







 根据《环境空气质量标准》,本文介绍了如何使用Python对空气质量进行模糊评价,涉及评判因子集、评价集、隶属函数的建立,以及权重因子的计算。通过超标加权法计算各因子权重,最终使用Flask框架在后端实现模糊综合评判算法,返回结果以JSON格式提供给前端展示。
根据《环境空气质量标准》,本文介绍了如何使用Python对空气质量进行模糊评价,涉及评判因子集、评价集、隶属函数的建立,以及权重因子的计算。通过超标加权法计算各因子权重,最终使用Flask框架在后端实现模糊综合评判算法,返回结果以JSON格式提供给前端展示。
- 建立评判因子集
根据《环境空气质量标准》(GB 3095—2012),主要空气污染物包括以下 6 项:二氧化氮(NO2)、一 氧化碳(CO)、二氧化硫(SO2)、臭氧(O3)、粒径小于或等于10 μm的颗粒物(PM10)、粒径小于或等于2.5μm的颗粒物(PM2.5)。因此,建立影响空气质量污染物所 对 应 的 因 子 集 :U ={u1,u2,u3,u4,u5,u6 }={SO2,NO2, CO,O3,PM10,PM2.5}。
- 建立评价集
结合《环境空气质量标准》(GB3095—2012)和上海市环境监测中心站检测污染物浓度的实际情况,建立四级评价集:
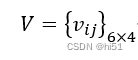
式中,i 表示空气质量评价因子,i=1,2,...,6;j 表示空气质量评价等级,j=1,2,...,4。
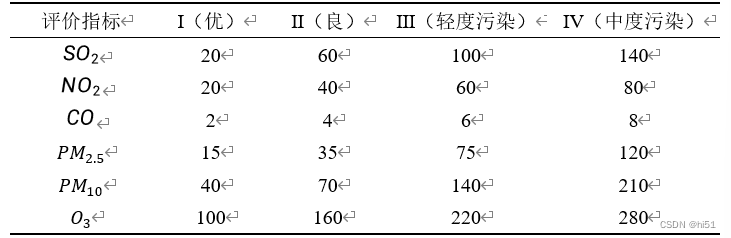
空气质量评价标准4个等级,Ⅰ(优)、Ⅱ(良)、Ⅲ(轻度污染)、Ⅳ(中度污染),具体见下表:
表格 1评价指标及浓度限差
- 建立隶属函数
采用降半阶梯形隶属度函数,建立评价因子对空气质量评价等级标准的隶属函数,从而建立模糊关系矩阵隶属度的计算公式如下:
当j=1时,
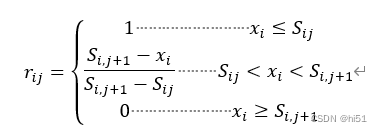
当j=2,3时,
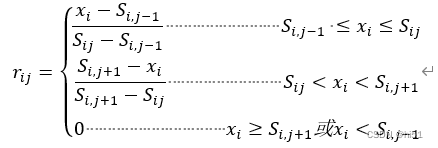
当j=4时,
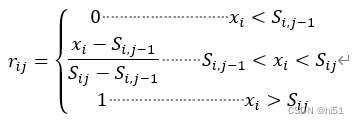
式(1)~(3)中,
xi为第i个评价因子的实测值;Sij为第i个评价因子的第j污染等级的浓度限值;rij为 第i个评价因子对第j污染等级的隶属度。将上海市某一天中的24小时数据进行均值化后代入到对应的隶属函数中,通过计算可得模糊关系矩阵R=[rij].
- 确定权重因子集合
空气质量评价中污染因子的权重是衡量各污染物对空气质量影响的重要程度,权重值越大,对空气质量影响越大,否则就越小。
模糊综合评判的赋权方法包括标准赋权法和主因素突出赋权法。每个评价因子对空气质量的影响都存在差异,对空气质量评价结果的影响也各不相同,所以要考虑每个评价因子在空气质量评价中所占的权重,采用超标加权法来计算每个评价因子的权重,通过归一化方法处理,得到权重集A={a1,a2,a3,a4,a5,a6}
其中权重系数的计算公式如下:
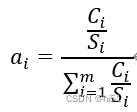
在该权重系数公式中,ai表示评价因子的权重,m表示评价因子的个数,Si表示空气质量等级及其对应评价因子的浓度限值的平均值,Ci表示标准的实测值。
将对应的数据代入到权重系数公式中,将可以得到权重集。
- 模糊综合评判
根据模糊矩阵和权重集的计算结果,可将A和R进行模糊矩阵的复合运算,可得:
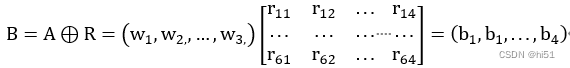
根据最大隶属度原则,取
![]()
作为空气质量模糊综合评价的结果。
- 后端实现代码
将上述模糊评价运行的步骤在后端利用Flask框架使用Python代码实现,并且将最终结果以json的格式返回,使得前端可以接收数据并且显示分析处理结果。
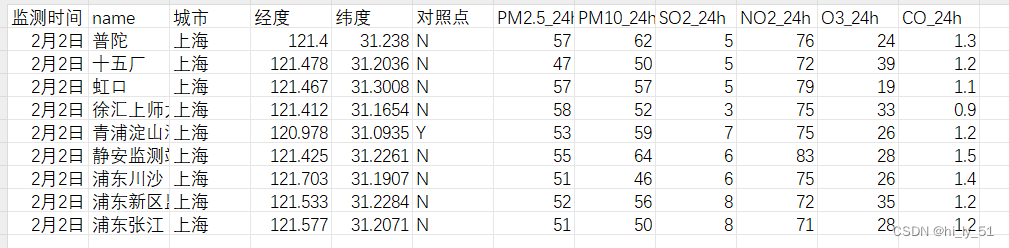
Excel表数据格式如下:
| from flask import Flask,request,jsonify,Response @app.route('/mohupj') |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









