







黄色标黄的是答案,蓝色是自己做的,绿色的是没记住的
二分查找
当n是偶数时,在两个中我们要选择前面那一个
当n是奇数时,(2+3)/2=2
对n个元素进行二分查找,最大比较次数为:⌊ l o g 2 n ⌋ + 1


子串

KMP——串的简单模式匹配算法
真子串的个数
串的序号是从1开始的


哈夫曼树
“哈夫曼树不一定是完全二叉树。哈夫曼树是带权路径长度达到最小的二叉树,也叫做最优二叉树,不一定是完全二叉树,也不一定是平衡二叉树
哈夫曼树的结点个数为m, 则其叶子结点个数为(m+1)/2,分支结点个数为(m-1)/2
树的带权路径长度:树中所有叶子结点的带权路径长度之和
结点的带权路径长度为结点到根节点之间的路径长度与该节点上权的乘积.


堆
(1)堆是一颗完全二叉树;
(2)堆中某个节点的值总是不大于(或不小于)其父节点的值。
根节点最大的堆叫做大顶堆,根节点最小的堆叫做小顶堆

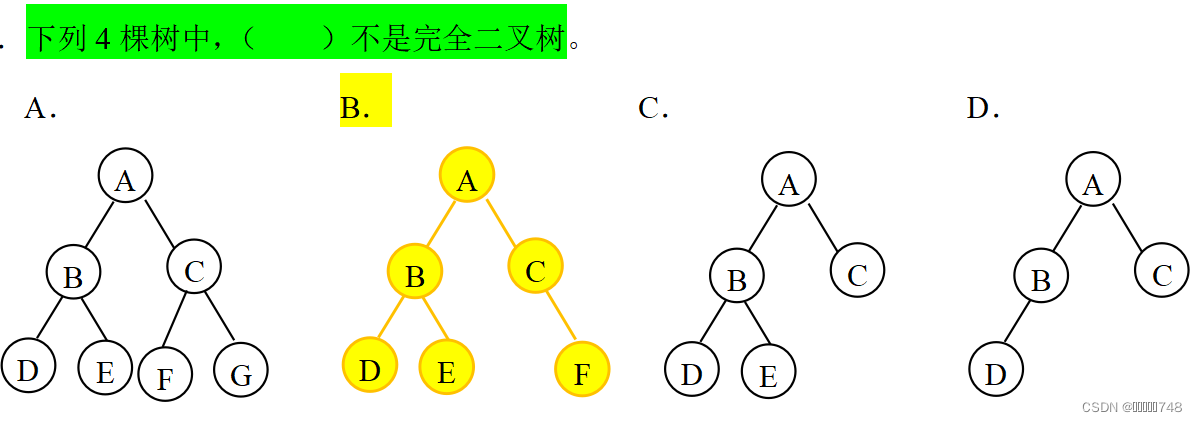
完全二叉树
如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。
在完全二叉树中,具有n个结点的完全二叉树深度为(log2n)+1,其中(log2n)+1是向下取整。

矩阵压缩

快速排序


插入排序

稳定
希尔排序(Shell排序)

