






前言:最近偶然翻看到了某大佬总结的优快云的C语言规范,这才想起来我也有这个原件,找了半天终于找到,放在某个U盘的角落已经吃土好长时间了,也鉴于个人的C语言编程水平规范性不是特别好,所以本着学习的心态打算再次学习并梳理一下华为的C语言编码规范,跟大家一起共勉。

引用文中大佬的话,很有道理。。。
“程序必须为阅读它的人而编写,只是顺便用于机器执行。”
------------------------HaroldAbelson和Gerald Jay
“编写程序应该以人为本,计算机第二。”
-------------------------Steve MeConnell
由于内容还是比较多的,建议先看目录,然后跳转到想学习与了解的内容中去,当然下面的10项是我筛选出来的比较重要的几点,其他还有诸如安全性与可测性等的,如果大家感兴趣可以去看看原件。。。
目录
2.4 每一个.c文件应有一个同名.h文件,用于声明需要对外公开的接口
2.8 总是编写内部#include保护符(#define保护)
2.10 只能通过包含头文件的方式使用其他.c提供的接口,禁止在.c中通过extern的方式使用外部函数接口、变量。
2.12 一个模块通常包含多个.c文件,建议放在同一个目录下,目录名即为模块名。为方便外部使用者,建议每一个模块提供一个.h,文件名为目录名。
2.13 如果一个模块包含多个子模块,则建议每一个子块提供一个对外的.h,文件名为子模块名。
2.15 同一产品统一包含头文件排列方式说明:常见的包含头文件排列方式:功能块排序、文件名升序、稳定度排序。
3.4 避免函数的代码块嵌套过深,新增函数的代码块嵌套不超过4层
3.5 可重入函数应避免使用共享变量;若需要使用,则应通过互斥手段(关中断、信号量)对其加以保护
3.6 对参数的合法性检查,由调用者负责还是由接口函数负责,应在项目组/模块内应统一规定。缺省由调用者负责。
3.11 函数应避免使用全局变量、静态局部变量和I/0操作,不可避免的地方应集中使用。
3.12 检查函数所有非参数输入的有效性,如数据文件、公共变量等
3.15 在源文件范围内声明和定义的所有函数,除非外部可见,否则应该增加static关键字
4.1.1 标识符的命名要清晰、明了,有明确含义,同时使用完整的单词或大家基本可以理解的缩写,避免使人产生误解。
4.1.2 除了常见的通用缩写以外,不使用单词缩写,不得使用汉语拼音
4.1.3 用正确的反义词组命名具有互斥意义的变量或相反动作的函数等
4.4 尽量避免名字中出现数字编号,除非逻辑上的确需要编号。
4.3.3 禁止使用单字节命名变量,但允许定义i、j、k作为局部循环变量
4.4.1 函数命名应以函数要执行的动作命名,一般采用动词或者动词+名词的结构。
4.5.1 对于数值或者字符串等等常量的定义,建议采用全大写字母,单词之间加下划线”’的方式命名(枚举同样建议使用此方式定义)
4.5.2 除了头文件或编译开关等特殊标识定义,宏定义不能使用下划线“”开头和结尾
5.7 构造仅有一个模块或函数可以修改、创建,而其余有关模块或函数只访问的全局变量,防止多个不同模块或函数都可以修改、创建同一全局变量的现象
5.8 使用面向接口编程思想,通过API访问数据:如果本模块的数据需要对外部模块开放,应提供接口函数来设置、获取,同时注意全局数据的访问互斥
5.9 在首次使用前初始化变量,初始化的地方离使用的地方越近越好
6.5 宏定义中尽量不使用return、goto、continue、break等改变程序流程的语句
7.3 在代码的功能、意图层次上进行注释,即注释解释代码难以直接表达的意图,而不是重复描述代码
7.4 修改代码时,维护代码周边的所有注释,以保证注释与代码的一致性。不再有用的注释要删除
7.5 文件头部应进行注释,注释必须列出:版权说明、版本号、生成日期、作者姓名、工号、内容、功能说明、与其它文件的关系、修改日志等,头文件的注释中还应有函数功能简要说明
7.6 函数声明处注释描述函数功能、性能及用法,包括输入和输出参数、函数返回值、可重入的要求等;定义处详细描述函数功能和实现要点,如实现的简要步骤、实现的理由、设计约束等
