







DataX3.0是阿里云DataWorks数据集成的开源版本,它继承了DataX1.0的优良基因,并在此基础上进行了全面的升级和扩展。新版本的DataX3.0不仅支持更多的数据源和目标端,还提供了更高效的数据同步能力,能够满足企业在数据迁移、数据同步和数据集成等场景下的需求。本文将深入探讨DataX3.0的主要特性、框架设计、支持的数据源、核心架构、安装测试以及实战案例。
主要特性
-
丰富的数据源支持:DataX3.0支持包括关系型数据库、NoSQL数据库、文件系统等多种数据源,几乎涵盖了所有常见的数据存储系统。
-
高性能的数据同步:通过优化内部处理流程和算法,DataX3.0在数据同步性能上有了显著提升,能够处理大规模数据迁移和同步任务。
-
易用的配置管理:DataX3.0提供了简洁明了的配置文件,用户可以轻松地进行数据源和目标端的配置,实现数据同步的自动化。
-
强大的容错机制:新版本增强了容错处理能力,即使在网络不稳定或数据源出现问题的情况下,也能确保数据同步的稳定性和可靠性。
-
灵活的错误处理:DataX3.0允许用户自定义错误处理策略,包括错误记录、重试机制等,以适应不同的业务需求。
DataX3.0框架设计

类似于之前的Flume:
source --> ReadPlugin
channel --> Channel
sink --> WritePlugin
DataX3.0支持的数据源
Datax可以理解为国内版的Sqoop。但是比Sqoop要快,Sqoop底层是MR(Map任务),基于磁盘的,DataX基于内存的,所以速度比较快。
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

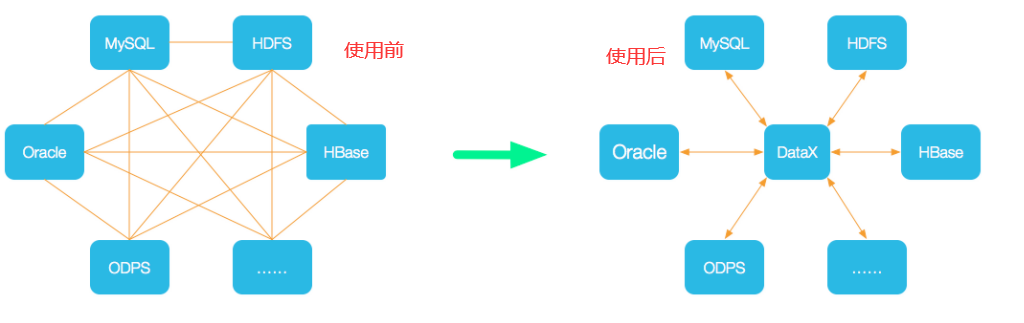
核心架构
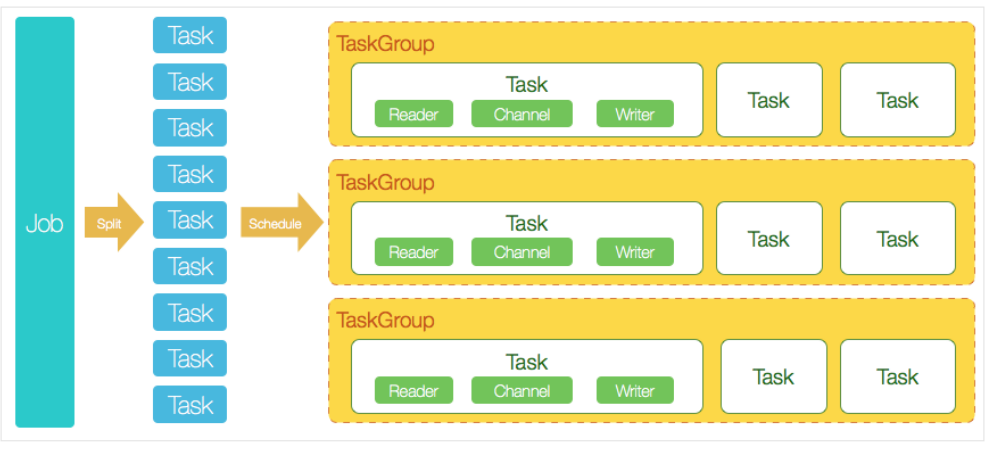
一个Job要想执行,可能会拆分成多个Task任务,这些任务又会分为很多个组,每一个组里面,又根据channel的数量,进行汇总,并行执行,默认一个TaskGroup 有 5个channel
计算题:
假如一个Job,被拆分为100个任务,20 个组,每个组里面并行执行5个任务。job 100个任务
TaskGroup 假如需要20个并发量
每一个TaskGroup 默认是5个任务
用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到HDFS里面。 DataX的调度决策思路是:
1. DataXJob根据分库分表切分成了100个Task。
2. 根据20个并发,DataX计算共需要分配4个TaskGroup。
3. 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task
datax中的数据导入导出,是并行执行的,并且是基于内存的,所以比较快!
