







从表征角度的详细解读Qwen-VL系列模型发展历程:
Qwen-VL(通义千问视觉语言模型)是阿里巴巴团队开发的多模态大模型系列,其核心目标是通过优化视觉-语言表征对齐,提升复杂多模态任务的性能。以下是各版本在表征思想上的演进路径:
1. Qwen-VL 1.0:基础视觉-语言对齐
表征思想:
-
目标:解决传统模型对中文场景支持不足的问题,同时提升视觉特征提取的细粒度。
-
方法:
-
视觉编码器:采用ViT-bigG编码器,针对中文图像内容优化,并支持了更高分辨率的图像输入(如448×448)。
-
连接器设计:引入跨模态适配器(Cross-Modal Adapter),使用单层交叉注意力(Cross-attention)模块将视觉特征映射到语言模型的嵌入空间。
-
数据策略:预训练数据涵盖公开多模态数据集(如LAION、COYO)及自建中文数据,微调阶段加入细粒度标注数据(区域描述、OCR文本对等)。
-
基于交叉注意力的跨模态适配器
1. 跨模态信息融合
在Qwen-VL中,Cross-attention模块通过计算图像特征(作为Key和Value)和一组可学习的查询向量(作为Query)之间的注意力得分,将图像特征压缩到固定长度的序列中。虽然文本特征没有直接参与Cross-attention计算,但它通过LLM与图像特征进行交互。LLM的自注意力机制能够动态地建模图像特征和文本特征之间的关系,从而实现多模态信息的融合。
2. 高效处理长序列
Qwen-VL中的视觉编码器会生成较长的图像特征序列,直接处理这些长序列会导致计算效率低下。Cross-attention模块通过将图像特征序列压缩到固定长度(Cross-attention层的输出序列的维度与查询序列是一致的,而查询序列的长度由人为设置),显著提高了模型的计算效率。
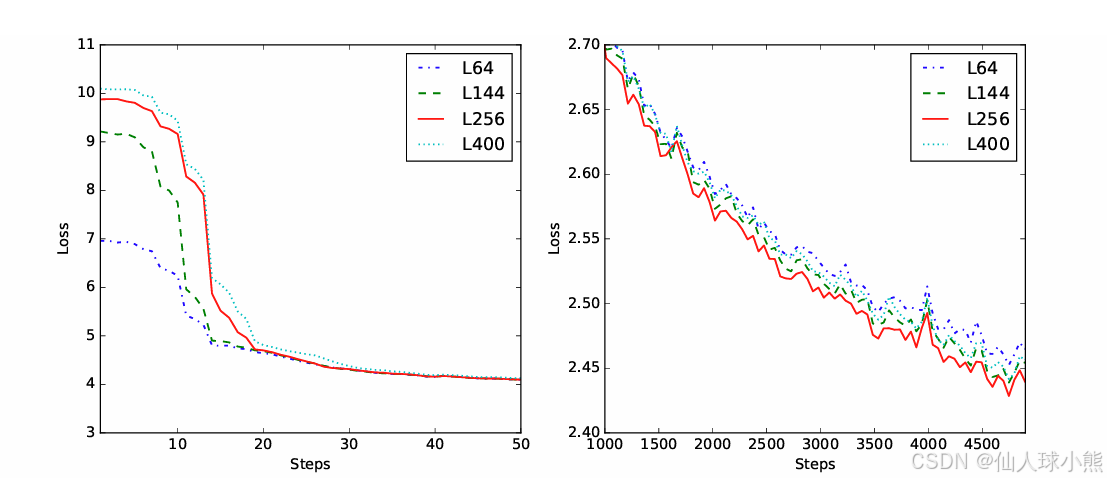
如图所示,在培训开始时使用的Query序列长度越小,初始损失就越小。然而,随着收敛,过多或过少的查询将导致收敛速度减慢。考虑到多任务预训练阶段采用 448 * 448 分辨率,其中 ViT 的输出序列长度为 (448/14) 2 = 1024。查询太少会导致更多信息丢失,我们选择在Qwen-VL 中使用 256个查询来处理视觉语言适配器。
