






1. 摘要
近年来,图像文本检索方法表现出了令人印象深刻的性能。然而,他们仍然面临两个问题:模态间匹配缺失问题和模态内语义丢失问题。这些问题会显著影响图像文本检索的准确性。为了应对这些挑战,作者提出了一种称为跨模态和单模态软标签对齐的新方法(CUSA)。该方法利用单模态预训练模型的力量为图像文本检索模型提供软标签监督信号。另外介绍了两种对齐的方法:交叉模态软标签对齐(CSA)和单模态软标签对齐(USA),用于克服假阴性和增强单模态样本之间的相似性识别。作者将该方法设计为即插即用,这意味着它可以很容易地应用于现有的图像文本检索模型,而无需改变其原始架构。作者在各种图像文本检索模型和数据集上进行了广泛的实验,并取得最优的结果。此外,该方法还可以提高图像文本检索模型的单模态检索性能,使其能够实现通用检索。
2. 介绍
图像文本检索(ITR)根据另一种模态中的查询从一种模态检索相关样本。它涉及两个子任务,一个是图像到文本检索(在文本库中为输入图像找到最相关的标题),另一个是文本到图像检索(为输入查询文本在图像库中查找最相关的图像)。大多数现有的ITR方法采用对比学习技术,将一个样本作为锚,将另一种模态中的相应样本作为阳性样本,而不相关的样本则被视为阴性。这些方法旨在最大化锚点和正样本之间的相似性,最小化锚点和负样本之间的相似度,以进行跨模态检索。然而其存在两个局限性:模态间匹配缺失问题和模态内语义丢失问题。
模态间匹配缺失问题
模态间匹配缺失问题是指在模型训练过程中,本应匹配的样本被错误地视为不匹配,从而导致模型性能下降的情况。具体来说,假设数据集中图A与句子A为匹配关系,然而句子B同样也可以描述图片A,但模型会认为句子B与图片A并不匹配,导致了错误的匹配。
模态内语义损失问题
模态内语义损失问题是指当前ITR模型识别相似输入样本的能力不足。这是由于大多数ITR方法只优先考虑优化两种模态之间的相似性,而忽略了每种模态中的关系。它们只关注对齐图像-文本对,而忽略了图像-图像对齐和文本-文本对齐的操作。
作者通过实验认为,仅通过数据增强很难实现有效的单模态对齐。作者从数学上证明,仅仅强调跨模态对齐会阻碍模型识别相似输入样本的能力,从而在模型在训练过程中遇到看不见的样本但与训练集中的某些样本相似的情况下,削弱图像文本检索的性能。
作者做了三件事:
- 从数学上证明,仅仅强调交叉模态对齐会阻碍ITR模型识别相似输入样本的能力,从而削弱图像文本检索的性能。
- 介绍了两种对齐技术,CSA和USA,它们使用软标签作为监督信号来指导ITR模型的交叉模态和单模态对齐。
- 对各种ITR模型和数据集进行了广泛的实验,并表明该模型可以持续提高图像文本检索的性能,并获得最新的最先进结果。
3. 模型方法
3.1 准备工作
给定图像文本对数据 { ( I i , T i ) } i = 1 N \{(I_i,T_i)\}_{i=1}^N {(Ii,Ti)}i=1N,使用图像编码器和文本编码器分别将 I i I_i Ii和 T i T_i Ti归一化表示为 I ^ i \hat{I}_i I^i和 T ^ i \hat{T}_i T^i。与CLIP相同,计算出他们的余弦相似度进行特征对齐,得到了图像到文本和文本到图像特征。公式如下, s i j s_{ij} sij代表余弦相似度。 Q i j i 2 t = exp ( s i j i 2 t / τ ) ∑ k = 1 N exp ( s i k i 2 t / τ ) Q_{ij}^{\text{i}2\text{t}}=\frac{\exp\left(s_{ij}^{\text{i}2\text{t}}/\tau\right)}{\sum_{k=1}^N\exp\left(s_{ik}^{\text{i}2\text{t}}/\tau\right)} Qiji2t=∑k=1Nexp(siki2t/τ)exp(siji2t/τ) Q i j t 2 i = exp ( s i j t 2 i / τ ) ∑ k = 1 N exp ( s i k t 2 i / τ ) Q_{ij}^{\text{t}2\text{i}}=\frac{\exp\left(s_{ij}^{\text{t}2\text{i}}/\tau\right)}{\sum_{k=1}^N\exp\left(s_{ik}^{\text{t}2\text{i}}/\tau\right)} Qijt2i=∑k=1Nexp(sikt2i/τ)exp(sijt2i/τ)
之后对于标签y使用one-hot编码,从而得到信息损失:
L
i
t
c
i
2
t
=
1
N
∑
i
=
1
N
H
(
y
i
,
Q
i
i
2
t
)
L
i
t
c
t
2
i
=
1
N
∑
i
=
1
N
H
(
y
i
,
Q
i
t
2
i
)
\begin{gathered} \mathcal{L}_{\mathrm{itc}}^{\mathrm{i2t}} =\frac1N\sum_{i=1}^N\mathcal{H}\left(\mathbf{y_i},Q_i^{\text{i}2\text{t}}\right) \\ \mathcal{L}_{\mathrm{itc}}^{\mathrm{t2i}} =\frac1N\sum_{i=1}^N\mathcal{H}\left(\mathbf{y_i},Q_i^{\text{t}2\text{i}}\right) \end{gathered}
Litci2t=N1i=1∑NH(yi,Qii2t)Litct2i=N1i=1∑NH(yi,Qit2i)
H
(
.