7.7 全局变量要有较详细的注释,包括对其功能、取值范围以及存取时注意事项等的说明
7.8 对于switch语句下的case语句,如果因为特殊情况需要处理完一个case后进入下一个case处理,必须在该case语句处理完、下一个case语句前加上明确的注释
7.10 注释应考虑程序易读及外观排版的因素,使用的语言若是中、英兼有的,建议多使用中文,除非能用非常流利准确的英文表达。对于有外籍员工的,由产品确定注释语言
7.11 文件头、函数头、全局常量变量、类型定义的注释格式采用工具可识别的格式
8.3 一条语句不能过长,如不能拆分需要分行写。一行到底多少字符换行比较合适,产品可以自行确定
8.4 多个短语句(包括赋值语句)不允许写在同一行内,即一行只写一条语句
8.5 if、for、do、while、case、switch、default等语句独占一行
8.6 在两个以上的关键字、变量、常量进行对等操作时,它们之间的操作符之前、之后或者前后要加空格:进行非对等操作时,如果是关系密切的立即操作符(如一>),后不应加空格。
8.7 注释符(包括'/*”//”“*/’)与注释内容之间要用一个空格进行分隔
9.1 表达式的值在标准所允许的任何运算次序下都应该是相同的
9.2 函数调用不要作为另一个函数的参数使用,否则对于代码的调试、阅读都不利
9.3 赋值语句不要写在if等语句中,或者作为函数的参数使用
10.1 使用编译器的最高告警级别,理解所有的告警,通过修改代码而不是降低告警级别来消除所有告警
10.2 在产品软件(项目组)中,要统一编译开关、静态检查选项以及相应告警清除策略
10.3 本地构建工具(如PC-Lint)的配置应该和持续集成的一致。
10.4 使用版本控制(配置管理)系统,及时签入通过本地构建的代码,确保签入的代码不会影响构建成功。
1,代码总体原则
1.1 清晰第一
清晰性是易于维护、易于重构的程序必需具备的特征。代码首先是给人读的,好的代码应当可以像文章一样发声朗诵出来。
目前软件维护期成本占整个生命周期成本的40%~90%。根据业界经验,维护期变更代码的成本,小型系统是开发期的5倍,大型系统(100万行代码以上)可以达到100倍。
业界的调查指出,开发组平均大约一半的人力用于弥补过去的错误,而不是添加新的功能来帮助公司提高竞争力。
1.2 简洁为美
简洁就是易于理解并且易于实现。代码越长越难以看懂,也就越容易在修改时引入错误。
写的代码越多,意味着出错的地方越多,也就意味着代码的可靠性越低。因此,我们提大家通过编写简洁明了的代码来提升代码可靠性。
废弃的代码(没有被调用的函数和全局变量)要及时清除,重复代码应该尽可能提炼成函数。
1.3 选择合适的风格
在公司已有编码规范的指导下,审慎地编排代码以使代码尽可能清晰,是一项非常重要的技能。如果重构/修改其他风格的代码时,比较明智的做法是根据现有代码的现有风格继续编写代码,或者使用格式转换工具进行转换。
2,头文件
依赖:本章节特指编译依赖。若x.h包含了y.h,则称作x依赖y。依赖关系会进行传导,如x.h包含y.h,y.h又包含了z.h,则x通过y依赖了z。
依赖将导致编译时间的上升。虽然依赖是不可避免的,也是必项的,但是不良的设计会导致整个系统的依赖关系无比复杂,使得任意一个文件的修改都要重新编译整个系统,导致编译时间巨幅上升。
三个大体上的原则
2.1 头文件中适合放置接口的声明,不适合放置实现
说明:头文件是模块(Module)或单元(Unit)的对外接口。头文件中应放置对外部的声明,如对外提供的函数声明、宏定义、类型定义等。
- 内部使用的函数(相当于类的私有方法)声明不应放在头文件中。
- 内部使用的宏、枚举、结构定义不应放入头文件中。
- 变量定义不应放在头文件中,应放在.c文件中。
- 变量的声明尽量不要放在头文件中,亦即尽量不要使用全局变量作为接口。
变量是模块或单元的内部实现细节,不应通过在头文件中声明的方式直接暴露给外部,应通过函数接口的方式进行对外暴露。即使必须使用全局变量,也只应当在.c中定义全局变量,在.h中仅声明变量为全局的。
2.2 头文件应当职责单一
