






1、解决了RNN梯度弥散的问题。
2、解决了记忆长度的问题。(RNN记忆更偏向指定词附近的词,short term memory)
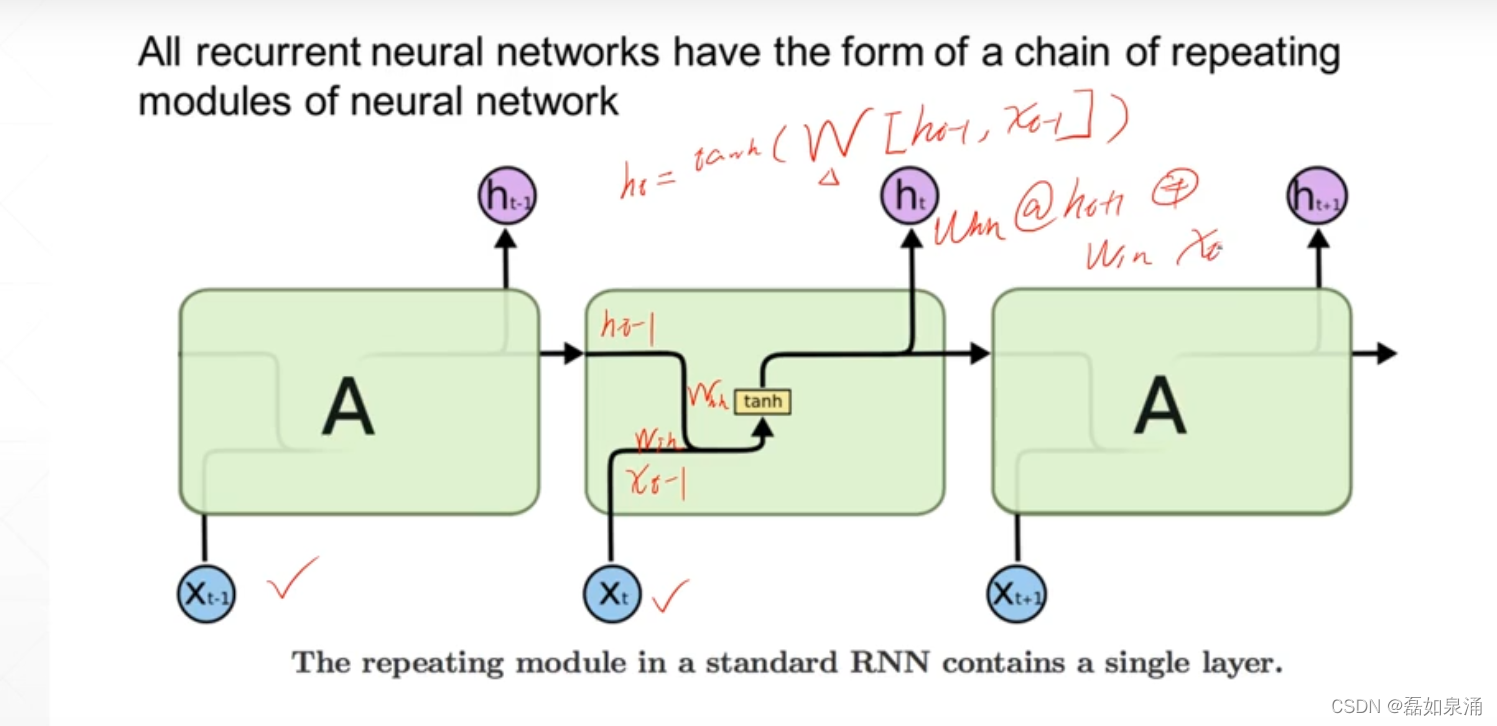
原始的RNN原理图
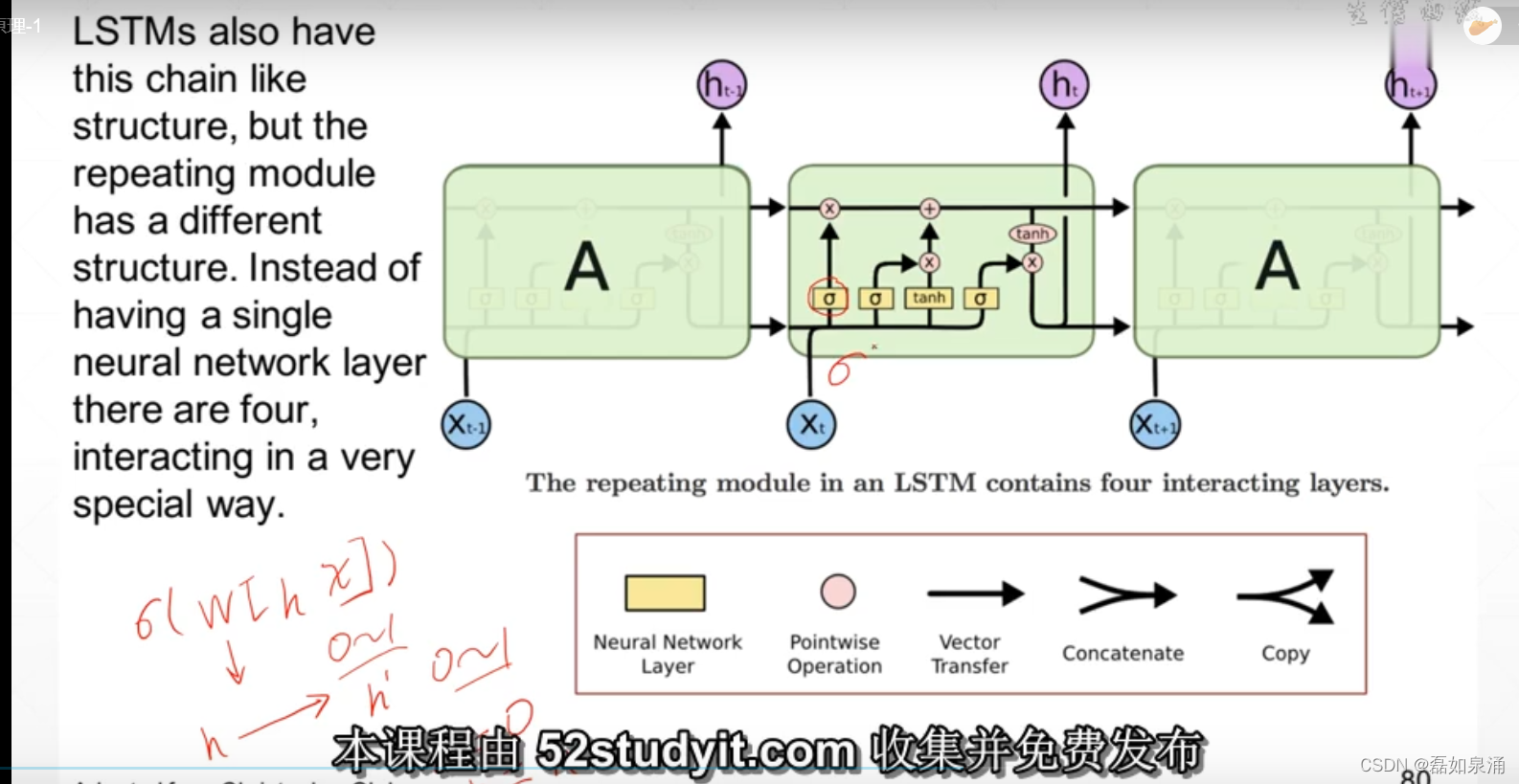
