







目录
对于有限自动机,目标是使得从一组正规式导出可执行词法分析器的过程自动化。这一节,将开发一些构造法,以便将RE转换为适合于实现的FA,还将设计一种算法,从FA接受的语言推导出对应的RE。
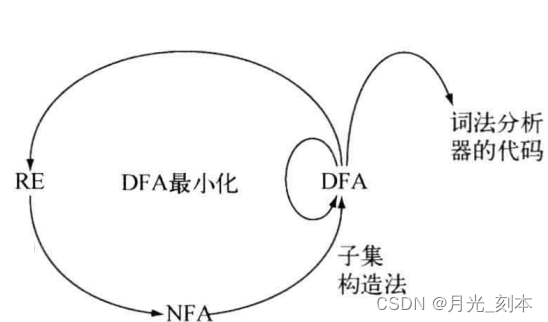
要解释这些构造法,我们需要先了解NFA和DFA。
3.1 NFA和DFA
对于RE的定义,规定为RE,但是我们之前手工构建的FA都不包含
,但一些RE确实用到了
。
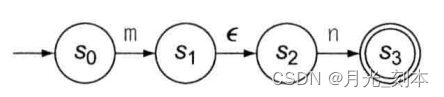
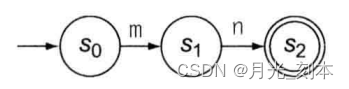
FA在S1->S2的转移不会消耗任何字符,目测我们可以合并这两个状态,形成下图:
举例:对于a*和ab的FA
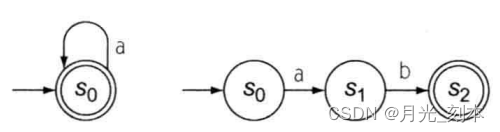
可以用一个转移合并它们,形成一个处理a*ab的FA
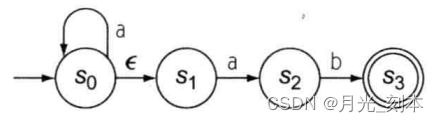
的引入使得S0在遇到字母a时可以有两种转移:1)转移到S0 2)转移到S2。
识别ab和aab的转移是不同的。采取哪一种转移取决于a后面的那个字符。对于包含S0这种状态的FA称为NFA。
NFA:非确定有限自动机:对单个输入字符有多种可能的转移;弧上的标记可以是中的一个字,而不一定是单个字符;初态不唯一,终态集可空。
