






前言:
由于我的一门课程需要用FlashRAG来跑数据集。我在复现的过程中也是遇到了各种各样的坑,特别是环境的搭建和配置的填写。最后还是跑成功了。于是,就想着和大家分享一下复现的经验。有任何问题,或是理解错误的地方,也欢迎大家指出。谢谢。
1.环境配置:
我这里用的是conda环境,创建的时候使用python3.9+(我用的3.9.20)。
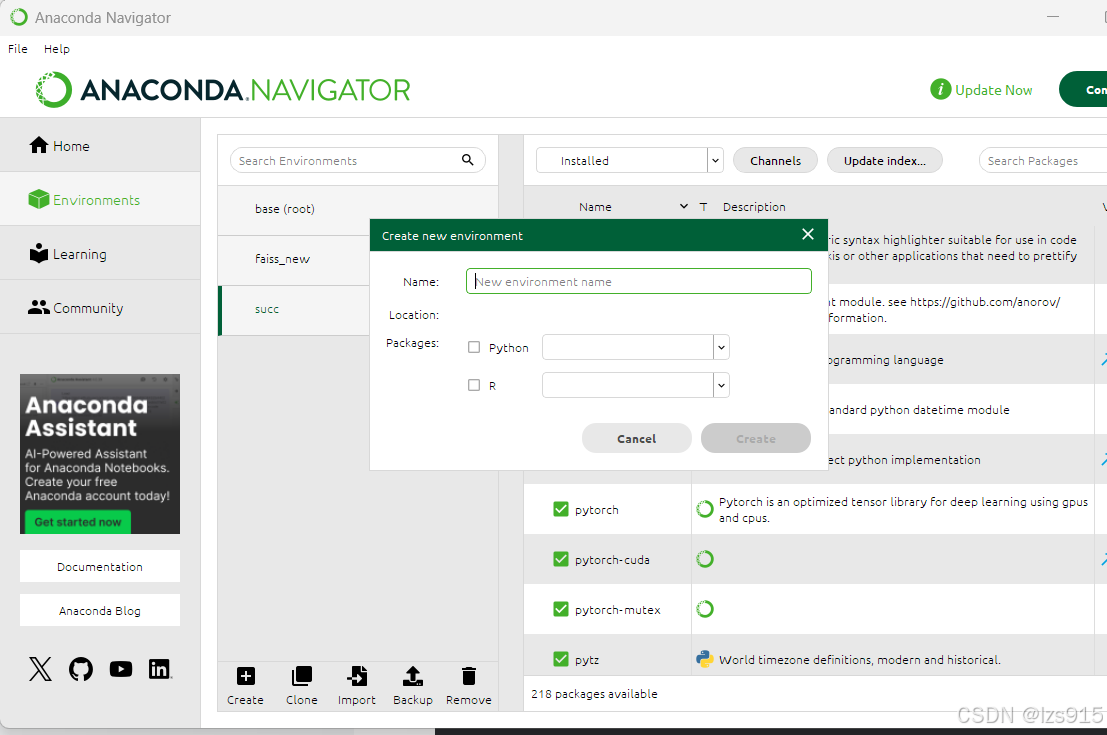
1.clone
打开anaconda prompt 运行 conda activate (你创建的环境名)后面所有涉及终端的操作,都需要进入你的conda环境去运行。也就是命令行前面有个(你的conda环境名)我这里是succ
进入一个你想要存放FlashRag的目录,然后运行
git clone https://github.com/RUC-NLPIR/FlashRAG.git
然后 进入该目录
cd FlashRAG
运行
pip install -e .
2.pycharm配置环境
进入File->setting
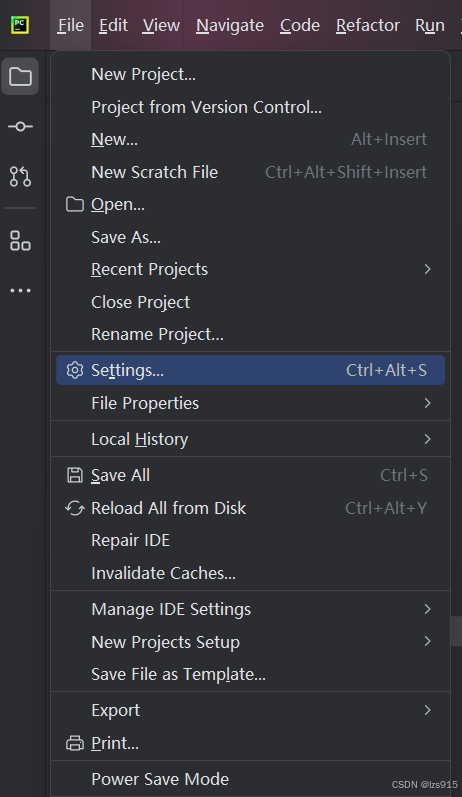
project->python Interpreter
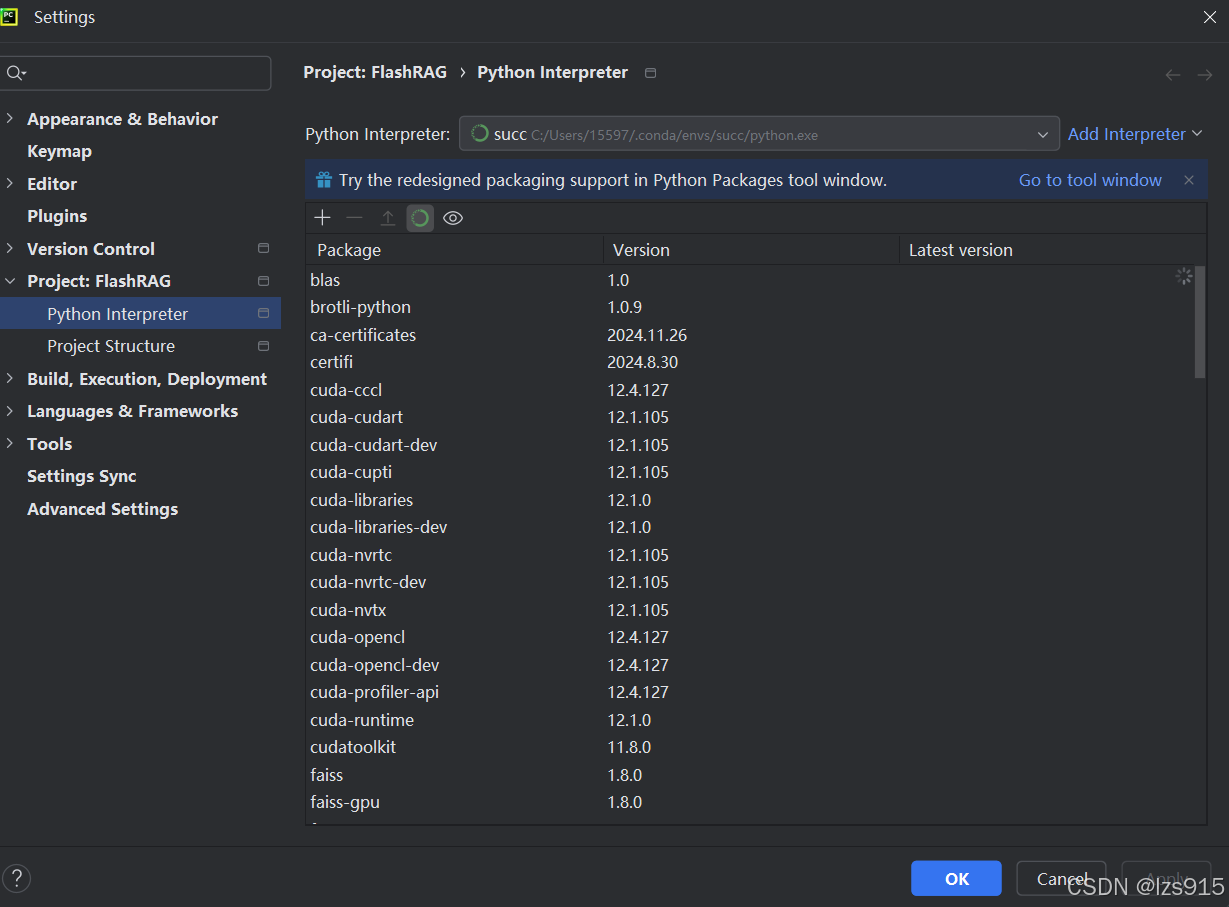
点击 add Interpreter

这里在conda executable选择你的conda安装路径,然后下面选择你的环境
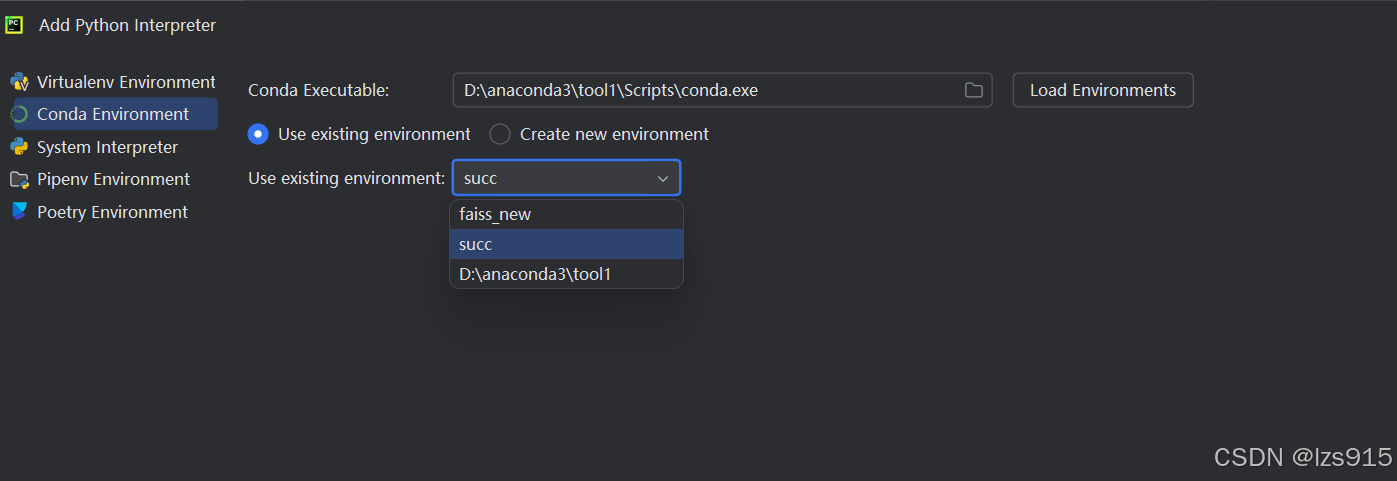
然后pycharm就ok了
3.下载配置
以下这些可以选择选择下载,全部不下载也可以运行,vllm等只是加速运行。且vllm上有个模块triton需要linux环境。于是我都没有使用。
# Install all extra dependencies pip install flashrag[full] # Install vllm for faster speed pip install vllm>=0.4.1 # Install sentence-transformers pip install sentence-transformers # Install pyserini for bm25 pip install pyserini
选择cpu或者gpu版本的faiss安装
# CPU-only version conda install -c pytorch faiss-cpu=1.8.0 # GPU(+CPU) version conda install -c pytorch -c nvidia faiss-gpu=1.8.0
安装PyTorch<-点击其进入网站
搜索cmd,点击命令提示符
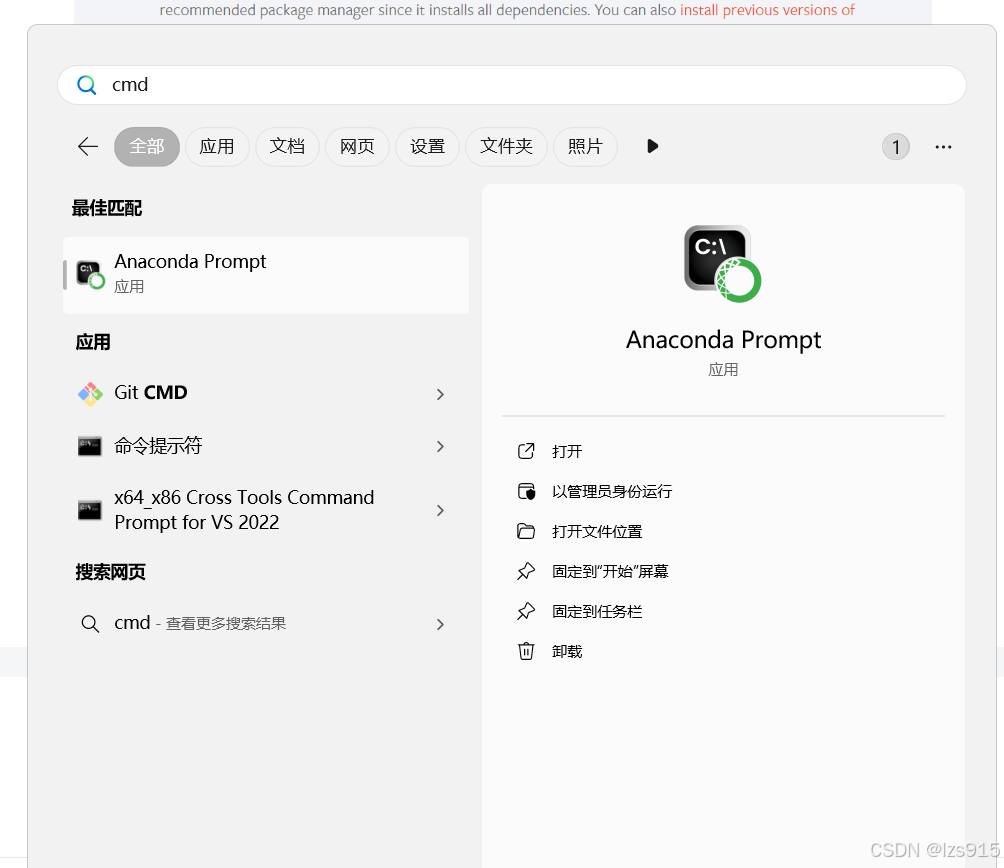
运行
nvidia-smi
然后可以看见CUDA Version 然后上面PyTorch网站中的选项 Computer platform可以选择cuda版本小于本机版本的,我可以选择12.4 12.1都可以
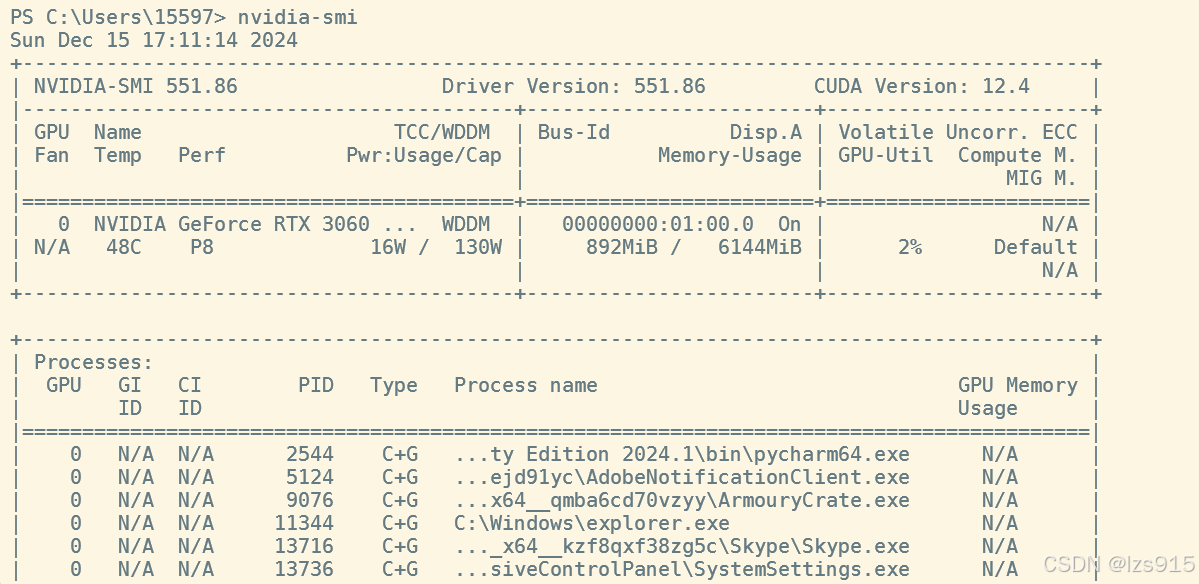 然后我运行网站生成的命令(这里运行你们自己对应生成的)