不稳定
选择排序
不稳定。例如5 8 5 2 9

冒泡排序
稳定

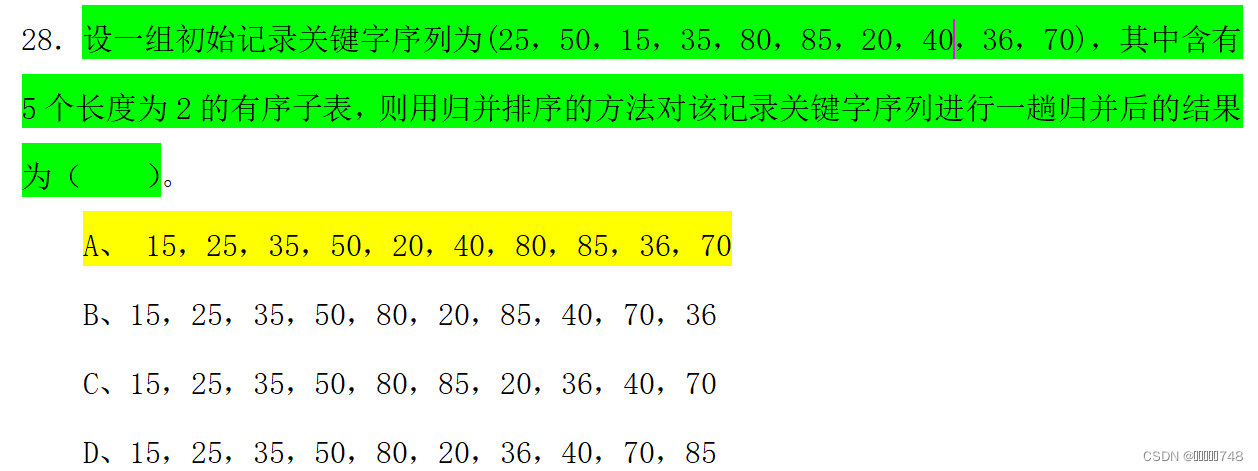
归并排序
稳定
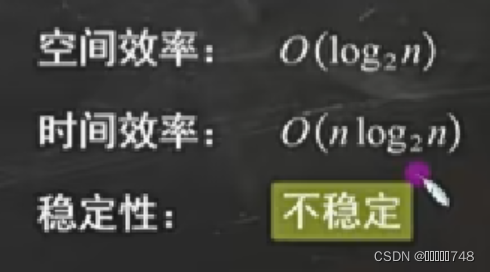
堆排序
迪杰斯特拉算法