,
.
)
\mathcal{H}(.,.)
H(.,.)代表交叉熵计算。最终得到损失
L
i
t
c
=
(
L
i
t
c
i
2
t
+
L
i
t
c
t
2
i
)
/
2
\mathcal{L}_{\mathrm{itc}}=\left(\mathcal{L}_{\mathrm{itc}}^{\mathrm{i2t}}+\mathcal{L}_{\mathrm{itc}}^{\mathrm{t2i}}\right)/2
Litc=(Litci2t+Litct2i)/2。我们使用
L
c
o
r
i
g
i
n
a
l
\mathcal{L}_{\mathrm{coriginal}}
Lcoriginal来表示ITR模型的原始损失函数,对于大多数模型,损失函数就是上面介绍的
L
i
t
c
\mathcal{L}_{\mathrm{itc}}
Litc,如下图1中用绿色圆圈加号表示的部分。
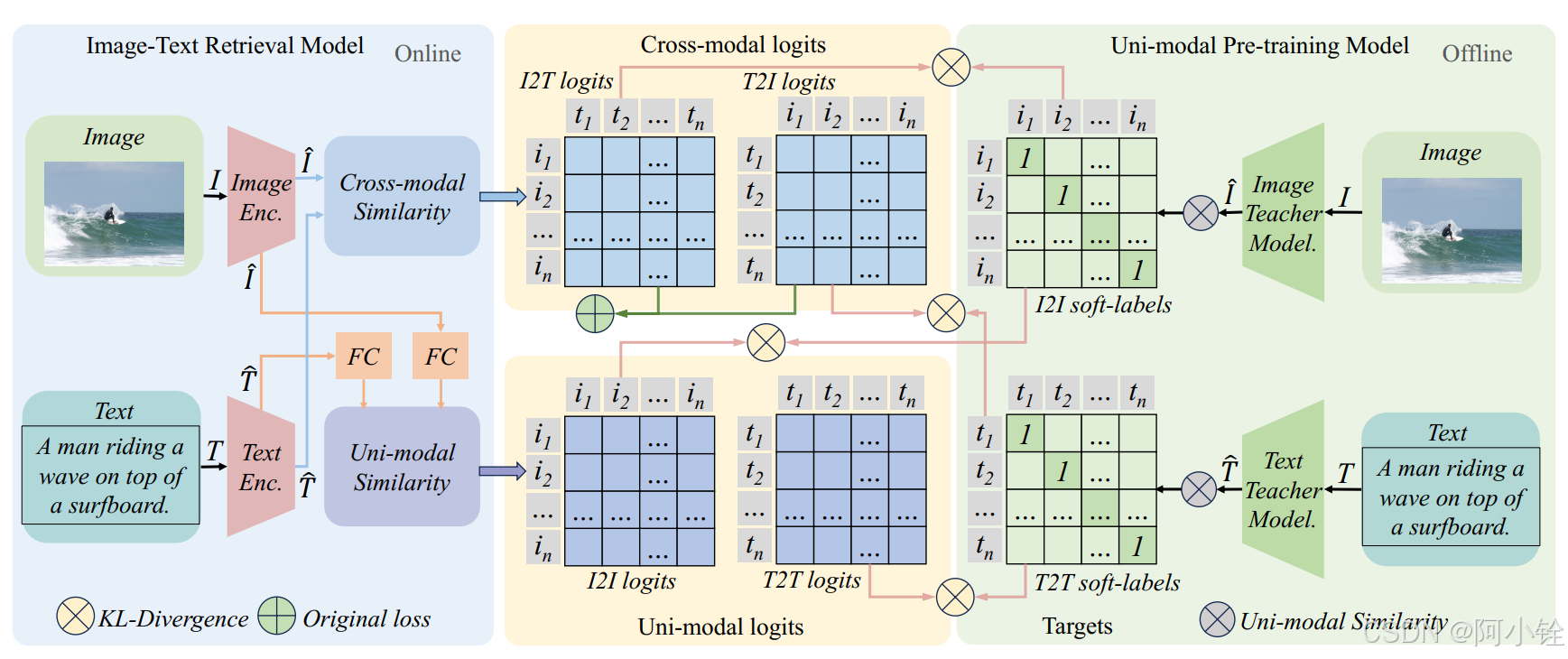
3.2 特征提取
作者引入了两个单模态预训练模型作为教师模型来计算软标签,以指导ITR模型。作者选择Unicom作为图像的教师模型,选择Sentence-BERT作为文本模型。图像和文本特征的提取可以离线完成,因此在在线训练期间不会增加ITR模型的复杂性。图像和文本的每个模型的选择都是灵活的,可以用任何可用的模型替换。
3.3 跨模态软标签对齐