说明:头文件过于复杂,依赖过于复杂是导致编译时间过长的主要原因。很多现有代码中头文件过大,职责过多,再加上循环依赖的问题,可能导致为了在.c中使用一个宏,而包含十几个头文件。
下面有个示例:
#include <VXWORKS.H>
#include <KERNELLIB.H>
#include <SEMLIB.H>
#include <INTLIB.H>
#include:<TASKLIB.H)
#include<MSGQLIB.H>
#include<STDARG.H>
#include <FI0LIB.H>
#include <STDI0.H>
#include:<STDLIB.H>
#includee <CTYPE.H>
#include<STRING.H>
#include:<ERRNOLIB.H>
#include <TIMERS.H>
#include <MEMLIB.H>
<TIME.H>#include
#include<WDLIB. H>
#include<SYSLIB.H>
#include <REBOOTLIB.H>
typedef unsigned short WORD;这个头文件不但定义了基本数据类型WORD,还包含了stdio.h syslib.h等等不常用的头文件。如果工程中有10000个源文件,而其中100个源文件使用了stdio.h的printf,由于上述头文件的职责过于庞大,而WORD又是每一个文件必须包含的,从而导致stdio.h/syslib.h等可能被不必要的展开了9900次,大大增加了工程的编译时间。
2.3 头文件应向稳定的方向包含
说明: 头文件的包含关系是一种依赖,一般来说,应当让不稳定的模块依赖稳定的模块,从而当不稳定的模块发生变化时,不会影响(编译)稳定的模块。就我们的产品来说,依赖的方向应该是:产品依赖于平台,平台依赖于标准库。某产品线平台的代码中已经包含了产品的头文件,导致平台无法单独编译、发布和测试,是一个非常糟糕的反例。除了不稳定的模块依赖于稳定的模块外,更好的方式是两个模块共同依赖于接口,这样任何一个模块的内部实现更改都不需要重新编译另外一个模块。在这里,我们假设接口本身是最稳定的。
几个具体一点的规则
2.4 每一个.c文件应有一个同名.h文件,用于声明需要对外公开的接口
说明: 如果一个.c文件不需要对外公布任何接口,则其就不应当存在,除非它是程序的入口,如main函数所在的文件。
2.5 禁止头文件循环依赖
说明: 头文件循环依赖,指a.h包含b.h,b.h包含c.h,c.h包含a.h之类导致任何一个头文件修改,都导致所有包含了a.h/b.h/c.h的代码全部重新编译一遍。而如果是单向依赖,如a.h包含b.h,b.h包含c.h,而c.h不包含任何头文件,则修改a.h不会导致包含了b.h/c.h的源代码重新编译。
2.6 .c/.h文件禁止包含用不到的头文件
说明: 很多系统中头文件包含关系复杂,开发人员为了省事起见,可能不会去一一钻研,直接包含一切想到的头文件,甚至有些产品干脆发布了一个god.h,其中包含了所有头文件,然后发布给各个项目组使用,这种只图一时省事的做法,导致整个系统的编译时间进一步恶化,并对后来人的维护造成了巨大的麻烦。
2.7 头文件应当自包含
说明: 简单的说,自包含就是任意一个头文件均可独立编译。如果一个文件包含某个头文件,还要包含另外一个头文件才能工作的话,就会增加交流障碍,给这个头文件的用户增添不必要的负担。
2.8 总是编写内部#include保护符(#define保护)
说明: 多次包含一个头文件可以通过认真的设计来避免。如果不能做到这一点,就需要采取阻止头文件内容被包含多于一次的机制。通常的手段是为每个文件配置一个宏,当头文件第一次被包含时就定义这个宏,并在头文件被再次包含时使用它以排除文件内容。
参考如下示例:
#ifndef VOS_INCLUDE_TIMER_TIMER_H
#define VOS_INCLUDE_TIMER_TIMER_H
...
#endif
//也可以使用如下简单方式保护:
#ifndef TIMER_H
#define TIMER_H
...
