






import re
def cal_follow(s, productions, first):
# print("first 集合",first)
follow = set()
# if len(s) != 1:
# return {}
if (s == list(productions.keys())[0]):
follow.add('$')
for i in productions:
for j in range(len(productions[i])):
if (s in productions[i][j]):
idx = productions[i][j].index(s)
if (idx == len(productions[i][j]) - 1):
if (productions[i][j][idx] == i):
# break
continue
else:
f = cal_follow(i, productions, first)
for x in f:
follow.add(x)
else:
while idx != len(productions[i][j]) - 1:
idx += 1
if not productions[i][j][idx].isupper():
# print("终结符:",productions[i][j][idx])
follow.add(productions[i][j][idx])
# print("follow:",follow)
break
else:
# f = cal_first(productions[i][j][idx], productions)
f=first[productions[i][j][idx]]
# print("非终结符,找first")
# print("FIRST(",productions[i][j][idx],")=",f)
if ('ε' not in f):
# print("first无ε")
for x in f:
follow.add(x)
break
# print("first:",f)
# print("follow:", follow)
elif ('ε' in f and idx != len(productions[i][j]) - 1):
# print("first有ε,不在产生式最后")
# f.remove('ε')
for k in f:
if k=='ε':
continue
follow.add(k)
# print("follow:", follow)
elif ('ε' in f and idx == len(productions[i][j]) - 1):
# print("first有ε,在产生式最后")
# f.remove('ε')
for k in f:
if k=='ε':
continue
follow.add(k)
# print("follow:", follow)
f = cal_follow(i, productions, first)
# print("找产生式左侧的follow:",f)
for x in f:
follow.add(x)
# print("follow:", follow)
return follow
def cal_first(s, productions):
global flag
global temp
if flag==0:
temp=[]
flag=1
# print("flag:",flag)
# print(s)
# print(temp)
if s in temp:
# print("T")
return []
temp.append(s)
# print(len(temp))
# print(temp)
# print(s)
# print(productions)
first = set()
for i in range(len(productions[s])):
for j in range(0,len(productions[s][i])):
# print(len(productions[s][i]))
# print(productions[s][i])
c = productions[s][i][j]
# print(c)
if(c.isupper()):
f = cal_first(c, productions)
if('ε' not in f):
for k in f:
first.add(k)
break
else:
if (j == len(productions[s][i]) - 1):
for k in f:
first.add(k)
else:
f.remove('ε')
for k in f:
first.add(k)
else:
first.add(c)
break
return first
temp=[]
flag=0
def main():
global flag
global temp
productions = {}
grammar = open("grammar2.txt", "r",encoding="UTF-8")
# print(grammar)
first = {}
follow = {}
for prod in grammar:
# print(prod)
l = re.split("( /→/\n/)*", prod)
# print(l)
m = []
for i in l:
if (i == "" or i == None or i == '\n' or i == " " or i == "→"):
pass
else:
m.append(i)
# print(m)
left_prod = m.pop(0)
# print(m)
right_prod = []
t = []
for j in m:
if(j != '|'):
t.append(j)
else:
right_prod.append(t)
t = []
right_prod.append(t)
# print(right_prod)
productions[left_prod] = right_prod
for s in productions.keys():
# print("hhh")
# temp = []
flag=0
first[s] = cal_first(s, productions)
print("*****FIRST*****")
for lhs, rhs in first.items():
first[lhs]=rhs
print(lhs, ":" , rhs)
print("")
for lhs in productions:
follow[lhs] = set()
# print(first)
for s in productions.keys():
# print("------------------------------------------------------")
# print("FOLLOW ",s)
follow[s] = cal_follow(s, productions, first)
# print(s,end='')
# print(" ",end='')
# print(cal_follow(s, productions, first))
# follow[s] = cal_follow(s, productions)
print("*****FOLLOW*****")
for lhs, rhs in follow.items():
print(lhs, ":" , rhs)
# print(cal_follow('L',productions,first))
grammar.close()
if __name__ == "__main__":
main()
# →去年的编译原理实验作业
借鉴的是GitHub的代码,不过GitHub的代码是有问题的,没法应付老师的测试样例,所以我改了一部分内容,通过了老师的测试样例,不确定还有没有其他问题
grammar1.txt
S→A | a
A→Bc |ε
B→d |AS
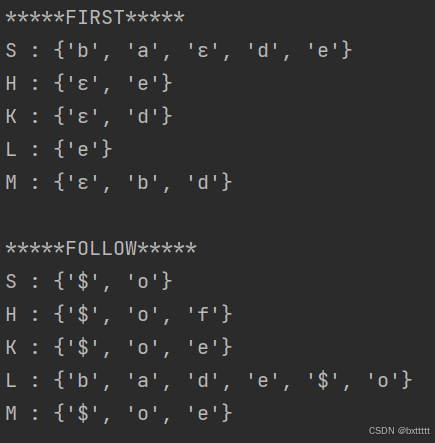
运行结果:

grammar2.txt
S→MH | a
H→LSo |ε
K→dML | ε
L→eHf
M→K | bLM运行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









