






主要适用于 MYSQL 数据库,不过核心语句也通用于其他数据库。【依旧是B站戴戴戴师兄的视频。】
只学习 SQL 语句的查询语句部分,对于数据分析师而言完全足够~
主要使用资源:基础语法部分基于公开网站 sqlzoo 的 MySQL 数据库引擎。网址:https://sqlzoo.net/wiki/SQL_Tutorial
基础语法
SQL 运行原理
from -- where -- group by -- having -- order by -- limit -- select
- 执行 from 语句从数据库中调取复制一份表格
- 执行 where 语句在复制的表格中筛选出符合条件的数据行
- 执行 group by 语句依据指定字段对筛选后的数据分区,将依据的字段去重分组,相当于 Excel 建立了一个数据透视表,添加了行标签
- 执行 having 语句筛选满足条件的分组
- 执行 order by 语句对筛选后的数据进行排序
- 执行 limit 语句对排序后的数据限制显示的行
- 执行 select 语句,提取最后要显示的字段
一、select & from
- select 字段名:决定这一段查询最后展示的字段
- from 表名:指定这段查询语句涉及的数据来源(从哪里查找字段)
例题1:从单表中查询多列 select A,B,C from WORLD
- 在 select 后指定要查询的字段名称,多个字段名之间用英文逗号(,)隔开,最后一个字段名后不需要添加逗号
- select 和 from 关键字后不要忘记添加空格
- 查询结果的字段顺序是按照 select 后的字段名顺序显示的
- SQL 语句不区分大小写
- 需要同时查询多段表格,返回多个结果时,需要在查询语句最后添加分号(;)【很少见】
(*)通配符
例题2:select * from WORLD
- select 和星号(*)通配符联用返回查询表中所有列
- 返回的所有列的显示顺序按照原表中定义的顺序显示
as 别名
例题3:select name as 国家名,continent as 大洲,population as 人口 from world
- select 中,在字段名后加 as 别名,可以给字段名在最后显示前赋予别名(直接显示别名)
- 注意 as 前后加空格
- 这个别名不会修改该字段在数据库表中的原名,仅仅影响最后的显示
- as 可以省略,直接在代码中写成{字段名 别名}注意字段名和别名之间有空格,别名和下一个字段之间有英文逗号
select 中使用 distinct 去重
加 distinct 对重复的行数据进行去重
例题4:select (distinct) continent from world
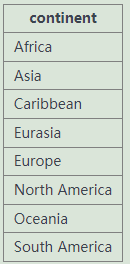

- 加了 distinct 只显示不同的数据一次
- distinct 紧跟在 select 后面,对后面的多个字段进行去重(无法对单一一个)
select 中计算字段的运用
例题6:查询国家名、gdp、人口及其人均gdp
select name,gdp,population,gdp/population 人均gdp from world
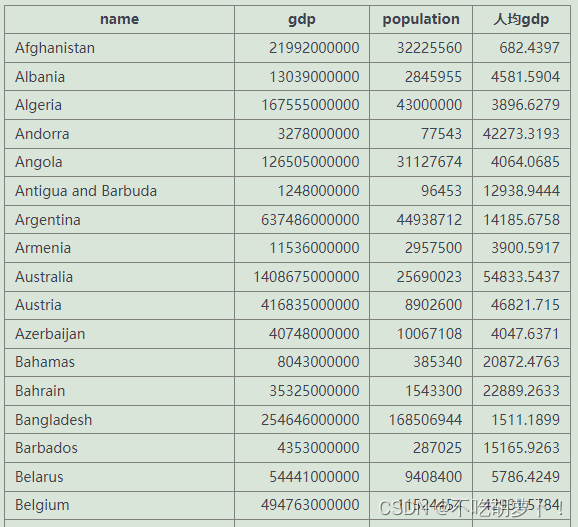
- 可以对数据库表中已有的字段进行计算形成新的字段
- 同理,加减乘除等简单数学运算都可以进行,字段值必须是数值才可以
- 也可以使用函数对字段进行处理,后续讲解