安装与测试
DataX3.0的安装过程相对简单,用户可以从GitHub上直接下载。
https://github.com/alibaba/DataX
github访问速度比较慢,访问不上,科学上网。
也可以使用Steam++_v3.0.0软件
通过网盘分享的文件:Steam++_v3.0.0-rc.8_win_x64.zip
安装
1、上传 /opt/modules
2、解压 tar -zxvf datax.tar.gz -C /opt/installs
3、修改/etc/profile
配置环境变量:
export DATAX_HOME=/opt/installs/datax
export PATH=$PATH:$DATAX_HOME/bin
source /etc/profile
测试一下
Play一下自带的案例:
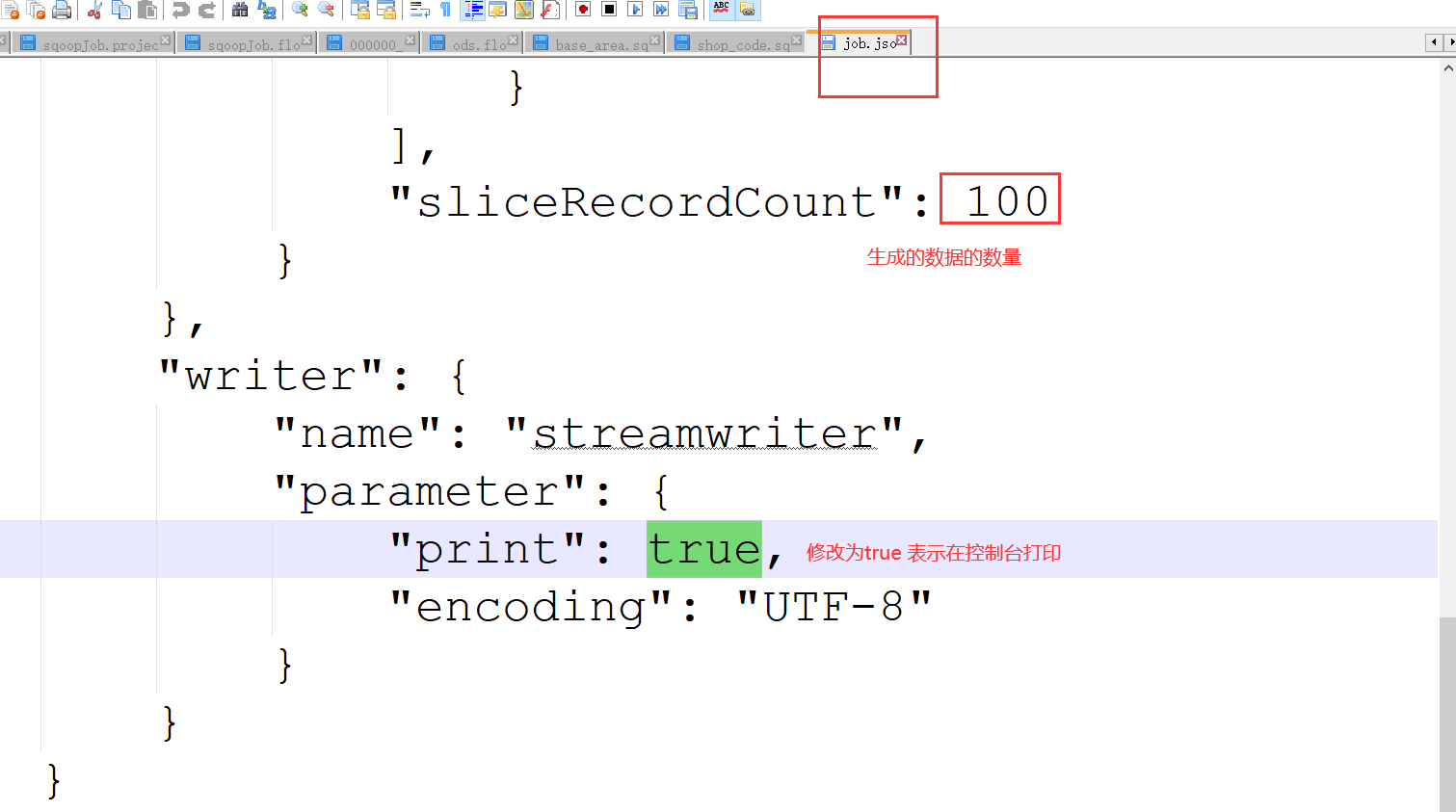
编辑这个案例:job.json文件
运行一下:
datax.py job.json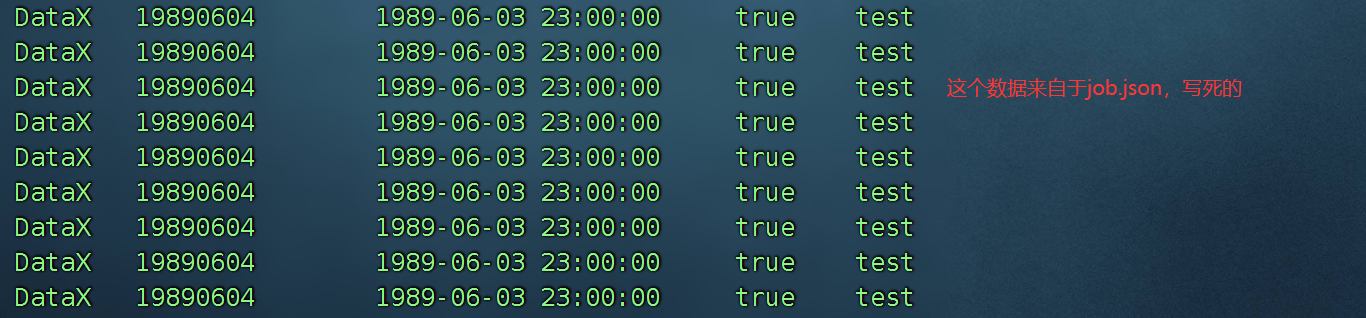

假如你运行报错如下:
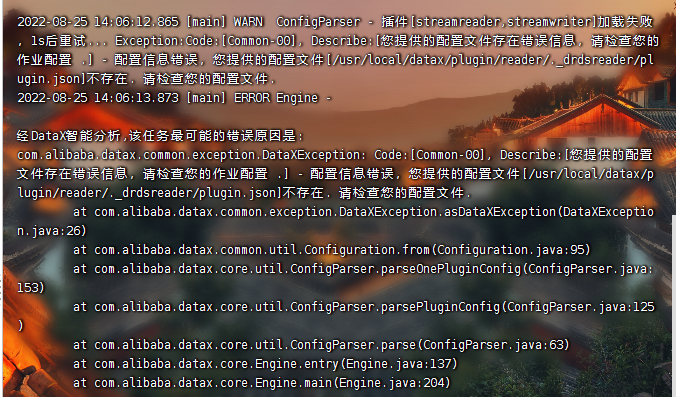
报错:
配置信息错误,您提供的配置文件[/opt/installs/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件rm -rf /opt/installs/datax/plugin/*/._*
说明运行该脚本的位置不对,找不到对应的json文件。

因为以后要链接mysql数据库,mysql数据库的驱动包少不了:
cp /opt/installs/sqoop/lib/mysql-connector-java-8.0.26.jar /opt/installs/datax/lib/实战案例
1) MySQLReader 案例
通过编写JSON配置文件,DataX能够读取MySQL数据库中的数据并将其输出到控制台。在配置文件中,如果需要指定所有字段,应使用带双引号的星号("*")。
1)datax 是让你编写 json
2) flume 是让你编写 conf
3) azkaban 是让你编写 flow
4) sqoop 是让你写命令
git --> 上传到 云龙--> gitLab 搭建的呢(代码管理)
在job 文件夹 创建一个文件 mysql2stream.json ,代码如下
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": [
"select * from emp where empno < 7788;"
],
"jdbcUrl": [
"jdbc:mysql://bigdata01:3306/sqoop"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true,
"encoding": "UTF-8"
}
}
}
]
}
}如果使用 cloumn 属性,并且是所有字段,使用 * , * 的左右两边需要添加双引号。
读取mysql的数据,将数据展示在控制台上。此时的stream其实就是控制台
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"empno",
"ename"
],
"splitPk": "empno",
"connection": [
{
"table": [
"emp"
],
"jdbcUrl": [