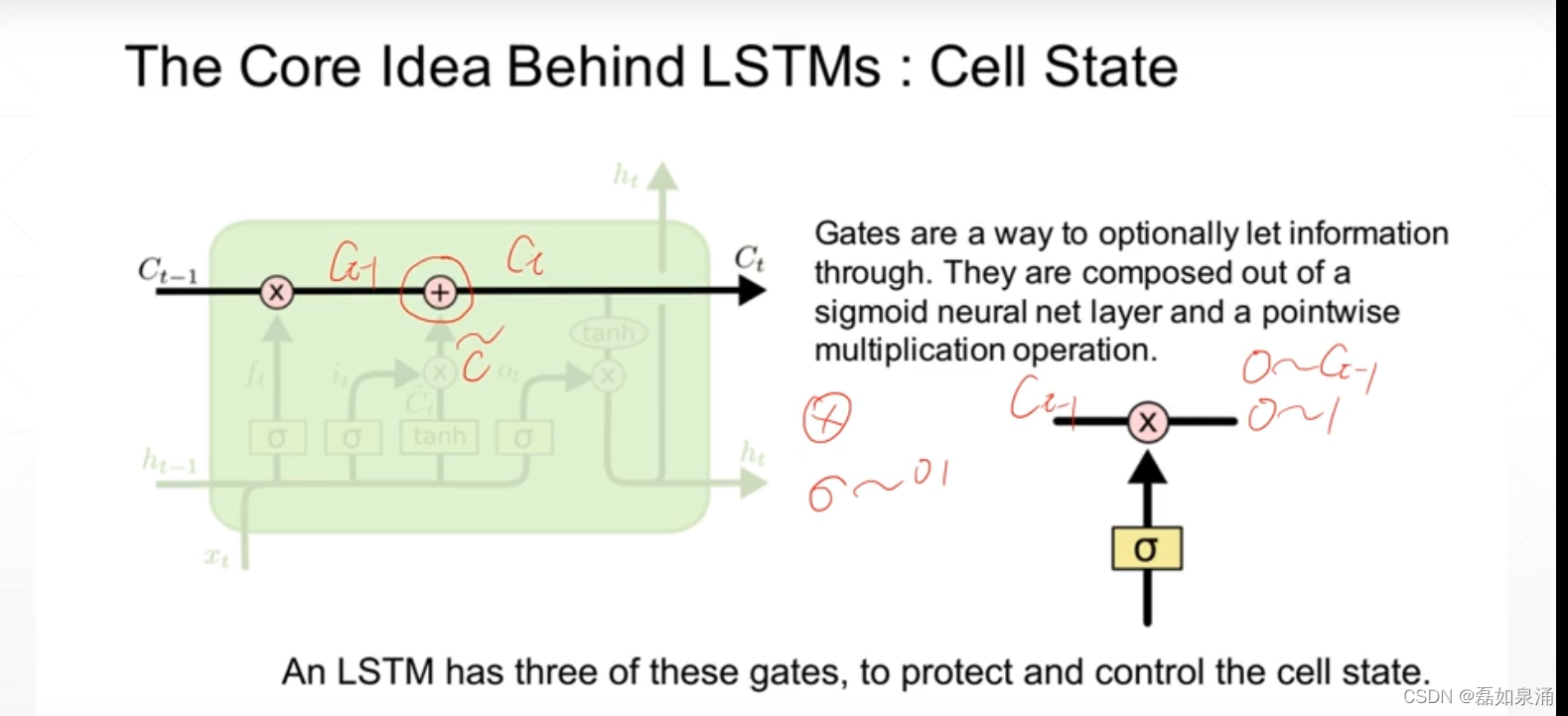
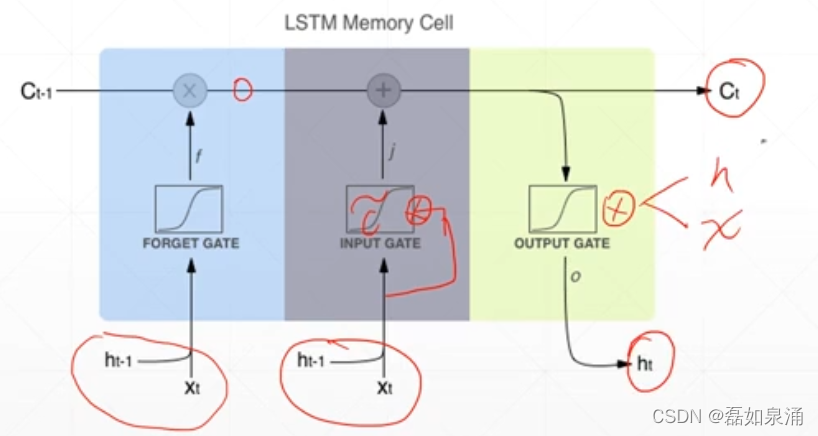
LSTM原理:设置了三道‘门’ 有代表sigmod即有一道“门”