DFA:确定有限自动机:每个状态对任一输入字符都具有唯一可能的转移;初态唯一,终态集合可空。
注:NFA和DFA在表达力上是等价的,任何DFA都是某个NFA的一个特例。
3.2 正规式与NFA
3.21 正规式->NFA
对于上的正规式,我们将构造一个NFA M,使L(M)=L(r),并且M只有一个终态,而且没有从该终态出发的箭弧。
1)转换模板
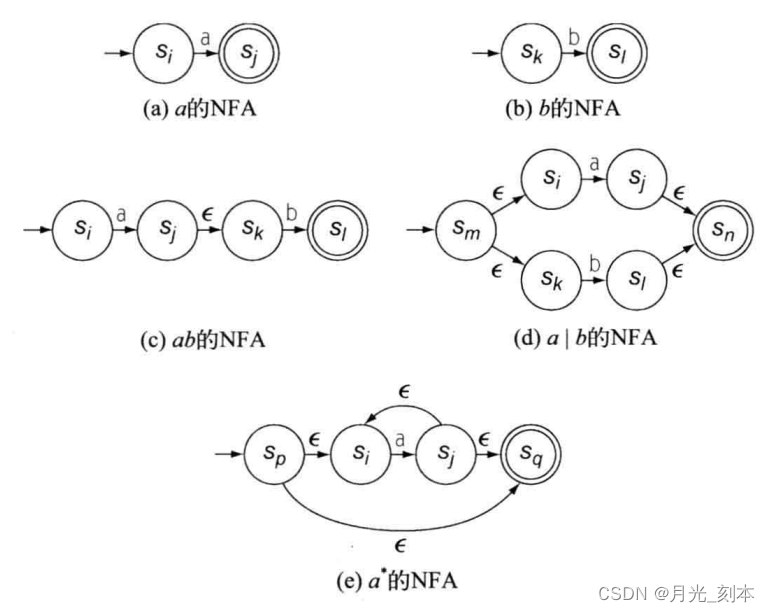
2)引入两个新的状态:初态和终态
3)若RE中没有运算符,转换图3.11

4)举例:a(b|c)*
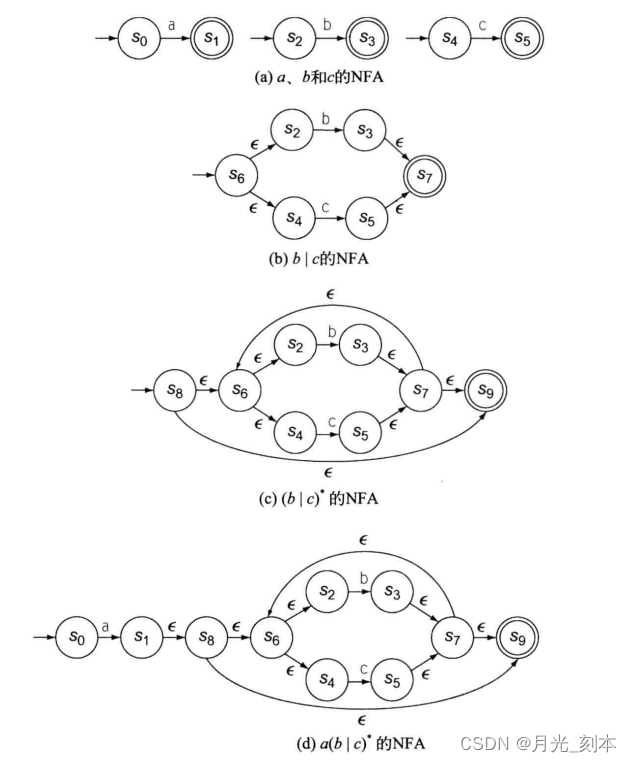
手工生成的NFA如下图,与上述NFA相比简洁很多,后续会对上述NFA进行简化。
正规式->NFA构造的特性:
(1)每个NFA都有一个起始状态和接受状态。
(2)除了进入起始状态的初始转移之外,没有其他转移;没有从接受状态发出的转移。
(3)在连接早先构建的对应于一些组件RE的NFA时,总是使用转移来连接前一个NFA的接受状态和后一个NFA的起始状态。
(4)每个状态至多有两个进入该状态和两个退出该状态的转移,对于字母表中的每个符号,至多有一个进入该状态和一个退出该状态的转移。
3.22 NFA->正规式
对于上的NFA M,我们来构造
上的正规式r,使L(r)=L(M)
(1)转换模板
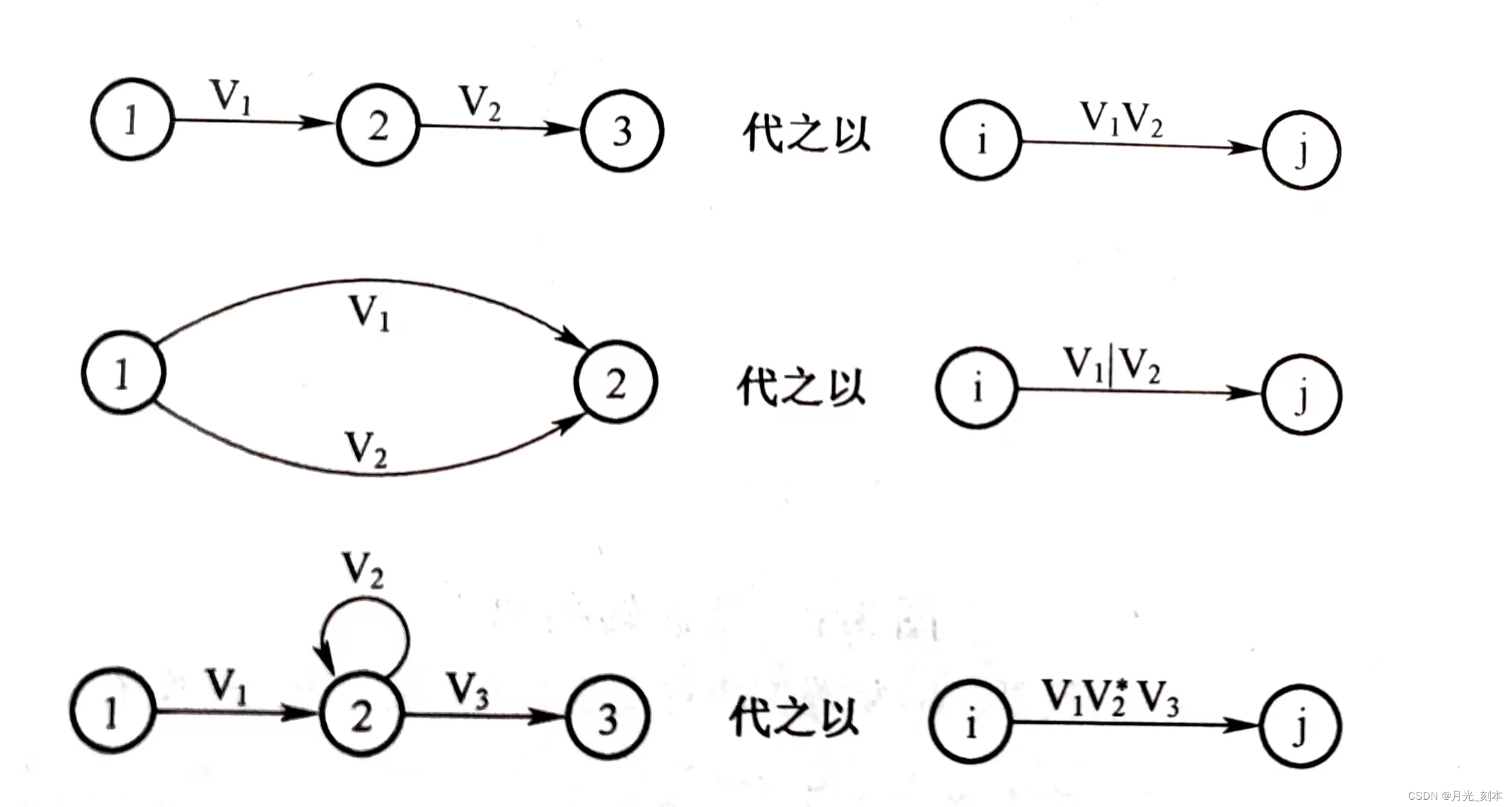