#endif2.9 禁止在头文件中定义变量。
说明: 在头文件中定义变量,将会由于头文件被其他.c文件包含而导致变量重复定义。
2.10 只能通过包含头文件的方式使用其他.c提供的接口,禁止在.c中通过extern的方式使用外部函数接口、变量。
说明:若a.c使用了b.c定义的foo()函数,则应当在b.h中声明extern int foo(int input);并在a.c中通过#include<b.h>来使用foo。禁止通过在a.c中直接写extern int foo(int input);来使用foo,后面这种写法容易在foo改变时可能导致声明和定义不一致。
2.11 禁止在extern“C"中包含头文件。
说明:在extern"C"中包含头文件,会导致extern"C"嵌套,Visual Studio对extern"c”嵌套层次有限制,嵌套层次太多会编译错误。
在extern“c"中包含头文件,可能会导致被包含头文件的原有意图遭到破坏。
错误示例:
#ifndef B_H
#define B_H
#ifdef __cplusplus
extern "C" {
#endif
#include "a. h"
#ifdef __cplusplus
}
#endif
#endif/*BH*/几个比较实用的建议
2.12 一个模块通常包含多个.c文件,建议放在同一个目录下,目录名即为模块名。为方便外部使用者,建议每一个模块提供一个.h,文件名为目录名。
说明:需要注意的是,这个,h并不是简单的包含所有内部的.h,它是为了模块使用者的方便,对外整体提供的模块接口。
2.13 如果一个模块包含多个子模块,则建议每一个子块提供一个对外的.h,文件名为子模块名。
说明:降低接口使用者的编写难度。
2.14 头文件不要使用非习惯用法的扩展名,如.inc
2.15 同一产品统一包含头文件排列方式说明:常见的包含头文件排列方式:功能块排序、文件名升序、稳定度排序。
示例1:以升序方式排列头文件可以避免头文件被重复包含,如:
#include<a.h>
#include <b.h>
#include <e/d.h>
#include <c/e.h>
#include <f.h>3,函数
函数设计的精髓: 编写整洁函数,同时把代码有效组织起来
原则说明
3.1 一个函数仅完成一件功能
说明: 一个函数实现多个功能给开发、使用、维护都带来很大的困难。将没有关联或者关联很弱的语句放到同一函数中,会导致函数职责不明确,难以理解,难以测试和改动。
3.2 重复代码应该尽可能提炼成函数
说明: 重复代码提炼成函数可以带来维护成本的降低。
具体规则列举
3.3 避免函数过长,新增函数不超过50行(非空非注释行)
说明: 本规则仅对新增函数做要求,对已有函数修改时,建议不增加代码行。
3.4 避免函数的代码块嵌套过深,新增函数的代码块嵌套不超过4层
说明: 本规则仅对新增函数做要求,对已有的代码建议不增加嵌套层次。函数的代码块嵌套深度指的是函数中的代码控制块(例如:if、for、while、switch等)之间互相包含的深度。每级嵌套都会增加阅读代码时的脑力消耗,因为需要在脑子里维护一个“栈”(比如,进入条件语句、进入循环……)。应该做进一步的功能分解,从而避免使代码的阅读者一次记住太多的上下文。
3.5 可重入函数应避免使用共享变量;若需要使用,则应通过互斥手段(关中断、信号量)对其加以保护
说明: 可重入函数是指可能被多个任务并发调用的函数。在多任务操作系统中,数具有可重入性是多个任务可以共用此函数的必要条件。共享变量指的全局变量和static变量。编写C语言的可重入函数时,不应使用static局部变量,否则必须经过特殊处理,才能使函数具有可重入性。
3.6 对参数的合法性检查,由调用者负责还是由接口函数负责,应在项目组/模块内应统一规定。缺省由调用者负责。
说明: 对于模块问接口函数的参数的合法性检香这一问题,往往有两个极端现象,即:要么是调用者和被调用者对参数均不作合法性检查,结果就遗漏了合法性检查这一必要的处理过程,造成问题隐患,要么就是调用者和被调用者均对参数进行合法性检查,这种情况虽不会造成问题,但产生了冗余代码,降低了效率。
3.7 对函数的错误返回码要全面处理
说明: 一个函数(标准库中的函数/第三方库函数/用户定义的函数)能够提供一些指示错误发生的方法。这可以通过使用错误标记、特殊的返回数据或者其他手段,不管什么时候函数提供了这样的机制,调用程序应该在函数返回时立刻检查错误指示。
3.8 设计高扇入,合理扇出(小于7)的函数
说明: 扇出是指一个函数直接调用(控制)其它函数的数目,而扇入是指有多少上级函数调用它。
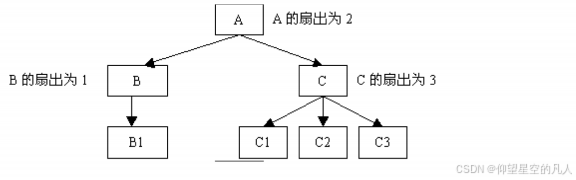
