



本文只是一个超级小白+草履虫写的一个个人浅显理解,大模型还没入门,可能叙述以及理解都不到位,仅作为本人学习留存,不保证百分百的准确性!
目录
摘要

把语言模型变大并不代表说他们会更好的去按照用户的意图来做事情,大的语言模型很有可能会生成一些不真实的,有毒的或者是没有帮助的一些答案。换句话说就是模型并没有和用户需求对齐(Aligned),在AI模型的部署方面,这种安全性和有效性是非常重要的。一方面人们享受AI模型带来的灵活性输出带来的巨大应用前景,另一方面这一灵活性也会导致出错概率的提升。即使ChatGPT自身在有意识地避开这些问题,但是人们还是有很多可能性去绕开ChatGPT的限制。这篇文章主要展示如何对语言模型和人类意图之间做Aligned,具体方法就是基于人类的反馈去做一个微调——这里是人类反馈而不是标注数据。首先从标注人员编写的提示和通过OpenAI API提交的提示中收集数据,标注人员展示了他们希望模型如何正确回应这些提示,生成一个理想模型行为的数据集。利用这些示范数据集,进行初步的监督学习微调。其次又收集了一个数据集,因为一个模型可能输出很多答案(概率采样嘛),然后对模型的多个输出用人来标注哪一个输出更好,接着就可以用强化学习继续训练一个模型出来,这个模型就叫InstructGPT。
总结就是做了两件事情:①标了一些数据,问题和答案都写出来然后训练一个模型【监督学习】。②又做了一个排序比较的一个数据集,用强化学习去训练这个模型。【强化学习】
结果上面,基于人类的评估发现InstructGPT虽然只有1.3B的模型参数,但是好过最大的模型GPT3,其拥有175B的模型参数,也就是模型更小了但效果也更好了。InstructGPT更能够在真实性方面降低有毒的的答案,在公开的NLP数据集上面它的性能也没有显著的下降。虽然还是有一些简单的错误。(这个结果不是很意外,因为标注的数据集信噪比更好一点,学习起来更加简单,不需要那么大一个模型,Transformer模型就是一个压缩,对整个数据进行一个压缩,把整个数据的信息压缩进模型的参数中,且标注的信息和最后要评估的数据集可能更接近一些,导致不需要去压那么多东西了。虽然很多大厂乃至openai都在训练一个特别大的模型,根本不需要标注效果也特别好,然而对于实际使用方面,如果这个方向一路走到底,计算能力不一定吃得消,而且数据增长到某个程度之后,覆盖的方面可能还是不全,在你想要的特性但模型做不到的方面适当加入一些人类的标注其实更划得来一些。一个好的方法需要平衡算力需求和人类标注的代价)
导论
摘要的详细版本
问题——方法——结果
大语言模型可以通过提示的方法,把任务作为他的输入,但是这些模型也经常有一些你不想要的行为比如说捏造事实,生成偏见/有毒的输出或者没有按照你想要的方法来。作者会认为这是因为整个语言模型的训练的目标函数不是很正确,原始语言模型的目标函数是在网上的文本数据中预测下一个词,这一目标函数和我们想要整个模型根据人的指示有帮助的和安全的生成答案其实是有不一样的,真正训练的目标函数和我们想让他干的这两个事情之间的差距被作者称之为语言模型的目标函数没有Aligned。