(2)在M的转换图上加入两个状态,初态X,终态Y。从X用弧连接到M的所有初态;从M的所有终态结点用
弧连接到Y,从而形成一个新的NFA,记为M‘
(3)反复利用(1)的转换规则,逐步消去M’中的所有结点,直至只剩下X和Y为止。
3.3 NFA->DFA:子集法
识别RE定义的语言,与NFA的执行相比,DFA的执行要容易模拟的多,所以在构造法的循环中,下一步是将NFA转换为可以识别同一语言的DFA。
NFA和DFA使用同样的字母表,DFA的起始状态和接受状态集是通过构造逐渐得到的,比较复杂的是从NFA的状态集推导DFA的状态集,以及DFA的转移函数的推导。
3.31 步骤
(1)转换模板
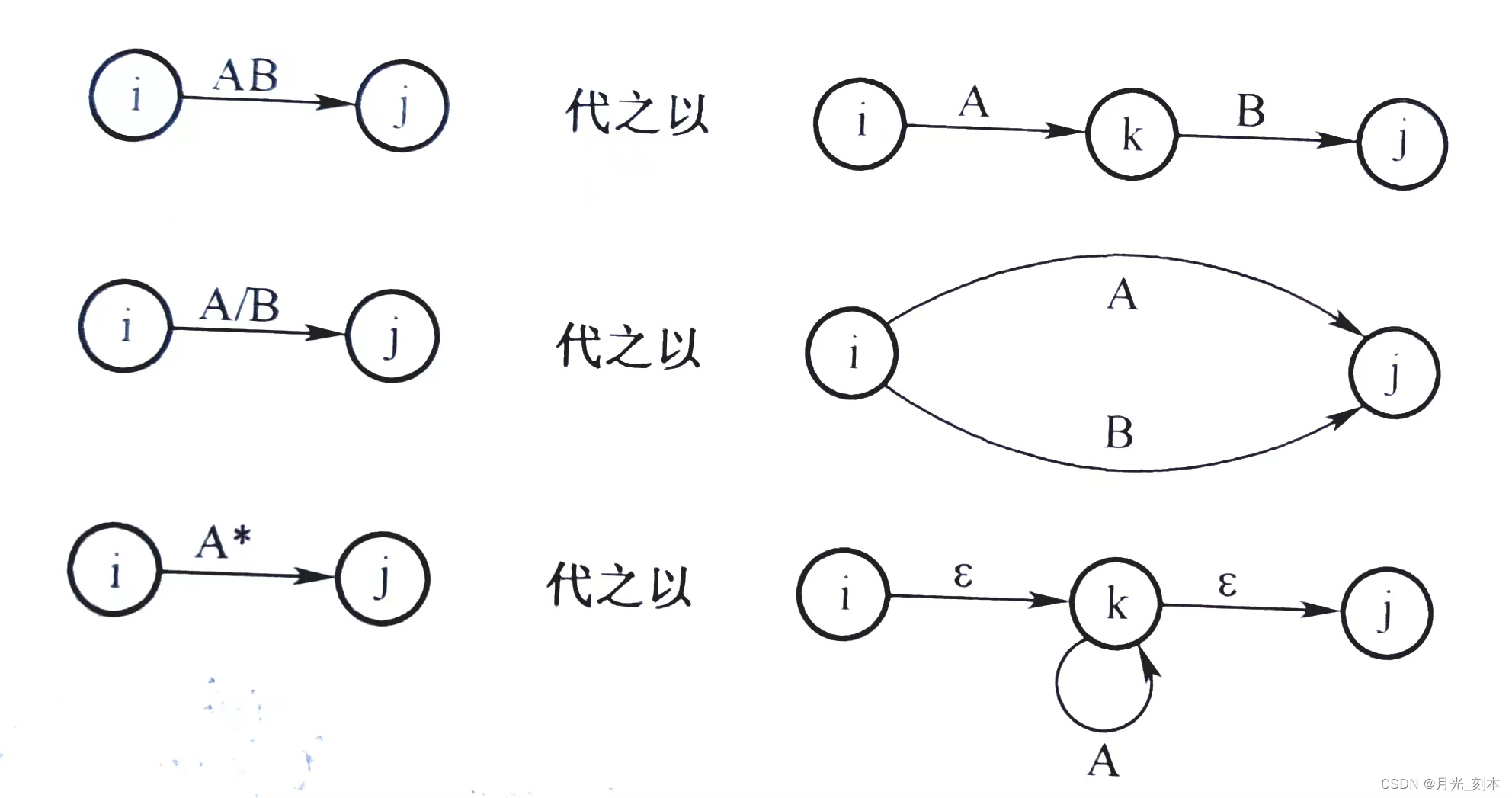
(2)引入新的初态结点X和终态结点Y;从X到So(NFA的初态集)中任意结点连一条箭弧,从F(NFA的终态集)中任意结点连一条
箭弧到Y,然后重复(1)的分裂过程,直到状态转换图的每条箭弧上的标记为
或
中的单个字母。将得到的NFA记为M‘。
(3)构造闭包
>定义状态集I的闭包:_CLOSURE(I)=I U J。(J:I中节点经过任意
到达的结点的集合)
>I的字符a可达的状态集:Ia=_CLOSURE(J)。(J:I中节点经过一条a弧到达的结点的集合)
>重构状态转移图
①该算法从一个初始集合I0开始,其中包含了X(M‘的初始状态),以及在M’中X通过仅包含转移(一条或多条连续仅包含
的弧)的路径所能到达的所有状态。