3.9 废弃代码(没有被调用的函数和变量)要及时清除
说明: 程序中的废弃代码不仅占用额外的空间,而且还常常影响程序的功能与性能,很可能给程序的测试、维护等造成不必要的麻烦。
几个函数方面的建议
3.10 函数不变参数使用const
说明: 不变的值更易于理解/跟踪和分析,把const作为默认选项,在编译时会对其进行检查,使代码更牢固/更安全。
3.11 函数应避免使用全局变量、静态局部变量和I/0操作,不可避免的地方应集中使用。
说明: 带有内部“存储器”的函数的功能可能是不可预测的,因为它的输出可能取决于内部存储器(如某标记)的状态。这样的函数既不易于理解又不利于测试和维护。在C语言中,函数的static局部变量是函数的内部存储器,有可能使函数的功能不可预测,然而,当某函数的返回值为指针类型时,则必须是static的局部变量的地址作为返回值,若为auto类,则返回为错针。
3.12 检查函数所有非参数输入的有效性,如数据文件、公共变量等
说明: 函数的输入主要有两种:一种是参数输入;另一种是全局变量、数据文件的输入,即非参数输入。函数在使用输入参数之前,应进行有效性检查。
如下示例:
hr = root_node->get_first_child(&log item); //list.xml 为空,导致读出log item为空ntne 4
hr = log_item->get_next_sibling(&media_next_node); // log item为空,导致宕机
// 正确写法:确保读出的内容非空。
hr = root_node->get_first_child(&log_item);
B Nif(log_item == NULL)//确保读出的内容非空
return retValue;
hr = log_item->get_next_sibling(&media_next_node);3.13 函数的参数个数不超过5个
说明: 函数的参数过多,会使得该函数易于受外部(其他部分的代码)变化的影响,从而影响维护工作。函数的参数过多同时也会增大测试的工作量。函数的参数个数不要超过5个,如果超过了建议拆分为不同函数。
3.14 除打印类函数外,不要使用可变长参函数
说明:可变长参函数的处理过程比较复杂容易引入错误,而且性能也比较低,使用过多的可变长参函数将导致函数的维护难度大大增加。
3.15 在源文件范围内声明和定义的所有函数,除非外部可见,否则应该增加static关键字
说明:如果一个函数只是在同一文件中的其他地方调用,那么就用static声明。使用static确保只是在声明它的文件中是可见的,并且避免了和其他文件或库中的相同标识符发生混淆的可能性。建议定义一个STATIC宏,在调试阶段,将STATIC定义为static,版本发布时,改为空,以便于后续的打热补丁等操作
4,标识符命名与定义
实际上,各种风格都有其优势也有其劣势,而且往往和个人的审美观有关。我们对标识符定义主要是为了让团队的代码看起来尽可能统一,有利于代码的后续阅读和修改,产品可以根据自己的实际需要指定命名风格,规范中不再做统一的规定。
(1)通用命名规则
4.1.1 标识符的命名要清晰、明了,有明确含义,同时使用完整的单词或大家基本可以理解的缩写,避免使人产生误解。
说明: 尽可能给出描述性名称,不要节约空间,让别人很快理解你的代码更重要。
示例如下:
//好的命名:
int error number;
int number of completed connection;
//不好的命名:使用模糊的缩写或随意的字符:
int n;
int nerr;
int ncomp conns;4.1.2 除了常见的通用缩写以外,不使用单词缩写,不得使用汉语拼音
说明: 较短的单词可通过去掉“元音”形成缩写,较长的单词可取单词的头儿个字母形成缩写,一些单词有大家公认的缩写,常用单词的缩写必须统一。协议中的单词的缩写与协议保持一致。对于某个系统使用的专用缩写应该在注视或者某处做统一说明。

上几条比较好的建议
4.1.3 用正确的反义词组命名具有互斥意义的变量或相反动作的函数等
示例:
insert/delete
increment/decrement
lock/unlock
old/new
source/target
source/destination
begin/end
create/destroy
first/last
put/get
open/close
start/stop
show/hide
copy/paste
get/release
add/delete
min/max
next/previous
send/receive
up/down
4.4 尽量避免名字中出现数字编号,除非逻辑上的确需要编号。