然后我运行网站生成的命令(这里运行你们自己对应生成的)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
然后到了这里基本环境就配置ok了,如果遇到什么报错可以尝试去搜一下。我在这里放出我的conda全部插件的版本,大家可以参考一下,毕竟很容易遇到版本冲突的问题。




4.下载模型
FlashRag作者推荐下载以下两个模型: - E5-base-v2 - Llama2-7B-Chat 模型的下载可以通过[Huggingface](https://huggingface.co/intfloat/e5-base-v2)。如果是中国用户,推荐使用镜像平台[hf-mirror](https://hf-mirror.com/)进行下载。
我选择下载了E5-base-v2(进入FlashRag 运行 git clone https://hf-mirror.com/intfloat/e5-base-v2), BAAI/bge-small-zh-v1.5(git clone https://hf-mirror.com/BAAI/bge-small-zh-v1.5),Qwen/Qwen1.5-0.5B-Chat(git clone https://hf-mirror.com/Qwen/Qwen1.5-0.5B-Chat)。
2.运行demo:
1.配置demo_zh.py
在FlashRAG\examples\quick_start\demo_zh.py有一个demo_zh.py 和\FlashRAG\examples\quick_start\demo_en.py 有一个demo_en.py分别是中文demo和英文demo。这里我们以中文demo举例子。
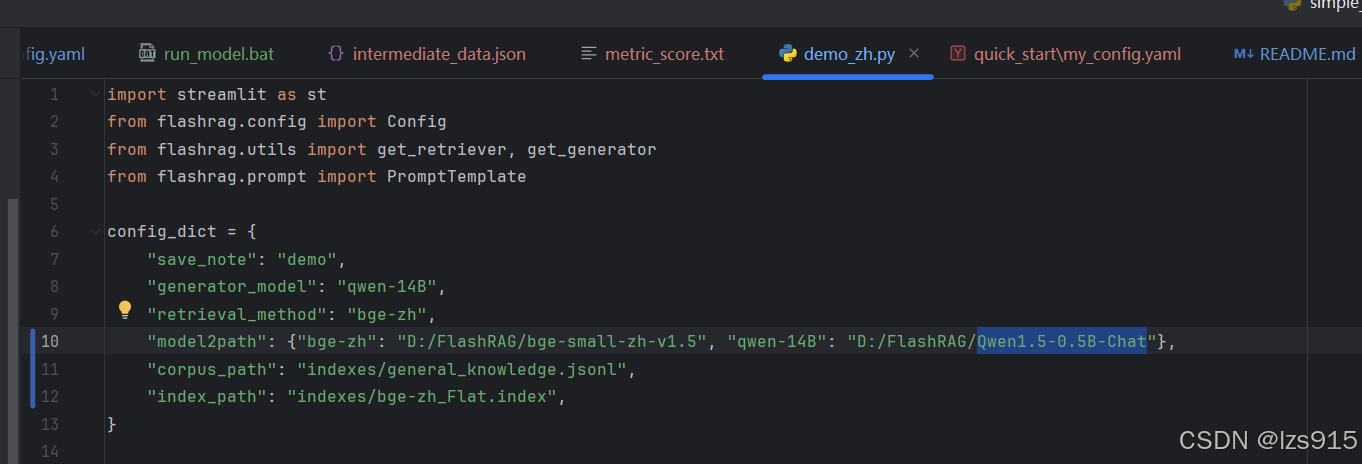
在config里面需要填写自己想用的生成器模型和检索器模型和其地址。
config_dict = {
"save_note": "demo",
"generator_model": "qwen-14B", //填写你要用的模型,得上一步已经下载的
"retrieval_method": "bge-zh", //填写你要用的模型,得上一步已经下载的
"model2path": {"bge-zh": "D:/FlashRAG/bge-small-zh-v1.5", "qwen-14B": "D:/FlashRAG/Qwen1.5-0.5B-Chat"}, //填写绝对地址 记得都要使用/,不能用\
"corpus_path": "indexes/general_knowledge.jsonl",//这个我是用默认文档集作者提供的,你们那里也会有
"index_path": "indexes/bge-zh_Flat.index", //这个index我后面会告诉你如何生成
如果你使用的是模型,作者有提供默认index,在../examples/quick_start/indexes/e5_Flat.index使用其他检索器的看我下一步 生成index 生成完成后的index填这里就ok了。
}
2.生成index
