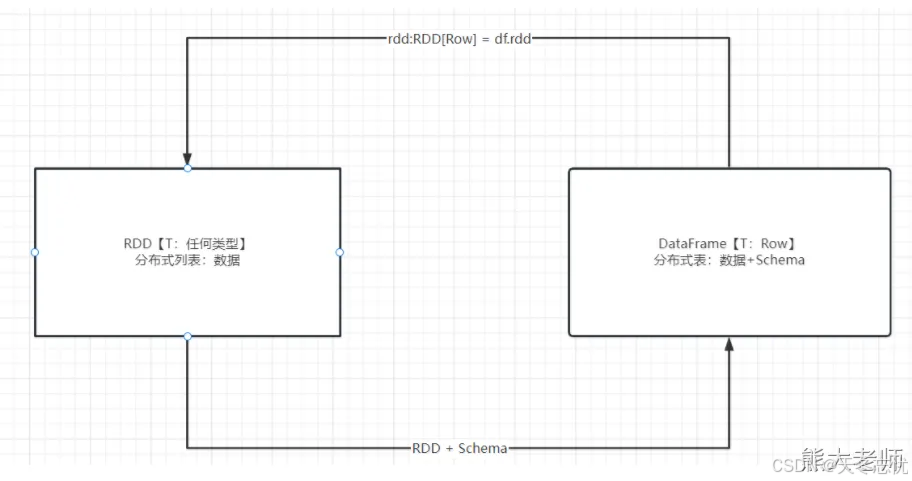
先学习 Rdd 怎么变为 DataFrame
toDF函数
- 功能:将元素类型为元组类型的RDD直接转换为DataFrame
- 语法
def toDF(self: RDD[RowLike], schema: List[str]) -> DataFrame
代码演示:将rdd转变为dataFrame的三种方式
import os
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
if __name__ == '__main__':
# 获取sparkSession对象
# 设置 任务的环境变量
os.environ['JAVA_HOME'] = r'C:\Program Files\Java\jdk1.8.0_77'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = r'C:\ProgramData\Miniconda3\python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 得到sparkSession对象
with SparkSession.builder.master("local[2]").appName("电影评分").config("spark.sql.shuffle.partitions",
2).getOrCreate() as spark:
# 数据类型转换, 将 rdd --> dataframe
sc = spark.sparkContext
fileRdd = sc.textFile("../../datas/zuoye/ratings.dat")
mapRdd = fileRdd.map(lambda line:line.split("::")).map(lambda list:(list[0],list[1],float(list[2]),int(list[3])))
#mapRdd.foreach(print)
# mapRdd --> DataFrame
# 第一种方案
df = mapRdd.toDF(["user_id", "movie_id", "rate","time"])
df.show()
# 第二种方案
# 这一种方案,必须rdd 算子中每一行都是 Row 对象
mapRdd2 = mapRdd.map(lambda tuple:Row(user_id=tuple[0], movie_id=tuple[1], rate=float(tuple[2]), ts=int(tuple[3])))
df2 = spark.createDataFrame(mapRdd2)
df2.show()
# 第三种方案
# rdd --> DataFrame
# 创建一个Schema
user_schema = StructType([
StructField(name="user_id", dataType=StringType(), nullable=False),
StructField(name="movie_id", dataType=StringType(), nullable=True),
StructField(name="rate", dataType=DoubleType(), nullable=True),
StructField(name="ts", dataType=LongType(), nullable=True)
])
df3 = spark.createDataFrame(mapRdd,user_schema)
df3.show()
如何将dataframe类型的数据变为rdd
dataframe类型的数据.rdd 就变为rdd类型的数据了,切记 此时的rdd 泛型是 [Row]
代码演示:
dfRdd = df.rdd
dfRdd.filter(lambda row: row["rate"] == 3).foreach(print)全部代码:
import os
from pyspark import Row
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
if __name__ == '__main__':
# 获取sparkSession对象
# 设置 任务的环境变量
os.environ['JAVA_HOME'] = r'C:\Program Files\Java\jdk1.8.0_77'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = r'C:\ProgramData\Miniconda3\python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 得到sparkSession对象
spark = SparkSession.builder.master("local[2]").appName("电影评分").config("spark.sql.shuffle.partitions",
2).getOrCreate()
# 数据类型转换, 将 rdd --> dataframe
sc = spark.sparkContext
print(sc)
fileRdd = sc.textFile("../../datas/zuoye/ratings.dat")
mapRdd = fileRdd.map(lambda line: line.split("::")).map(
lambda list: (list[0], list[1], float(list[2]), int(list[3])))
# mapRdd.foreach(print)
# mapRdd --> DataFrame
# 第一种方案
df = mapRdd.toDF(["user_id", "movie_id", "rate", "time"])
df.show()
# 第二种方案
# 这一种方案,必须rdd 算子中每一行都是 Row 对象
mapRdd2 = mapRdd.map(lambda tuple: Row(user_id=tuple[0], movie_id=tuple[1], rate=float(tuple[2]), ts=int(tuple[3])))
df2 = spark.createDataFrame(mapRdd2)
df2.show()
# 第三种方案
# rdd --> DataFrame
# 创建一个Schema
user_schema = StructType([
StructField(name="user_id", dataType=StringType(), nullable=False),
StructField(name="movie_id", dataType=StringType(), nullable=True),
StructField(name="rate", dataType=DoubleType(), nullable=True),
StructField(name="ts", dataType=LongType(), nullable=True)
])
df3 = spark.createDataFrame(mapRdd, user_schema)
df3.show()
# 将dataframe变为rdd
rdd1 = df3.rdd
rdd1.filter(lambda row: row['rate'] >= 3.0).foreach(print)
# sc.stop()四、实际应用场景与注意事项
应用场景
在企业数据处理流程中,若数据源是半结构化(如日志文件含不规则格式时间戳、文本描述等)或特殊格式数据,因 SparkSQL 的 DataFrame 只能处理结构化数据,一般需先经 SparkCore(基于 RDD)处理。比如电商订单日志,先用 RDD 清洗、规整格式(提取关键订单信息、转换日期格式等),再转换为 DataFrame 利用 SparkSQL 做复杂分析(关联查询不同表、统计各地区订单量等)。
注意事项
- 进行自动推断转换时,要确保 RDD 数据整理规范,对应列数据类型符合后续操作预期,不然可能出现类型转换错误、数据解析异常。
- 自定义 Schema 时,仔细核对各字段属性设置,错误的类型定义或空值限制会导致数据丢失、写入失败等问题,尤其在数据持久化环节。
- 不同转换方式性能有差异,大规模数据处理时可提前测试对比,选择最优转换策略提升整体处理效率。
五、总结
SparkSQL 中 DataFrame 转换操作是数据处理核心环节,灵活掌握其与 RDD 转换、多种转换方式细节,结合实际场景按需选择,能让我们在大数据分析、处理复杂业务数据道路上畅通无阻,高效挖掘数据价值、赋能业务决策。后续大家可在本地环境多尝试不同数据样本、转换操作组合,深化理解运用。


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