示例:如下命名,使人产生疑惑。
#define EXAMPLE_O_TEST
#define EXAMPLE_1_TEST
//应改为有意义的单词命名
#define EXAMPLE_UNIT_TEST
#define EXAMPLE_ASSERT_TEST(2) 文件命名规则
-
文件命名统一采用小写字符。
说明: 因为不同系统对文件名大小写处理会不同(如MS的D0S、Windows系统不区分大小写,但是Linux系统则区分),所以代码文件命名建议统一采用全小写字母命名。
(3)变量命名规则
4.3.1 全局变量应增加“g_”前缀
4.3.2 静态变量应增加“s_”前缀
4.3.3 禁止使用单字节命名变量,但允许定义i、j、k作为局部循环变量
4.3.3 使用名词或者形容词+名词方式命名变量
(4) 函数命名规则
4.4.1 函数命名应以函数要执行的动作命名,一般采用动词或者动词+名词的结构。
4.4.2 函数指针除了前缀,其他按照函数的命名规则命名。
(5) 宏的命名规则
4.5.1 对于数值或者字符串等等常量的定义,建议采用全大写字母,单词之间加下划线”’的方式命名(枚举同样建议使用此方式定义)
4.5.2 除了头文件或编译开关等特殊标识定义,宏定义不能使用下划线“”开头和结尾
说明: 一般来说,’开头、结尾的宏都是一些内部的定义
5,变量
5.1 一个变量只有一个功能,不能把一个变量用作多种用途
说明: 一个变量只用来表示一个特定功能,不能把一个变量作多种用途,即同一变量取值不同时,其代表的意义也不同
5.2 结构功能单一;不要设计面面俱到的数据结构
说明: 相关的一组信息才是构成一个结构体的基础,结构的定义应该可以明确的描述一个对象,而不是一组相关性不强的数据的集合。设计结构时应力争使结构代表一种现实事务的抽象,而不是同时代表多种。结构中的各元素应代表同一事务的不同侧面,而不应把描述没有关系或关系很弱的不同事务的元素放到同一结构中。
示例:如下结构
typedef struct STUDENT STRU
unsigned char name[32];/* student's name */
unsigned char age;/* student's age */
unsigned char sex;/*student's sex, as follows */
/*0-FEMALE:1-MALE*/unsigned char teacher name[32];/* the student teacher's name */unsigned char teacher sex;/* his teacher sex */
}STUDENT;
// 若改为如下,会更合理些。
typedef struct TEACHER STRU
unsigned char name[32];/*teacher name */unsigned char sex:/* teacher sex, as follows *//*0-FEMALE:1-MALE */
unsigned int teacher ind;/* teacher index */
}TEACHER;
typedef struct STUDENT {
unsigned char name[32];/* student's name */unsigned char age;/* student's age */unsigned char sex;/* student's sex, as follows *//*0-FEMALE:1-MALE */
unsigned int teacher;/* his teacher index */
}STUDENT;5.3 不用或者少用全局变量
说明: 单个文件内部可以使用static的全局变量,可以将其理解为类的私有成员变量。全局变量应该是模块的私有数据,不能作用对外的接口使用,使用static类型定义,可以有效防止外部文件的非正常访问,建议定义一个STATIC宏,在调试阶段,将STATIC定义为static,版本发布时,改为空,以便于后续的打补丁等操作。
5.4 防止局部变量与全局变量同名
说明: 尽管局部变量和全局变量的作用域不同而不会发生语法错误,但容易使人误解。
5.5 通讯过程中使用的结构,必须注意字节序
5.6 严禁使用未经初始化的变量作为右值。
说明: 坚持建议(在首次使用前初始化变量,初始化的地方离使用的地方越近越好)可以有效避免未初始化错误。
5.7 构造仅有一个模块或函数可以修改、创建,而其余有关模块或函数只访问的全局变量,防止多个不同模块或函数都可以修改、创建同一全局变量的现象
说明: 降低全局变量耦合度。