进入FlashRAG\flashrag\retriever下
我们需要做的是创建一个名为run_indexing.bat的文件(或者其他名字也行),然后根据你想要用的模型去填写。FlashRAG\docs\building-index.md这里是作者关于生成index的讲解,你如果需要用到sentence transformers插件,就可以按照里面的模板去填写。这里我放到其他index里面了
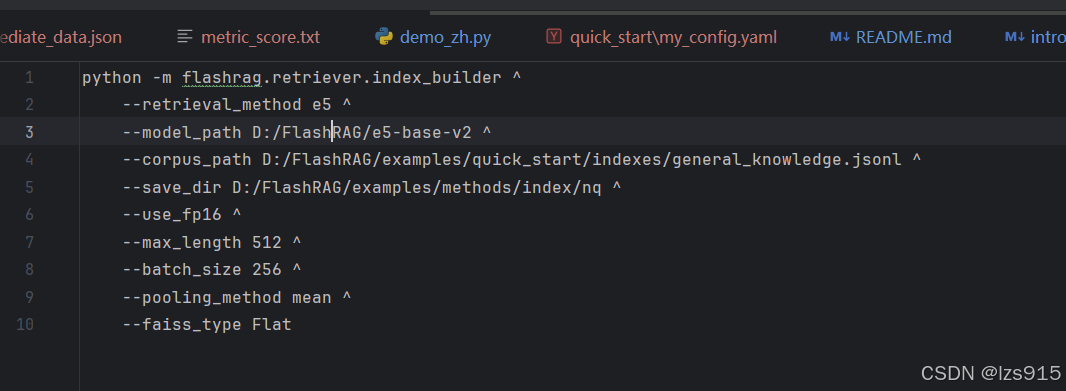
python -m flashrag.retriever.index_builder ^
--retrieval_method e5 ^
--model_path D:/FlashRAG/e5-base-v2 ^ //模型路径
--corpus_path D:/FlashRAG/examples/quick_start/indexes/general_knowledge.jsonl ^ //语料库,这里我用作者提供默认的
--save_dir D:/FlashRAG/examples/methods/index/nq ^ //储存的位置
--use_fp16 ^
--max_length 512 ^
--batch_size 256 ^
--pooling_method mean ^
--faiss_type Flat
填写完以后,命令行进入FlashRAG\flashrag\retriever下,运行刚刚写出来的run_indexing.bat
![]()
运行成功,就会出现以下结果,然后在你刚刚填的--save_dir D:/FlashRAG/examples/methods/index/nq ^ //储存的位置 就会出现该index。

index和检索器模型和语料库文档也就是corpus有关,如果你用相同的模型,相同的语料库去跑不同的数据集。就不用去重新生成index。
3.其他index
If the retrieval model support `sentence transformers` library, you can use following code to build index (**no need to consider pooling method**).
```bash
python -m flashrag.retriever.index_builder \
--retrieval_method e5 \
--model_path /model/e5-base-v2/ \
--corpus_path indexes/sample_corpus.jsonl \
--save_dir indexes/ \
--use_fp16 \
--max_length 512 \
--batch_size 256 \
--pooling_method mean \
--sentence_transformer \
--faiss_type Flat
```
#### For sparse retrieval method (BM25)
If building a bm25 index, there is no need to specify `model_path`.
