







目录
在上一篇博客中说的AlexNet没有提供一个通用的模板来指导后续人们设计新的网络
博客参考书籍:7.4. 含并行连结的网络(GoogLeNet) — 动手学深度学习 2.0.0 documentation (d2l.ai)
VGG
经典卷积神经网络的基本组成部分:
- 带有填充以保持分辨率的卷积层
- 非线性激活函数
- 汇聚层
一个VGG块也是类似的,由一系列的卷积层组成,然后在后面加上用于空间下采样的最大汇聚层。
下面是VGG块的代码定义:
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)VGG网络
VGG网络也是可以分成两个部分:
1. 卷积层和汇聚层(VGG块)
2. 全连接层
代码实现:
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)在上面的网络中的卷积部分使用了vgg_block函数,提高了复用性,使神经网络的实现更加的简便,然后
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
在这里面设置好输入、输出的通道数量,每遍历一次就是一个卷积层,最后再加上全连接层。
输入一个单通道样本数据(1,1,224,224)来观察每个层的输出形状:

可以看到,在每个块中的高度和宽度都减半,最终高度和宽度都是7,然后最后再展平表示,送入全连接层来处理。
总结
因为这里的VGG使用了8个卷积层和三个全连接层,所以也被称作VGG-11 .它使用可以服用的卷积块VGG块构造网络;不同的VGG模型可以通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用可以有效的设计复杂的网络,导致网络定义的非常的简洁。
在VGG的论文中,有一个发现:深且窄的卷积(3 x 3)相较于较浅层且宽的卷积更有效。
NiN
前面的三个网络都有一个共同的设计模式:
通过一系列的卷积层和汇聚层来提取空间结构特征;然后再通过全连接层对特征的表征进行处理。
在此基础上,AlexNet和VGG对LeNet的改进主要在于如喝扩大和加深这两个模块。
如果使用了全连接层,可能会放弃表征的空间结构,所以NiN网络再每个像素的通道上分别使用多层感知机。
全连接层的输入输出通常是分别对应于样本和特征的二维张量,NiN再每个像素位置(针对每个高度和宽度)应用一个全连接层。
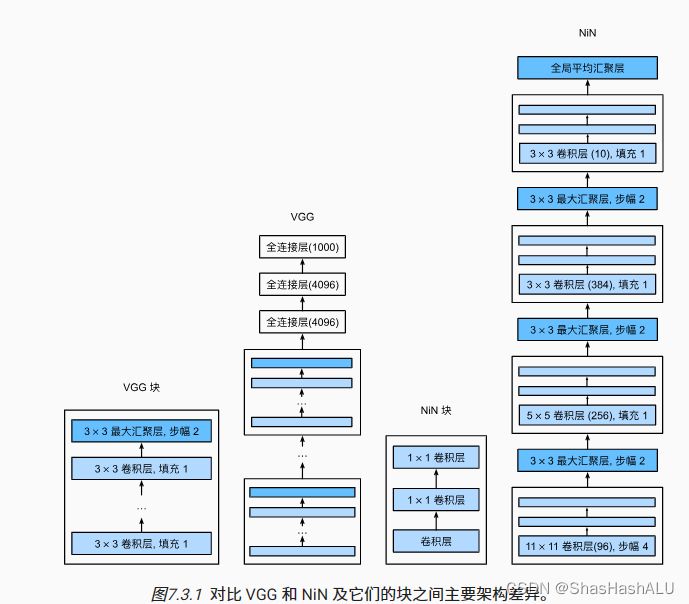
VGG和NiN对比
NiN块的实现代码:
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())可以看到块里面都是卷积层,并且除了第一个的核自定义以外,后面的卷积层的核都为1.