图
边的个数

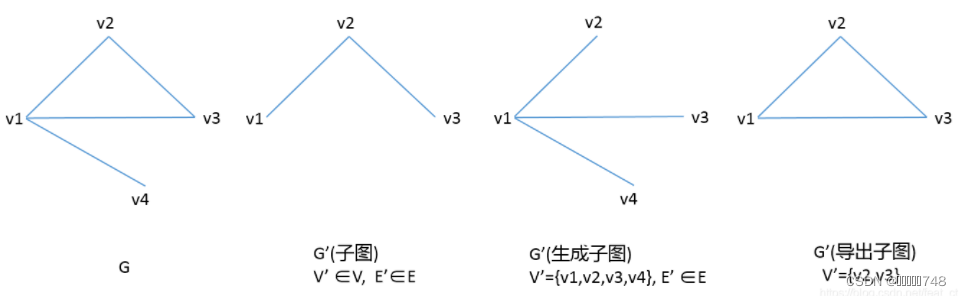
子图
子图G’中所有的顶点和边均包含于原图G。即E’∈E,并且V’∈V。
生成子图
生成子图G’中顶点个数V’必须和原图G中V的数量相同,而E’∈E即可。
导出子图
导出子图G’,V’∈V,但对于V’中任一顶点,只要在原图G中有对应边,那么就要出现在E’中
举例
连通图
图中任意两个顶点都是连通的
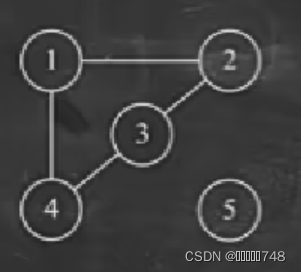
极小连通子图
- 极小连通子图为图的某一个顶点子集所确定的连通子图中,包含边最少且包含全部顶点的连通子图。
生成树
包含图中全部顶点的一个极小连通子图
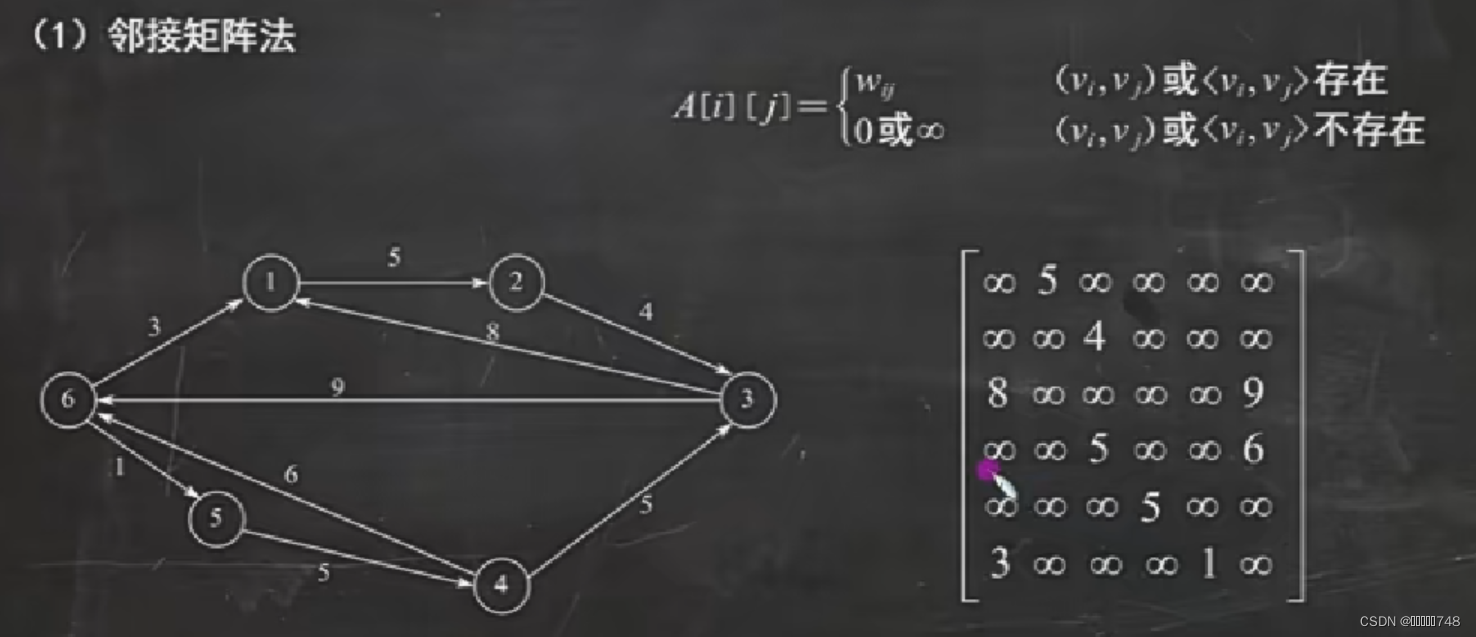
邻接矩阵
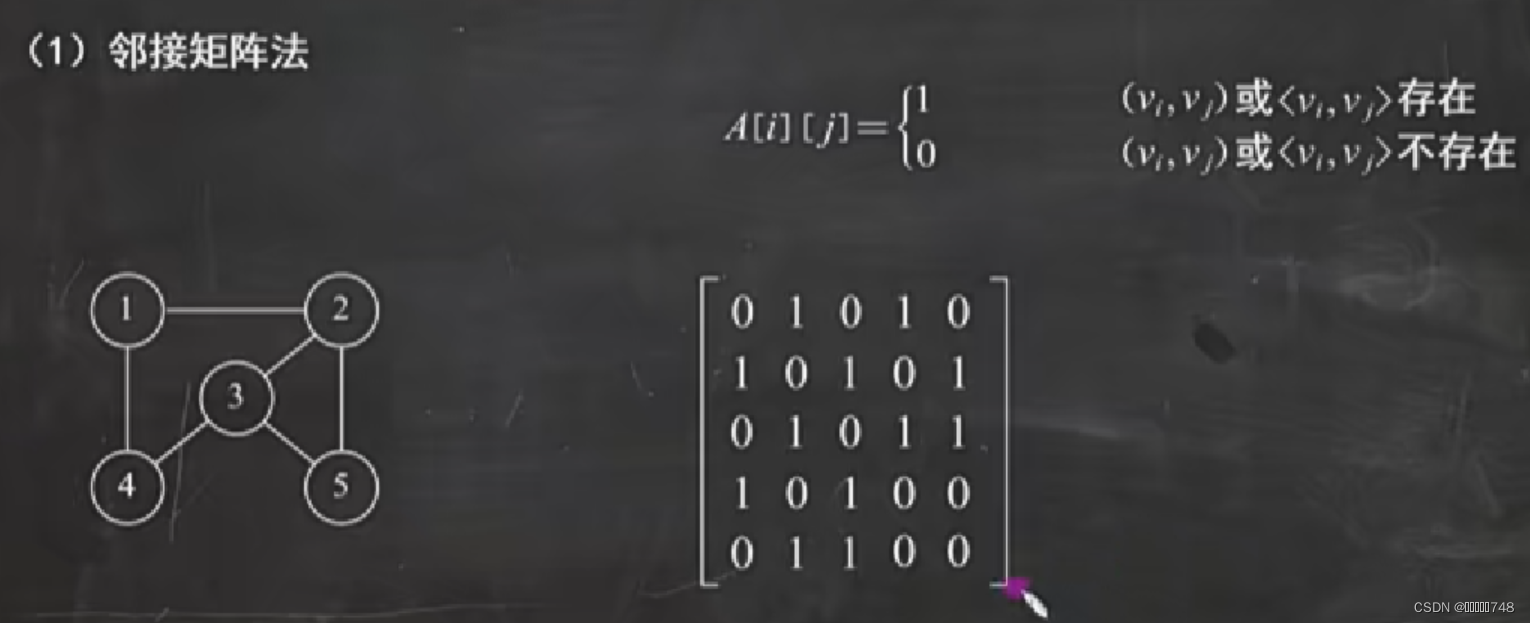