##### Use BM25s to build index
```bash
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend bm25s \
--save_dir indexes/
```
##### Use Pyserini to build index
```bash
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend pyserini \
--save_dir indexes/
```
4.配置config
打开\FlashRAG\examples\methods\my_config.yaml 这个文件
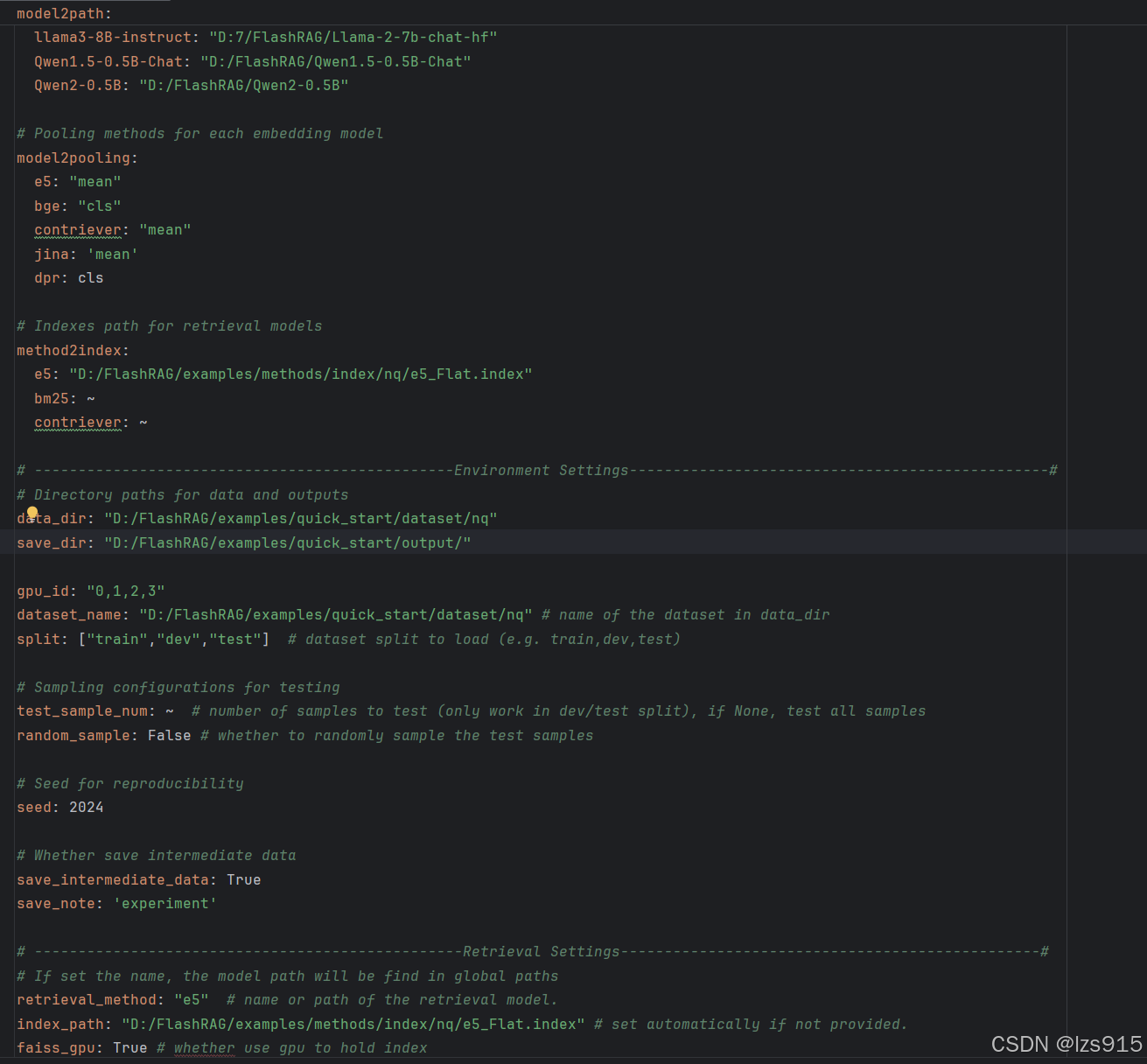
model2path: //填写可能用到的模型,及其本地路径,注意需要使用/ e5: "D:/FlashRAG/ab/e5-base-v2" bge: "D:/FlashRAG/bge-small-zh-v1.5" contriever: "facebook/contriever" llama2-7B-chat: "D:/Users/15597/FlashRAG/Llama-2-7b-chat-hf" llama2-7B: "D:/FlashRAG/Llama-2-7b-chat-hf" llama2-13B: "D:/FlashRAG/Llama-2-7b-chat-hf" llama2-13B-chat: "D:7/FlashRAG/Llama-2-7b-chat-hf" llama3-8B-instruct: "D:7/FlashRAG/Llama-2-7b-chat-hf" Qwen1.5-0.5B-Chat: "D:/FlashRAG/Qwen1.5-0.5B-Chat" Qwen2-0.5B: "D:/FlashRAG/Qwen2-0.5B"
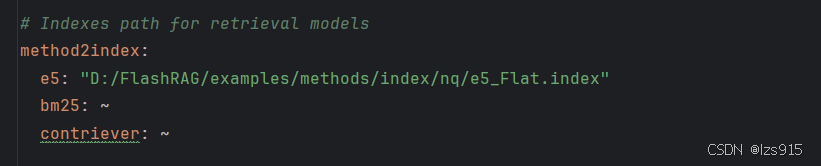
method2index: e5: "D:/FlashRAG/examples/methods/index/nq/e5_Flat.index"//填写上一步处理好的index,别忘了demo_zh.py中也需要添加 bm25: ~ contriever: ~
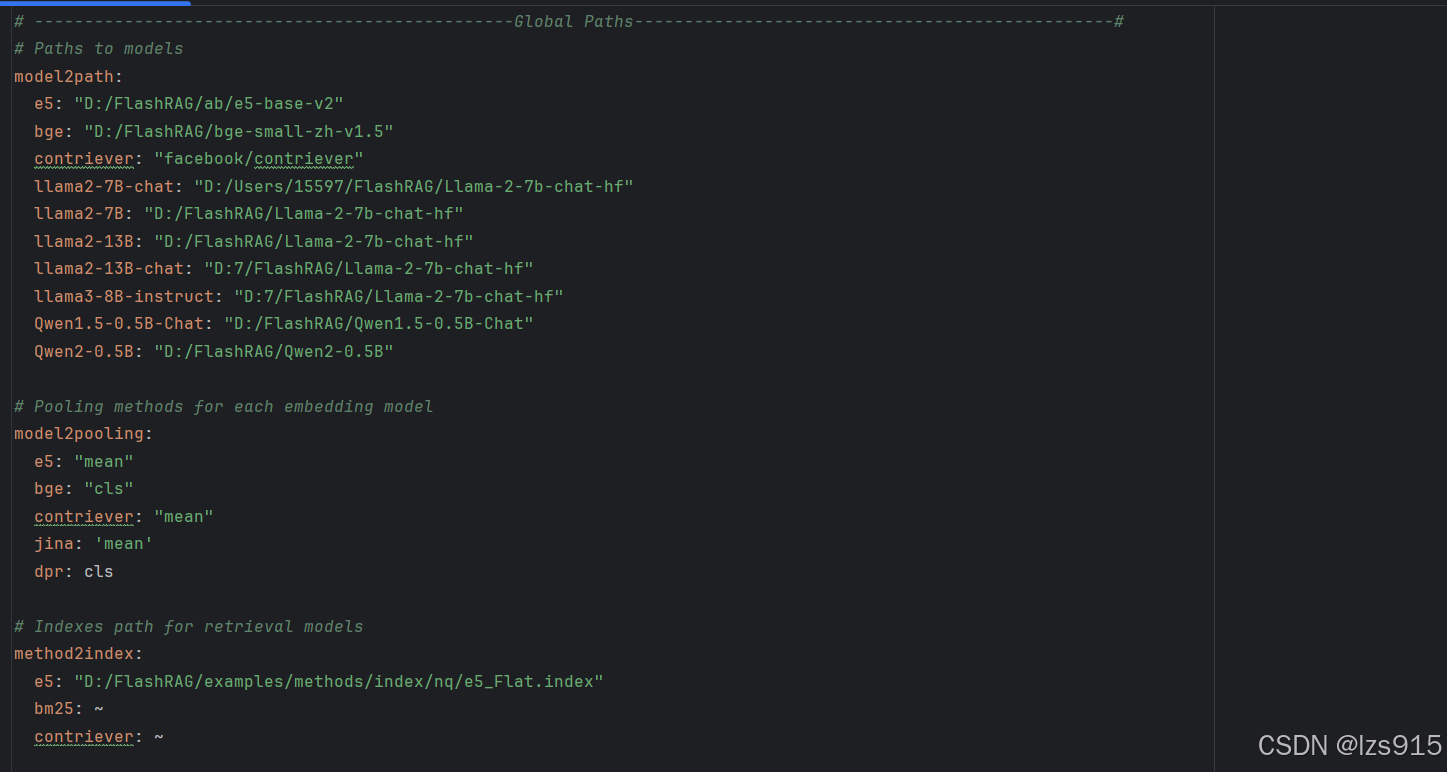