②计算经过字符可达的状态集:假设字符a,接下来计算Ia,其中包含初态集合I0中每一个元素经过一条a弧能直接到达的状态,接下来求目前Ia中所有元素的闭包,即其中元素经过仅包含转移(一条或多条连续仅包含
的弧)的路径所能到达的所有状态,将这些状态也加入到Ia中,到此Ia结束。计算I0的其他字符到达集。
③接下来依次计算已经得到的到达集的字符到达集。一直重复③直到没有新的到达集出现。
3.32 举例
(1)引入X和Y状态,并进行分裂后的结果如下:
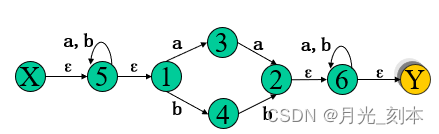
(2)子集构造法
初始集合I0:包含X和X的闭包,{X,5,1}
Ia:{5,3}(I0中的每个元素经过一条a弧能直接到达的状态) U {1}(已得到的Ia{5,3}中每个元素求闭包,在此只有5有闭包)= {5,3,1}
| I | Ia | Ib |
| {X,5,1} | {5,3,1} | {5,4,1} |
| {5,3,1} | {5,3,1,2,6,Y} | {5,4,1} |
| {5,4,1} | {5,3,1} | {5,4,1,2,6,Y} |
| {5,3,1,2,6,Y} | {5,3,1,2,6,Y} | {5,4,1, 6,Y} |
| {5,4,1,2,6,Y} | {5,3,1,6,Y} | {5,4,1,2,6,Y} |
| {5,4,1,6,Y} | {5,3,1,6,Y} | {5,4,1,2,6,Y} |
| {5,3,1,6,Y} | {5,3,1,2,6,Y} | {5,4,1, 6,Y} |