第一道门:遗忘门
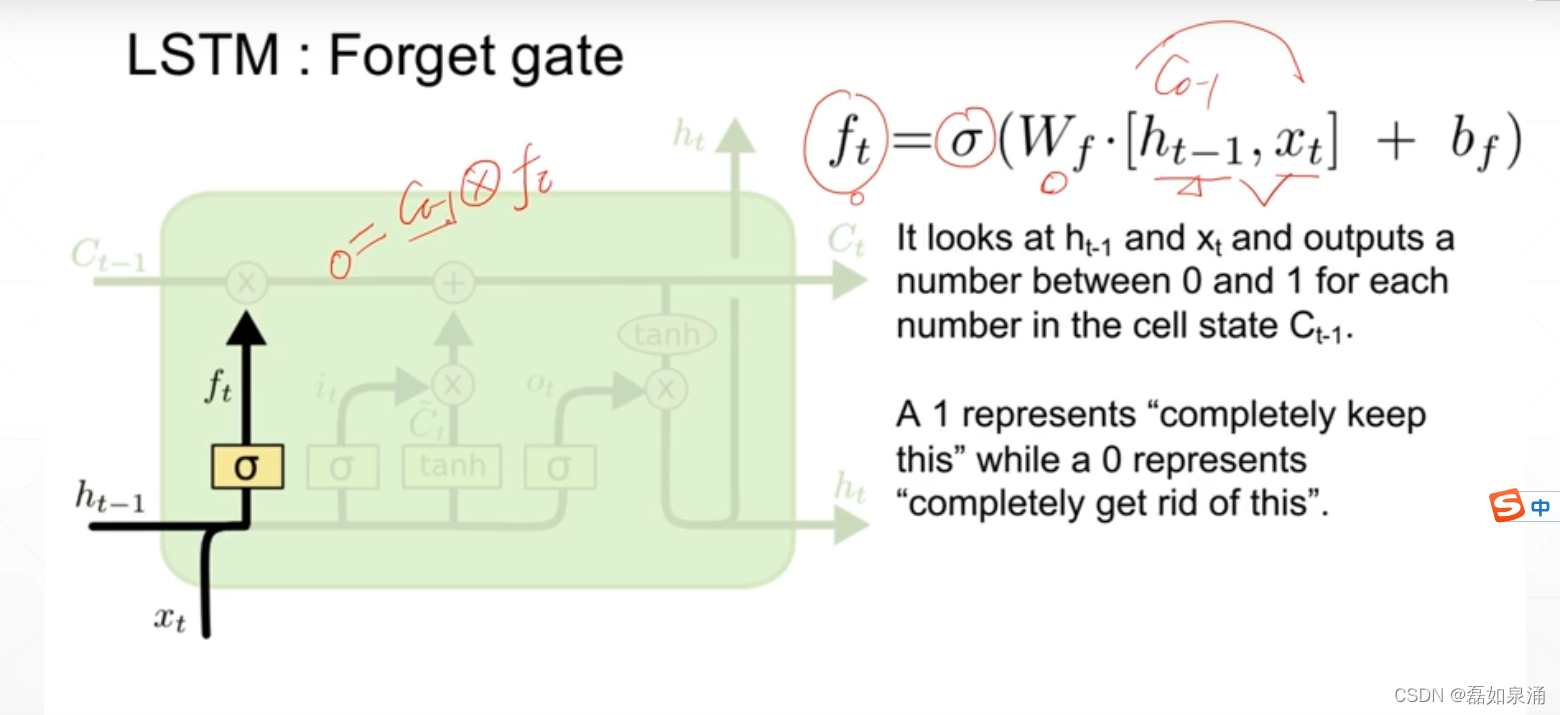
经过后
(代表开度)变为0-1,当等于0的时候代表全部遗忘,等于1代表全部记住。