"jdbc:mysql://bigdata01:3306/sqoop"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
运行:
datax.py mysql2stream.json2) 含有sql语句的mysqlReader案例
DataX同样支持将数据写入MySQL数据库。需要注意的是,如果表中存在主键约束,DataX在写入时会根据主键避免重复插入。
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": ["select * from emp where comm is not null;"],
"jdbcUrl": ["jdbc:mysql://bigdata01:3306/sqoop"]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true,
"encoding": "UTF-8"
}
}
}
]
}
}特殊说明:

如果你编写的json文件中需要用到字段类型,必须指定DataX内部类型,不要使用Mysql类型和java类型
3) MySQLWriter 展示
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "SHAWN", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": ["empno", "ename", "job", "hiredate", "sal"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://bigdata01:3306/sqoop",
"table": ["emp"]
}
]
}
}
}
]
}
}由于emp表中empno是主键,所以10条数据,只插入了一条。

mysql Writer 的另一个案例:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "ZhangSan", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "root",
"password": "123456",
"column": ["empno", "ename", "job", "hiredate", "sal"],
"preSql": ["delete from emp"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://bigdata01:3306/sqoop",
"table": ["emp"]
}
]
}
}
}
]
}
}insert into 插入 不判断,直接插入
replace into 先查看这个主键是否有数据,如果有直接删除并插入,如果没有,直接插入。
4))HDFSReader 案例展示
DataX能够读取和写入HDFS上的数据。在处理HDFS数据时,需要注意字段类型的支持和文件的分隔符。
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/home/a.txt",
"defaultFS": "hdfs://bigdata01:9820",
"column": [ "*" ],
"fileType": "text"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}column 中的字段类型目前已知的支持的有: long、double、string、bool、date、bytes 不支持 int,varchar ,目前正在探索中....