3. 增强模型的细粒度理解能力
在多模态任务中,细粒度的视觉理解是关键。Qwen-VL通过在Cross-attention中加入2D位置编码,使得模型能够更好地捕捉图像中的局部细节和位置信息。此外,Cross-attention机制允许模型在生成输出时动态关注输入序列中的关键部分,从而提高对图像细节的理解能力。
4. 训练过程中的逐步优化
Qwen-VL的训练流程分为多个阶段,在预训练阶段,Cross-attention模块与视觉编码器一起被训练,以对齐视觉和语言特征。在多任务预训练阶段,Cross-attention模块被进一步优化,以处理更高分辨率的图像输入(如448×448),从而提升模型在细粒度任务中的性能。
综上所述,Cross-attention机制在Qwen-VL模型中作为表征器,不仅能够高效地融合和处理跨模态信息,还能显著提升模型的细粒度理解和计算效率,使其成为多模态任务中的理想选择。
论文图解:
动机:大多数开源 VLLM 仍然以粗粒度方式感知图像,并且缺乏执行细粒度感知的能力,如对象接地(Object grounded,大致意思是模型能定位图片中的物体)或阅读图片中的文字。
Qwen-VL 是在 Qwen-7B (Qwen,2023) 语言模型的基础上建立的一系列高性能、多功能的视觉语言基础模型。通过引入一种新的视觉感知器,包括语言对齐的视觉编码器和位置感知适配器,赋予 LLM 基础以视觉能力。同时,精心设计了一个三阶段的训练pipe-line,以优化整个模型的海量图像文本语料库。
具体来说,Qwen-VL 系列模型的特点包括:
多语言:基于多语言图文数据进行训练,支持英语、中文和多语言指令。
多图像: 在训练阶段,允许任意交错的图像 - 文本数据作为 Qwen-VL 的输入,使得Qwen-Chat-VL 可对多个图像进行比较、理解和分析上下文。
细粒度视觉理解: 由于高分辨率的输入(448*448)和训练中使用的细粒度语料库,Qwen-VLs 显示出高度竞争性的细粒度视觉理解能力。
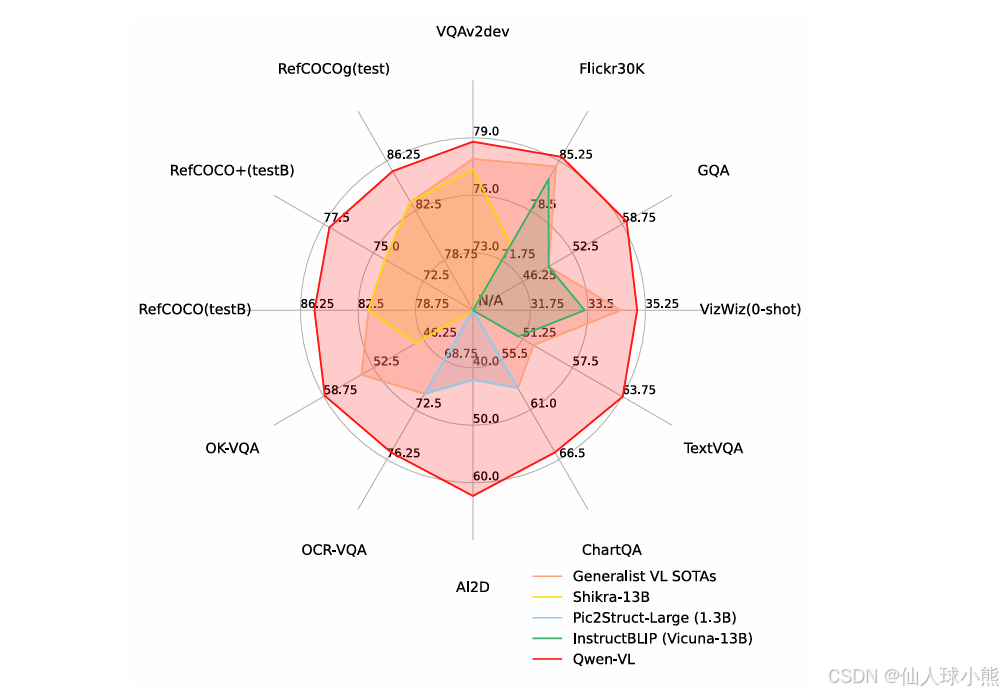
模型性能如图,在当时达到了多个SOTA:
Qwen-VL 的整体网络架构包括三个组件:
大语言模型: Qwen-VL 采用大语言模型作为其基础组件。该模型使用来自 Qwen-7B (Qwen,2023) 的预先训练的权重进行初始化。
视觉编码器: Qwen-VL 的可视觉编码器使用Vision Transformer(ViT)架构,用来自 Openlip 的 ViT-bigG (Ilharco 等,2021) 的预先训练的权重初始化。在训练和推理过程中,输入图像被调整到特定的分辨率。可视化编码器处理图像的方法是,以 14 的步长将图像分割成patch,生成一组图像特征。
位置感知视觉语言适配器: 为了解决长图像特征序列带来的效率问题,Qwen-VL 引入了一种压缩图像特征的视觉语言adapter。该adapter包括随机初始化的单层交叉注意力模块(Cross-Modal Adapter)。该模块使用一组可训练向量 (Embeddings) 作为查询向量,以视觉编码器的图像特征作为交叉注意操作的Key和Value。该机制将视觉特征序列压缩为固定长度(256)。此外,考虑到位置信息对细粒度图像理解的重要性 ,将2D绝对位置编码引入到交叉注意机制的查询键值对中,以减少压缩过程中位置细节的潜在丢失。然后将长度为 256 的压缩图像特征序列输入到大语言模型中。
三大组成部分的参数量如下图所示:
 模型结构与训练流程如下图:
模型结构与训练流程如下图:
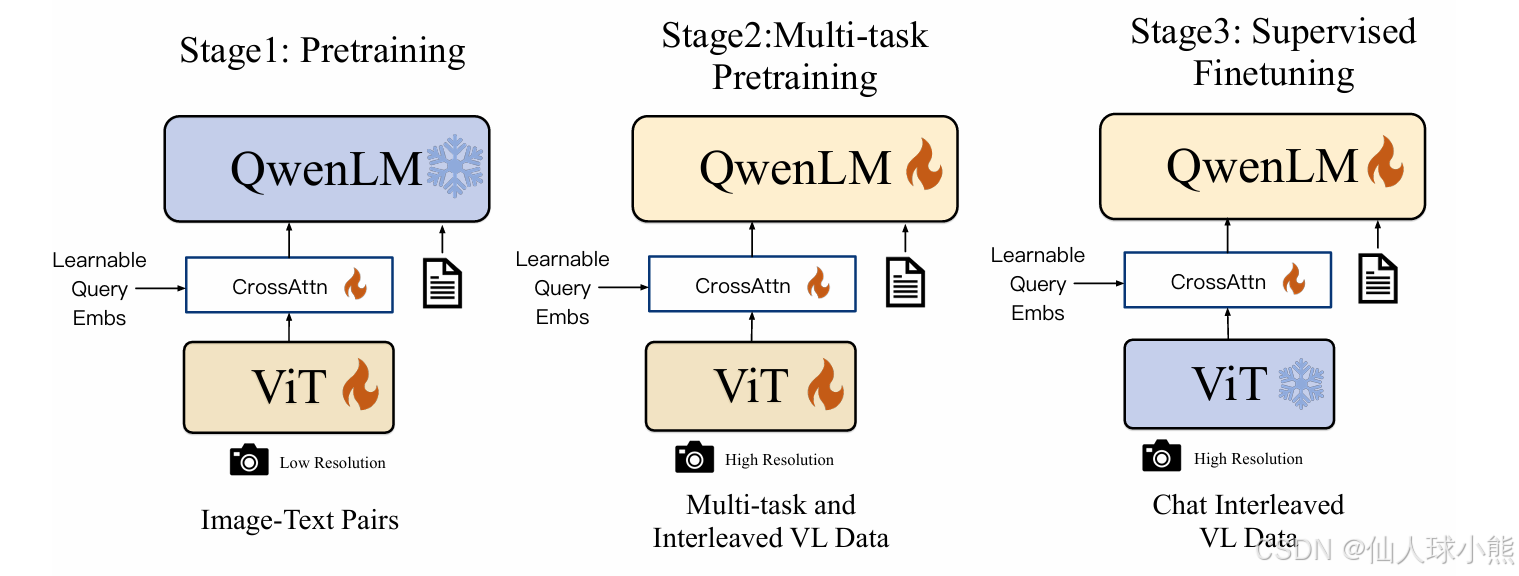
stage1:预训练,目标是使用大量的图文对数据对齐视觉模块和LLM的模态,这个阶段冻结LLM模块的参数。
stage2:多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入(448*448),全参数训练。
stage3:指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。
2. Qwen-VL 2.0:统一表征与端到端优化
表征思想:
-
目标:解决分辨率固定问题、分阶段训练(视觉编码器冻结)导致的表征不匹配问题。
-
方法:
-