第二道门:输入门
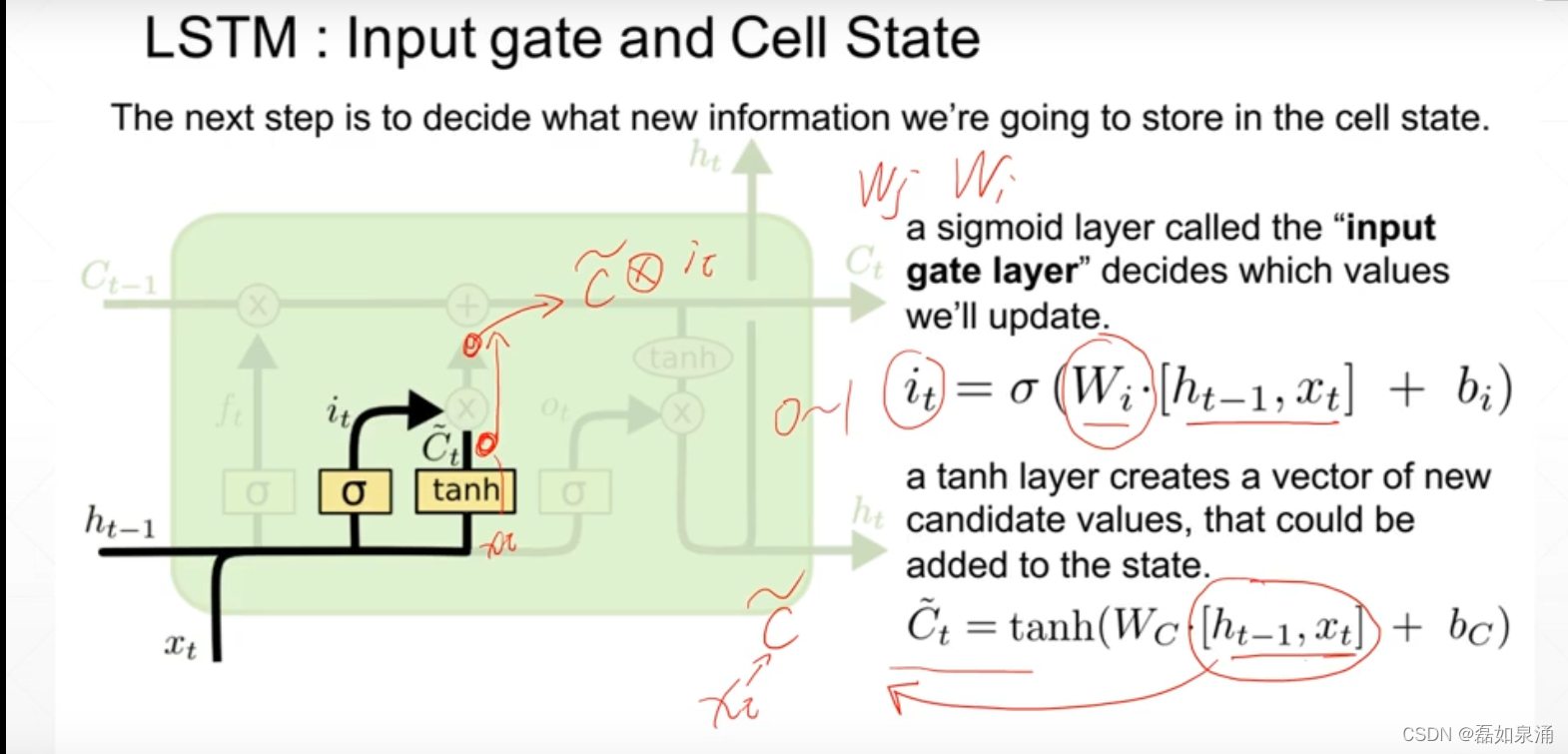
之后得到更新结果,也就是memory
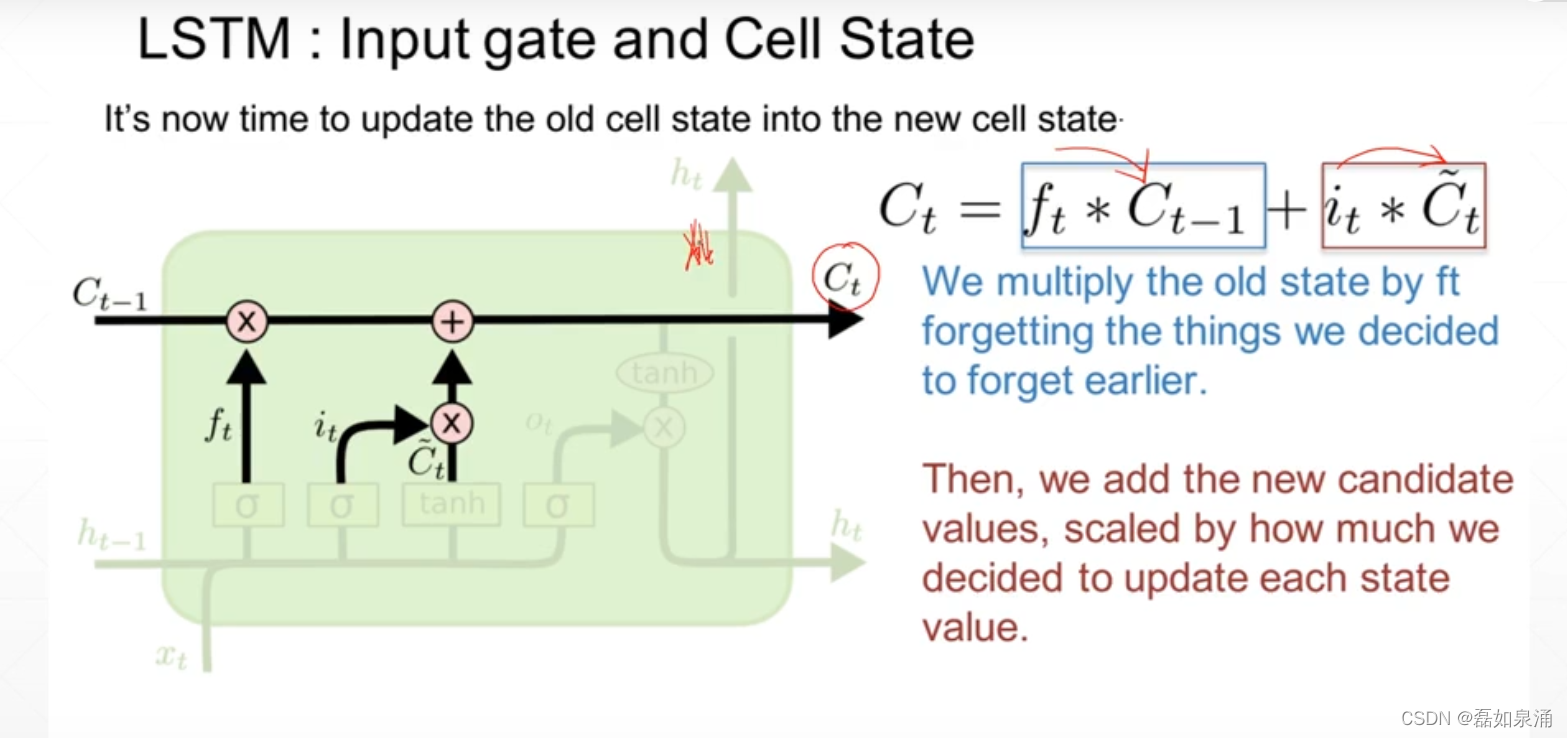