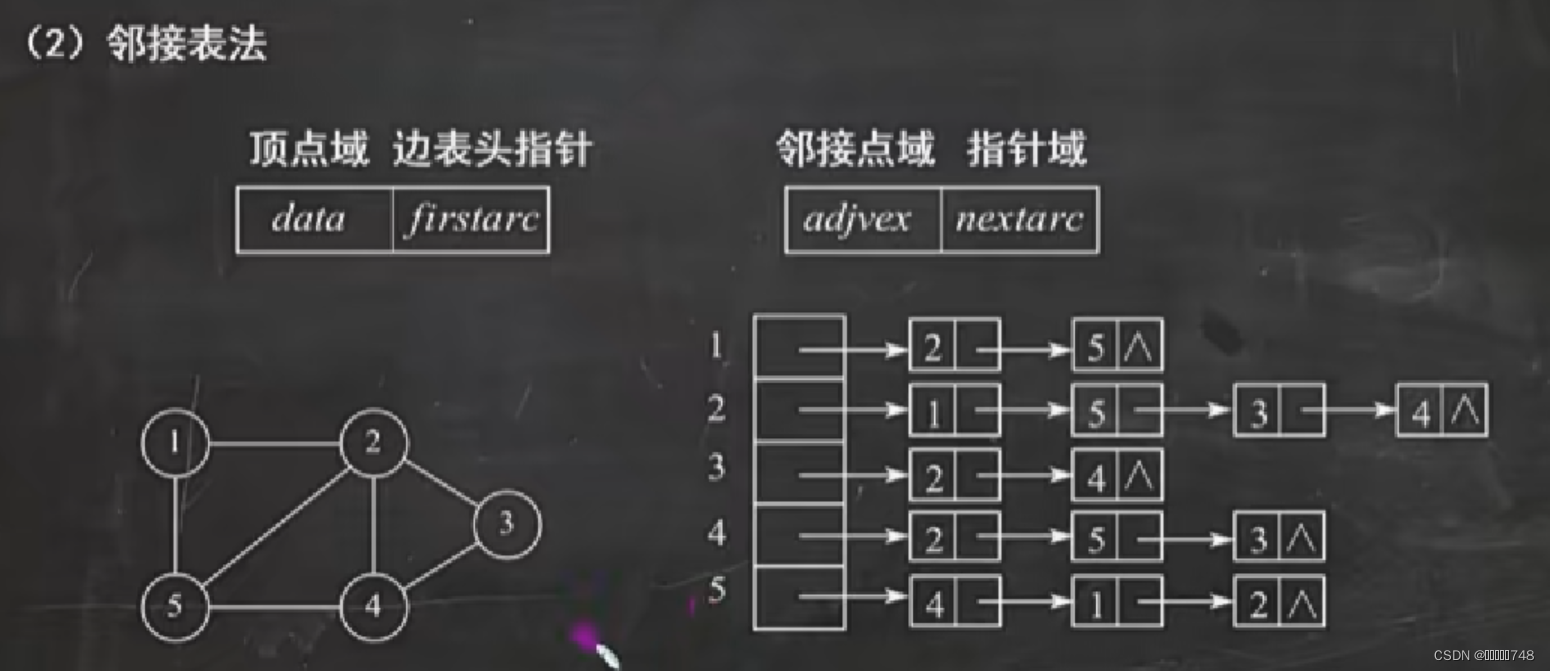
邻接表法


深度优先搜索(DFS)
广度优先搜索(BFS)