联合训练框架:采用图像和视频数据混合训练方案。Qwen2-VL采用了一种混合训练方案,结合了图像视频数据,确保在图像理解和视频解析方面都能达到熟练程度。为尽可能完整地保留视频信息,以每秒两帧的速度对每个视频进行采样。此外,整合了深度为两层的3D卷积来处理视频输入,使模型能够处理3D管状结构而不是2D斑块,从而在不增加序列长度的前提下处理更多的视频帧(Arnab等人,2021年)。为了保持一致性,每个图像被视为两个相同的帧。为了平衡长视频处理和整体训练效率的计算需求,我们动态调整每个视频帧的分辨率,将每个视频的总标(tokens)记数限制在16384以内。这种训练方法在模型理解长视频的能力与训练效率之间取得了平衡。
-
统一表征空间:设计多模态共享嵌入层,视觉与文本特征直接映射到同一语义空间。
-
动态分辨率:与 Qwen-VL 不同,Qwen-VL 现在可以处理任何分辨率的图像,动态地将它们转换成可变数量的视觉标记。、
为了支持这一特性,引入了 2D-RoPE(二维-多通道旋转位置编码)以捕获图像的二维位置信息。在推理阶段,不同分辨率的图像被打包成一个序列(打包长度被控制以限制 GPU 内存的使用),为了减少每个图像的视觉标记,在 ViT 之后使用简单的 MLP 层将相邻的 2 × 2 标记压缩成单个标记,在压缩的视觉标记的开始和结束处放置特殊的 <| vision _ start |> 和 <| vision _ end |> 标记。因此,一个分辨率为 224 × 224 的图像 (使用 patch _ size = 14 的 ViT 编码) 在进入 LLM 之前将被压缩到 66 个令牌。 - 多通道旋转位置编码(MPoPE):与传统的1D-RoPE(用于LLM)仅能编码一维位置信息不同,M-RoPE有效地建模了多模态输入的位置信息。这通过将原始旋转embedding分解为三个组成部分:时间、高度和宽度来实现。对于文本输入,这些组件使用相同的位置ID,使得M-RoPE在功能上等同于1D-RoPE。在处理图像时,每个视觉token的时间ID保持不变,而高度和宽度组件则根据token在图像中的位置分配不同的ID。对于视频,视为一系列帧,每帧的时间ID递增,而高度和宽度组件遵循与图像相同的ID分配模式。在输入包含多种模态的情况下,每种模态的位置编号通过将前一模态的最大位置ID +1 来初始化(如图中文本输入的第一个位置编码为4)。M-RoPE不仅增强了位置信息的建模,还减少了图像和视频的位置ID值,使模型在推理时能够推断更长的序列。
