






1. yield()函数
当一个进程使用完时间片后,会中断并调用yield函数来让出CPU给新的进程。 yield函数首先获取进程表锁,并将进程状态设为可运行,以便下次遍历时可以被唤醒。之后执行sched函数,准备将CPU切换到scheduler context。最后释放进程表锁。
// Give up the CPU for one scheduling round.
//放弃CPU进行一轮调度
void
yield(void)
{
acquire(&ptable.lock); //DOC: yieldlock
myproc()->state = RUNNABLE;
sched();//执行sched函数,准备将CPU切换到scheduler context
release(&ptable.lock);
}2. sched()函数
sched()是切换至CPU context,并在切换context之前,进行一系列判断,以避免出现冲突的函数。
切换到scheduler必须:
1.持有p->lock并且已更改proc->state。
2.保存和恢复intena,因为intena是这个内核线程的属性,而不是这个CPU的属性。
它应该是proc->intena和proc->ncli,但这会再持有锁但没有进程的少数地方中断。
// Enter scheduler. Must hold only ptable.lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->ncli, but that would
// break in the few places where a lock is held but
// there's no process.
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&ptable.lock))//是否获取了进程表锁
panic("sched ptable.lock");
if(mycpu()->ncli != 1)//是否执行过pushcli
panic("sched locks");
if(p->state == RUNNING)//执行的程序应该处于结束或睡眠
panic("sched running");
if(readeflags()&FL_IF)//判断中断是否可以关闭
panic("sched interruptible");
intena = mycpu()->intena;//保存intena
swtch(&p->context, mycpu()->scheduler);//上下文切换至scheduler
mycpu()->intena = intena;//恢复intena
}
3.scheduler()函数
scheduler函数是xv6中的核心调度器函数,用于根据选择的调度算法从就绪队列中选择下一个要运行的进程。
当CPU初始化之后,即调用scheduler(),循环从进程队列中选择一个进程执行。
计划程序永远不会返回。它循环执行以下操作:
1.选择要运行的进程。
2.swtch开始运行该进程。
3.最终该进程会转移控制权,通过swtch返回到调度程序。
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run
// - swtch to start running that process
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();//跟踪当前cpu上正在运行的进程
c->proc = 0;//表示当前没有进程再运行
for(;;){
// Enable interrupts on this processor.
//在每次执行一个进程之前。开启CPU中断。通过确保设备可以中断,来避免死锁。
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);//避免其他cpu更改进程表
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
// Switch to chosen process. It is the process's job
// to release ptable.lock and then reacquire it
// before jumping back to us.
c->proc = p;
switchuvm(p);
p->state = RUNNING;
//通过调用swtch函数,将CPU的上下文切换到该进程的上下文
//swtch函数负责保存当前CPU的上下文,并将控制权转移到指定进程的上下文
swtch(&(c->scheduler), p->context);//运行进程
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
//进程目前已完成运行
//再回来之前改变他的p->state
c->proc = 0;
}
release(&ptable.lock);
}
}4.fork()函数
fork()的作用时复制一个进程。
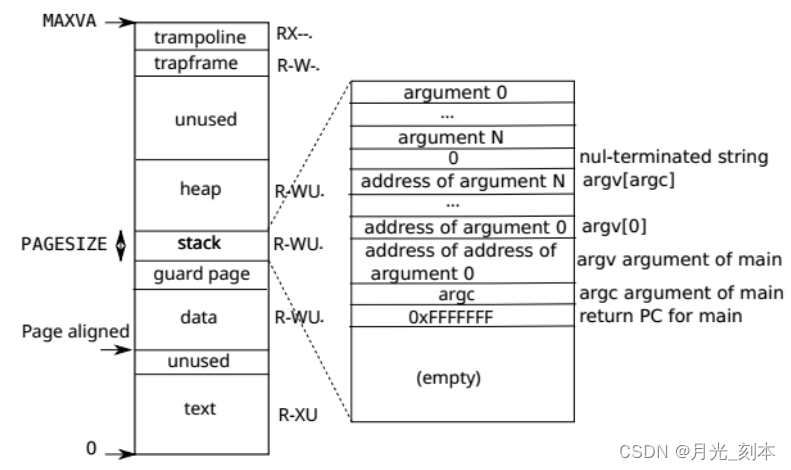
上图代表一个用户地址空间,一个进程就是由上图各部分组成的,包括代码段text,数据段data,堆区heap,栈区stack,trampoline page和trapframe page以及guard page。所以我们就是要原封不动地复制一个这样的用户地址空间。
fork()的返回值有两种情况:父进程返回子进程的pid,子进程返回0。
// Create a new process copying p as the parent.