因此这篇文章的目的就是为了让语言模型Aligned的更加好一点,具体来讲希望语言模型更有帮助性,能解决我想让他解决的事情,更加真诚不要捏造事实,且无害。具体方法就是基于人类反馈的强化学习,简称RLHF,其实是在之前的工作里面提出来的,其实这些工作也是本文作者前面的工作了,选用RLHF这个方法可能是因为openai是强化学习的出身hhh。强化学习的一个方法就是去仿照人,比如说打游戏或者做机器人之类的,因此这里的技术可以同样用过来让我们的模型能够仿照人来生成这种答案或者生成符合人类偏好的这种答案。
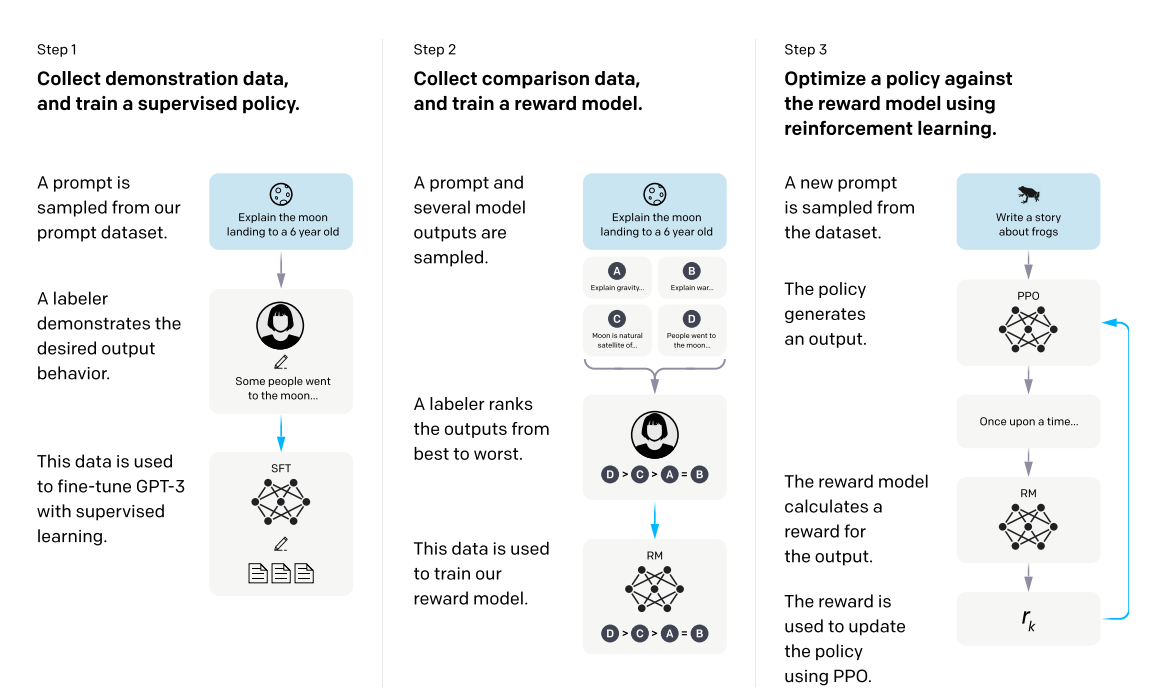
step1:找了一些人写了各种各样的问题,这个问题在GPT中称之为prompt,具体来说就是类似于向一个六岁的孩子解释什么是登月。这些问题也可能来自于之前用户在向GPT3提交的各种问题里面筛选出来,然后它继续让人来写答案。有了问题和答案之后把这俩拼接成一段话,基于这个数据去微调GPT3。虽然是人类标注的数据但是在GPT眼中其实和之前数据的形式是差不多的,也就是给你一段话去预测下一个词,只不过这个数据的质量更好更符合人类的需求。所以在微调上面和你微调任何别的东西或甚至是做预训练上没有太多区别,GPT3的模型在人类标注数据上进行微调出来的模型称之为SFT(有监督的微调),这就是训练出来的第一个模型。这个模型其实也能用,但是写答案是一个很费时费力的事情,很难让人把各式各样的答案都写出来,因此干了第二个事情,使得在标注上更加简单。
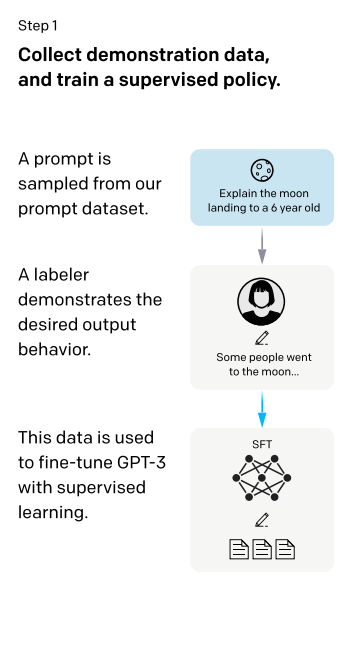
step2:还是给你一个问题,给之前预训练好的这个SFT,让SFT生成答案,我们知道GPT的预测其实是根据概率进行采样,采样出很多答案,通常说可以用bing Search,这个地方就生成了四个答案,然后把四个答案提供给人,让人标注谁好谁坏,这就是一个排序的标注,根据这个标注训练一个新的模型:RM,在强化学习中称之为奖励模型,这个模型是说你给我你的prompt和你的输出,模型对它生成一个分数(奖励/打分),使得我对这个答案的分数能够满足人类标注的排序关系。一旦该模型生成好之后,就可以对生成的答案进行打分。
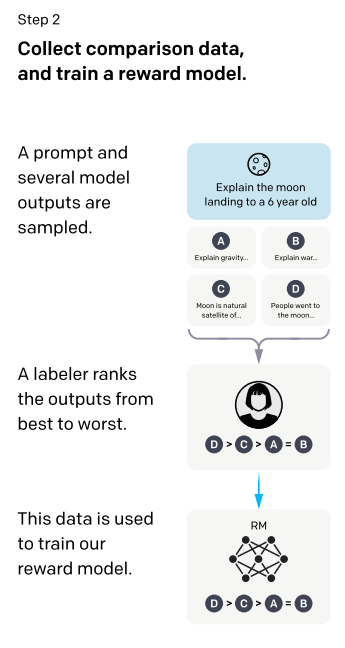
step3:继续去微调前面训练好的SFT,使得它生成的答案送入RM能够得到一个比较高的分数,去优化SFT中的参数。
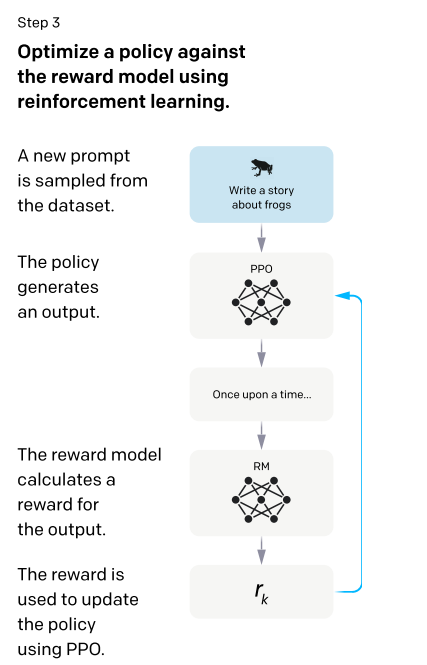
总结三步骤:①手动选择一些问题并以人工的方式给出答案,以上述作为数据集训练出SFT模型②让训练好的SFT模型回答一些问题,人工对SFT生成的答案进行打分,以这一部分数据集训练出RM打分模型③根据RM模型的打分结果,继续优化SFT模型。(如果第一步能够生成足够多的答案的话,其实不需要后面两个步骤也许也是可以的,但是考虑到去写一个答案做生成式的这种标注远远复杂于排序这种判别式的标注,有这一步的好处可以使得数据标注更加简单,能够更快速地得到更多的标注信息,加上这两块之后就可以使得在同样的标注成本下能得到更多的数据,可能模型性能会更好一些)最后训练出来的模型就是InstructGPT,GPT3就是通过这三步之后训练而来的。从技术要点上来看,主要还是强化学习这一块RM模型如何训练出的,因为其他步骤如微调和GPT3的微调其实是一样的,RM模型如何训练出来的一定要讲一下,还有就是RM模型训练出来之后如何通过强化学习来训练SFT。