在实际中,同一批中未配对的图像和文本之间可能存在潜在的语义关联,但未在数据集中标记。我们称这种情况为“模态间匹配缺失问题”,它导致语义匹配的图像和文本在训练过程中被错误地推送。为了解决这个问题,作者提出了跨模态软标签对齐(CSA)方法,如图一。
具体来说,我们根据从教师模型中获得的特征计算
I
^
i
\hat{I}_i
I^i和
I
^
j
\hat{I}_j
I^j两个图像之间的余弦相似度,并将其表示为
r
i
j
i
2
i
r_{ij}^{\mathrm{i}2\mathrm{i}}
riji2i。然后,在批归一化过程中得到
I
^
i
\hat{I}_i
I^i和
I
^
j
\hat{I}_j
I^j之间的相似性,以获得
P
i
j
i
2
i
P_{ij}^{\mathrm{i}2\mathrm{i}}
Piji2i,即这两个图像在教师网络中语义一致的概率估计:
P
i
j
i
2
i
=
exp
(
r
i
j
i
2
i
)
∑
j
=
1
N
exp
(
r
i
j
i
2
i
)
P_{ij}^{\mathrm{i2i}}=\frac{\exp\left(r_{ij}^{\mathrm{i2i}}\right)}{\sum_{j=1}^N\exp\left(r_{ij}^{\mathrm{i2i}}\right)}
Piji2i=∑j=1Nexp(riji2i)exp(riji2i)
最后我们将概率分布
(
P
i
1
i
2
i
,
.
.
.