# Directory paths for data and outputs data_dir: "D:/FlashRAG/examples/methods/dataset/wiki" //数据集路径,但是运行demo不涉及这个,可以改,后面跑训练集的时候会说 save_dir: "D:/FlashRAG/examples/methods/output/" //这个是训练结果存放的地方
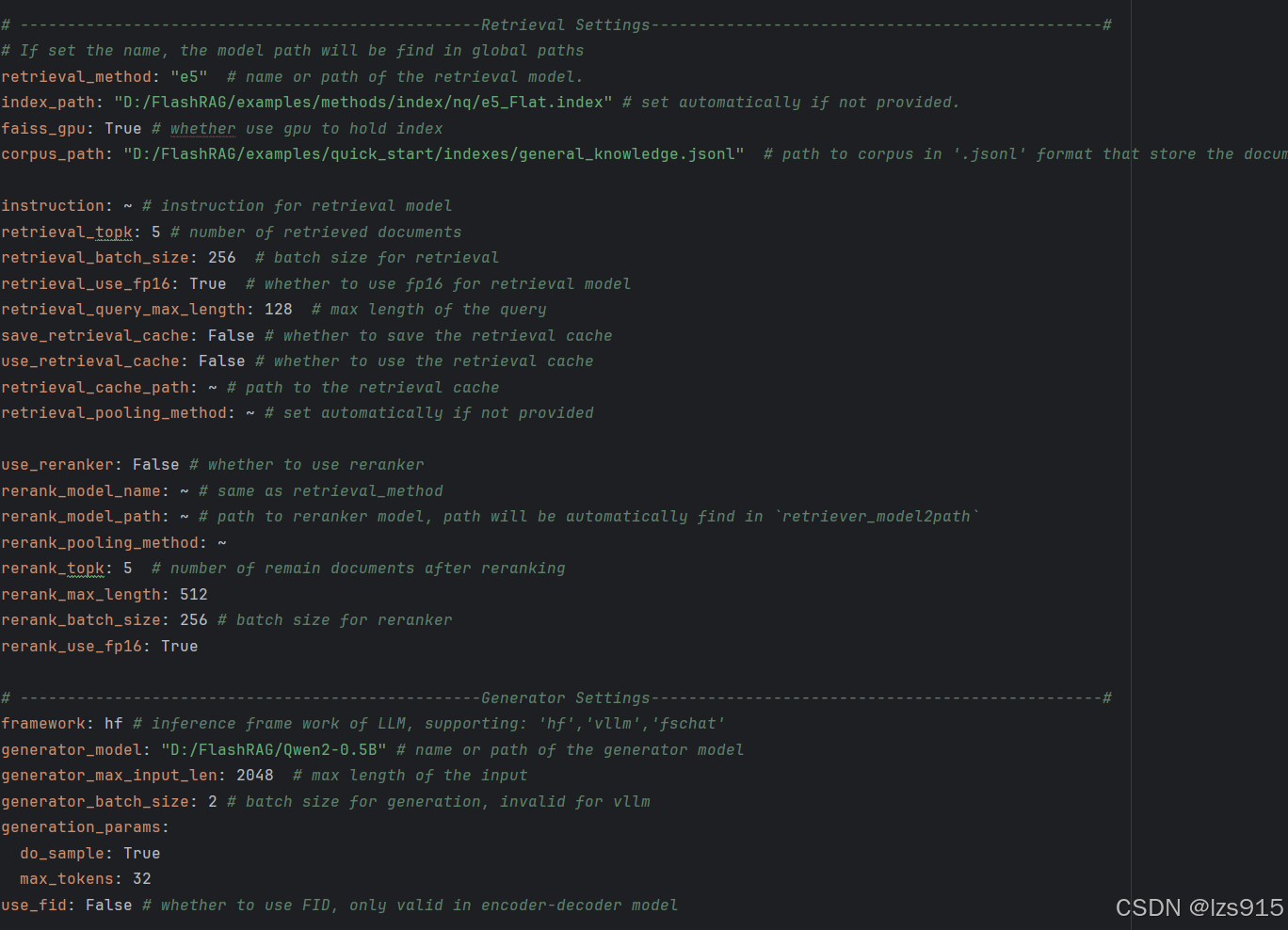
# -------------------------------------------------Retrieval Settings------------------------------------------------# # If set the name, the model path will be find in global paths retrieval_method: "e5" # name or path of the retrieval model. //填写检索器模型 index_path: "D:/FlashRAG/examples/methods/index/nq/e5_Flat.index" # set automatically if not provided. //填写index faiss_gpu: True # whether use gpu to hold index //看你的faiss是否支持gpu corpus_path: "D:/FlashRAG/examples/quick_start/indexes/general_knowledge.jsonl" # path to corpus in '.jsonl' format that store the documents
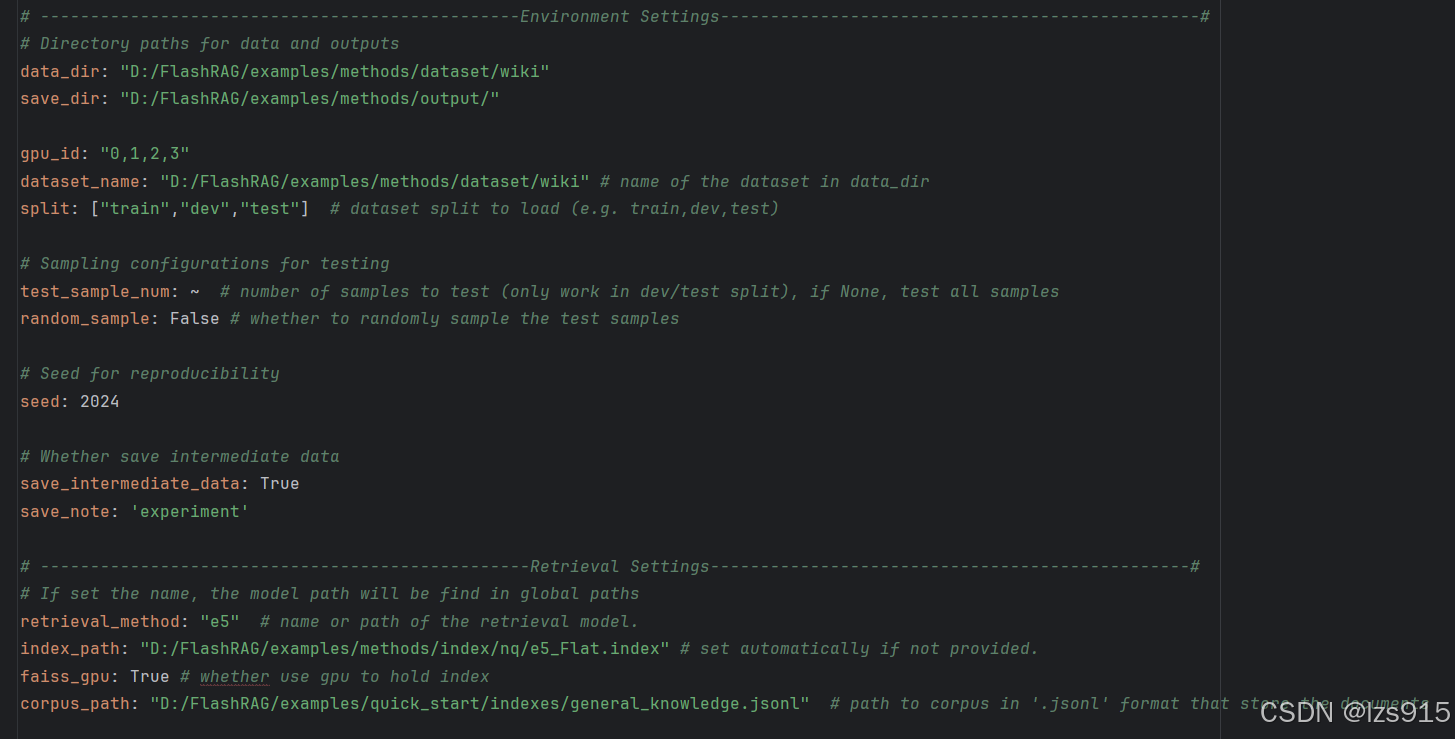
framework: hf # inference frame work of LLM, supporting: 'hf','vllm','fschat' //由于没有使用vllm,所以填hf generator_model: "D:/FlashRAG/Qwen2-0.5B" # name or path of the generator model //生成器模型 generator_max_input_len: 2048 # max length of the input generator_batch_size: 