






1 摘要
直接从成对的放射学报告中学习医学视觉表示已经成为表示学习中的一个新兴话题。然而,现有的医学图像-文本联合学习方法受到实例或局部监督分析的限制,忽略了疾病层面的语义对应。在本文中,作者提出了一种新的用于广义医学视觉表示学习的多粒度跨模态对齐(MGCA)框架,该框架通过利用医学图像和放射学报告之间在三个不同级别(即病理区域级别、实例级别和疾病级别)上自然表现出的语义对应关系。具体来说,首先通过最大化图像报告对之间的一致性来合并实例对齐模块。此外,对于标记对齐,文章引入了一种双向交叉注意力策略来显式学习细粒度视觉标记和文本标记之间的匹配,然后进行对比学习来对齐它们。更重要的是,为了利用高级主题间关系语义(例如,疾病)对应关系,作者设计了一种新的跨模态疾病水平对齐范式,以增强跨模态聚类分配的一致性。在包括图像分类、对象检测和语义分割任务的七个下游医学图像数据集上的大量实验结果表明,该框架具有稳定和卓越的性能。
2 介绍
近几十年来,当大规模标记数据集可用时,深度学习技术显著提高了医学图像理解。然而,组装这样大的带注释的数据既昂贵又耗时。因此,直接从伴随医学图像的放射学报告中学习成为研究的热点。模型从医生的详细医疗记录中学习一般的医学视觉表示,然后将学习到的表示转移到下游任务。但考虑到病理通常只占整个图像的一小部分这一限制,因此细粒度语义很重要。
如图1所示,医学图像和放射学报告在不同级别(如疾病级别、实例级别和病理区域级别)自然表现出多粒度的语义对应。然而,现有的图像-文本联合学习方法仅限于探索对应关系仅从一部分级别进行监督。因此,如何从所有三个层面有效地利用医学图像和放射学报告之间固有的多粒度跨模态对应关系来增强医学视觉表示仍然是一个悬而未决的问题。
在本文中,我们提出了一种新的多粒度跨模态对齐(MGCA)框架,以无缝利用医学图像和放射学报告之间的多粒度语义对应关系进行广义医学视觉表示学习。具体而言,我们通过对比学习结合了众所周知的实例对齐、细粒度标记对齐和疾病级别对齐。通过从三个方面利用多粒度跨模态对应关系,MGCA框架能够在图像和像素级别提升下游任务,其中只需要有限的注释数据。
我们用大规模医学图像和报告数据集(即MIMICCXR)预训练我们的MGCA框架,然后用七个下游数据集验证我们学习的医学视觉表示,这些数据集属于三个医学任务:图像分类、对象检测和语义分割。
实验结果表明,与现有的最先进的医学图像文本预训练方法相比,即使使用1%的训练数据进行训练,我们的模型也能实现稳定、卓越的传输性能。
3 模型框架
3.1 模型总览
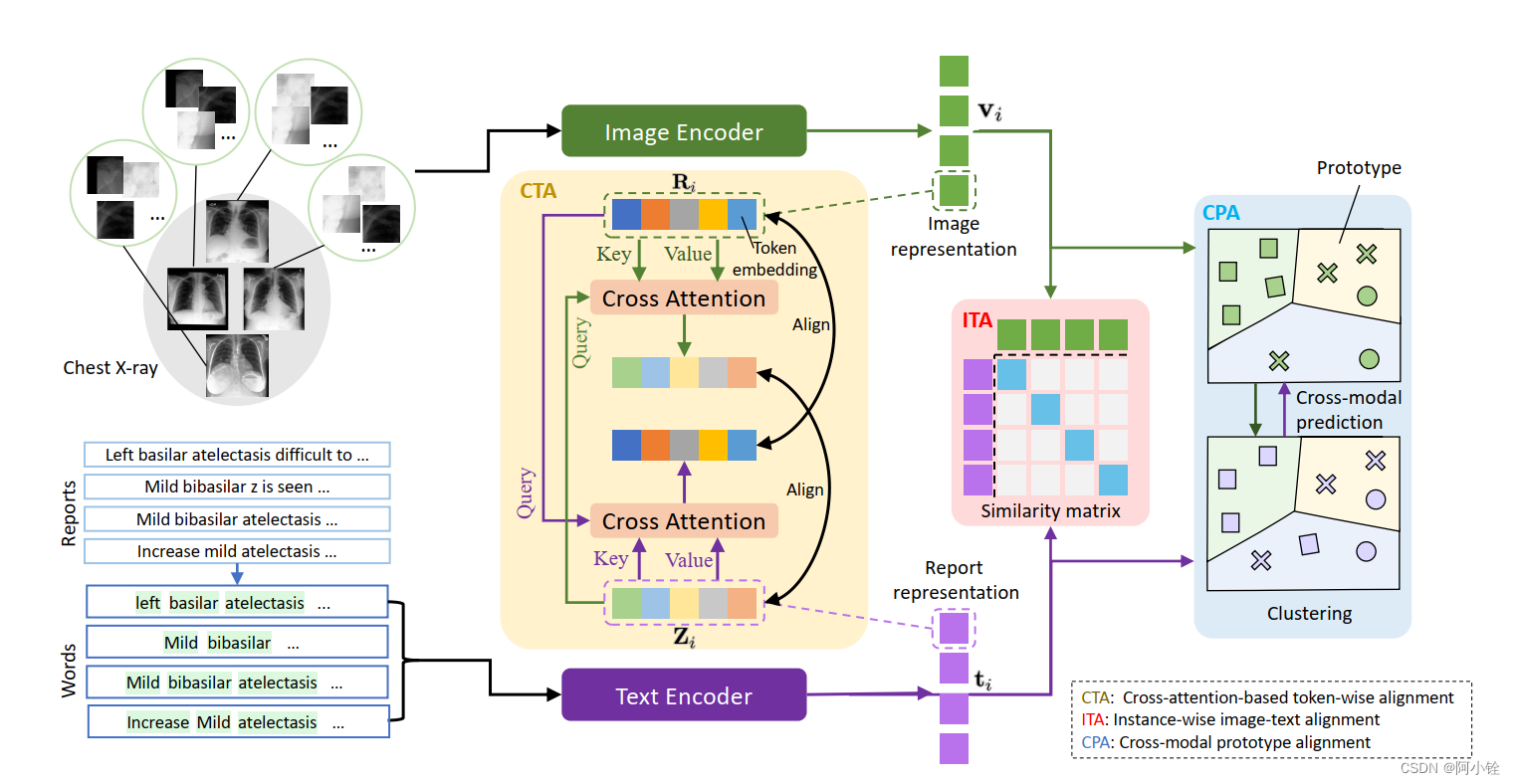
给定一个包含N个图像-报告对的训练集 D = { ( x v , 1 , x t , 1 ) , ( x v , 2 , x t , 2 ) , . . . , ( x v , N , x t , N ) } \begin{aligned}\mathcal{D}=\{(x_{v,1},x_{t,1}),(x_{v,2},x_{t,2}),...,(x_{v,N},x_{t,N})\}\end{aligned} D={(xv,1,xt,1),(xv,2,xt,2),...,(xv,N,xt,N)},我们使用一个图像编码器 f v f_v fv(例如ViT)和一个文本编码器 f t f_t ft(例如BERT)来将图像报告对映射到一个潜在空间 E = { ( v 1 , t 1 ) , ( v 2 , t 2 ) , . . . , ( v N , t N ) } \mathcal{E}=\{(\mathbf{v}_1,\mathbf{t}_1),(\mathbf{v}_2,\mathbf{t}_2),...,(\mathbf{v}_N,\mathbf{t}_N)\} E={(v1,t1),(v2,t2),...,(vN,tN)},其中 v i = f v ( x v , i ) , t i = f t ( x t , i ) \mathbf{v}_i=f_v(x_{v,i}),\mathbf{t}_i=f_t(x_{t,i}) vi=fv(xv,i),ti=ft(xt,i)。