二、where
标准语法:[ where 表达式 ] 限定查询行必须满足的条件
- 文本需要用英文单引号('')包裹,数字不需要
运算符
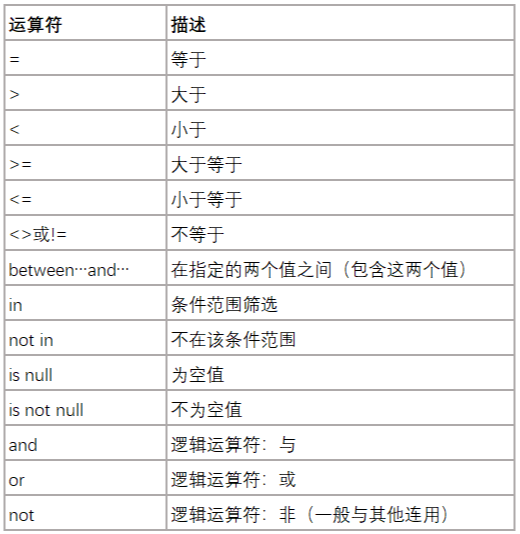
- =、>、<、>=、<=、<>、!= 为比较运算符,用于判断表中的哪些数据符合条件
- and、or 和 not 为逻辑运算符
- between and 用于查询两个值之间范围的值(包含这两个值)
- in 用于查询指定条件范围内的数据,一般为 in (xxx,xxx,......),用括号将条件括起来
- is null 用于查询空值(NULL),空值不同于0,也不同于null字符串
模糊查询 like
where子句的表达式中除了使用运算符来进行条件判断,还可以使用 like 操作符组合通配符进行模糊查询

多条件查询
使用and或者or逻辑运算符对多个条件进行组合筛选想要的数据
- and 的优先级高于 or ,会先运行 and 再运行 or
- 当有需要先运行 or 再运行 and 的条件时,使用括号()来标记优先运行的部分
- 同时在 and 和 or 联用时最好使用括号来标记优先运行的部分便于阅读代码,也避免条件逻辑出错
- 使用 between and 时如果想要去掉某个边界可以使用英文符号(!=)来去除
三、order by
标准语法:[ order by 字段名 asc|desc ]
- 默认为升序排序
- order by 关键字后可以加多个字段,依次按照字段顺序排序
order by XXX in ('A','B')
会给 in 括号内的内容会赋值 1,括号外的内容会赋值 0。因此排序是 in 括号内的内容在其他内容之后
四、limit
标准语法:[ limit [位置偏移量,]行数 ] 限制最终展现出多少行
- limit 子句是可选项,行数是子句中的必选参数,参数位置偏移量是可选参数
- limit n 表示返回结果的前 n 行;limit x,n 表示从 x+1 行开始返回 n 行
五、聚合函数 & group by
聚合函数
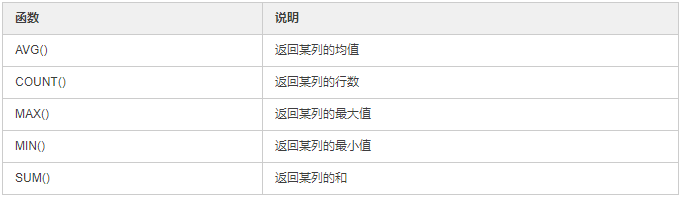
聚合函数适用于需要获取数据的汇总信息,例如某字段行数、某字段平均值、某字段中最大最小数等
例题20:查询非洲总人口数
select sum(population) from world where continent = 'Africa'
例题21:计算表格行数
select count(*) from world
- count (*) 计算表中的总行数,不管某列中是否有数值为空值
- count(字段名)计算指定字段下的总行数,但计算时将忽略空值的行
- 聚合函数也同样会忽略空值
group by
标准语法:[ group by 字段名1 ]
- group by 字段名规定依据哪个字段分组聚合
- group by 核心子句是可选项,使用该子句是为了依据相同字段值分组后进行聚合运算,常和聚合函数联用
- group by 与 distinct 的去重结果是一样的,但两者逻辑不同。distinct 仅仅是返回不同的行,group by 本质是先将指定的字段中相容的值分为一个区,再对字段进行去重分组
- 在 SQL 中使用 group by 会打破原表的结构,创建一张新表(类似于新的数据透视表)
- 使用 group by 子句时,select 只能使用聚合函数和 group by 引用过的字段,否则会报错 !!!