// Sets up stack to return as if from system call.
// Caller must set state of returned proc to RUNNABLE.
int
fork(void)
{
int i, pid;
struct proc *np;
struct proc *curproc = myproc();
// Allocate process.
//分配一个proc结构体
if((np = allocproc()) == 0){
return -1;
}
// Copy process state from proc.
//复制父进程的页表
if((np->pgdir = copyuvm(curproc->pgdir, curproc->sz)) == 0){
kfree(np->kstack);
np->kstack = 0;
np->state = UNUSED;
return -1;
}
np->sz = curproc->sz;
np->parent = curproc; //成为父子关系
*np->tf = *curproc->tf; //tf的信息也要全部复制,这样才能保证复制后的进程同样正常运行
// Clear %eax so that fork returns 0 in the child.
np->tf->eax = 0; // 这一步是区分父进程与子进程的关键
// 复制已打开的文件
for(i = 0; i < NOFILE; i++)
if(curproc->ofile[i])
np->ofile[i] = filedup(curproc->ofile[i]);
np->cwd = idup(curproc->cwd);
safestrcpy(np->name, curproc->name, sizeof(curproc->name));
pid = np->pid;
acquire(&ptable.lock);
np->state = RUNNABLE;// 子进程可以被调度
release(&ptable.lock);
return pid;//子进程的pid
}
5.exec()函数
int exec(char *file,char **argv):加载一个文件并使用参数执行它;只有在出错时才返回。
它的作用是替换一个进程,通常紧跟在fork()函数后面。需要替换掉text,data,而stack和heap,trampoline page和trapframe page则是重新分配。
exec()分为三部分进行分析:
- text+data替换
- stack分配
- 参数写入
text+data替换:
可执行文件的构成:ELF header,Program header和Segment构成。 通过ELF header得Proram header,再得到对应的Segment(代码段或数据段)。

在得到Program header后,我们首先需要通过uvmalloc()在页表中建立起新的va和pa的映射,然后调用loadseg()把pa对应的内容替换掉,我们text和data的替换就完成了。
stack分配:
在替换掉代码段和数据段之后再新增两页,一页用于guard page,一页用于stack。并且由最后的p->sz = sz可以得到,我们的进程大小=text+data+stack。
stack分配结束后,还剩下相当大一部分区域用于heap。heap并不需要单独为它初始化,它也会通过页表与物理内存映射,但编译器不会为我们像stack一样做类似压栈出栈的处理,相反它选择什么都不做。所以我们在使用时只要是分配了这段内存,就需要即使释放它。
参数写入:
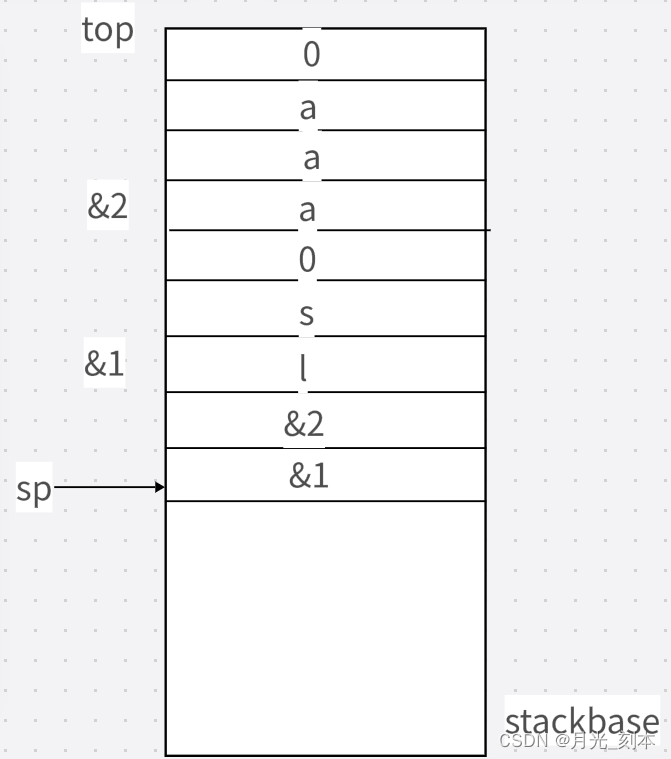
新进程运行时是需要参数的,这就需要把exec()里的参数传递给进程,也就是传递给main()函数。exec()中需要传递给新进程的参数通过保存在新进程堆栈里完成传递。
