



论文:XFeat: Accelerated Features for Lightweight Image Matching
代码:https://github.com/verlab/accelerated_features.git
用途:专门用于资源受限的设备中,适合视觉导航和增强现实等下游任务。Xfeat是通用且独立于硬件,在姿态估计和视觉定位中比24年之前的局部特征检蛮不错现在测更快,且精度更好或者相当。
值得学习的话术:Since image feature extraction is critical for a myriad of tasks [1, 25, 27, 29, 35, 38, 44], efficient solutions are highly desirable, especially on resource-constrained platforms such as mobile robots, augmented reality, and portable devices, where scarce computational resources are often allocated to multiple tasks simultaneously. Although specific works aim to perform hardware-level optimization for existing architectures [13 Zippypoint], which is still hardwarespecific and cumbersome in practice, few works focus on the architectural design for efficient feature extraction [46ALIKE]
keypoint-based methods are more suitable to efficient visual localization based on Structure-from-Motion (SfM) maps [From Coarse to Fine: Robust Hierarchical Localization at Large Scale], while dense feature matching can be more effective for relative camera pose estimation in poorly textured scenes [LOFTER].
作者在论文中指出:
1.Xfeat可以取代传统的ORB,昂贵的深度学习模型SuperPoint、DISK和轻量化的AKILE模型。
2.Xfeat在视觉定位、摄像机姿态估计和单应性配准方面是有效的。
方法论
轻量化的主干网络
1.传统的MobileNets和Shufflenet的轻量化原则是:“浅层高分辨率低通道,深层低分辨率高通道”,以空间换通道,优化FLOPs
2.与以往的对网络进行轻量化的操作不同,作者提出了一种创新点额CNN通道分配策略,在千层减少通道数,在深层三倍增长通道数,实现了计算效率和模型精度的平衡。
具体而言:早期图像分辨率为(H*W),少量通道便可以捕获基础特征,此时通道数为4.随着网络层数的增加,三倍数着呢宫颈癌通道,而分辨率减半(通过步长为2的卷积操作来实现),深层比较多的通道数可以维持较好的特征表达能力,抵消层参数减少的影响。
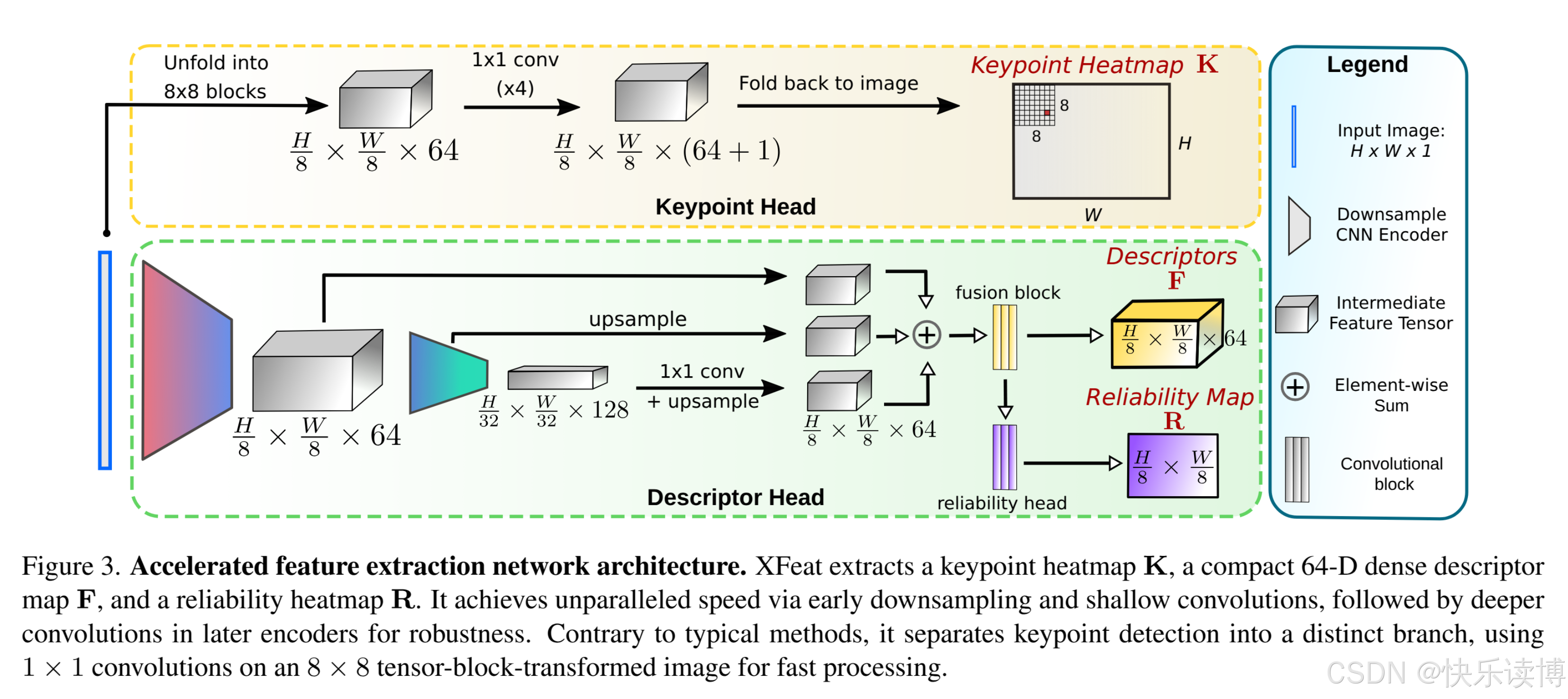
局部特征提取
描述符头
描述符主要是通过编码器的多尺度特征融合得到的,这里采用了特征金字塔策略【Feature Pyramid Networks for Object Detection】和上采样求和,从编码器中提取密集特征形成描述符。多尺度特征有利于低成本扩大感受野,同时保留多尺度信息,使得描述子在一定程度上面具备尺度不变性。
关键点头
本文采用和SuperPoint一样的特征点提取策略,但是有一个不同在于:SUperPoint是对于关键点和描述符共享主干,联合训练,而本文是新增一个独立的关键点检测的并行分支,轻量化的卷积,网格化处理,实时的同时,保证高精度。具体来讲,将输入图像划分为8*8的网格,每个网格64维度特征,代表每个像素都可能是一个关键点位置,新增一个垃圾箱纬度,所以最后通过1*1的卷积进行快速分类回归,输出65维的关键点分布。推理过程中,将垃圾过滤生成8*8的热力图,非极大值抑制提取最终关键点。(需要注意:低层特征更适合提取关键点,因为边缘角点在浅层更加丰富,而高层特征更适合提取语义信息,因为语义信息在深层。)
密集匹配