第三道门:输出门
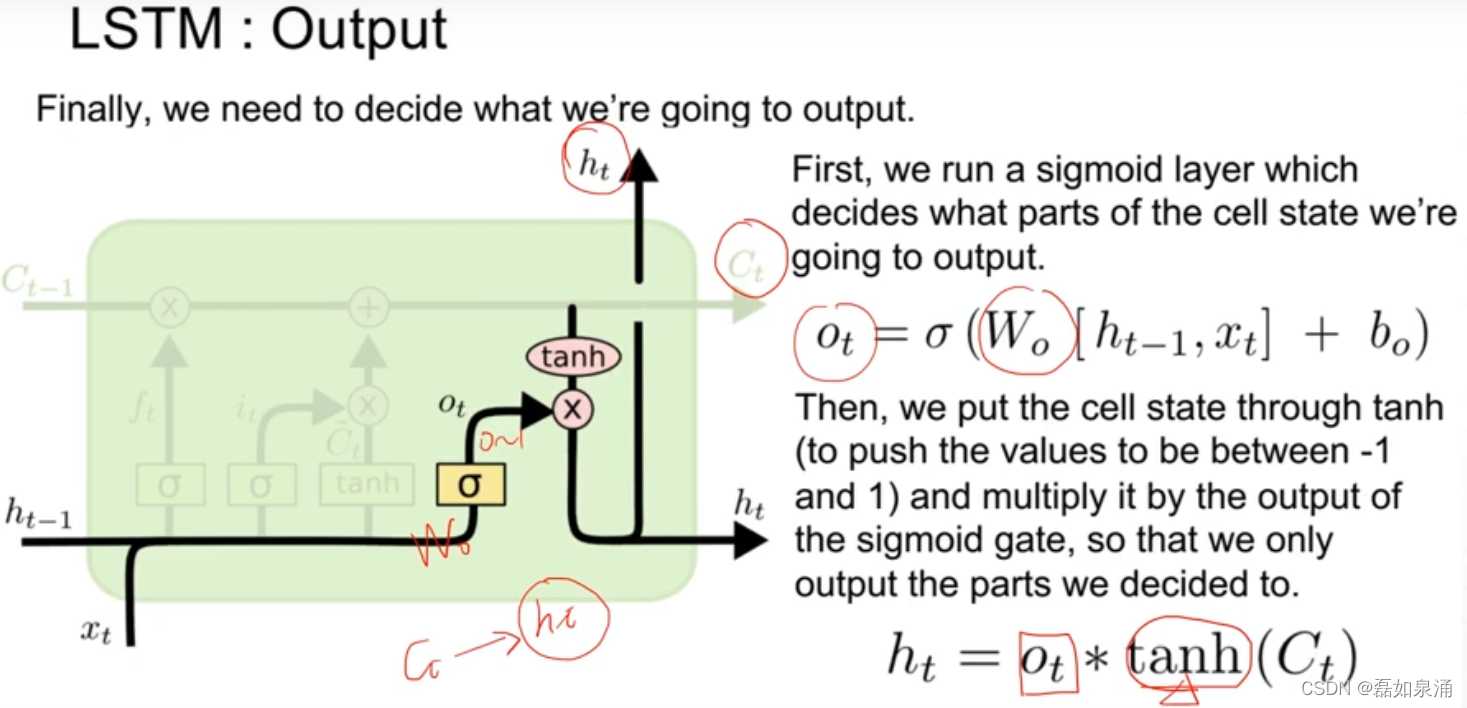
整体原理即
梯度弥散解决