导论最后是结果的一些描述:①标注人员觉得InstructGPT比GPT3的答案要好很多;②真实性上也好一些;③有毒的输出上也好一些;④但是在偏见上并没有特别好的提升;⑤微调时,通常是根据某一个目标函数做微调,可能会使得在一些别的任务上性能下降,这个地方就是说在做强化学习的时候,把最原始的目标函数还是拿回来,使得我们调完之后虽然在QA上做的更好一些,但是在一些其他任务比如公有的NLP数据集上的性能也要做到下降的并不多。⑥找人来标注,但是标注具有主观性。找了一些没有标注数据参与训练的人,只从结果上评估InstructGPT的话,还是发现比GPT3更好一些,人与人之间的喜好度有一定的相关性的⑦把GPT3在InstructGPT的数据上微调了一下,也在一些其他的公用数据集上(FLAN和T0,每个数据集中都有大量的NLP任务)调了一下,发现还是在自己数据集上调出来的效果更好,毕竟别人的数据和我们自己人工标注的数据在分布上不那么一致,意味着微调对数据还是比较敏感的⑧虽然标注了大量的问题,但是因为语言模型还是比较灵活,不可能把所有问题都标注出来。不过比如虽然标注的这些里面只有非常少的代码问题,但是在训练完之后发现实际模型在这一方面的表现还是不错的,说明模型是有一定泛化性的,其实也没有必要一定把这种所有不同的问答类型全都标注,也可以说是few-shot⑨还是会犯一些简单错误
相关工作
跳过Alignment这一块工作
研究方法和实验细节
宏观方法论
这些技术不是Instruct GPT的原创,而是之前就有了,只是Instruct GPT用这些技术在一个新的数据集上重新训练了一下,这里暂且不提后面还会仔细说的。
数据集
prompt数据/问题和任务的来源
- 普通任务——标注人员自由地创建多样化任务,确保数据的广泛性。
- 少量示例任务——标注人员为各种指令编写多个查询/响应对,模拟少量示例任务的学习场景。
- 基于用户的任务——基于用户的实际用例创建任务,以确保模型能在真实应用中表现良好。 (用户提供了一些想要支持的应用场景,把他构建成任务)
有了上述最初构建出来的prompt之后,就训练出来了第一个Instruct GPT的模型,然后把模型拿出来放在Playground中,让大家随意去用。这时候用户会再问一些问题,他们又把这些问题采集回来,做一些筛选,比如对每个用户采用200个这样的问题,在划分训练,验证,测试集的时候是根据用户ID来划分的,收集了来自不同用户的许多问题之后不要放在一起随即划分,因为一个用户可能会问一些类似的问题,如果这个问题同时出现在训练和测试集里面,就有点污染在里面了,因此按照用户来切分公平性会好一点,另一个方面会把问题中的用户信息过滤掉,用这种方法可以得到更多的这种prompt,这个也是一种常见的产品思路。
有了这些prompt之后就产生了三个不同的数据集:
- 标注工直接写答案——用于训练生成SFT的模型是一万三千个样本
- 用于训练一个RM模型,只要排序就行——三万三千个样本