本文提出来一种轻量化的密集匹配架构,通过缓存前面进行描述符和关键点训练回归的置信度热力图,来挑选TOP-K个图像区域进行密集特征匹配,并设计了一种多层感知机进行从粗到细的匹配。他不像SiLK和LoFTR依赖于高分辨率的原图,所以计算更加高效,符合资源受限的场景。
网络训练
注意关键点训练,它是使用ALIKE提供的去噪后的关键点分布,比直接使用标注更鲁邦,轻量化学生网络继承教师对底层特征的敏感性,但计算量更低。其他网络训练,我不是太关注,所以不讲。
网络推理
两个类型:稀疏关键点检测用Xfeat。半稠密检测用Xfeat*。
实验结果
作者在姿态估计、单应性矩阵估计和视觉定位方面表现出了强大的竞争力。主要是速度很快。
代码复现:https://github.com/verlab/accelerated_features.git
1.进行复现之前,先点进去看看别人提的问题,自己是否有相同的疑问,避免踩坑。
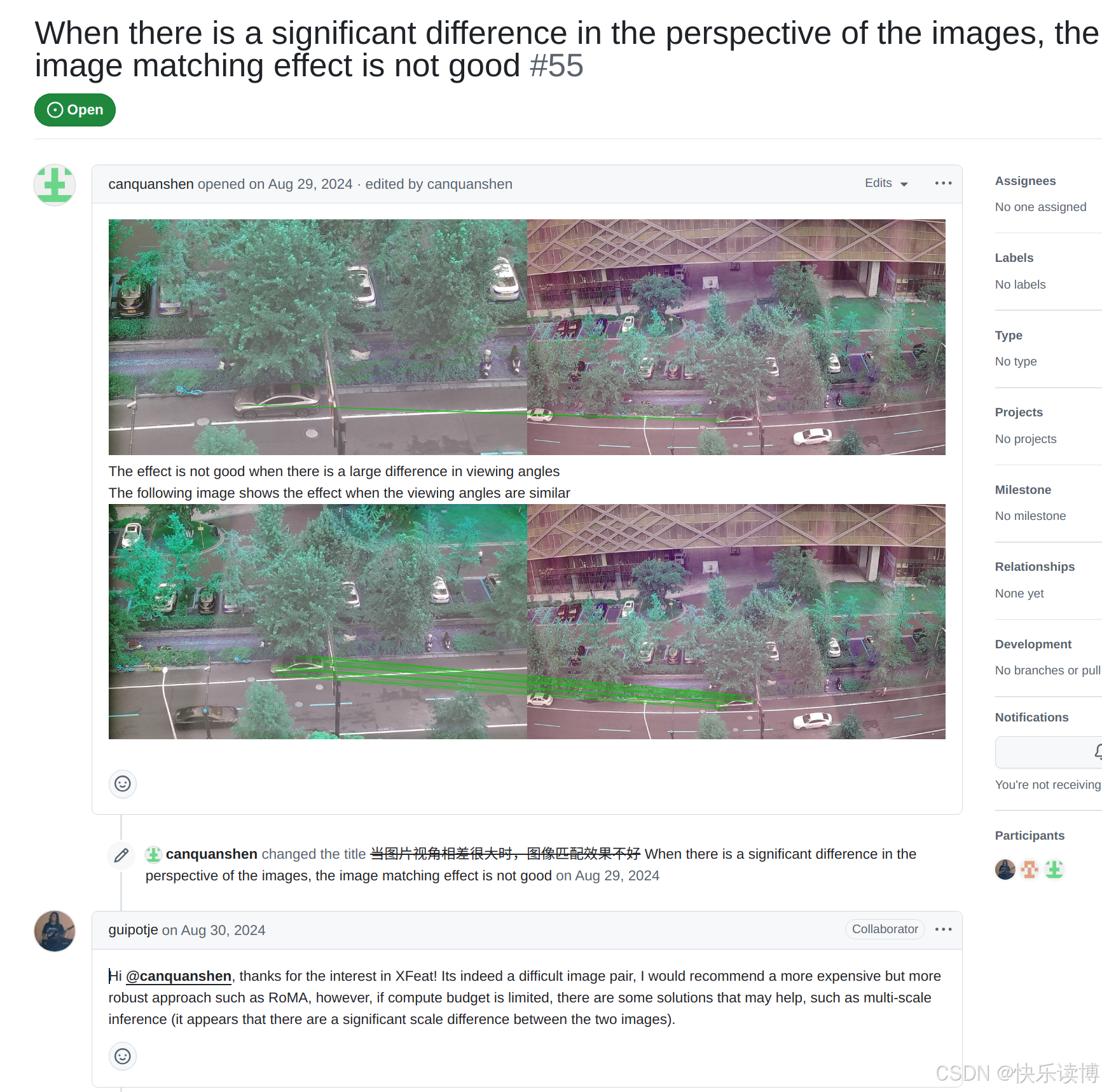
2.值得注意:有人提到两幅图像透视差异巨大时,匹配效果不好,作者推荐了RoMA方法!
我查了一下“RoMa: Robust Dense Feature Matching”,代码在这里:https://github.com/Parskatt/RoMa.git
3.开始进行推理的复现,因为只是需要关键点检测。
打开终端:
1.克隆代码到本地
(base) liutao@liutao-MS-7E07:/media/liutao/文档/CVPR$ git clone https://github.com/verlab/accelerated_features.git
正克隆到 'accelerated_features'...
remote: Enumerating objects: 167, done.
remote: Counting objects: 100% (99/99), done.
remote: Compressing objects: 100% (67/67), done.
remote: Total 167 (delta 70), reused 32 (delta 32), pack-reused 68 (from 1)
接收对象中: 100% (167/167), 20.10 MiB | 1.31 MiB/s, 完成.
