







OutPutFormat是Reducer阶段结束,写入到文件的一个过程。也就是Reducer阶段结束后,并不是直接写入文件,需要通过OutPutFormat过程再写入文件。
(1)案例需求
过滤输入的 log
日志,包含
atguigu
的网站输出到
e:/atguigu.log
,不包含
atguigu 的网站输出到
e:/other.log
。(也就是给定一个数据集,输出多个数据集)
数据集内容:(log.txt)

(2)需求分析
输入数据就是log.txt。
输出数据就是
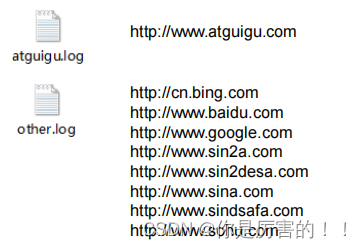
因为需要输出两个文件,所以就需要继承FileOutputFormat类重写RecordWriter方法,而重写的RecordWriter方法,需要返回一个RecordWriter对象,所以可以额外创建一个类继承RecordWriter类重写其中方法来写实现RecordWriter对象,也可以使用内部类创建RecordWriter对象。
(3)代码实现
创建的是maven项目。
其中pom.xml文件代码如下
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>1、Mapper类
package com.hadoop.mapreduce.outputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author codestart
* @create 2023-06-20 12:13
*/
public class logMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//Mapper阶段不需要做处理
context.write(value,NullWritable.get());
}
}
2、Reducer类
package com.hadoop.mapreduce.outputFormat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author codestart
* @create 2023-06-20 12:17
*/
public class logReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//一条一条写入
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
}
3、重写的OutputFormat类
package com.hadoop.mapreduce.outputFormat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author codestart
* @create 2023-06-20 18:15
*/
public class logOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
LogRecordWriter lrw = new LogRecordWriter(job);
return lrw;
}
}
4、重写RecordWrite类
package com.hadoop.mapreduce.outputFormat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
/**
* @author codestart
* @create 2023-06-20 18:20-m
*/
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream atguiguOut;
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) {
//创建两条流
try {
FileSystem fs = FileSystem.get(job.getConfiguration());
atguiguOut = fs.create(new Path("D:\\data\\output\\atguigu.log"));
otherOut = fs.create(new Path("D:\\data\\output\\other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
//获取一行内容
String s = key.toString();
//查看是否包含某个单词
if (s.contains("atguigu")) {
//写入
atguiguOut.writeBytes(s + "\n");
} else {
otherOut.writeBytes(s + "\n");
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
//关闭
IOUtils.closeStream(atguiguOut);
IOUtils.closeStream(otherOut);
}
}
5、Driver类
package com.hadoop.mapreduce.outputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author codestart
* @create 2023-06-20 19:01
*/
public class logDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1、获取job
Configuration conf = new Configuration();
Job job = new Job(conf);
//2、设置驱动jar位置
job.setJarByClass(logDriver.class);
//3、关联Map和Reudce
job.setMapperClass(logMapper.class);
job.setReducerClass(logReducer.class);
//4、设置Map的输出k-v
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//5、设置最终输出的K-V
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置outputformat
job.setOutputFormatClass(logOutputFormat.class);
//6、设置输入输出路径,虽然设置输出流的时候设置了输出路径,但是fileoutputformat
//要输出一个_SUCCESS 文件,所以在这还得指定一个输出目录。
FileInputFormat.setInputPaths(job, new Path("D:\\data\\input\\inputoutputformat"));
FileOutputFormat.setOutputPath(job, new Path("D:\\data\\output\\outputfile1"));
//7、提交任务
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
(4)预期效果和总结
预期效果
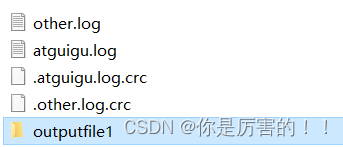
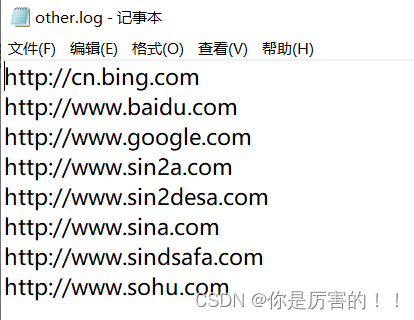

总结:以上是我通过网络学习,自己总结和练习的过程。一是为了防止自己忘记学过的知识,二是分享自己学习过程得到的结果,以此来发布博客。以上如有雷同,请联系本人!

















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