- 训练最终的模型Instruct GPT,这个时候就不需要标注了,因为标注来自于RM模型的标注——PPO的模型是三万一千个样本
用这个API的用户的prompt都干了些什么事情:
最多的是生成某些东西,然后是一些开放性QA,头脑风暴,聊天,重写,总结等等
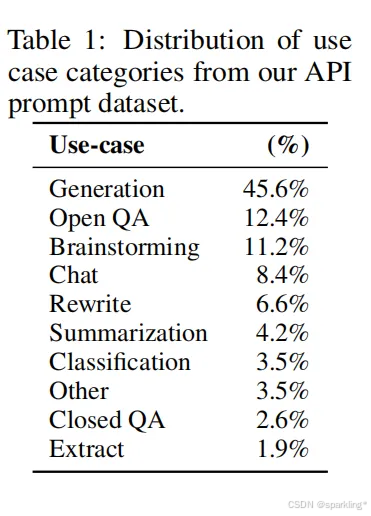

prompt对应的任务类型
其实就是刚刚讲的那些内容
人类数据收集
如何挑选标注人员进行数据的标注等,不是特别重要也跳过。
模型***(重点内容!!!)
三个模型:
- SFT:(有监督的微调)就是把GPT3这个模型,在标注好的prompt和答案上面重新训练一次,训练完其实有些过拟合了,但是这个模型不是直接拿出去用而是用于初始化后面的模型,因此过拟合没啥问题反而有一些帮助。
- RM:第二个就是说前面的模型SFT,把它后面的unembedding layer除掉,之前都是过了最后一个输出层之后,放进softmax输出一个概率,现在是说最后一个softmax不用了,后面加上一个线性层进行一个投影,输出中所谓的值通过线性投影,(因为每个词都是有一个输出,把所有这些词的输出放在一起)能够把整个一段话投影到一个值里面,也就是输出为1的一个线性层,就可以输出一个标量即为分数。这个奖励是在prompt和你的回复上面一起训练而来的。这里用的是6B的一个RM,没有用175B,因为175B训练起来好像不太稳定(比较大的模型上进行训练不稳定是一个痛点,现在也没有特别好的解决方案,训练着训练着可能就炸掉了,loss飞起,而如果不稳定的话在后续RL的训练中会比较麻烦),且小模型节省算力资源。损失函数方面,因为输入的标注是排序,而不是用户标了一个值出来,需要把顺序换成值,具体来讲用的是排序里面常见的一个pairwise ranking loss:
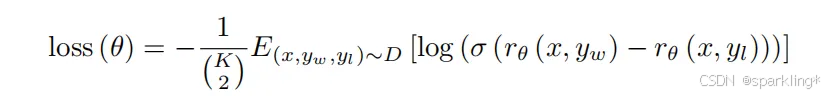
 (文字描述解释公式:请看图中手写文字部分,比较简单不做赘述)还有一些细节,为什么选择这样的方法:首先看一道题目去理解花费的时间可能比成倍的排序花费的时间更多或者差不多,还有就是再比如K=4的时候,带来的标注信息是C42也就是6,但是K=9的时候产生了36个这样的排序关系,标注信息增加为原来的6倍,但是时间成本只增加了一倍,是赚的。由于一个小批量中,K=9的排序全部算在这里面,公式后面的部分可能包含36项,这里面最贵的地方就是把x和y放进你的RM模型里面(6B的GPT3的模型)得到一个值的输出,虽然是36项但是只需要做9次就行了,值是可以重复利用的,也就是算了9次但是是36个结果,相当于省了4倍的时间,K越大省的时间越多,即计算上K大一些也是有好处的。且之前的工作不仅仅是k=4,它标的时候只标最好的那个,也就是说四个答案中选出最好的答案,做损失的时候就不是一个pairwise,因为你没有两两比较信息,把二分类的logistic regression变成了一个多分类的softmax,在四类里面把最大的值选出来,也就是如果你的yw是最好的,直接把这个