处理 delta 中: 100% (78/78), 完成.2.进入代码目录
(base) liutao@liutao-MS-7E07:/media/liutao/文档/CVPR$ cd accelerated_features3.用conda创建虚拟环境
(base) liutao@liutao-MS-7E07:/media/liutao/文档/CVPR/accelerated_features$ conda create -n xfeat python==3.8
Retrieving notices: ...working... done
Channels:
- defaults
Platform: linux-64
Collecting package metadata (repodata.json): done
Solving environment: done## Package Plan ##
environment location: /home/liutao/.conda/envs/xfeat
added / updated specs:
- python==3.8
The following NEW packages will be INSTALLED:_libgcc_mutex pkgs/main/linux-64::_libgcc_mutex-0.1-main
_openmp_mutex pkgs/main/linux-64::_openmp_mutex-5.1-1_gnu
ca-certificates pkgs/main/linux-64::ca-certificates-2025.2.25-h06a4308_0
libedit pkgs/main/linux-64::libedit-3.1.20230828-h5eee18b_0
libffi pkgs/main/linux-64::libffi-3.2.1-hf484d3e_1007
libgcc-ng pkgs/main/linux-64::libgcc-ng-11.2.0-h1234567_1
libgomp pkgs/main/linux-64::libgomp-11.2.0-h1234567_1
libstdcxx-ng pkgs/main/linux-64::libstdcxx-ng-11.2.0-h1234567_1
ncurses pkgs/main/linux-64::ncurses-6.4-h6a678d5_0
openssl pkgs/main/linux-64::openssl-1.1.1w-h7f8727e_0
pip pkgs/main/linux-64::pip-24.2-py38h06a4308_0
python pkgs/main/linux-64::python-3.8.0-h0371630_2
readline pkgs/main/linux-64::readline-7.0-h7b6447c_5
setuptools pkgs/main/linux-64::setuptools-75.1.0-py38h06a4308_0
sqlite pkgs/main/linux-64::sqlite-3.33.0-h62c20be_0
tk pkgs/main/linux-64::tk-8.6.14-h39e8969_0
wheel pkgs/main/linux-64::wheel-0.44.0-py38h06a4308_0
xz pkgs/main/linux-64::xz-5.6.4-h5eee18b_1
zlib pkgs/main/linux-64::zlib-1.2.13-h5eee18b_1
Proceed ([y]/n)? y
Downloading and Extracting Packages:Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate xfeat
#
# To deactivate an active environment, use
#
# $ conda deactivate4.激活虚拟环境
liutao@liutao-MS-7E07:/media/liutao/文档/CVPR/accelerated_features$ conda activate xfeat
5.安装需要的依赖,首先装torch
(xfeat) liutao@liutao-MS-7E07:~$ pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu1246.
调用方式很简单(打开pycharm和项目工程,直接运行下面的就可以看到检测到的关键点了,训练与我无关,这里不进行复现,确实跑的速度挺快的)
import os import torch from modules.xfeat import XFeat import cv2 import matplotlib.pyplot as plt # 用于显示结果 os.environ['CUDA_VISIBLE_DEVICES'] = '' #Force CPU, comment for GPU xfeat = XFeat() #Random input img_path = '/media/liutao/文档/CVPR/accelerated_features/assets/tgt.png' img = cv2.imread(img_path) img = cv2.resize(img, (640, 480)) img_tensor = torch.from_numpy(img).float() x = img_tensor.permute(2,0,1).unsqueeze(0) output = xfeat.detectAndCompute(x, top_k = 4096)[0] print("----------------") print("keypoints: ", output['keypoints'].shape) print("descriptors: ", output['descriptors'].shape) print("scores: ", output['scores'].shape) print("----------------\n") # 可视化关键点 ----------------------------------- def plot_keypoints(img, kpts, scores=None, color=(0, 255, 0), radius=3): """ 在图像上绘制关键点 参数: img: RGB格式的numpy数组 (H,W,3) kpts: 关键点坐标 (N,2) 格式为[x,y] scores: 关键点得分 (N,) color: 绘制颜色 (R,G,B) radius: 关键点半径 """ img_draw = img.copy() kpts = kpts.cpu().numpy() if torch.is_tensor(kpts) else kpts for i, (x, y) in enumerate(kpts): # 根据得分调整颜色/大小(如果有得分) if scores is not None: score = scores[i].item() if torch.is_tensor(scores[i]) else scores[i] thickness = int(score * 5) # 得分越高点越大 cv2.circle(img_draw, (int(x), int(y)), max(1, thickness), color, -1) else: cv2.circle(img_draw, (int(x), int(y)), radius, color, -1) return img_draw # 绘制关键点(绿色圆圈) img_with_kpts = plot_keypoints(img, output['keypoints'], output['scores']) # 显示结果 plt.figure(figsize=(12, 8)) plt.imshow(img_with_kpts) plt.title(f"Detected {len(output['keypoints'])} Keypoints") plt.axis('off') plt.show()

















 1575
1575



 到【灌水乐园】发言
到【灌水乐园】发言