最终得到的结果如上图。
(3)对每个状态重新命名,注意得到的DFA的终态为得到的状态集中包含Y的所有状态集。在此,终态集包含S3,S4,S5,S6
| S | a | b |
| 0 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | 1 | 4 |
| 3 | 3 | 5 |
| 4 | 6 | 4 |
| 5 | 6 | 4 |
| 6 | 3 | 5 |
重新画状态转移图,S3,S4,S5,S6为终态
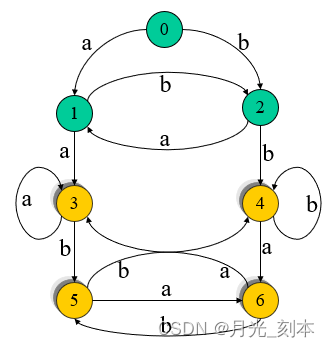
3.4 DFA最小化
从子集构造法产生的DFA可能有大量状态,虽然这不会增加扫描字符串所需的时间,但确实会增加识别器在内存中占用的空间。在现代计算机上,内存访问的速度通常决定了计算的速度。更小的识别器更适合载入到处理器的高速缓存。
状态等价:二者对于任何输入字符串都产生同样的行为。如果不是这样(到达的状态不在一个集合或一个没有发生转移),将围绕输入的该字符来拆分。
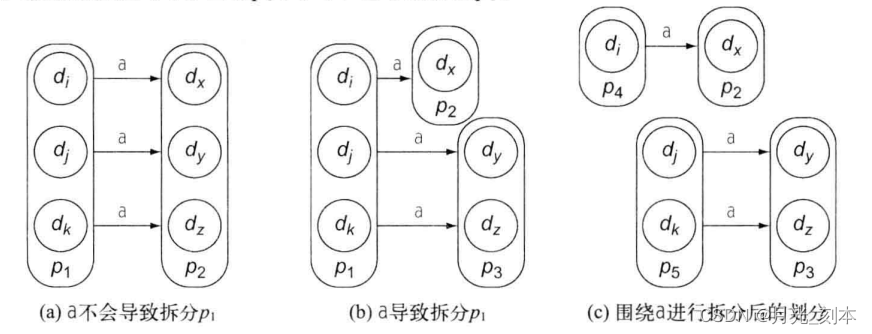
围绕a拆分一个划分p1
3.41 步骤
(1)初始划分为2个集合:终态和非终态;这种分割确保了在最终划分中不会有集合同时包含接受和非接受状态。
(2)在得到的集合中进一步划分,重复执行,直到没有新的划分出现。
(3)对于每一个划分的子集,选择子集中的一个状态来代表该状态,得到化简的DFA