Prim算法

Kruskal算法

拓扑排序

关键路径

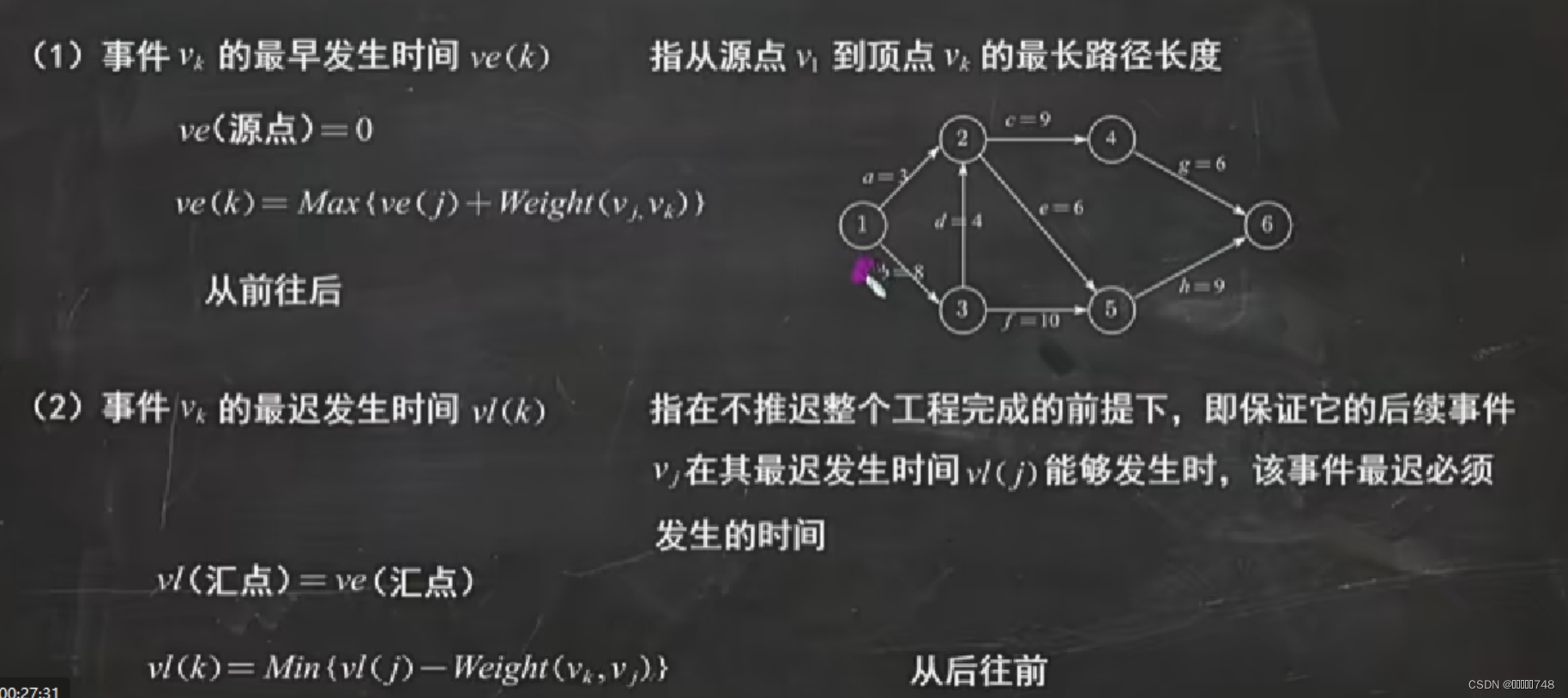


Substr函数

循环队列

散列查找(哈希查找)
排序算法的稳定性
稳定性概念:能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同
堆排序、快速排序、希尔排序、直接选择排序是不稳定的排序算法,而冒泡排序、直接插入排序、折半插入排序、归并排序是稳定的排序算法。
BST(二叉搜索树、二叉排序树、二叉查找树)
创建
添加
删除
哈夫曼树
栈
出栈个数