具体来说,对于第i个图像-报告对输入,图像编码器会生成一个对应的视觉标记编码序列 R i = { r i 1 , r i 2 , . . . , r i S } \mathbf{R}_i=\{\mathbf{r}_i^1,\mathbf{r}_i^2,...,\mathbf{r}_i^S\} Ri={ri1,ri2,...,riS}和一个图像全局表示 v i {\mathbf{v}}_i vi。同样的,文本编码器会生成一个对应的文本标记编码序列 Z i = { z i 1 , z i 2 , . . . , z i L } \mathbf{Z}_i=\{\mathbf{z}_i^1,\mathbf{z}_i^2,...,\mathbf{z}_i^L\} Zi={zi1,zi2,...,ziL}和文本全局表示 t i {\mathbf{t}}_i ti。S和L表示视觉标记和文本标记的总数。
如图1所示,我们通过利用自然表现出的多粒度跨模态对应关系,即疾病(原型)级、实例级和病理区域(表征)级,设计了一种用于表示学习的新的多粒度交叉模态对齐框架。具体来讲,框架中存在三个模块:实例图像文本对齐模块(ITA),标记对齐模块(CTA),跨模态原型对比模块(CPA)。
- 实例图像文本对齐模块(ITA):通过最大化真实图像报告对(vi;ti)与随机对之间的一致性来保持跨模态平滑性。
- 标记对齐模块(CTA):基于双向交叉注意力,利用视觉和文本标记之间自然存在的细粒度对应的优势来学习视觉标记序列和文本标记序列之间的软匹配,并通过对比学习对其进行对齐。
- 跨模态原型比对模块(CPA):通过捕捉两种模态之间的主体间关系对应关系,有利于高级语义(如疾病)理解
3.2 多粒度跨模态对齐
3.2.1 实例式跨模态对齐(ITA)
实例对齐模块使潜在空间中同一图像-报告对的距离接近,而不同图像报告对的距离远离。具体来说,我们首先使用两个非线性层分别将 v i {\mathbf{v}}_i vi和 t i {\mathbf{t}}_i ti归一化为低维嵌入。图像-报告对的相似程度使用余弦相似度: s i m ( x v , i , x t , i ) = v ~ i T t ~ i , where v ~ i = g v ( v i ) , t ~ i = g t ( t i ) sim(x_{v,i},x_{t,i})=\tilde{\mathbf{v}}_i^T\tilde{\mathbf{t}}_i,\text{where }\tilde{\mathbf{v}}_i=g_v(\mathbf{v}_i),\tilde{\mathbf{t}}_i=g_t(\mathbf{t}_i) sim(xv,i,xt,i)=v~iTt~i,where v~i=gv(vi),t~i=gt(ti)对于批次中的第i个图像-报告对,我们将两个模态数据视为查询(Q)和关键字(K)。其损失函数的构建与CLIP等模型相同,最小化图像到文本和文本到图像损失,即InfoNCE loss。其公式如下: ℓ i v 2 t = − l o g exp ( s i m ( x v , i , x t , i ) / τ 1 ) ∑ k = 1 B exp ( s i m ( x v , i , x t , k ) / τ 1 ) , ℓ i t 2 v = − l o g exp ( s i m ( x t , i , x v , i ) / τ 1 ) ∑ k = 1 B exp ( s i m ( x t , i , x v , k ) / τ 1 ) \begin{aligned}\ell_i^{\mathrm{v}2\mathrm{t}}&=-\mathrm{log}\frac{\exp(sim(x_{v,i},x_{t,i})/\tau_1)}{\sum_{k=1}^B\exp(sim(x_{v,i},x_{t,k})/\tau_1)},\quad\ell_i^{\mathrm{t}2\mathrm{v}}&=-\mathrm{log}\frac{\exp(sim(x_{t,i},x_{v,i})/\tau_1)}{\sum_{k=1}^B\exp(sim(x_{t,i},x_{v,k})/\tau_1)}\end{aligned} ℓiv2t=−log∑k=1Bexp(sim(xv,i,xt,k)/τ1)exp(sim(xv,i,xt,i)/τ1),ℓit2v=−log∑k=1Bexp(sim(xt,i,xv,k)/τ1)exp(sim(xt,i,xv,i)/τ1) L I T A = 1 2 N ∑ i = 1 N ( ℓ i v 2 t + ℓ i t 2 v ) , \mathcal{L}_{\mathrm{ITA}}=\frac1{2N}\sum_{i=1}^{N}(\ell_{i}^{\mathrm{v2t}}+\ell_{i}^{\mathrm{t2v}}), LITA=2N1i=1∑N(ℓiv2t+ℓit2v),其中B为batch size, τ 1 \tau_1 τ1为温度水平参数,N为图像-报告对总数。
3.2.2 标记对齐模块(CTA)
细粒度信息在医学领域尤为重要,因为病理只占整个图像的一小部分,报告中只有少数疾病标签描述了关键的医疗状况。考虑到在优化全局实例表示时,这些重要的细微线索可能会被忽略,我们引入了一个有效的双向跨注意力标记对齐(CTA)模块,以明确匹配和对齐医学图像和放射学报告之间的跨模态局部表示。
具体来说,对于第i个图像-报告对,生成的视觉和文本特征编码首先会被投影为标准化的低维特征 R ~ i = { r ~ i 1 , r ~ i 2 , . . . , r ~ i S } \tilde{\mathbf{R}}_i=\{\tilde{\mathbf{r}}_i^1,\tilde{\mathbf{r}}_i^2,...,\tilde{\mathbf{r}}_i^S\} R~i={r~i1,r~i2,...,r~iS}和 Z ~ i = { z ~ i 1 , z ~ i 2 , . . . , z ~ i L } \tilde{\mathbf{Z}}_i=\{\tilde{\mathbf{z}}_i^1,\tilde{\mathbf{z}}_i^2,...,\tilde{\mathbf{z}}_i^L\} Z~i={z~i1,z~i2,...,z~iL}。为了进行标记对齐,我们需要找到视觉和文本标记之间的匹配。我们使用交叉注意力机制来计算生成的视觉和文本标记之间的软匹配,而不是直接计算不同标记的余弦相似性。形式上来说,对于第i个图像-报告对的第j个视觉标记编码 r ~ i j \tilde{\mathbf{r}}_i^j r~ij,我们让其注意所有的文本标记编码,计算其对应的跨模态文本嵌入。 o i j = ∑ k = 1 N O ( α i j 2 k ( V z ~ i k ) ) , α i j 2 k = softmax ( ( Q r ~ i j ) T ( K z ~ i k ) d ) , \mathbf{o}_i^j=\sum_{k=1}^NO(\alpha_i^{j2k}(V\tilde{\mathbf{z}}_i^k)),\alpha_i^{j2k}=\text{softmax}(\frac{(Q\tilde{\mathbf{r}}_i^j)^T(K\tilde{\mathbf{z}}_i^k)}{\sqrt{d}}), oij=k=1∑NO(αij2k(Vz~ik)),αij2k=softmax(d(Qr~ij)T(Kz~ik)),其中,Q,K,V都是可以学习的矩阵。之后,我们采用Local Image-to-text Alignment (LIA) loss L L I A \mathcal{L}_\mathrm{LIA} LLIA,将 r ~ i j \tilde{\mathbf{r}}_i^j r~ij接近它的跨模态文本嵌入 o i j \mathbf{o}_i^j oij且远离其他的跨模态文本嵌入。这样可以最大化每个图像报告对内的局部跨模态互信息的下界。