以exec(“ls”, “aaa”)为例,它在堆栈中的分布如上图所示。在保存完字符串“ls”,“aaa”之后,我们还需要字符串的地址,用于告知字符串的位置,地址会紧跟在字符之后保存。此时sp的位置,就是第一个参数的字符串地址。
int
exec(char *path, char **argv)
{
char *s, *last;
int i, off;
uint argc, sz, sp, ustack[3+MAXARG+1];
struct elfhdr elf;
struct inode *ip;
struct proghdr ph;
pde_t *pgdir, *oldpgdir;
struct proc *curproc = myproc();
begin_op();// FS事务开始
if((ip = namei(path)) == 0){ // 解析出path对应的inode
end_op();
cprintf("exec: fail\n");
return -1;
}
ilock(ip);
pgdir = 0;
/*****text+data替换*****/
// Check ELF header
if(readi(ip, (char*)&elf, 0, sizeof(elf)) != sizeof(elf)) // 校验elf header
goto bad;
if(elf.magic != ELF_MAGIC)
goto bad;
if((pgdir = setupkvm()) == 0)// 获得页表
goto bad;
// Load program into memory.
sz = 0;
for(i=0, off=elf.phoff; i<elf.phnum; i++, off+=sizeof(ph)){
if(readi(ip, (char*)&ph, off, sizeof(ph)) != sizeof(ph))// 读取program header
goto bad;
if(ph.type != ELF_PROG_LOAD)
continue;
if(ph.memsz < ph.filesz)
goto bad;
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad;
if((sz = allocuvm(pgdir, sz, ph.vaddr + ph.memsz)) == 0)// 建立pa与va的映射
goto bad;
if(ph.vaddr % PGSIZE != 0)
goto bad;
if(loaduvm(pgdir, (char*)ph.vaddr, ip, ph.off, ph.filesz) < 0)
// 完成pa内容的填充(即把可执行文件指向pa)
goto bad;
}
iunlockput(ip);
end_op();// FS事务结束
ip = 0;
/*****stack分配*****/
// Allocate two pages at the next page boundary.
// Make the first inaccessible. Use the second as the user stack.
// 再增加两页作为用户栈和guard page
sz = PGROUNDUP(sz);
if((sz = allocuvm(pgdir, sz, sz + 2*PGSIZE)) == 0)
// 再分配两页,一页stack,一页guard page
goto bad;
clearpteu(pgdir, (char*)(sz - 2*PGSIZE)); // 用作guard page
sp = sz;
// 参数传入
// Push argument strings, prepare rest of stack in ustack.