2 # batch size for generation, invalid for vllm generation_params: do_sample: True max_tokens: 32 use_fid: False # whether to use FID, only valid in encoder-decoder model
5.运行demo.py
命令行(需要conda环境下)进入cd examples/quick_start这个路径下
运行
streamlit run demo_zh.py
如果是demo_en
streamlit run demo_en.py
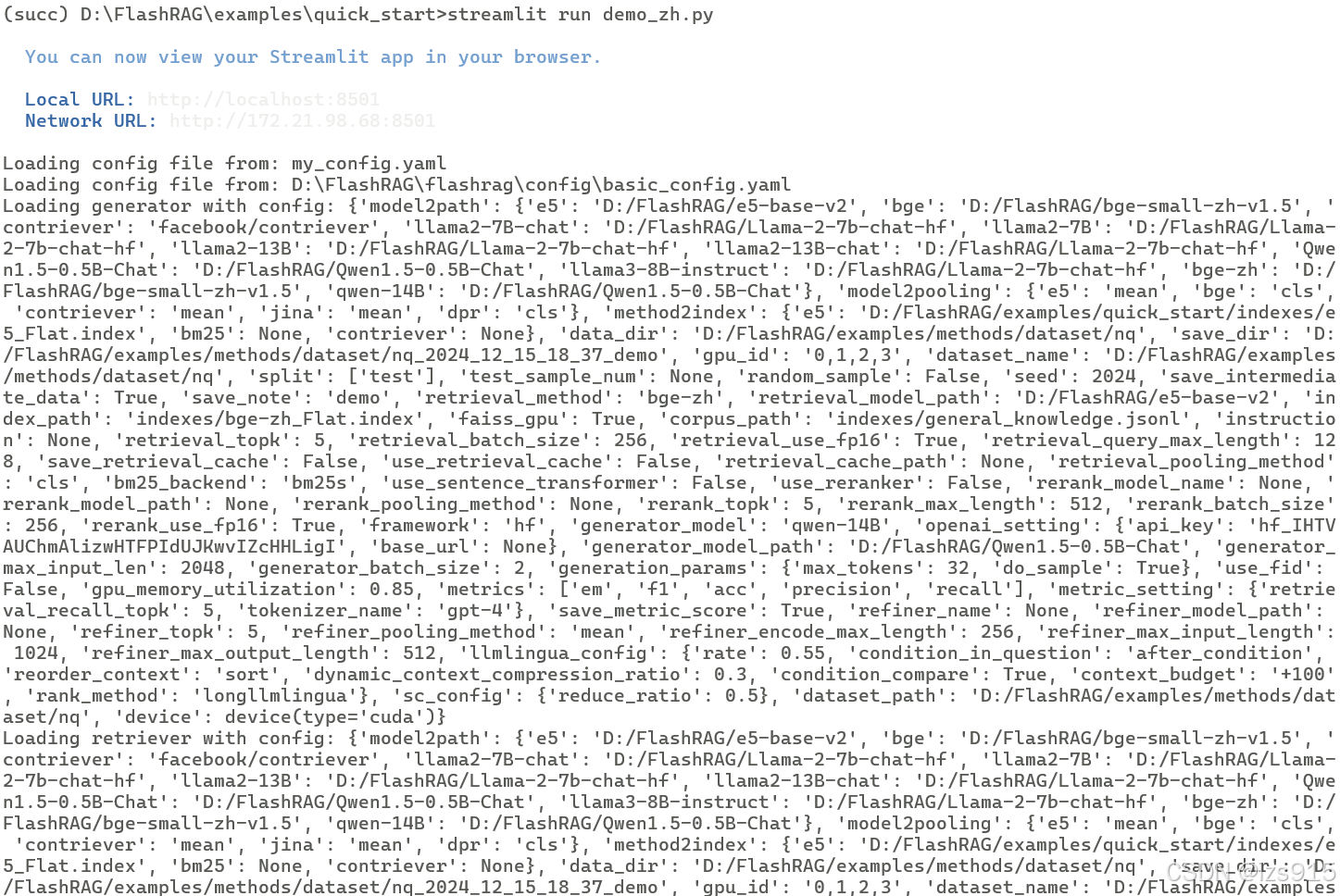
命令行显示:
浏览器显示:
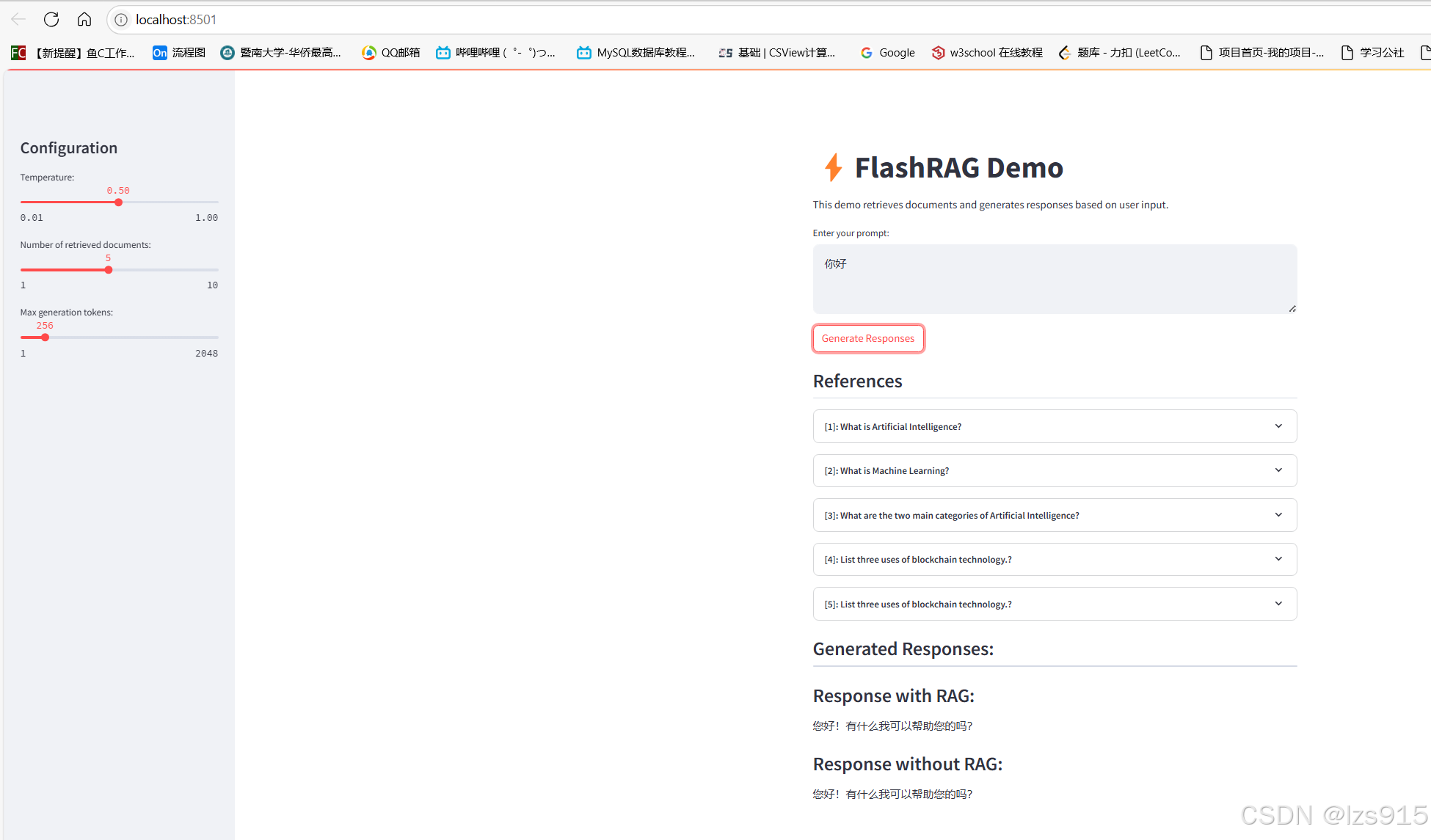
然后就可以简单使用这个rag算法及你使用的模型来使用。
3.跑训练集:
对于一些需要使用额外模型的方法,需要额外的步骤。具体可以参考\FlashRAG\docs\reproduce_experiment_zh.md
这里就不在赘述。
1.训练集格式:
这里就用作者提供的训练集(../examples/quick_start/dataset/nq/)和index,e5检索器来做一个示范。若想要用其他数据集可以去RUC-NLPIR/FlashRAG_datasets · Datasets at Hugging Face下载,语料库文档也是(RUC-NLPIR/FlashRAG_datasets at mainRUC-NLPIR/FlashRAG_datasets at mainRUC-NLPIR/FlashRAG_datasets at main)。当然使用了新的语料库就需要重新构建index。
如果要自己处理训练集,则需要处理为以下格式:

通常训练集由以下3个jsonl组成(dev,train,test)
以下是作者原话。
所有使用的代码都基于仓库的 [example/methods](../examples/methods/)。我们为各种方法设置了适当的超参数。如果你需要自己调整它们。
首先,你需要在 `my_config.yaml` 中填写各种下载的路径。具体来说,你需要填写以下四个字段: - **model2path**:用你自己的路径替换 E5 和 Llama3-8B-instruct 模型的路径 - **method2index**:填写使用 E5 构建的索引文件的路径 - **corpus_path**:填写 `jsonl` 格式的 Wikipedia 语料库文件的路径 - **data_dir**:更改为你自己的数据集下载路径