,
P
i
N
i
2
i
)
(P_{i1}^{{\mathrm{i2i}}},...,P_{iN}^{{\mathrm{i2i}}})
(Pi1i2i,...,PiNi2i)视为
P
i
i
2
i
P_{i}^{{\mathrm{i2i}}}
Pii2i。同样,我们计算
T
i
T_i
Ti和
T
j
T_j
Tj两个文本之间的相似度,记为
r
i
j
t
2
t
r_{ij}^{\mathrm{t}2\mathrm{t}}
rijt2t,从而得到
P
i
t
2
t
P_{i}^{{\mathrm{t2t}}}
Pit2t。
在训练过程中,我们将
P
i
i
2
i
P_{i}^{{\mathrm{i2i}}}
Pii2i作为目标分布来指导
Q
i
i
2
t
Q_{i}^{\text{i}2\text{t}}
Qii2t的分布,通过计算KL散度实现。同样的,将
P
i
t
2
t
P_{i}^{{\mathrm{t2t}}}
Pit2t作为目标分布来指导
Q
i
t
2
i
Q_{i}^{\text{t}2\text{i}}
Qit2i的分布,也通过计算KL散度实现。最后。CSA的损失函数表示为:
L
C
S
A
=
(
L
C
S
A
i
2
t
+
L
C
S
A
t
2
i
)
/
2
=
(
D
K
L
(
P
i
i
2
i
∥
Q
i
i
2
t
)
+
D
K
L
(
P
i
t
2
t
∥
Q
i
t
2
i
)
)
/
2
\begin{aligned} \mathcal{L}_{\mathrm{CSA}}& =\left(\mathcal{L}_{\mathrm{CSA}}^{\mathrm{i2t}}+\mathcal{L}_{\mathrm{CSA}}^{\mathrm{t2i}}\right)/2 \\ &=\left(D_{KL}(P_i^{\mathrm{i}2\mathrm{i}}\parallel Q_i^{\mathrm{i}2\mathrm{t}})+D_{KL}(P_i^{\mathrm{t}2\mathrm{t}}\parallel Q_i^{\mathrm{t}2\mathrm{i}})\right)/2 \end{aligned}
LCSA=(LCSAi2t+LCSAt2i)/2=(DKL(Pii2i∥Qii2t)+DKL(Pit2t∥Qit2i))/2
3.4 单模态软标签对齐
接下来我们解决“模态内语义损失问题”,这可能会影响模型在看不见的数据上的泛化性能。如下图2所示,我们考虑了图像-文本对 1 ◯ \textcircled{1} 1◯和 3 ◯ \textcircled{3} 3◯是训练集中的样本,而 2 ◯ \textcircled{2} 2◯是训练过程中看不见的样本的情况。对于大部分模型,图中的情况:每个图像和文本对可以很好地对齐,但由于没有引入单模态对齐,两对可能会出现在超球面上的不同区域,每个样本被映射到相应的位置。此时,图像 2 ◯ \textcircled{2} 2◯与图像 1 ◯ \textcircled{1} 1◯在像素级别上相似(论文原文为与图像 3 ◯ \textcircled{3} 3◯相似,但可能是作者笔误,从配图来看确实是与图像 1 ◯ \textcircled{1} 1◯相似,若是我理解不对麻烦在评论区指出),文本 2 ◯ \textcircled{2} 2◯与文本 3 ◯ \textcircled{3} 3◯在语义级别上相似。因此,图像 2 ◯ \textcircled{2} 2◯与文本 2 ◯ \textcircled{2} 2◯在球面上的距离会被拉远,这是我们所不希望看到的。
此外,作者从数学上证明了只关注跨模态对齐的模型缺乏单模态能力,正是因为模型识别相似输入样本的能力不够好,限制了跨模态检索的泛化性能,即下面的论述。
- 论述:单独的交叉模态对齐不足以对相似样本进行最佳识别

根据这个论述,作者提出了单模态软标签对齐(USA)模型,使模型能够识别单模态样本之间的相似性,从而提高看不见的数据的性能。
如图1所示,模型从教师模型中得到
P
i
i
2
i
P_{i}^{{\mathrm{i2i}}}
Pii2i和
P
i
t
2
t
P_{i}^{{\mathrm{t2t}}}
Pit2t,接着,从ITR模型的输出中提取图像和文本对应的特征表征
I
^
i
\hat{I}_i
I^i和
T
^
i
\hat{T}_i
T^i。这里两个特征表征还会通过一个投影层(线性层)。与跨模态软标签对齐方法类似,我们将
I
^
i
\hat{I}_i
I^i和
I
^
j
\hat{I}_j
I^j的余弦相似度表示为
s
i
j
i
2
i
s^{i2i}_{ij}
siji2i,而
T
^
i
\hat{T}_i
T^i和
T
^
j
\hat{T}_j
T^j的余弦相似度表示为
s
i
j
t
2
t
s^{t2t}_{ij}
sijt2t。同样的,对
I
^
i
\hat{I}_i
I^i和
I
^
j
\hat{I}_j
I^j之间的相似性进行批归一化,得到
Q
i
j
i
2
i
Q_{ij}^{\text{i}2\text{i}}
Qiji2i:
Q
i
j
i
2
i
=
exp
(
s
i
j
i
2
i
/
τ
)
∑
j
=
1
N
exp
(
s
i
j
i
2
i
/
τ
)
Q_{ij}^{\text{i}2\text{i}}=\frac{\exp\left(s_{ij}^{\text{i}2\text{i}}/\tau\right)}{\sum_{j=1}^N\exp\left(s_{ij}^{\text{i}2\text{i}}/\tau\right)}
Qiji2i=∑j=1Nexp(siji2i/τ)exp(siji2i/τ)最后我们将概率分布
(
Q
i
1
i
2
i
,
.