5) HDFS只读取部分列值
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/home/a.txt",
"defaultFS": "hdfs://bigdata01:9820",
"column": [
{"index": 0, "type": "long"},
{"index": 1, "type": "long"},
{"value": "老闫真帅", "type": "string"}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}假如 hdfs 上的文件的分隔符是 tab 键,如何切分?
1 zhangsan 20
2 lisi 38上传至 hdfs
hdfs dfs -put /home/b.txt /home编写任务读取对应的数据:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/home/b.txt",
"defaultFS": "hdfs://bigdata01:9820",
"column": [
{"index": 0, "type": "long"},
{"index": 1, "type": "string"},
{"index": 2, "type": "long"}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}6) 将数据导入到hdfs上,即 hdfsWriter 案例
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "SHAWN", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://bigdata01:9820",
"path": "/datax/emp",
"fileName": "emp",
"column": [
{"name": "empno", "type": "string"},
{"name": "ename", "type": "string"},
{"name": "job", "type": "string"},
{"name": "hiredate", "type": "string"},
{"name": "sal", "type": "double"}
],
"fileType": "text",
"writeMode": "append",
"fieldDelimiter": "\t"
}
}
}
]
}
}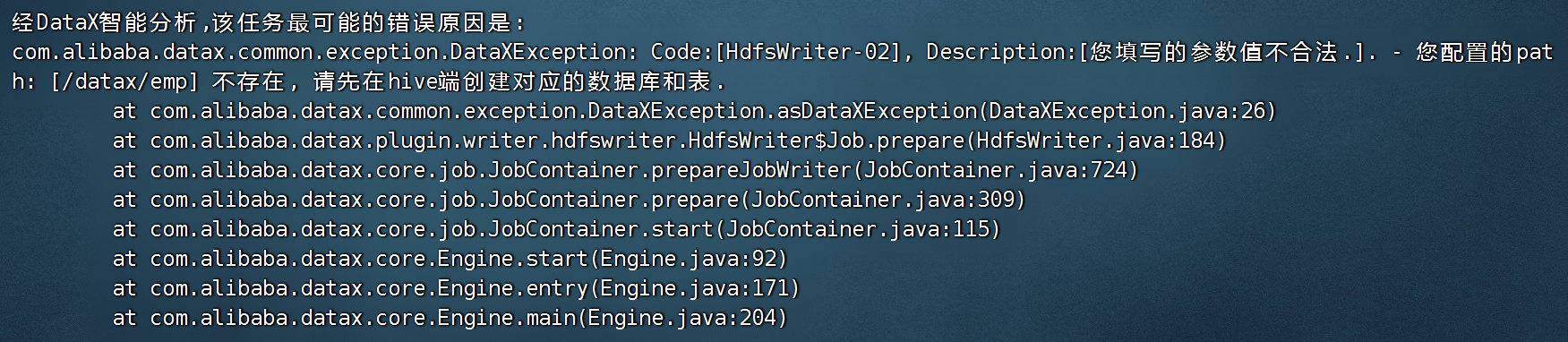
说明 hdfs上的路径必须提前创建好
hdfs dfs -mkdir -p /datax/emp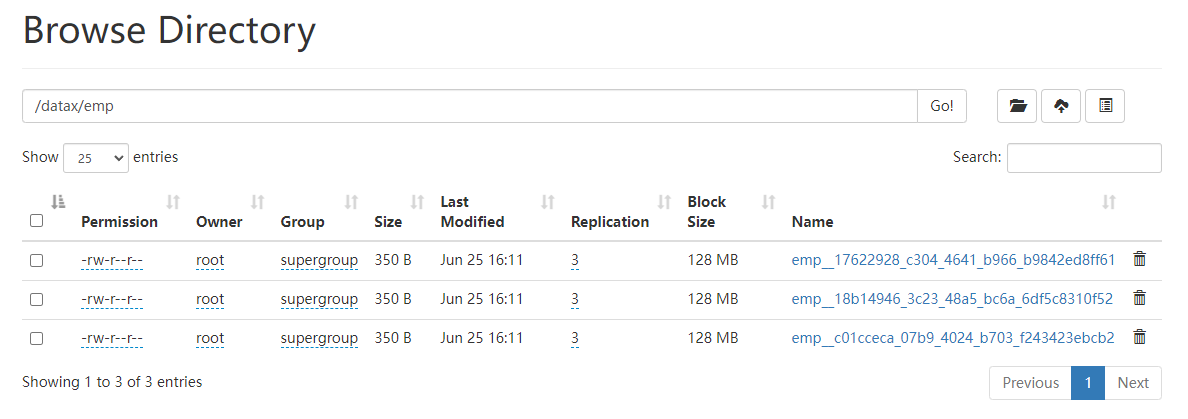
hdfswriter 中的columns 类型,一般跟hive 表中的字段 类型保持一致是不会报错的。
将刚才 hdfs 上的数据读取出来,打印到控制台:
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/datax/emp/*",
"defaultFS": "hdfs://bigdata01:9820",
"column": [
{"index": 0, "type": "string"},
{"index": 1, "type": "string"},
{"index": 2, "type": "string"},
{"index": 3, "type": "string"},
{"index": 4, "type": "double"}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}7)将mysql的数据导入到hive中 重要
[hive 可以作为数仓使用 ]
第一步:创建mysql的表 base_area
需要使用base_area.sql
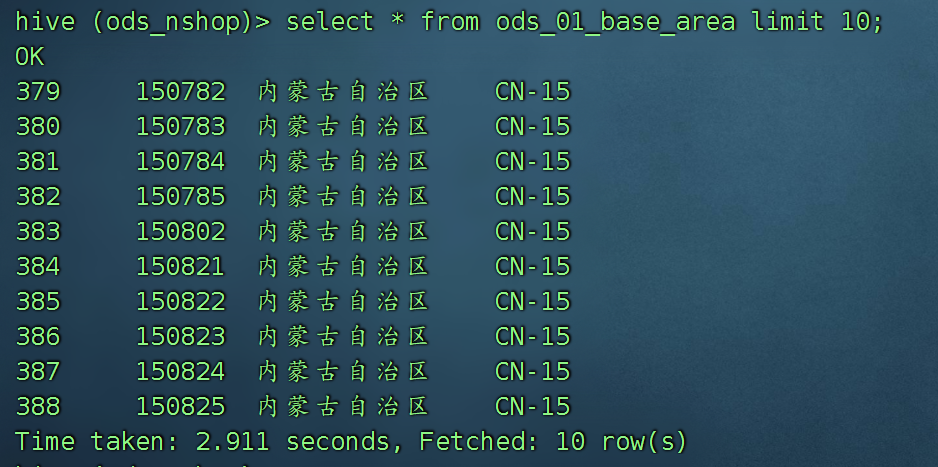
第二步:在hive中创建一个ods_01_base_area
create external table if not exists ods_01_base_area (
id int COMMENT 'id标识',
area_code string COMMENT '省份编码',
province_name string COMMENT '省份名称',
iso string COMMENT 'ISO编码'
)row format delimited fields terminated by ','
stored as TextFile