NiN模型
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())每个块的输出形状:
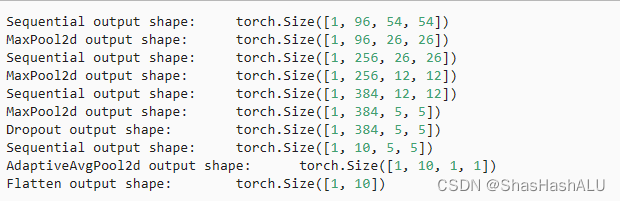
从上面的代码可以看出NiN完全取消了全连接层,使用一个NiN块,其输出通道数等于标签类别的数量、,最后放一个全局平均汇聚层,生成一个对数几率。NiN显著减少了模型所需要参数的数量,但是在实践中有时候会增加模型训练的时间。
总结
NiN使用由一个卷积层核多个1 x 1卷积层组成。
NiN去除了容易造成过度拟合的全连接层,并替换成全剧平均汇聚层(在所有位置上进行求和)。该汇聚层的通道数量等于所需输出数量。移除全连接层除了可以减少过拟合遗骸,也显著减少了NiN的参数。
GoogLeNet
在NiN网络的基础上又做了改进
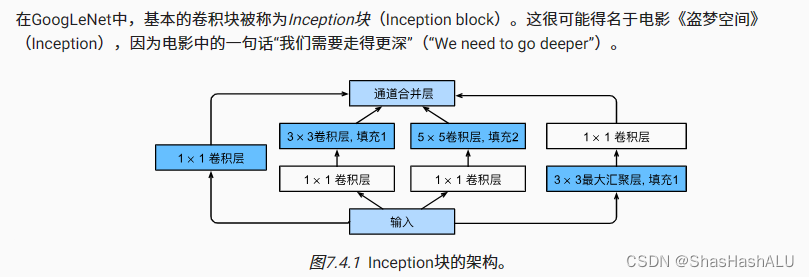
从图中可以看出这个inception块由四条并行路径组成前三条使用不同核的卷积层从不同的空间大小来提取信息,然后中间的两条路径在输入上执行1 x 1卷积来减少通道数,从而降低模型的复杂性。第四条路径使用3 x 3的最大汇聚层然后再用 1 x 1的卷积层来改变通道数。最后,将每一条路径上的输出在通道维度上连结,并构成inception块的输出。
通常调节的超参数是每层输出通道数
代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)模型设计
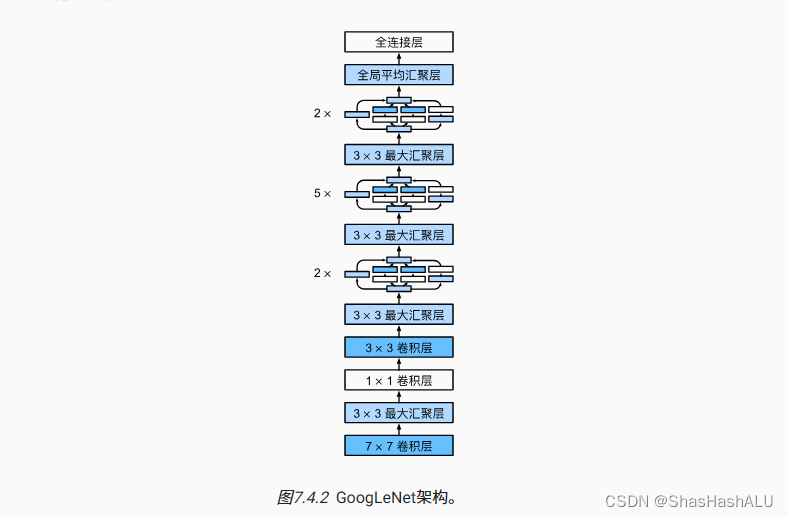
一共使用了9个inception块和全局平均汇聚层的堆叠来生成其估计值,块之间的最大汇聚层可降低维度,全局平均汇聚层避免了在最后使用全连接层。
代码实现:
#第一个模块使用64个通道、7x7卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#第二个模块使用两个卷积层:第一个卷积层是64个通道、1x1卷积层;第二个卷积层使用将通道数量增加三倍的3x3卷积层。 这对应于Inception块中的第二条路径。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#第三个模块串联两个完整的Inception块。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#第四模块更加复杂, 它串联了5个Inception块
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
#第五模块包含两个Inception块。 其中每条路径通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