(文字描述解释公式:请看图中手写文字部分,比较简单不做赘述)还有一些细节,为什么选择这样的方法:首先看一道题目去理解花费的时间可能比成倍的排序花费的时间更多或者差不多,还有就是再比如K=4的时候,带来的标注信息是C42也就是6,但是K=9的时候产生了36个这样的排序关系,标注信息增加为原来的6倍,但是时间成本只增加了一倍,是赚的。由于一个小批量中,K=9的排序全部算在这里面,公式后面的部分可能包含36项,这里面最贵的地方就是把x和y放进你的RM模型里面(6B的GPT3的模型)得到一个值的输出,虽然是36项但是只需要做9次就行了,值是可以重复利用的,也就是算了9次但是是36个结果,相当于省了4倍的时间,K越大省的时间越多,即计算上K大一些也是有好处的。且之前的工作不仅仅是k=4,它标的时候只标最好的那个,也就是说四个答案中选出最好的答案,做损失的时候就不是一个pairwise,因为你没有两两比较信息,把二分类的logistic regression变成了一个多分类的softmax,在四类里面把最大的值选出来,也就是如果你的yw是最好的,直接把这个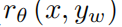 值最大化就行了,softmax最大的好处就是在标注上面四选一,而不是真的要完全做一个排序,但是问题就是容易over fitting,现在改成全序的排序变得更复杂一些,不是要学一个分数只要把最大的挑出来就行,而是要学一个分数使得他整个9个答案之间的排序能够直接保存下来,标号越多过拟合现象就越好一些,这也是对之前方法改动的原因。在看视频弹幕上的时候,弹幕说论文中还提到一点就是如果不把36个pair放在一个batch里面,会导致每个答案被学习8次,这就容易导致过拟合。不管怎样,这也是一个标准的排序问题,用的损失函数就是pairwise的ranking loss。【Elo系统:对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。在这里我先私以为这样设计的损失函数训练方式模拟了Elo生成的标量分数吧】
值最大化就行了,softmax最大的好处就是在标注上面四选一,而不是真的要完全做一个排序,但是问题就是容易over fitting,现在改成全序的排序变得更复杂一些,不是要学一个分数只要把最大的挑出来就行,而是要学一个分数使得他整个9个答案之间的排序能够直接保存下来,标号越多过拟合现象就越好一些,这也是对之前方法改动的原因。在看视频弹幕上的时候,弹幕说论文中还提到一点就是如果不把36个pair放在一个batch里面,会导致每个答案被学习8次,这就容易导致过拟合。不管怎样,这也是一个标准的排序问题,用的损失函数就是pairwise的ranking loss。【Elo系统:对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。在这里我先私以为这样设计的损失函数训练方式模拟了Elo生成的标量分数吧】 - RL:强化学习模型是如何训练出来的?用到的算法是强化学习中的PPO算法。强化学习中,模型叫做policy,就是RL policy,其实就是GPT3这个模型了。为什么叫策略,是因为对强化学习来说,每一个策略就是说状态,就是当前的模型需要做一些所谓的action,要输出这样的一个y奖励值出来,一旦做了action之后,环境会发生变化。