location '/data/nshop/ods/ods_01_base_area/';从mysql导入到hive中(其实就是导入到hdfs)
编写对应的Job的json文件:
read 方 是mysqlreader
write 方 是 hive (没有找到,找到了hdfswriter)
在 job文件夹,创建一个 mysql2hive01.json
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"area_code",
"province_name",
"iso"
],
"splitPk": "id",
"connection": [
{
"table": [
"base_area"
],
"jdbcUrl": [
"jdbc:mysql://bigdata01:3306/sqoop"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://bigdata01:9820",
"fileType": "text",
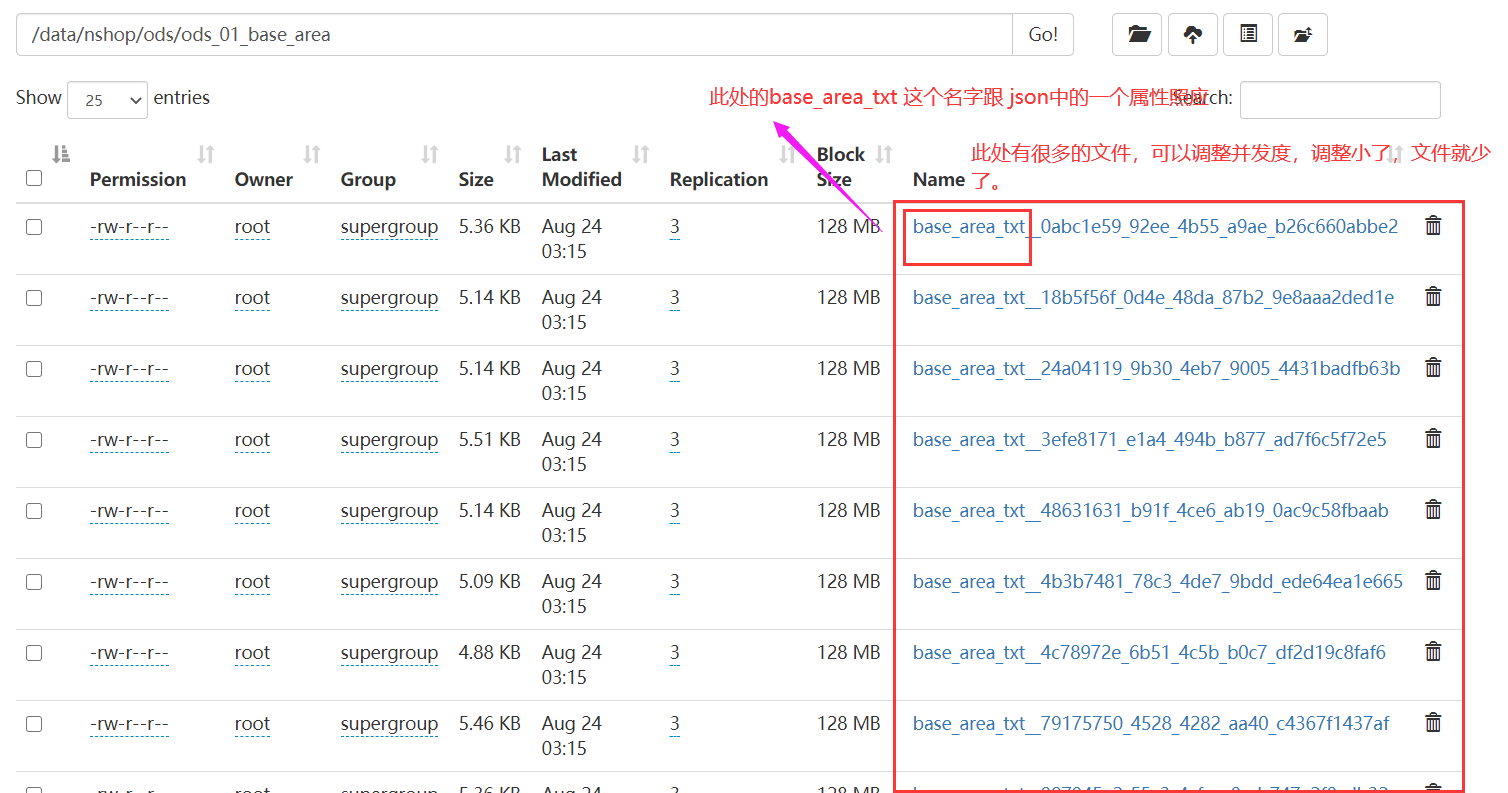
"path": "/data/nshop/ods/ods_01_base_area/",
"fileName": "base_area_txt",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "province_name",
"type": "string"
},
{
"name": "iso",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}
mysql数据导入hive表,使用sqoop,不需要事先在hive中创建表,而datax需要。这样的话,大大提升了工作量。
8)数据从hive导出到mysql 重要
一般都是将hive中分析的结果,存入到hive的一个表中,web端想展示,必须将hive中的数据导出到mysql或者其他关系型数据库中。
insert into c
select id,name,count(1) from a join b on a.xx = b.xx;
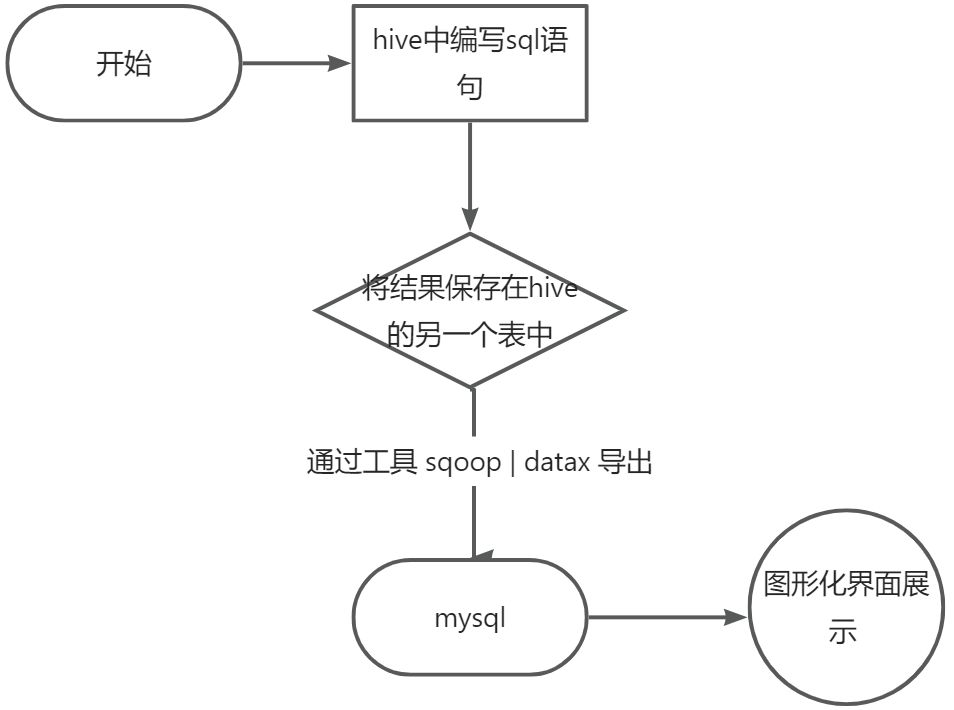
数据准备:
查看hive中是否有数据:
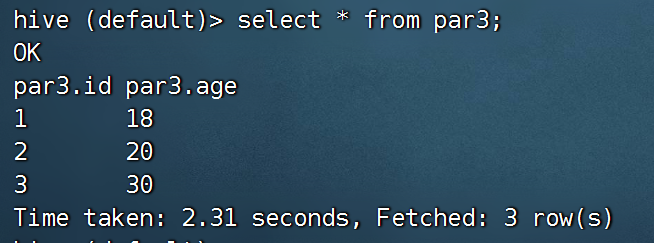
在mysql中创建一个表,用于存放数据。
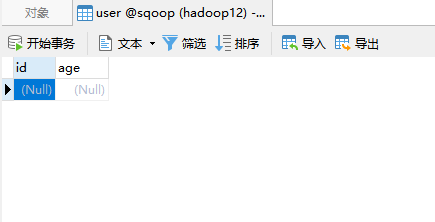
目标:从par3中导出数据到mysql的user表。

在咱们的datax中没hiveReader,但是有hdfsreader,所以本质上就是hdfs导出到mysql
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/yhdb.db/par3/*",
"defaultFS": "hdfs://bigdata01:9820",
"column": [
{
"index": 0,
"type": "long"
},
{
"index": 1,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"age"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://bigdata01:3306/sqoop",
"table": [
"par3"
]
}
]
}
}
}
]
}
}
结果展示:
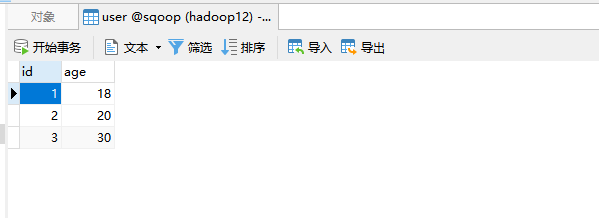
9)datax如何做增量导入
DataX支持增量导入,通过在SQL语句中使用WHERE子句来指定时间范围或其他条件,实现对新数据的提取。
sqoop增量导入有两种方案:
1、使用where语句 2、使用last-value 和 job任务一起使用,让job记住last-value
datax只有一种方案:使用where语句
举例:
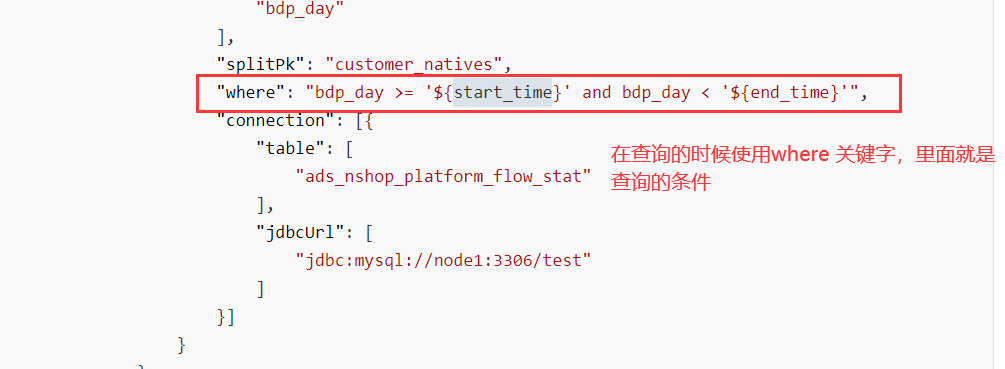
id name dtime
1 zhangsan 2024-09-05 12:38:56
2 lisi 2024-09-05 08:38:12
想提取这个表中的 9 月 5 号的数据
select * from a where dtime >='2024-09-05 00:00:00' and dtime <='2024-09-05 23:59:59'
还有一种方案:
select * from a where substr(dtime,1,10) ='2024-09-05'