六、having & 简单运行原理
标准语法:[ having 表达式 ] 对group by分组后的数据进行筛选
例题26:查询总人口数量至少为1亿(100000000)的大洲
在分组聚合的基础上对数据进行筛选使用having子句,筛选出大洲人口数量至少为1亿的数据行
- 只有使用了 group by 子句后才会使用 having 子句,having 子句不能脱离 group by 子句单独使用,因为 having 子句本质上是对 group by 分组的筛选
- having 子句中只能使用聚合函数和 group by 作为分组依据的字段
- having 的表达式和 where 的表达式基本相同,但是 having 的表达式中可以使用聚合函数,where 的表达式中不可以,因为 where 是对原表中的行数据进行筛选,而 having 是对 group by 分组后的数据进行筛选
七、部分常见函数
【数学函数】
round(x,y) —— 四舍五入函数
- round 函数对 x 值进行四舍五入,精确到小数点后 y 位
- y 为负值时,保留小数点左边相应的位数为0,不进行四舍五入
例如:round(3.15,1) 返回 3.2,round(14.15,-1) 返回 10
【字符串函数】
concat(s1,s2,...) —— 连接字符串函数
- concat 函数返回连接参数 s1、s2 等产生的字符串
- 任一参数为 null 时,则返回 null
例如:concat('My',' ','SQL')返回My SQL,concat('My',null,'SQL')返回null(空格也需要加单引号)
replace(s,s1,s2) —— 替换函数
- replace 函数使用字符串 s2 代替 s 中所有的 s1
例如:replace('MySQLMySQL','SQL','sql')返回MysqlMysql
left(s,n)、right(s,n)&substring(s,n,len) —— 截取字符串一部分的函数
- left 函数返回字符串 s 最左边 n 个字符
- right 函数返回字符串 s 最右边 n 个字符
- substring 函数返回字符串 s 从第 n 个字符起取长度为 len 的子字符串,n 也可以为负值,则从倒数第 n 个字符起取长度为 len 的子字符串,没有 len 值则取从第 n 个字符起到最后一位(substring 中都是从左往右截取,只有 right 是从右往左的)
例如:left('abcdefg',3) 返回 abc,right('abcdefg',3) 返回 efg,substring('abcdefg',2,3) 返回bcd,substring('abcdefg',-2,3) 返回 fg,substring('abcdefg',2) 返回 bcdefg
【数据类型转换函数】
cast(x as type) —— 转换数据类型的函数
- cast 函数将一个类型的 x 值转换为另一个类型的值
- type 参数可以填写 char(n)、date、time、datetime、decimal 等转换为对应的数据类型
【日期时间函数】
year(date)、month(date)&day(date) —— 获取年月日的函数
- date 可以是年月日组成的日期,也可以是年月日时分秒组成的日期时间
- year(date) 返回日期格式中的年份
- month(date) 返回日期格式中的月份
- day(date) 返回年日期格式中的日份
