







一、度保持的随机化网络
编程实践案例:(蛋白质网络数据)
#加载蛋白质网络数据集
df = pd.read_csv('D:/python项目/Symbolic/Net/Five/protein_interaction.csv')
G = nx.from_pandas_edgelist(df,'source','target',create_using = nx.Graph())
print(len(G.nodes),len(G.edges()))
#删除自环
self_edgs = []
for e in G.edges():
if e[0] == e[1]:
self_edgs.append(e)
G.remove_edges_from(self_edgs)
Gcc = sorted(nx.connected_components(G),key = len,reverse = True)
#得到图G的最大连通组件
LCC = G.subgraph(Gcc[0])
#获得原始网络的最大连通子图节点数和连边数
N,M = len(LCC.nodes),len(LCC.edges)
print(N,M)
print(nx.average_clustering(LCC))
print(nx.degree(LCC))
#生成度保持的随机化网络
newG = LCC.copy()
G_d = nx.double_edge_swap(newG, nswap=M, max_tries=5 * M)
print(nx.average_clustering(G_d))
print(nx.degree(G_d))
#生成完全随机化的网络
G_r = nx.gnm_random_graph(N,M)
all_sp1, Pl = get_pdf(newG)
all_sp1_d, Pl_d = get_pdf(G_d)
all_sp1_r, Pl_r = get_pdf(G_r)
plt.figure(figsize=(6,6))
plt.plot(all_sp1, Pl, 'ro-', label='original network')
plt.plot(all_sp1_d, Pl_d, 'bs-', label='degree-preserving random network')
plt.plot(all_sp1_r, Pl_r, 'gv-', label='random network')
plt.legend(loc=0)
plt.xlabel("$d$")
plt.ylabel("$p_d$")
plt.xscale("log")
plt.yscale("log")
plt.show()运行结果:
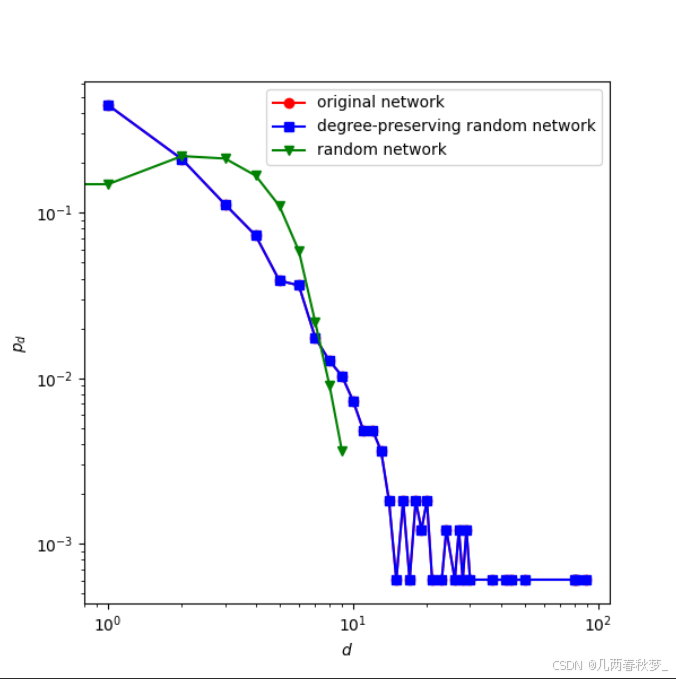
综上所述,随机网络由于缺少枢纽节点而高估了节点间的距离。通过度保持的随机化得到的随机网络保留了枢纽节点,因此其距离和原始网络的距离非常接近。
二、精准地绘制幂律分布以及估计度分布指数
① 线性坐标,线性分箱
② 双对数坐标,线性分箱
③ 双对数坐标,对数分箱
④ 双对数坐标,累积分布
编程实践:
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
import powerlaw
edges = [tuple(line) for line in np.loadtxt("D:/python项目/Symbolic/Net/Five/internet.txt")]
G1 = nx.Graph()
G1.add_edges_from(edges)
degree_seq1 = [G1.degree(i) for i in G1.nodes()]
print(len(G1.nodes()),len(G1.edges()))
#对数坐标,线性分箱
powerlaw.plot_pdf(degree_seq1,linear_bins=True,color = 'r',marker = 'o')
plt.show()
#对数坐标,对数分箱
powerlaw.plot_pdf(degree_seq1,linear_bins=False,color = 'b',marker = 's')
plt.show()
#对数坐标,累计度分布
powerlaw.plot_ccdf(degree_seq1,color = 'b',marker = 'o')
plt.show()
#估计度指数
fit = powerlaw.Fit(degree_seq1)
kmin = fit.power_law.xmin
print("kmin:", kmin)
print("gamma:", fit.power_law.alpha)
print("D:", fit.power_law.D)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