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad;
sp = (sp - (strlen(argv[argc]) + 1)) & ~3;
if(copyout(pgdir, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad;
ustack[3+argc] = sp;
}
ustack[3+argc] = 0;
ustack[0] = 0xffffffff; // fake return PC
ustack[1] = argc;
ustack[2] = sp - (argc+1)*4; // argv pointer
// push the array of argv[] pointers.
sp -= (3+argc+1) * 4;
if(copyout(pgdir, sp, ustack, (3+argc+1)*4) < 0)
goto bad;
// Save program name for debugging.
for(last=s=path; *s; s++)
if(*s == '/')
last = s+1;
safestrcpy(curproc->name, last, sizeof(curproc->name));
// Commit to the user image.
oldpgdir = curproc->pgdir;
curproc->pgdir = pgdir;// 替换新页表
curproc->sz = sz;// p->sz代表从text到stack的大小(sz最后幅值的地方在stack分配处)
curproc->tf->eip = elf.entry; //initial program counter = main
curproc->tf->esp = sp;// initial stack pointer
switchuvm(curproc);
freevm(oldpgdir);//释放旧页表
return 0;
bad:
if(pgdir)
freevm(pgdir);
if(ip){
iunlockput(ip);
end_op();
}
return -1;
}
6.exit()函数
void exit(int status):终止当前进程,并将状态报告给wait()函数。无返回。
当一个进程退出时,需要让init进程收养自己的子进程
// Exit the current process. Does not return.
// An exited process remains in the zombie state
// until its parent calls wait() to find out it exited.
// 一个子进程退出之后会变为僵尸进程, 直到父进程调用wait()将其回收
// exit()并没有释放子进程的所有资源,因为其正在运行当中,如果贸然释放
// 会产生很多问题, 因为等子进程退出之后,再由父进程的wait()来释放子进程的资源
void
exit(void)
{
struct proc *curproc = myproc();
struct proc *p;
int fd;
if(curproc == initproc)
panic("init exiting");
// Close all open files.
// 1.关闭所有的打开文件
for(fd = 0; fd < NOFILE; fd++){
if(curproc->ofile[fd]){
fileclose(curproc->ofile[fd]);
curproc->ofile[fd] = 0;
}
}
// 进程对与当前目录的一个引用,需要将其释放给文件系统
// 因为文件系统中使用了引用计数
begin_op();
iput(curproc->cwd);
end_op();
curproc->cwd = 0;
acquire(&ptable.lock);
// Parent might be sleeping in wait().
// 唤醒父进程
wakeup1(curproc->parent);
// Pass abandoned children to init.
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->parent == curproc){
// Give any children to init.
// 让init进程收养当前进程的子进程
p->parent = initproc;
if(p->state == ZOMBIE)
wakeup1(initproc);
}
}
// Jump into the scheduler, never to return.
curproc->state = ZOMBIE;
// 此时进程的资源还没有完全释放,进入到调度器线程
sched();
// 由于进程的state为ZOMBIE, 因此其不会被调度
panic("zombie exit");
}7.wait()函数
int wait(int *status):等待一个子进程退出;将退出状态存入*status;返回子进程PID
当一个子进程终止时,如果其父进程还未终止,那么其会将自己的state设置为ZOMBIE,然后wakeup()正处于wait()状态的父进程,父进程遍历进程表,找到state为ZOMBIE的子进程,然后释放其资源
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
int
wait(void)
{
struct proc *p;
int havekids, pid;
struct proc *curproc = myproc();
//获取lock避免丢失唤醒
acquire(&ptable.lock);
for(;;){
// Scan through table looking for exited children.
havekids = 0;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
// 这里没有使用p->lock因为在扫描进程表过程中
// 可能会扫描到curproc的祖先(ap),如果ap也正在使用wait, 那么它就会持有ap->lock
// 此时就会发生deadlock
if(p->parent != curproc)
continue;
havekids = 1;
// 检查处于ZOMBIE状态的子进程,将其回收
if(p->state == ZOMBIE){
// Found one.
pid = p->pid;
kfree(p->kstack);
p->kstack = 0;
freevm(p->pgdir);
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->killed = 0;
p->state = UNUSED;
release(&ptable.lock);
return pid;
}
}
// No point waiting if we don't have any children.
if(!havekids || curproc->killed){
release(&ptable.lock);
return -1;
}
// Wait for children to exit. (See wakeup1 call in proc_exit.)