2.处理config
需要更改\FlashRAG\examples\methods\my_config.yaml下的各个设定,设置成你想跑的模型,数据集。其实改这个周围都有英文注释。比较重要的其实就是数据集在哪,模型在哪,index在哪,用哪个模型当检索器,用哪个模型当检索器,这几个主要参数的填写,这里我就不细说了,大家可以看我的和默认的我改了哪些,然后你改成你路径下,你想用的就ok了。
然后config就处理完成了。
3.处理.bat
主要是通过运行\FlashRAG\examples\methods\run_exp.py文件来进行文件的训练,其需要我们输入一些参数来调动我们希望使用的方法,和训练的训练集。
有以下几种方法
naive zero-shot AAR-contriever llmlingua recomp selective-context sure replug skr flare iterretgen ircot trace
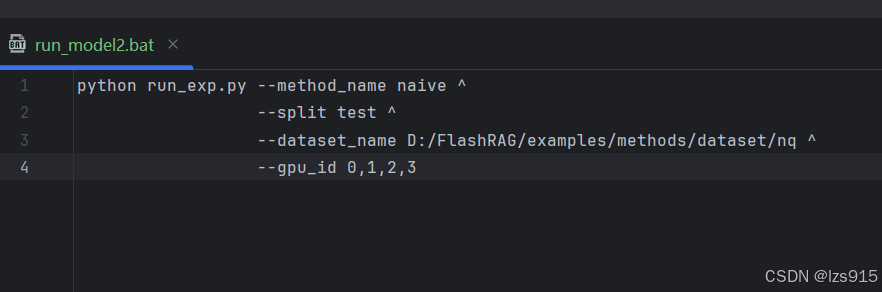
在\FlashRAG\examples\methods/下创建run_model2.bat文件
python run_exp.py --method_name naive ^ //方法之一,你可以填你想用的
--split test ^ //指定数据集的分割类型为 test,通常表示验证集。如果是跑测试
--dataset_name D:/FlashRAG/examples/methods/dataset/nq ^//你想跑的数据集位置,如果是作者提供的nq,你就写你电脑上nq的位置。
--gpu_id 0,1,2,3
然后控制台进入FlashRAG\examples\methods/运行run_model2.bat
这就是在跑训练集了,上面几行输出是我自己改代码的,你们没有很正常。
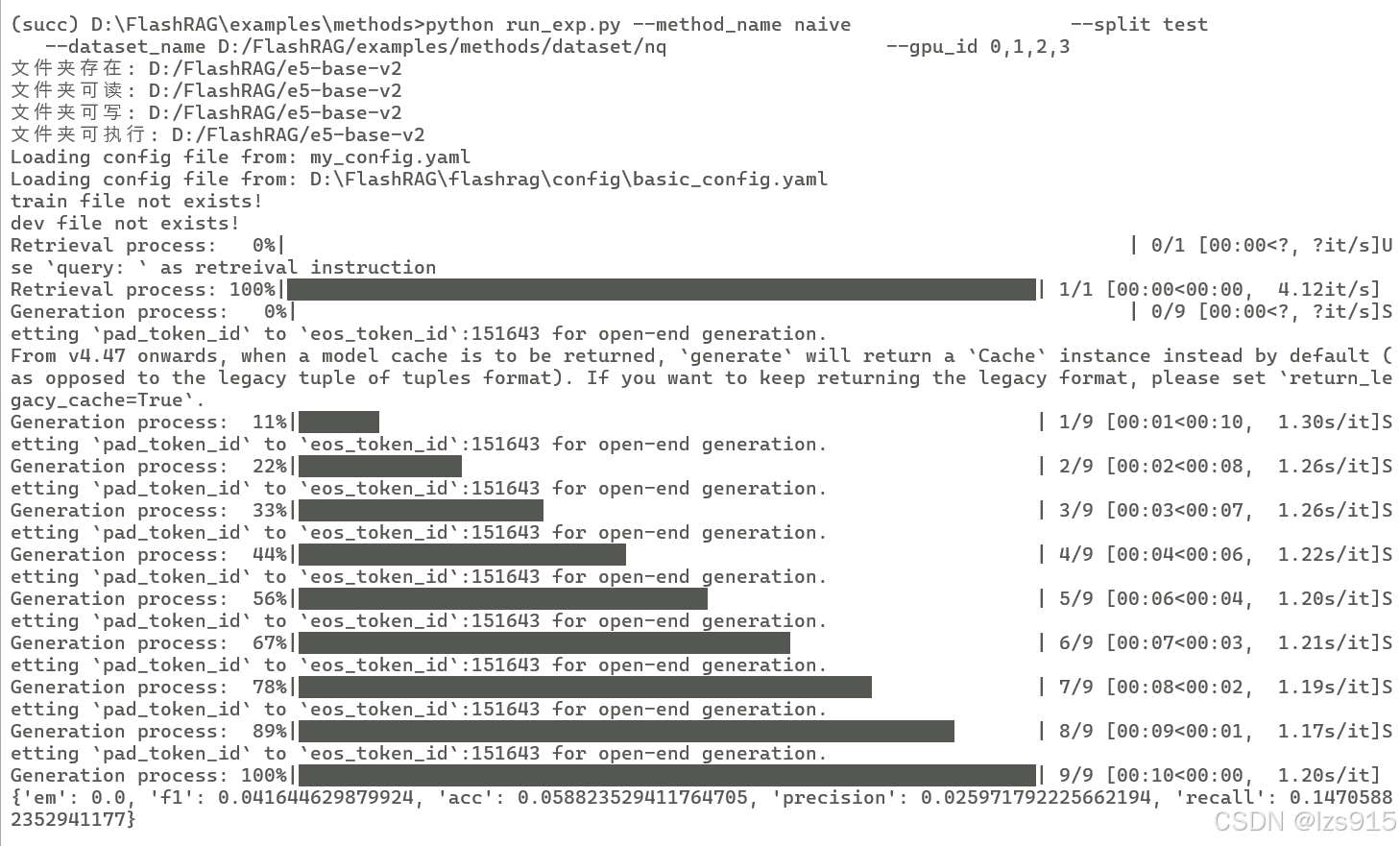
对应位置就会出现如下输出,包括指标什么的。
好了,到了这一步大家也基本理解该如何替换各个部分,然后去个性化训练自己的数据集和模型。
4.遇到的问题:
1.权限问题
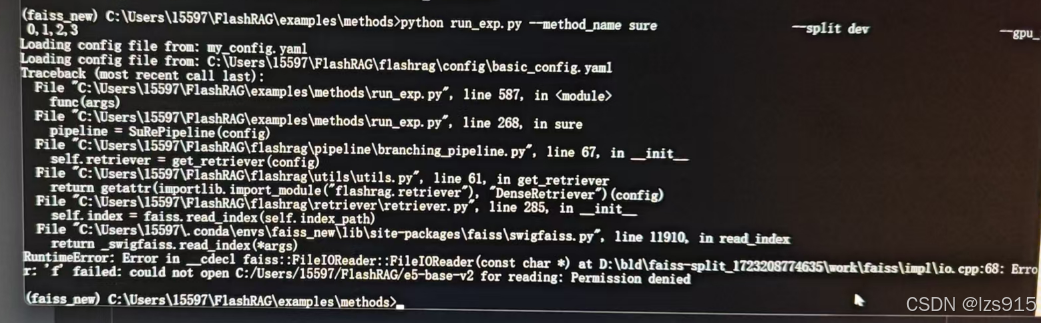