-
论文图解:
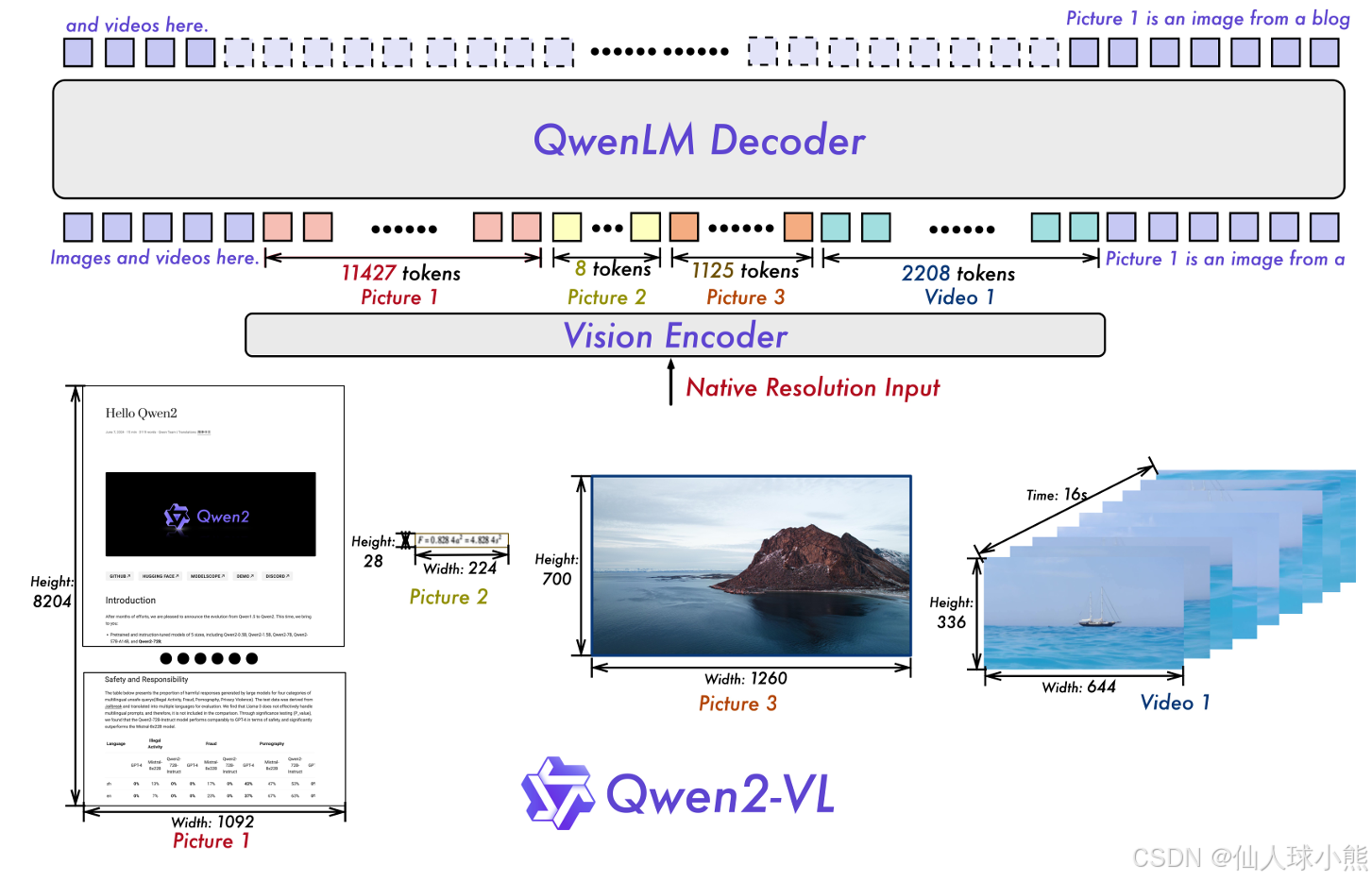
上图展示了Qwen2-VL的全面结构。我们保留了Qwen-VL(Bai等人,2023b)的框架,该框架集成了视觉编码器和语言模型。为了适应各种尺度变化,我们实现了一个大约拥有6.75亿参数的视觉变换器(ViT)(Dosovitskiy等人,2021),它能够熟练处理图像和视频输入。在语言处理方面,我们选择了更强大的Qwen2(Yang等人,2024)系列语言模型。
此外,从图片中video1的token数来看,3D卷积过程中应该进行了空间尺度上的压缩(个人推断),使得token数从16*2*336*664/196=8832降低为2208。
总结:Qwen-VL系列的表征演进
| 版本 | 核心表征思想 | 关键技术改进 | 典型应用场景 |
|---|---|---|---|
| Qwen-VL 1.0 | 初步跨模态对齐 | 跨模态适配器 | 基础图像描述、简单VQA |
| Qwen-VL 2.0 | 端到端统一表征 | 动态分辨率与MRoPE | 高分辨率图像理解、复杂推理 |
发展动机与核心挑战
-
初代(1.0):
-
动机:填补中文多模态大模型的空白,构建基础对齐能力。
-
挑战:平衡视觉与语言模型的异构表征空间。
-
-
2.0版本:
-
动机:实现真正的端到端多模态建模,减少信息损失。
-
挑战:联合训练的算力需求与长序列优化。
-
与LLaVA系列的对比
| 特性 | LLaVA系列 | Qwen-VL系列 |
|---|---|---|
| 连接器设计 | 单层FC → 2层MLP | 交叉注意力层 → 隐式对齐 |
| 语言模型 | Vicuna/Llama(英文为主) | Qwen-LM(中英双语) |
| 核心优势 | 开源社区支持、轻量易用 | 中文场景适配、端到端优化 |
| 典型应用 | 学术研究、开放域对话 | 商业场景(如电商、文档分析) |
对比与思考(配合deepseek R1):
1. 省去显式对齐模块的优势
优点
-
计算效率更高:
-
显式对齐模块(如 Q-Former 或 Cross-attention)通常需要额外的计算资源,尤其是在处理高分辨率图像或长视频时。