考虑到不同的视觉标记具有不同的重要性(例如,包含病理的视觉标记显然比具有不相关信息的视觉标记更重要),我们在计算LIA损失时进一步为第j个视觉标记分配权重 w i j w_i^{j} wij。因此,LIA损失可以公式化为 L L I A = − 1 2 N S ∑ i = 1 N ∑ j = 1 S w i j ( log exp ( s i m ( r ~ i j , o i j ) / τ 2 ) ∑ k = 1 S exp ( s i m ( r ~ i j , o i k ) / τ 2 ) + log exp ( s i m ( o i j , r ~ i j ) / τ 2 ) ∑ k = 1 S exp ( s i m ( o i j , r ~ i k ) / τ 2 ) ) \begin{aligned}\mathcal{L}_{\mathrm{LIA}}&=-\frac{1}{2NS}\sum_{i=1}^{N}\sum_{j=1}^{S}w_i^j(\log\frac{\exp(sim(\tilde{\mathbf{r}}_i^j,\mathbf{o}_i^j)/\tau_2)}{\sum_{k=1}^{S}\exp(sim(\tilde{\mathbf{r}}_i^j,\mathbf{o}_i^k)/\tau_2)}+\log\frac{\exp(sim(\mathbf{o}_i^j,\tilde{\mathbf{r}}_i^j)/\tau_2)}{\sum_{k=1}^{S}\exp(sim(\mathbf{o}_i^j,\tilde{\mathbf{r}}_i^k)/\tau_2)})\end{aligned} LLIA=−2NS1i=1∑Nj=1∑Swij(log∑k=1Sexp(sim(r~ij,oik)/τ2)exp(sim(r~ij,oij)/τ2)+log∑k=1Sexp(sim(oij,r~ik)/τ2)exp(sim(oij,r~ij)/τ2))其中 τ 2 \tau_2 τ2是标记级别的温度超参数。与实例对齐相同的是,这里也使用了两个对称的InfoNCE损失,分别将视觉标记嵌入 r ~ i j \tilde{\mathbf{r}}_i^j r~ij和其跨模态文本嵌入 o i j \mathbf{o}_i^j oij作为查询。需要注意的是,我们将 w i j w_i^{j} wij设置为从第j个视觉标记到[CLS]标记的最后一层注意力权重,该权重在多个头部中平均。
类似地,对于在第i个图像-报告对中嵌入的第j个文本标记嵌入 z ~ i j \tilde{\mathbf{z}}_i^j z~ij,我们也以相同的方式计算跨模态图像嵌入 o ^ i j \hat{\mathbf{o}}_i^j o^ij,并通过将 z ~ i j \tilde{\mathbf{z}}_i^j z~ij与 o ^ i j \hat{\mathbf{o}}_i^j o^ij进行对比来构建本地文本到图像对齐(LTA)损失LLTA。CTA模块的最终目标是LIA和LTA损失的组合: L C T A = 1 2 ( L L I A + L L T A ) \mathcal{L}_\mathrm{CTA}=\frac12(\mathcal{L}_\mathrm{LIA}+\mathcal{L}_\mathrm{LTA}) LCTA=21(LLIA+LLTA)
3.2.3 疾病层面的跨模态对齐
ITA和CTA方法将来自不同实例的样本均视为负对,导致许多具有相似高层语义(如疾病)的样本对在嵌入空间中被不恰当地推远。因此,我们设计了跨模态原型对齐(CPA)模块,以利用医学图像和报告之间的跨模态主体间对应关系。