(4)含有原初态的成为新初态,含有原终态的成为新终态。
3.42 举例
将图中的DFA M最小化
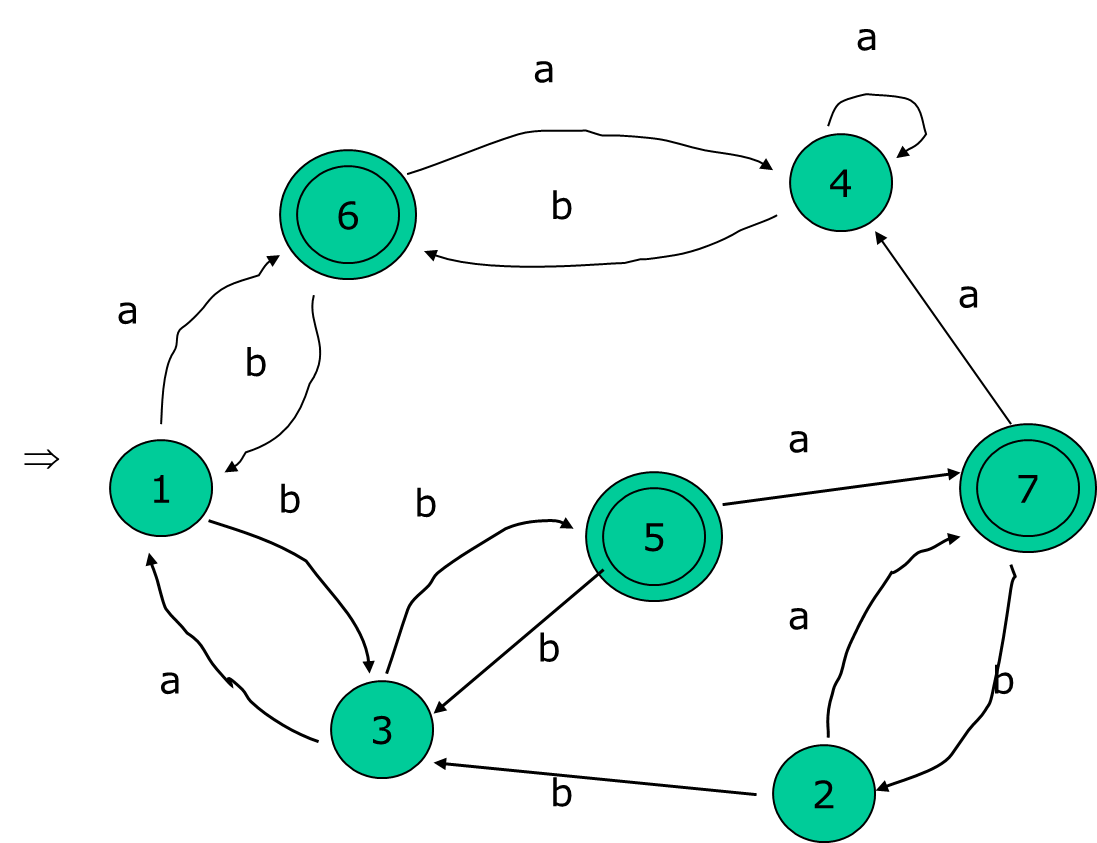
①将M分成两个子集:一个终态(可接受态)组成,一个非终态组成。
P0=({1,2,3,4},{5,6,7})
②子集{1,2,3,4}:{1,2}a={6,7}{5,6,7},
{3,4}a={1,4}{1,2,3,4}
{1,2}中的状态和{3,4}中的状态在读入a后到达了不等价的状态。
P1=({1,2},{3,4},{5,6,7})
③子集: {1,2}a={6,7}{5,6,7},{1,2}b={3}
{3,4},不用再划分
子集{3,4}:{3}a={1}{1,2},
{4}a={4}{3,4}
再分割为:P2=({1,2},{3},{4},{5,6,7})
④子集{5,6,7}:{6,7}a={4}{4}
{5}a={7}{5,6,7}
分割为:P3=({1,2},{3},{4},{5},{6,7})
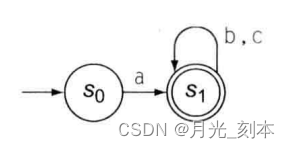
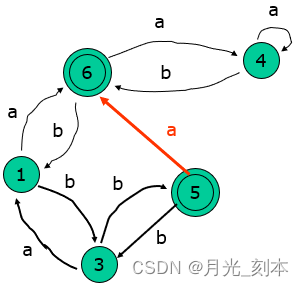
⑤不能再分割,令状态1代表{1,2},状态6代表{6,7},得到的DFA如下图。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