进栈出栈
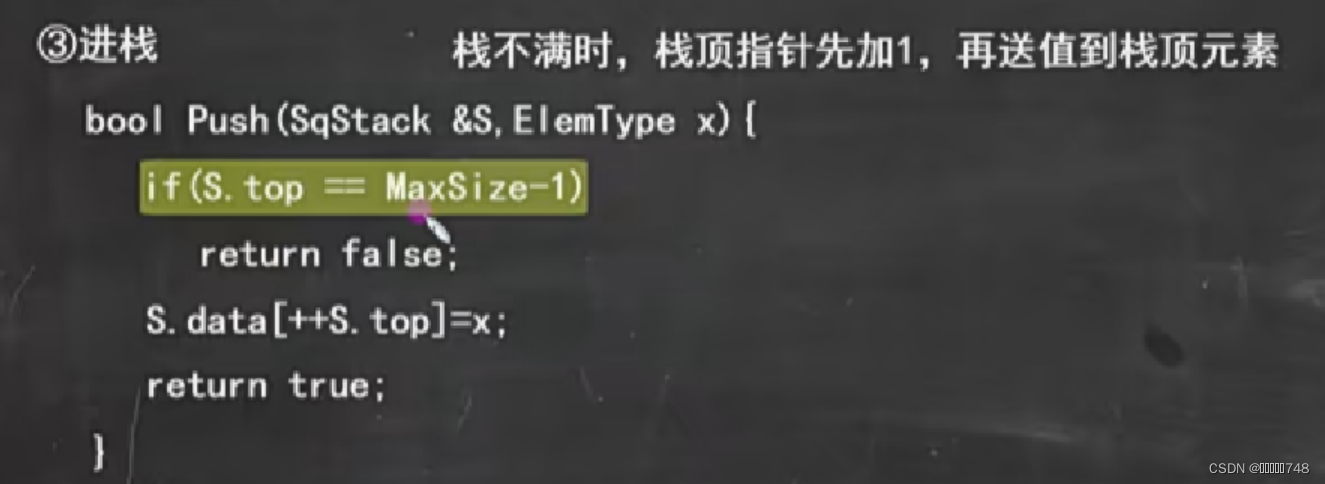
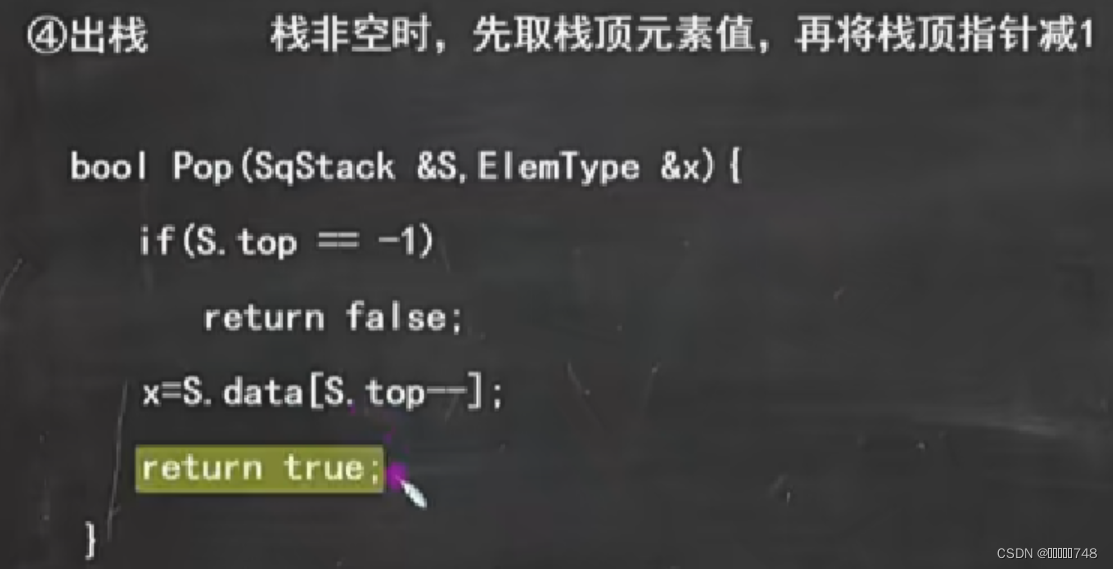
共享栈