5.8 使用面向接口编程思想,通过API访问数据:如果本模块的数据需要对外部模块开放,应提供接口函数来设置、获取,同时注意全局数据的访问互斥
说明: 避免直接暴露内部数据给外部模型使用,是防止模块间耦合最简单有效的方法。
5.9 在首次使用前初始化变量,初始化的地方离使用的地方越近越好
说明: 未初始化变量是C和C++程序中错误的常见来源。在变量首次使用前确保正确初始化在较好的方案中,变量的定义和初始化要做到亲密无间。
5.10 明确全局变量的初始化顺序,避免跨模块的初始化依赖
说明: 系统启动阶段,使用全局变量前,要考虑到该全局变量在什么时候初始化,使用全局变量和初始化全局变量,两者之间的时序关系,谁先谁后,一定要分析清楚,不然后果往往是低级而又灾难性的。
5.11 尽量减少没有必要的数据类型默认转换与强制转换
说明: 当进行数据类型强制转换时,其数据的意义、转换后的取值等都有可能发生变化,而这些细节若考虑不周,就很有可能留下隐患。
6,宏、常量
6.1 用宏定义表达式时,要使用完备的括号
说明: 因为宏只是简单的代码替换,不会像函数一样先将参数计算后,再传递
6.2 将宏所定义的多条表达式放在大括号中
说明: 更好的方法是多条语句写成do while(0)的方式
6.3 使用宏时,不允许参数发生变化
示例:如下用法可能导致错误。
#define SQUARE(a)((a)*(a))
int a =5;
int b;
b=SQUARE(a++);//结果:a=7,即执行了两次增,
//正确的用法是:
b= SQUARE(a);
a++;//结果:a=6,即只执行了一次增6.4 除非必要,应尽可能使用函数代替宏
说明: 宏对比函数,有一些明显的缺点:宏缺乏类型检查,不如函数调用检查严格。
6.5 宏定义中尽量不使用return、goto、continue、break等改变程序流程的语句
说明: 如果在宏定义中使用这些改变流程的语句,很容易引起资源泄漏问题,使用者很难自己察觉。
7,注释
7.1 优秀的代码可以自我解释,不通过注释即可轻易读懂
说明: 优秀的代码不写注释也可轻易读懂,注释无法把糟糕的代码变好,需要很多注释来解释的代码往往存在坏味道,需要重构。
7.2 注释的内容要清楚、明了,含义准确,防止注释二义性
说明: 有歧义的注释反而会导致维护者更难看懂代码,正如带两块表反而不知道准确时间。
7.3 在代码的功能、意图层次上进行注释,即注释解释代码难以直接表达的意图,而不是重复描述代码
说明: 注释的目的是解释代码的目的、功能和采用的方法,提供代码以外的信息,帮助读者理解代码。防止没必要的重复注释信息。对于实现代码中巧妙的、晦涩的、有趣的、重要的地方加以注释。注释不是为了名词解释(what),而是说明用途(why)。
7.4 修改代码时,维护代码周边的所有注释,以保证注释与代码的一致性。不再有用的注释要删除
说明: 不要将无用的代码留在注释中,随时可以从源代码配置库中找回代码;即使只是想暂时排除代码,也要留个标注,不然可能会忘记处理它
7.5 文件头部应进行注释,注释必须列出:版权说明、版本号、生成日期、作者姓名、工号、内容、功能说明、与其它文件的关系、修改日志等,头文件的注释中还应有函数功能简要说明
说明: 通常头文件要对功能和用法作简单说明,源文件包含了更多的实现细节或算法讨论。
7.6 函数声明处注释描述函数功能、性能及用法,包括输入和输出参数、函数返回值、可重入的要求等;定义处详细描述函数功能和实现要点,如实现的简要步骤、实现的理由、设计约束等
说明: 重要的、复杂的函数,提供外部使用的接口函数应编写详细的注释。
7.7 全局变量要有较详细的注释,包括对其功能、取值范围以及存取时注意事项等的说明
7.8 对于switch语句下的case语句,如果因为特殊情况需要处理完一个case后进入下一个case处理,必须在该case语句处理完、下一个case语句前加上明确的注释
说明: 这样比较清楚程序编写者的意图,有效防止无故遗漏break语句。
一些建议
7.9 避免在一行代码或表达式的中间插入注释
说明: 除非必要,不应在代码或表达中间插入注释,否则容易使代码可理解性变差。
7.10 注释应考虑程序易读及外观排版的因素,使用的语言若是中、英兼有的,建议多使用中文,除非能用非常流利准确的英文表达。对于有外籍员工的,由产品确定注释语言
说明: 注释语言不统一,影响程序易读性和外观排版,出于对维护人员的考虑,建议使用中文。
7.11 文件头、函数头、全局常量变量、类型定义的注释格式采用工具可识别的格式
说明: 采用工具可识别的注释格式,例如doxygen格式,方便工具导出注释形成帮助文档。
8,排版格式
8.1 程序块采用缩进风格编写,每级缩进为4个空格
说明: 当前各种编辑器/IDE都支持TAB键自动转空格输入,需要打开相关功能并设置相关功能。