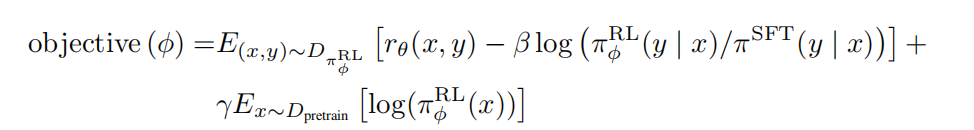
(公式解析:①KL散度惩罚项:在训练时,RL模型不断进行更新,生成的y逐渐偏向新的RL模型的分布,可能导致RM模型计算出的关于新的y的奖励分数不准,因此引入KL散度惩罚项,该项的目的是希望强化学习的新模型RL输出的y的概率分布不会明显偏离于SFT模型输出的y的概率分布。参数β控制着KL惩罚项的强度。②引入原GPT3上的原始数据与损失函数:防止新模型失去原模型在多样化任务中的能力,防止由于新模型某种能力的提高导致的其他方面能力的下降。参数γ控制着对原始数据集的倾向程度,即预训练梯度的强度。)为什么有标好的数据,我还需要训练一个RM出来,再去训练原来的模型,为什么不直接训练原来的模型就算了,主要原因是我标的只是一个排序而不是分数,如果能把y标出来就回到第一个有监督的微调模型里面了,现在就是说你给定当前模型我生成多样的输出,人类进行排序,真的想直接优化的话不学RM怎么做呢?每一次更新的时候生成一些这样的答案,找人来标一下,看这些顺序,拿到顺序后再算梯度对模型进行更新,下一次的时候我又生成新的数据找人来标——在RL中称为在线学习。这样的方式对人的占用太狠了,需要学习一个函数去替代人的行为,以便带来一个实时的反馈。
总结
三件事情
- 数据把prompt和答案都标注出来,用最正常的GPT的微调,有监督的调出一个模型SFT出来
- 训练一个奖励模型RM,为了使用RL的这种框架干事情,该奖励模型拟合了人对模型多个输出之间的一个排序
- RM放入强化学习框架中,以便代替人类进一步调整这个模型SFT得到最终模型
评估和实验结果
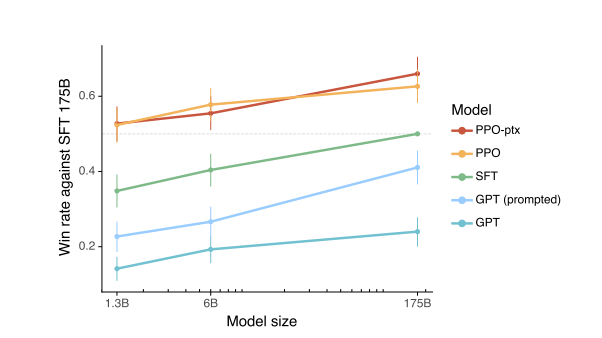
GPT3——GPT3在prompt上做较多的调整,有提升,但是和有标注比较还是差距挺多,在1.3B这个模型上,通过13000个标注,可以看到也是有一个巨大的提升,这个提升大于你把最原始的1.3B的模型扩大一百倍带来的效果——SFT——PPO通过额外的三万条数据和它对每一个9个输出的一个排序再做一次训练的话,提升也是更加巨大一些,且还是1.3B的一个模型,比之前都要好,1%已经打败1了,前提是在一个特定的测试集上面,因为这个地方的测试集其实和你的训练数据有一定的耦合性。
还有一些零碎的点:数据集小了,效率也会提高。标注人员带来的限制。不同语言上的差异表现,可能英语表现更好。模型上不完全aligned, 不完全安全。RLHF之外还有别的方法训练。到底要aligned到什么地方?用户让干什么就干什么还是深入理解用户内在的需求等等,如何通过模型衡量也是很难的一部分。
技术上是实用的,给定一个较大的语言模型,如何通过一些标注数据迅速把它在某一个关心领域方面的性能能够达到实用的阶段,为生成模型做产品提供了一个实际可操作的思路。文章主要针对帮助性提升,剩下两个主要是靠奇迹哈哈哈哈。创新性一般,只优化了一个目标。RL可能没必要,我可以在第一步多标注一些数据,或者文本合成的方法快速增大数据。


















 1906
1906




 到【灌水乐园】发言
到【灌水乐园】发言