队列
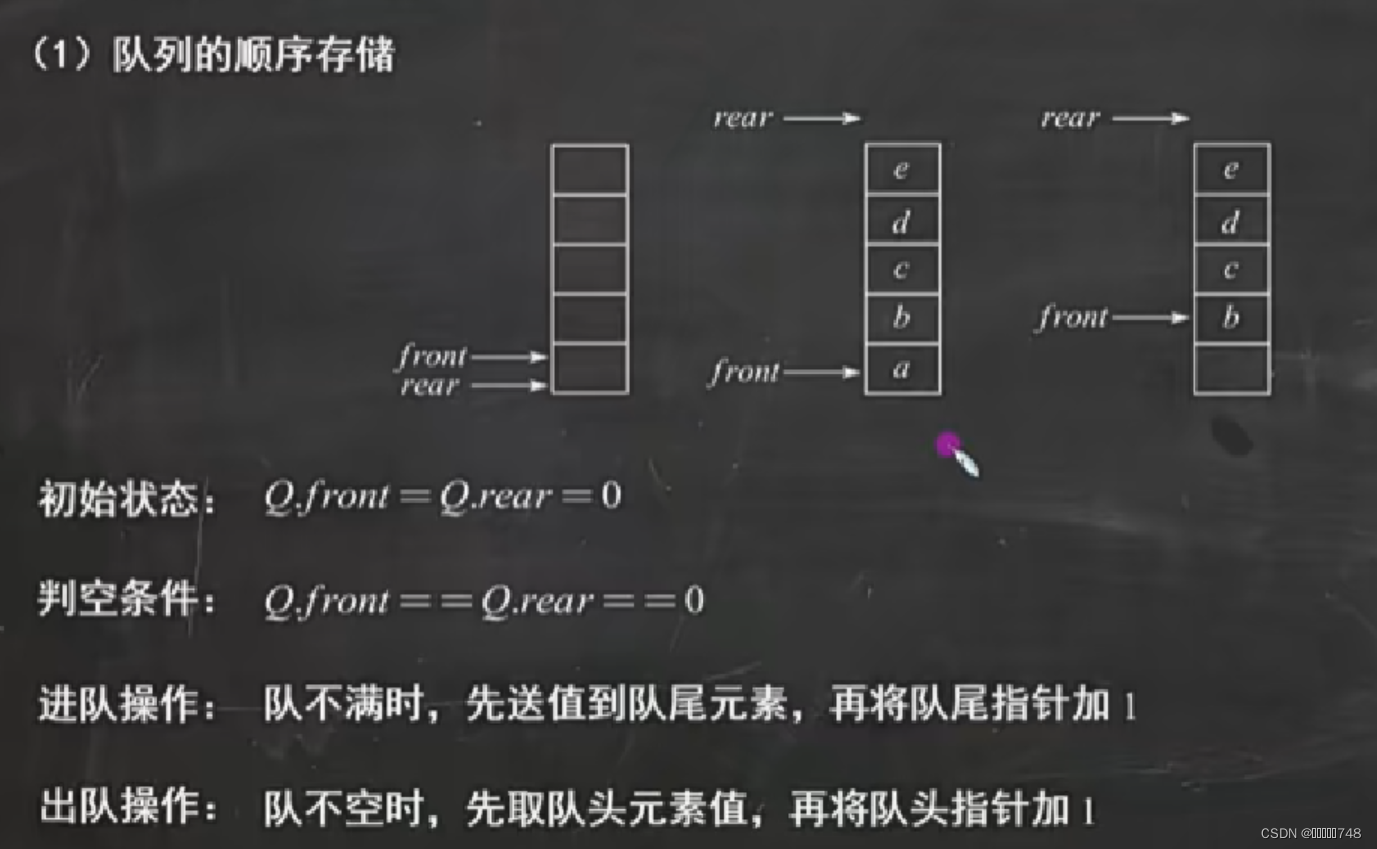



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