.
.
,
Q
i
N
i
2
i
)
(Q_{i1}^{{\mathrm{i2i}}},...,Q_{iN}^{{\mathrm{i2i}}})
(Qi1i2i,...,QiNi2i)视为
Q
i
i
2
i
Q_{i}^{{\mathrm{i2i}}}
Qii2i,相同的步骤得到
Q
i
t
2
t
Q_{i}^{{\mathrm{t2t}}}
Qit2t。在训练过程中,我们将
P
i
i
2
i
P_{i}^{{\mathrm{i2i}}}
Pii2i作为目标分布来指导
Q
i
i
2
i
Q_{i}^{\text{i}2\text{i}}
Qii2i的分布,通过计算KL散度实现。同样的,将
P
i
t
2
t
P_{i}^{{\mathrm{t2t}}}
Pit2t作为目标分布来指导
Q
i
t
2
t
Q_{i}^{\text{t}2\text{t}}
Qit2t的分布,也通过计算KL散度实现。最后。USA的损失函数表示为:
L
U
S
A
=
(
L
U
S
A
i
2
i
+
L
U
S
A
t
2
t
)
/
2
=
(
D
K
L
(
P
i
i
2
i
∥
Q
i
i
2
i
)
+
D
K
L
(
P
i
t
2
t
∥
Q
i
t
2
t
)
)
/
2
\begin{aligned} \mathcal{L}_{\mathrm{USA}}& =\left(\mathcal{L}_{\mathrm{USA}}^{\mathrm{i2i}}+\mathcal{L}_{\mathrm{USA}}^{\mathrm{t2t}}\right)/2 \\ &=\left(D_{KL}(P_i^{\mathrm{i}2\mathrm{i}}\parallel Q_i^{\mathrm{i}2\mathrm{i}})+D_{KL}(P_i^{\mathrm{t}2\mathrm{t}}\parallel Q_i^{\mathrm{t}2\mathrm{t}})\right)/2 \end{aligned}
LUSA=(LUSAi2i+LUSAt2t)/2=(DKL(Pii2i∥Qii2i)+DKL(Pit2t∥Qit2t))/2
USA方法以单模态方式将相似的样本拉近,同时将不同的样本推开。经过这种模态内对齐操作后,我们可以使模型更偏向于图2(b)中的情况。通过这种单模态约束,我们希望ITR模型能够在看不见的数据中取得更好的结果。
3.5 训练目标
我们使用上述两个损失,CSA和USA,来修正ITR模型的原始损失,因此整体损失函数表示为:
L
C
U
S
A
=
L
o
r
i
g
i
n
a
l
+
α
⋅
L
C
S
A
+
β
⋅
L
U
S
A
\mathcal{L}_{\mathrm{CUSA}}=\mathcal{L}_{\mathrm{original}}+\alpha\cdot\mathcal{L}_{\mathrm{CSA}}+\beta\cdot\mathcal{L}_{\mathrm{USA}}
LCUSA=Loriginal+α⋅LCSA+β⋅LUSA
其中,
α
\alpha
α和
β
\beta
β为损失权重。该方法为即插即用的,不改变ITR模型的原始架构。在应用我们的方法时,我们只需要在图像和文本端分别添加一个FC层来实现USA方法,其余的模型结构不需要任何更改。因此,它可以很容易地扩展到现有的ITR模型。
4. 结论
文章提出了一种新的图像文本检索方法,称为跨模态和单模态软标签对齐。该方法利用单模态的预训练模型为ITR模型提供软标签监督信号,并使用CSA和USA两种对齐技术来克服假阴性,增强模态内样本之间的相似性识别。文章的是即插即用,可以很容易地应用于现有的ITR模型,而无需改变其原始架构。作者对各种ITR模型和数据集进行了广泛的实验,证明其方法可以持续提高图像文本检索的性能,并获得最新的技术成果。此外,该方法还可以提高ITR模型的单模态检索性能,使其能够实现通用检索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