如果json中有变量,需要传递值,在运行的时候,使用-D 传递即可
datax.py job/append.json -p "-Dstart_time=2021-01-01 -Dend_time=2021-01-03"
第二种还是使用where条件,只是这个时候的where条件是在SQL语句中

调优指南
DataX提供了全局和局部两种配置文件,允许用户调整并发度、记录数和字节数等参数来优化数据同步性能。正确地调整这些参数,可以显著提高数据迁移的效率。
DataX中有配置文件,一种全局的,一种局部的。
全局的是 conf/core.json

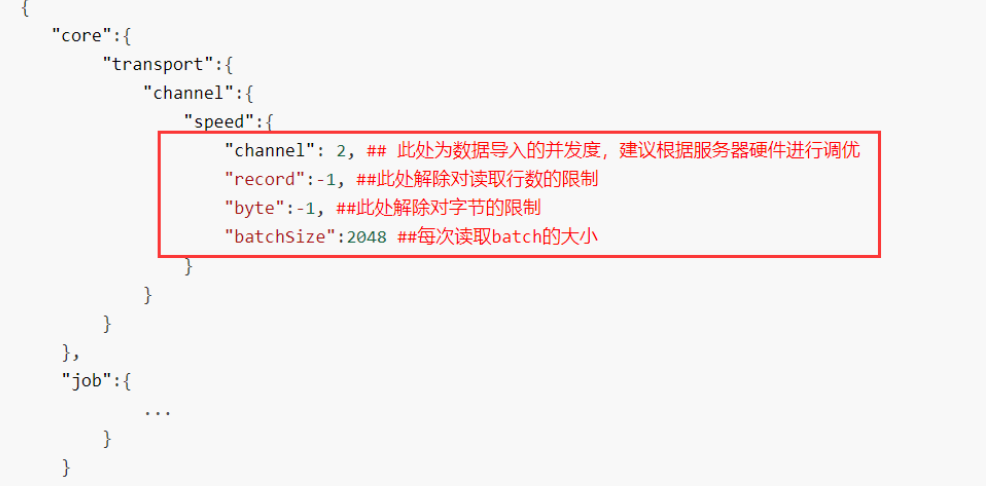
#默认值1024一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量
也可以通过 record 和 byte 进行限速,这个值是每秒的条数和字节大小。
这个地方可以调整channel的各项参数,并发度默认是5个。
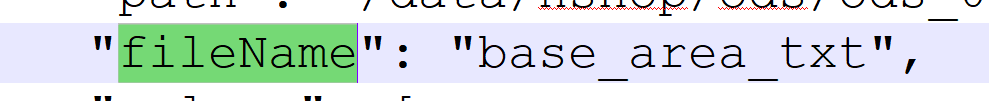
局部的配置文件,就是自己写的 xxxx.json

参数调优
1、调整channel(频道)的数量,扩大并发度
2、调整jvm堆的大小,调整方案可以使用局部调整
python datax.py --jvm="-Xms3G -Xmx3G" ../job/test.json
JVM虚拟机的大小,不是随便设置的,假如你的物理机 16G, JVM不可能设置的超过16G,默认jvm最大内存是物理内存的 1/4, 最小内存是 1/64。一般这个任务比较大,报OOM异常了,或者GC次数特别的情况下,就可以指定堆大小。
指定的时候为什么初识容量大小和最大容量是一样的呢?
因为从初识容量到最大容量,需要不断的尝试,这个也比较耗时,所以一步到位即可。
关于并行度的说明
结语
DataX3.0作为一个功能强大、灵活且易于使用的开源数据集成工具,能够帮助企业高效地处理海量数据的迁移和同步任务。通过深入理解其架构和配置,用户可以充分发挥DataX3.0的潜力,解决实际工作中的数据集成挑战。


















 3901
3901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