-
省去这些模块可以减少计算量,提高训练和推理效率。
-
-
模型更简洁:
-
显式对齐模块增加了模型的复杂性和参数量。
-
共享嵌入层和动态分辨率机制使得模型架构更加简洁。
-
-
端到端训练:
-
隐式对齐机制使得模型可以端到端训练,无需分阶段优化对齐模块。这有助于更好地联合优化视觉和文本特征。
-
2. 省去显式对齐模块的代价
缺点
-
对齐效果可能较弱:
-
显式对齐模块(如 Q-Former)通过专门设计的注意力机制或映射函数,能够更精确地将视觉特征与文本特征对齐。
-
隐式对齐依赖于共享嵌入层和动态分辨率机制,可能无法完全捕捉视觉和文本之间的复杂关系,导致对齐效果较弱。
-
-
模态差异问题:
-
视觉和文本特征通常分布在不同的语义空间中,显式对齐模块可以显式地解决这种模态差异。
-
隐式对齐依赖于共享嵌入层,可能无法完全消除模态差异,尤其是在多模态任务中(如视觉问答、图像描述生成)。
-
-
动态分辨率的局限性:
-
动态分辨率机制虽然灵活,但在处理极端分辨率(如极高分辨率图像或极长视频)时,可能导致信息丢失或计算不稳定性。
-
显式对齐模块通常对输入分辨率不敏感,能够更稳定地处理不同分辨率的输入。
-
-
训练难度增加:
-
隐式对齐机制需要模型在训练过程中同时学习视觉和文本的对齐关系,这可能导致训练难度增加,尤其是在数据量有限的情况下。
-
显式对齐模块可以分阶段训练,先优化对齐模块,再联合优化整个模型,从而降低训练难度。
-
3.如何选择
Qwen2-VL 省去显式对齐模块,依赖共享嵌入层和动态分辨率机制实现隐式对齐,是一种效率与性能的权衡,这种设计适合以下场景:
-
大规模预训练:当模型在大规模多模态数据集上预训练时,隐式对齐机制可以通过数据驱动的方式学习对齐关系。
-
高效推理:在需要高效处理高分辨率图像或长视频的场景中,隐式对齐机制可以减少计算开销。
而如果是针对特定领域、特定任务的情况,数据量有限,且对任务有定制化要求的话,那使用显式的对齐模块将是一个更合理的选择。


















 3708
3708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