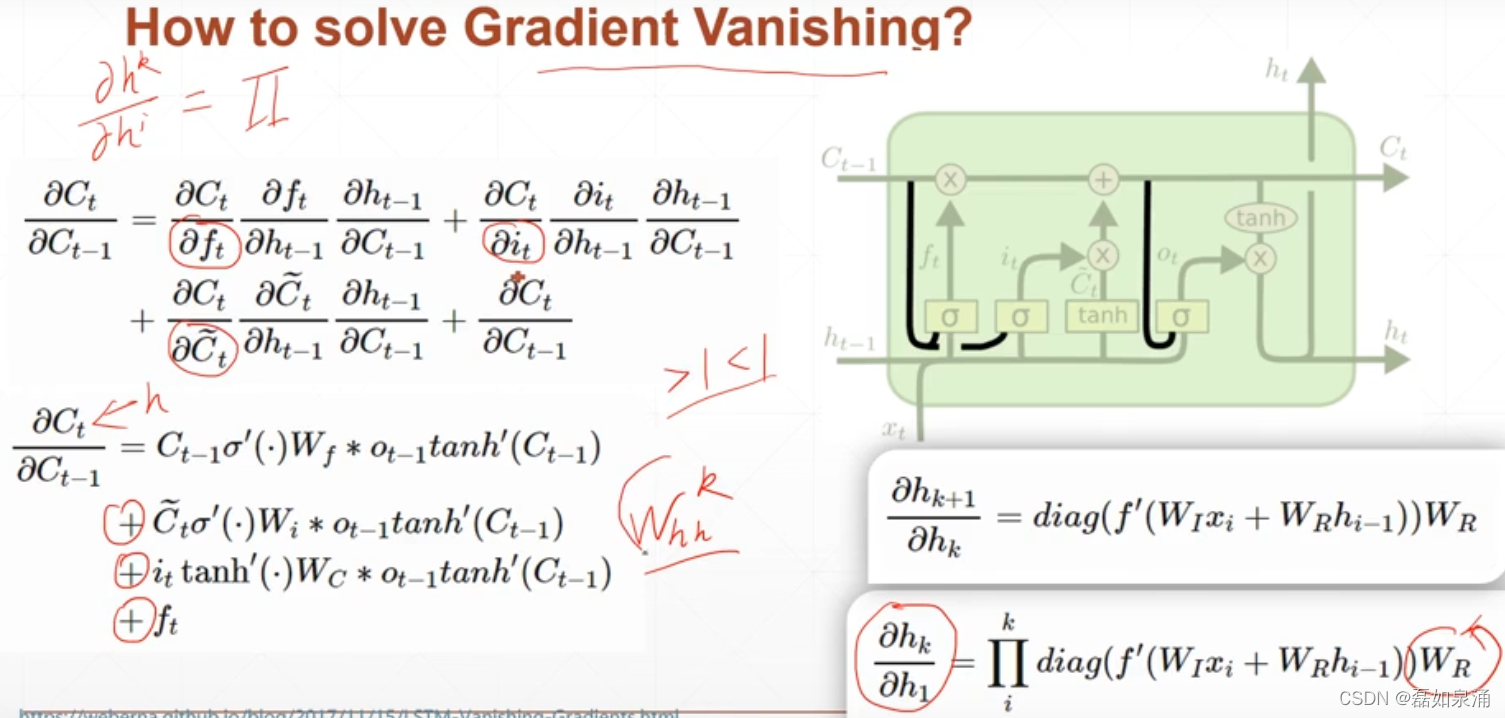
原来的RNN梯度计算如上图右下角,是一个累乘,容易出现小都小,大都大的情况(存在),当我们使用LSTM时,发现加法可以很好的避免梯度弥散现象。

















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