例如:year('2021-08-03') 返回 2021,month('2021-08-03') 返回 8,day('2021-08-03') 返回 3
date_add(date,interval expr type)&date_sub(date,interval expr type) —— 对指定起始时间进行加减操作
- date 用来指定起始时间
- date 可以是年月日组成的日期,也可以是年月日时分秒组成的日期时间
- expr 用来指定从起始时间添加或减去的时间间隔
- type 指示 expr 被解释的方式,type 可以可以是以下值
主要使用红框中的值
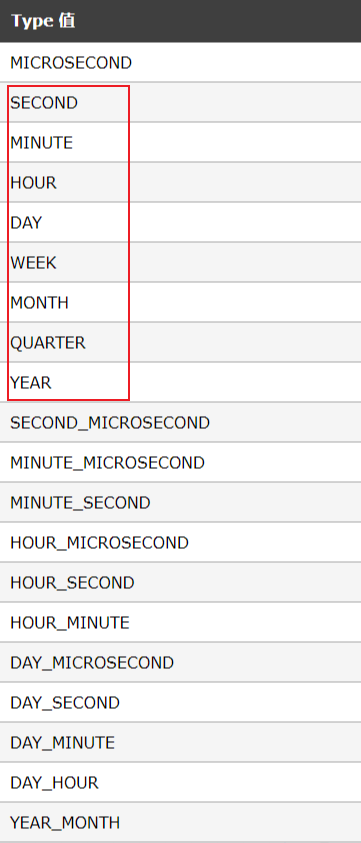
- date_add 函数对起始时间进行加操作,date_sub 函数对起始时间进行减操作
例如:date_add('2021-08-03 23:59:59',interval 1 second) 返回 2021-08-04 24:00:00,date_sub('2021-08-03 23:59:59',interval 2 month) 返回 2021-06-03 23:59:59
datediff(date1,date2) —— 计算两个日期之间间隔的天数
- datediff 函数由 date1-date2 计算出间隔的时间,只有 date 的日期部分参与计算,时间不参与
例如:datediff('2021-06-08','2021-06-01') 返回 7,datediff('2021-06-08 23:59:59','2021-06-01 21:00:00') 返回 7,datediff('2021-06-01','2021-06-08') 返回 -7
date_format(date,format) —— 将日期和时间格式化
- date_format 函数根据 format 指定的格式显示 date 值
- 可以换使用的格式有
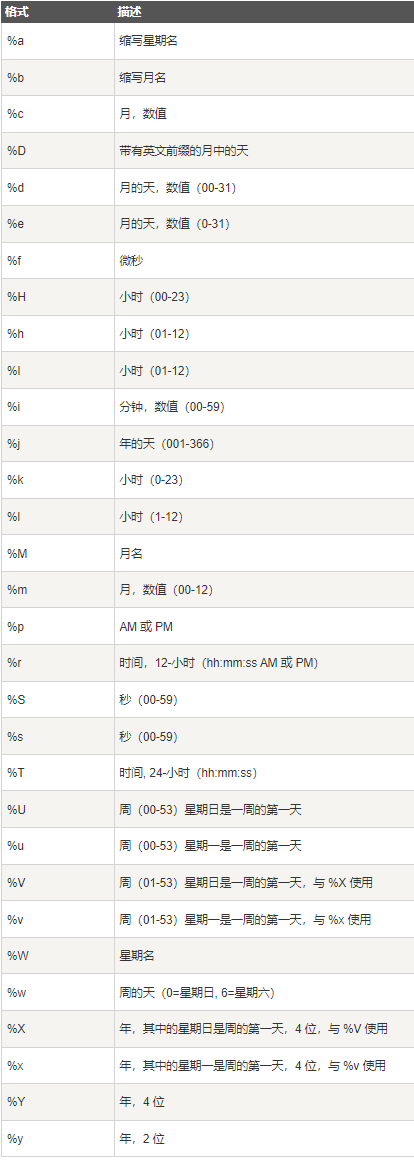
例如:date_format('2018-06-01 16:23:12','%b %d %Y %h:%i %p') 返回 Jun 01 2018 04:23 PM,date_format('2018-06-01 16:23:12','%Y/%d/%m') 返回 2018/01/06
【条件判断函数】——根据满足不同条件,执行相应流程
if(expr,v1,v2)
- 如果表达式 expr 是 true 返回值 v1,否则返回 v2
例如:if(1<2,'Y','N')返回Y,if(1>2,'Y','N')返回N
case when
- case expr when v1 then r1 [when v2 then r2] ...[else rn] end
例如:case 2 when 1 then 'one' when 2 then 'two' else 'more' end 返回 two
case 后面的值为 2,与第二条分支语句 when 后面的值相等相等,因此返回 two
- case when v1 then r1 [when v2 then r2]...[else rn] end
例如:case when 1<0 then 'T' else 'F' end返回 F
1<0的结果为 false,因此函数返回值为 else 后面的 F


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