编辑器/IDE如果有显示TAB的功能也应该打开,方便及时纠正输入错误。IDE向导生成的代码可以不用修改。宏定义、编译开关、条件预处理语句可以顶格(或使用自定义的排版方案,但产品/模块内必须保持一致)。
8.2 相对独立的程序块之间、变量说明之后必须加空行
8.3 一条语句不能过长,如不能拆分需要分行写。一行到底多少字符换行比较合适,产品可以自行确定
说明: 对于目前大多数的PC来说,132比较合适(80/132是VTY常见的行宽值):对于新PC宽屏显示器较多的产品来说,可以设置更大的值。
换行时有如下建议:
- 换行时要增加一级缩进,使代码可读性更好:
- 低优先级操作符处划分新行:换行时操作符应该也放下来,放在新行首:
- 换行时建议一个完整的语句放在一行,不要根据字符数断行
8.4 多个短语句(包括赋值语句)不允许写在同一行内,即一行只写一条语句
8.5 if、for、do、while、case、switch、default等语句独占一行
说明: 执行语句必须用缩进风格写,属于if、for、do、while、case、switch、default等下一个缩进级别:
一般写if、for、do、while等语句都会有成对出现的"{}’,对此有如下建议可以参考:if、for、do、while等语句后的执行语句建议增加成对的“{}’;如果if/else配套语句中有一个分支有")",那么令一个分支即使一行代码也建议增加'{};添加'{的位置可以在if等语句后,也可以独立占下一行:独立占下一行时,可以和if在一个缩进级别,也可以在下一个缩进级别:但是如果if语句很长,或者已经有换行,建议使用独占一行的写法。
8.6 在两个以上的关键字、变量、常量进行对等操作时,它们之间的操作符之前、之后或者前后要加空格:进行非对等操作时,如果是关系密切的立即操作符(如一>),后不应加空格。
说明: 采用这种松散方式编写代码的目的是使代码更加清晰。在已经非常清晰的语句中没有必要再留空格,如括号内侧(即左括号后面和右括号前面)不需要加空格,多重括号间不必加空格,因为在C语言中括号已经是最清晰的标志了。在长语句中,如果需要加的空格非常多,那么应该保持整体清晰,而在局部不加空格。给操作符留空格时不要连续留两个以上空格。
8.7 注释符(包括'/*”//”“*/’)与注释内容之间要用一个空格进行分隔
说明: 这样可以使注释的内容部分更清晰。现在很多工具都可以批量生成、删除’//注释,这样有空格也比较方便统一处理。
8.8 源程序中关系较为紧密的代码应尽可能相邻
9,表达式
9.1 表达式的值在标准所允许的任何运算次序下都应该是相同的
说明: 除了少数操作符(函数调用操作符()、&&、||、? : 和,(逗号))之外,子表达式所依据的运算次序是未指定的并会随时更改。注意,运算次序的问题不能使用括号来解决,因为这不是优先级的问题。
建议
9.2 函数调用不要作为另一个函数的参数使用,否则对于代码的调试、阅读都不利
9.3 赋值语句不要写在if等语句中,或者作为函数的参数使用
说明: 因为if语句中,会根据条件依次判断,如果前一个条件已经可以判定整个条件,则后续条件语句不会再运行,所以可能导致期望的部分赋值没有得到运行
9.4 用括号明确表达式的操作顺序,避免过分依赖默认优先级
说明: 使用括号强调所使用的操作符,防止因默认的优先级与设计思想不符而导致程序出错;同时使得代码更为清晰可读,然而过多的括号会分散代码使其降低了可读性。
9.5 赋值操作符不能使用在产生布尔值的表达式上
说明: 如果布尔值表达式需要赋值操作,那么赋值操作必须在操作数之外分别进行。这可以帮助避免和==的混淆,帮助我们静态地检查错误。
10,代码编译
10.1 使用编译器的最高告警级别,理解所有的告警,通过修改代码而不是降低告警级别来消除所有告警
说明: 编译器是你的朋友,如果它发出某个告警,这经常说明你的代码中存在潜在的问题。
10.2 在产品软件(项目组)中,要统一编译开关、静态检查选项以及相应告警清除策略
说明: 如果必须禁用某个告警,应尽可能单独局部禁用,并且编写一个清晰的注释,说明为什么屏蔽。某些语句经编译/静态检查产生告警,但如果你认为它是正确的,那么应通过某种手段去掉告警信息
10.3 本地构建工具(如PC-Lint)的配置应该和持续集成的一致。
说明: 两者一致,避免经过本地构建的代码在持续集成上构建失败。
10.4 使用版本控制(配置管理)系统,及时签入通过本地构建的代码,确保签入的代码不会影响构建成功。
说明: 及时签入代码降低集成难度。


















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