// 子进程还未退出, sleep等待
// sleep在自己身上, 即curproc->chan = curproc
sleep(curproc, &ptable.lock); //DOC: wait-sleep
}
}8.kill()函数
int kill(int pid):终止对应PID进程,返回0,或返回-1表示错误。
kill并没有直接杀死进程,因为当对一个进程执行kill操作的时候,进程可能正在更新某些数据,也可能正在创建一个文件,它们还可能持有锁,因此,直接杀死进程会导致一系列问题。
仅仅是将进程的killed标志位置为了1,但是对于处于SLEEPING状态的进程有着特殊处理。
通过将进程的killed标志位置为1, 然后在一些安全的地方对killed标志位进行检查,这样可以确保进程安全的退出。
通常,当kill()“杀死”进程后,该进程通常不会立即死亡,而是会在下一次的某个系统调用/计时器中断/设备中断时自愿的调用exit()退出
// Kill the process with the given pid.
// Process won't exit until it returns
// to user space (see trap in trap.c).
int
kill(int pid)
{
struct proc *p;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->pid == pid){
// 这里基本上没有干什么事情
p->killed = 1;
// Wake process from sleep if necessary.
if(p->state == SLEEPING)
p->state = RUNNABLE;
release(&ptable.lock);
return 0;
}
}
release(&ptable.lock);
return -1;
}例如:
//如果进程发现killed标志位为1,会自愿调用exit()退出
// 在这里,进程并没有持有任何的锁
if(p->killed)
exit(-1);9.allocproc()函数
初始化了proc结构体,其中p->context->eip = (uint)forkret;就指定了第一次被调度的入口函数。原因是从调度器的视角来看,在需要调度一个新进程时,它会执行swtch(&c->scheduler, &p->context),其中&p->context当作参数传入,eip就是返回的函数地址。
// Look in the process table for an UNUSED proc.
// If found, change state to EMBRYO and initialize
// state required to run in the kernel.
// Otherwise return 0.
// 遍历然后分配一个UNUSED proc,并对结构体成员初始化
static struct proc*
allocproc(void)
{
struct proc *p;
char *sp;
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == UNUSED)
goto found;
release(&ptable.lock);
return 0;
// 对刚分配的UNUSED proc进行初始化
found:
p->state = EMBRYO;
p->pid = nextpid++;// 分配pid
release(&ptable.lock);
// Allocate kernel stack.
// 为trapframe分配物理空间
if((p->kstack = kalloc()) == 0){
p->state = UNUSED;
return 0;
}
sp = p->kstack + KSTACKSIZE;
// Leave room for trap frame.
sp -= sizeof *p->tf;
p->tf = (struct trapframe*)sp;
// Set up new context to start executing at forkret,
// which returns to trapret.
sp -= 4;
*(uint*)sp = (uint)trapret;
sp -= sizeof *p->context;
p->context = (struct context*)sp;
memset(p->context, 0, sizeof *p->context);
p->context->eip = (uint)forkret;
return p;
}10.forkret()函数
forkret()首先会释放进程锁,然后判断first变量(用于init进程)。
// A fork child's very first scheduling by scheduler()
// will swtch here. "Return" to user space.
void
forkret(void)
{
static int first = 1;
// Still holding ptable.lock from scheduler.
release(&ptable.lock);
if (first) {
// init进程创建时才会进入此处
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
// 放在context处:1.会调用sleep,而sleep只有在进程创建时才能使用(p->state=sleep)
// 2.新进程会从文件系统中读可执行文件,需要提前初始化好
first = 0;
iinit(ROOTDEV);
initlog(ROOTDEV);
}
// Return to "caller", actually trapret (see allocproc).
}
















 2122
2122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









