









ICLR 2024
发表单位:清华大学人工智能研究所(THUAI);北京信息科学与技术国家研究中心(BNRist);清华大学自动化系
code:https://github.com/zaocan666/AF-FCL
摘要:
联邦持续学习 FCL:现有研究主要集中在减轻与其他客户合作时持续学习的灾难性遗忘问题(遗忘现象并非总是有害的)
设计的场景:在FL场景中,客户端之间的统计异质性和数据噪声可能会表现出虚假的相关性,从而导致有偏差的特征学习。虽然现有的学习策略侧重于完全利用先前的知识,但我们发现忘记有偏见的信息在我们的研究中是有益的。
——>提出精准遗忘概念,生成重播方法 AF-FCL:选择性地利用联邦网络中的先前知识,采用基于normalizing flow(规范化流)模型的概率框架来量化先前知识的可信度。(具体如何量化的?数据隐私和通信开销?)
FCL面临挑战:
(1)本地客户端的非iid数据导致的统计异质性
(2)灾难遗忘:由于存储限制、隐私问题等现实因素对以前任务数据的限制访问,可能导致模型在吸收新任务后失去熟练执行先前任务的能力
(3)联邦场景存在的特征偏差,影响持续学习模型中的内存;标签噪声(有噪声标签的记忆会显著影响模型的性能)
持续学习里全局记忆库:
全局记忆库在持续学习里面是怎样存在?里面所存储的数据样本或参数是如何选择的?





前提假设:
无限任务池(LTP) ;从时间的角度来看,单个客户在不同时间点从LTP随机选择的任务可能是不相关的,甚至是对立的
在严格持续学习的场景中,模型被假设无法访问之前的数据。这种情况下,模型必须在不回顾过去数据的前提下学习新任务。
遗忘现象并非总是有害的(Han et al, 2020)。相反,准确遗忘减轻异质性对模型学习的负面影响
在有噪声的数据集上进行实验验证
持续学习的优化目标:
找到一组模型参数 θt,使得这些参数在所有已经完成的任务上的表现都尽可能好。希望模型在新任务上的表现良好,同时不牺牲其在过去学过的任务上的表现。

使用的理论:
为了准确地从以前的任务中识别良性知识,使用学习的归一化流(NF)模型实现相关性估计(Durkan等,2019;Winkler等人,2019;Rezende & Mohamed, 2015)。NF模型可以通过一系列双射变换将任意复杂的数据分布映射到预定义的分布。这种可逆性使得神经网络对输入的知识具有无损记忆,并能准确地估计观测数据的概率密度。虽然NF模型中的信息可能包含有偏差的特征或由于异构数据而产生的虚假相关性,但我们认为,相对于当前任务的异常特征是可疑的,可能构成威胁学习的过程。一个特定特征的可信度可以用它在当前任务中的概率密度来量化。利用NF模型进行相关估计,自适应地减轻了错误信息
归一化流是一种生成模型。通过一系列平滑和可逆的变换将复杂的多模态分布映射到简单的概率分布








实现目标:
促进具有参数θ的全局模型的协同构建。在联邦学习和持续学习中固有的隐私约束下,我们的目标是学习当前任务,同时为所有客户端保留先前任务的性能,从而寻求优化所有客户所有任务的性能
![]()
创建一个共享的、统一的模型,该模型由一组参数θ定义

精确遗忘:
采用精确遗忘来减轻异质性的负面影响,并有选择地鼓励对不良信息的遗忘
无损记忆:通过对可逆层的精心设计,归一化流完成了双目标变换,保持了输入和输出空间元素之间的一对一对应关系。双射性保证原始输入的无损记忆。因此,NF的这种固有属性对于复杂分布的精确建模至关重要,并且在生成应用程序中处于中心地位。
精确似然估计:可逆性可精确估计学习数据集中数据样本的概率密度

计算给定数据点z的对数概率密度:(利用可逆的正常流模型来精确估计数据样本的概率密度,并通过一系列数学推导展示了具体的计算方法)
公式第一步:通过对数变换和对数雅可比行列式的性质得到;
第二步:根据链式法则展开变换。

通过设计特定的变换来简化雅可比行列式的计算,以及如何在条件NF模型中使用标签作为额外的信息来进行似然估计

AF-FCL:
面临挑战背景:特定的客户端可能拥有不相关的任务和有偏差的数据集。当模型记住来自特定客户的偏差或虚假相关时,所有客户的任务序列可能会出现模型性能下降。直接部署旨在减轻灾难性遗忘的持续学习方法很难解决FCL中的异质性问题。
AF-FCL方法:自适应地利用记忆知识并在fedavg框架下为所有客户端学习无偏特征。每个客户机中分类器的训练示意图。总体而言,AF-FCL的实现由以下组件组成:(I)特征生成重放。为了防止完全遗忘,在分类器的特征空间中训练了一个全局NF模型用于生成重播;(二)知识蒸馏。在特征空间中使用知识蒸馏来减轻显著漂移,从而增强了NF模型训练过程的稳定性;(三)相关估计。与当前任务相关的异常特征可能会潜在地破坏学习过程。通过生成的特征在当前任务中的概率密度来评估其可靠性。
使用模型已经学习到的信息(记忆知识),以便于从所有参与训练的客户端数据中学习到一组普遍有效且不偏向任何单个客户端的特征。这样做可以提高模型的泛化能力,确保训练出的模型在全局数据上表现良好。
本地客户端中:
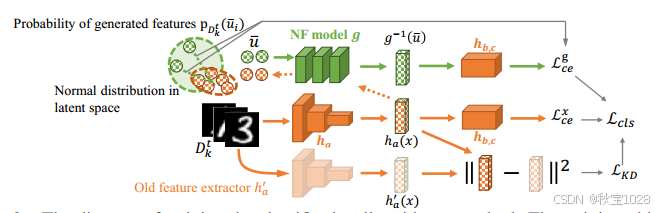

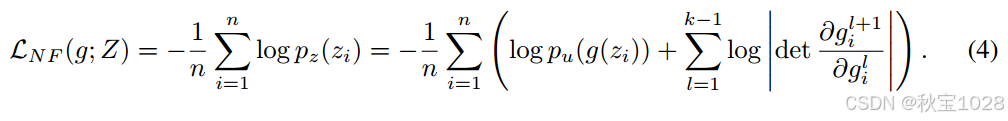




神经序列模型(Neural Flow, NF)的训练方法及其在特征空间中的应用:


利用归一化流(Normalizing Flow, NF)模型进行特征变换的方法,以及如何在联邦学习场景下通过相关性估计来准确利用记忆的知识:


定义损失函数以及分类器如何从之前的学习任务中获得有益的特征:
通过优化一个综合损失函数来确保分类器不仅能够有效地利用新数据和旧数据中的有用信息,还能避免记住可能对当前任务有害的偏见特征。这种方法旨在随着训练过程的进行不断提高模型的泛化和适应能力
参考:

















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