在3.跑训练集中的3.处理.bat中,显示faiss没权限,当时我找了很多解决办法,有的说路径不能有中文,这个我排除了。
然后文件属性安全也全开权限。
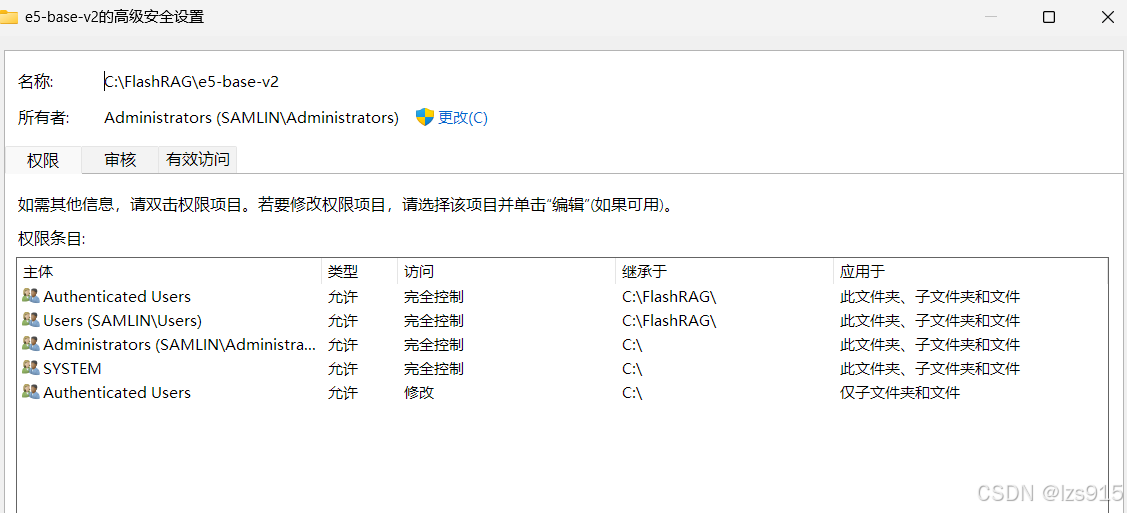
管理员模式运行也不行
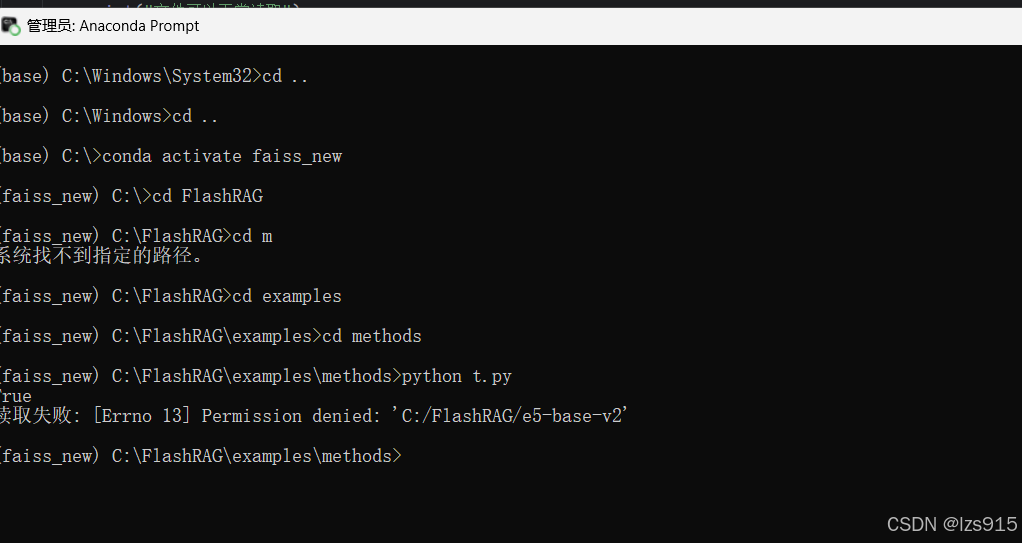
然后我尝试用代码去排除问题。
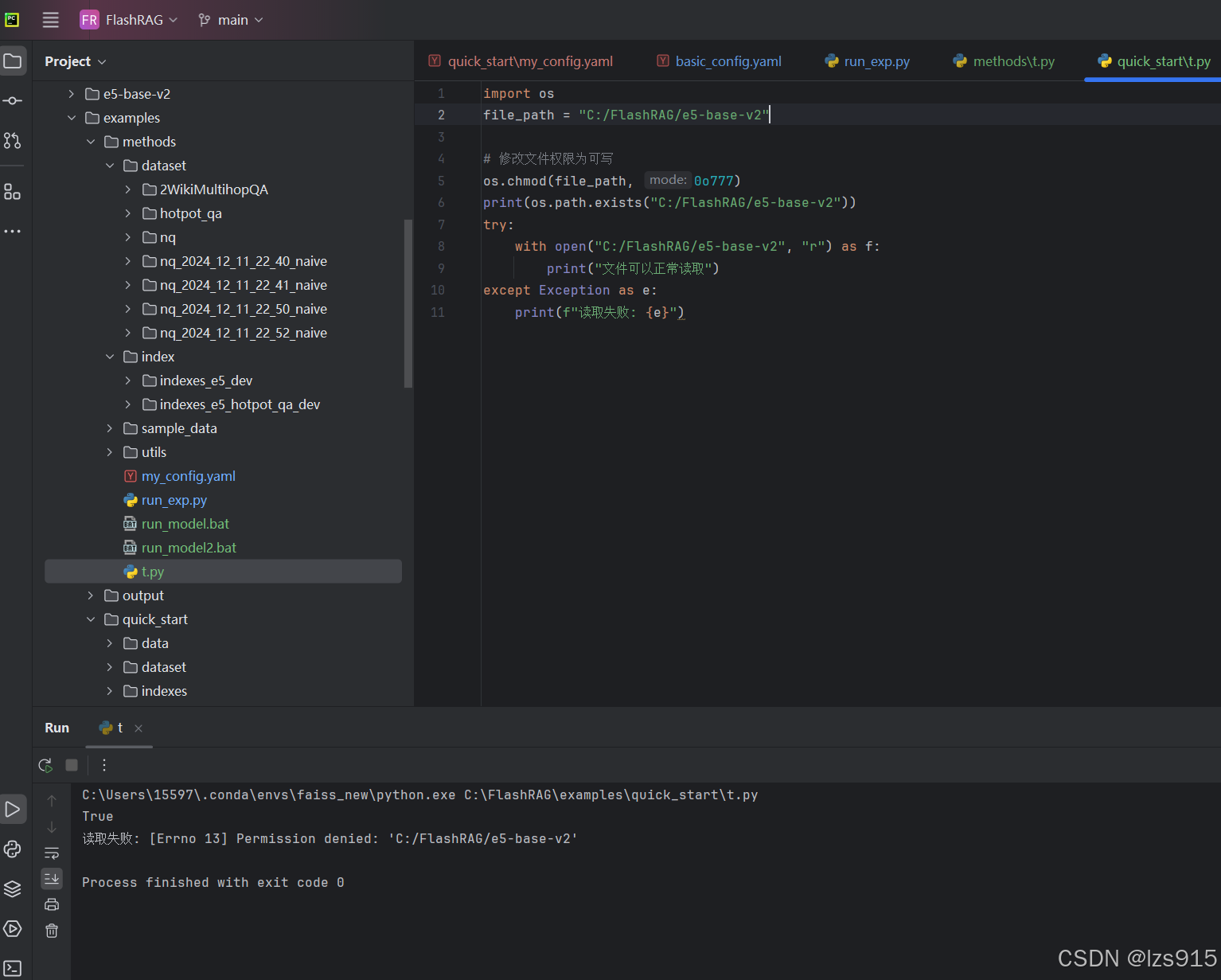
大家看出什么问题了吗
我在尝试读取一个文件夹,那怎么可能不报错对吧。还是太粗心了。
以下2个要填index路径的,被我填写成了e5的路径。当然我上面写的步骤已经帮大家规避了这个问题。

2.OMP问题
报错OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方法:
1. 确认只有一个版本的 libiomp5md.dll
搜索系统中的 libiomp5md.dll 文件。
删除或重命名重复的 libiomp5md.dll 文件,确保程序只加载一个版本。
2. 设置环境变量避免冲突
如果无法解决冲突,可以设置 KMP_DUPLICATE_LIB_OK 环境变量作为临时解决方案:
命令行设置(临时生效):
cmd打开命令行
输入set KMP_DUPLICATE_LIB_OK=TRUE
永久设置(Windows 系统):
打开 控制面板 > 系统 > 高级系统设置。
点击 环境变量。
新增系统变量:
名称:KMP_DUPLICATE_LIB_OK
值:TRUE
⚠️ 注意:此方法只是临时规避问题,可能导致性能下降或错误结果,不推荐作为长期解决方案。
3. 避免加载冲突的库
我这里选择了永久设置。不想再升级插件,到时候又出现不兼容,秉承着能用就不改的原则。
5.个人总结
在完成整个复现的过程,我深深感受到复现这个项目对于没有人工智能基础的人来说的困难。各种配置上的报错,插件之间不兼容,配置文件填写的要求。包括我一开始甚至没下载模型到本地就想跑通(实在是异想天开)。所以我也写了这个FlashRAG复现指南,希望可以帮助到大家。然后大家记得多读文档。在\FlashRAG\docs下,有作者提供的大量文档(我也是吃了一开始没看到的亏,导致遇到很多问题),然后还有\FlashRAG\README.md。本文也是基于以上文档调试出来的经验。感谢观看!

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