对于步骤①中的每个图像-报告嵌入对 ( v i , t i ) (v_i, t_i) (vi,ti),采用迭代Sinkhorn-Knopp聚类算法分别生成两个软聚类分配码 q v , i ∈ R K 和 q t , i ∈ R K q_{v,i} ∈ R^K 和 q_{t,i} ∈ R^K qv,i∈RK和qt,i∈RK,将 v i v_i vi 和 t i t_i ti分配到 K 个聚类中。同时,我们预定义 K 个可训练的跨模态原型 C = c 1 , . . . , c K C = {c_1,..., c_K} C=c1,...,cK,其中 c k ∈ R d c_k ∈ R^d ck∈Rd。接着,计算图像嵌入 v i v_i vi与所有跨模态原型 C 的余弦相似度的视觉softmax概率 p v , i ∈ R K p_{v,i} ∈ R^K pv,i∈RK,以及文本嵌入 t i t_i ti与所有跨模态原型 C 的余弦相似度的文本softmax概率 p t , i ∈ R K p_{t,i} ∈ R^K pt,i∈RK。公式中 τ 3 τ_3 τ3是原型层温度参数,(k) 表示向量的第 k 个元素。
为实现跨模态疾病层面(即原型)对齐,我们通过跨模态预测并优化以下两个交叉熵损失:
ℓ
(
v
~
i
,
q
t
,
i
)
=
∑
k
=
1
K
q
t
,
i
(
k
)
log
p
v
,
i
(
k
)
,
ℓ
(
t
~
i
,
q
v
,
i
)
=
∑
k
=
1
K
q
v
,
i
(
k
)
log
p
t
,
i
(
k
)
.
\ell(\tilde{\mathbf{v}}_i,\mathbf{q}_{t,i})=\sum_{k=1}^K\mathbf{q}_{t,i}^{(k)}\log\mathbf{p}_{v,i}^{(k)},\quad\ell(\tilde{\mathbf{t}}_i,\mathbf{q}_{v,i})=\sum_{k=1}^K\mathbf{q}_{v,i}^{(k)}\log\mathbf{p}_{t,i}^{(k)}.
ℓ(v~i,qt,i)=k=1∑Kqt,i(k)logpv,i(k),ℓ(t~i,qv,i)=k=1∑Kqv,i(k)logpt,i(k).
将文本软聚类分配码
q
t
,
i
q_{t,i}
qt,i 作为“伪标签”训练图像表示
v
~
i
ṽ_i
v~i;将图像软聚类分配码
q
v
,
i
q_{v,i}
qv,i 作为“伪标签”训练报告表示
t
i
t_i
ti。
最终,CPA模块的总体损失是所有图像-报告对的平均预测损失:
L C P A = 1 2 N Σ i = 1 N ( l ( v ~ i , q t , i ) + l ( t ~ i , q v , i ) ) L_{CPA }=\frac{1}{2N} Σ_{i=1}^{N} (l(ṽ_i, q_{t,i}) + l(t̃_i, q_{v,i})) LCPA=2N1Σi=1N(l(v~i,qt,i)+l(t~i,qv,i))
3.2.4 总训练目标
通过联合优化三个跨模态对齐模块来训练MGCA框架,鼓励网络学习区分性和通用性的医学图像表示。总体培训目标可以表示为:
L
=
λ
1
∗
L
I
T
A
+
λ
2
∗
L
C
T
A
+
λ
3
∗
L
C
P
A
\mathcal{L}=\lambda_1*\mathcal{L}_\mathrm{ITA}+\lambda_2*\mathcal{L}_\mathrm{CTA}+\lambda_3*\mathcal{L}_\mathrm{CPA}
L=λ1∗LITA+λ2∗LCTA+λ3∗LCPA


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









