







目录
一. 插入查询结果
将一张表 (表1) 中数据的查询结果插入到另外一张表 (表2) 中
要求另外一张表(表2)的表结构必须与查询结果的结果相同才可进行插入操作 (列的个数,每列的类型)
insert into 表1 select 列名 from 表2;
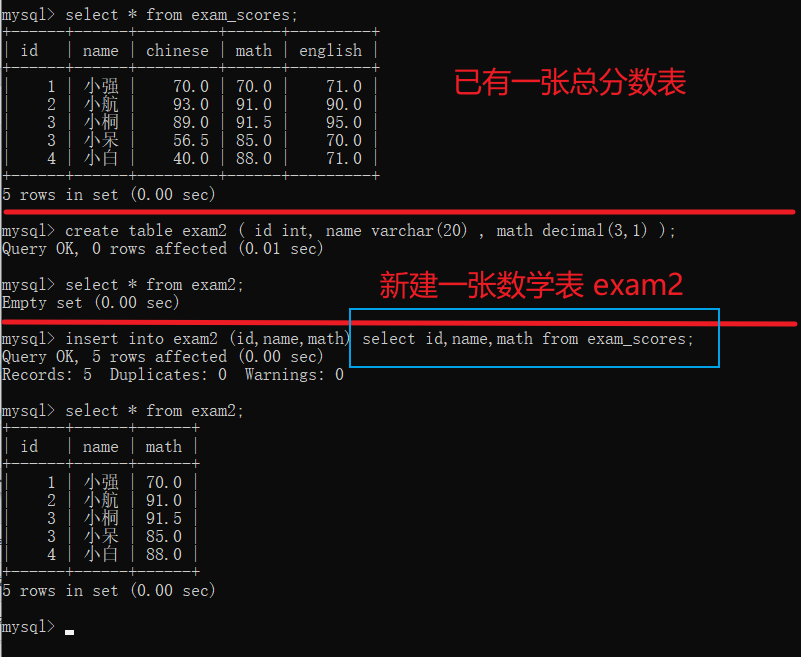
插入 对exam_scores表中 id,name,math 的查询结果,然后再查询exam2就不再是空表了
二. 聚合查询
在表达式查询中,我们通过表达式可以实现 列和列之间 的运算
而通过聚合查询,我们可以实现表中 行和行之间 的运算
聚合查询依赖于聚合函数,聚合函数是有 SQL 提供的 库函数
1.聚合函数
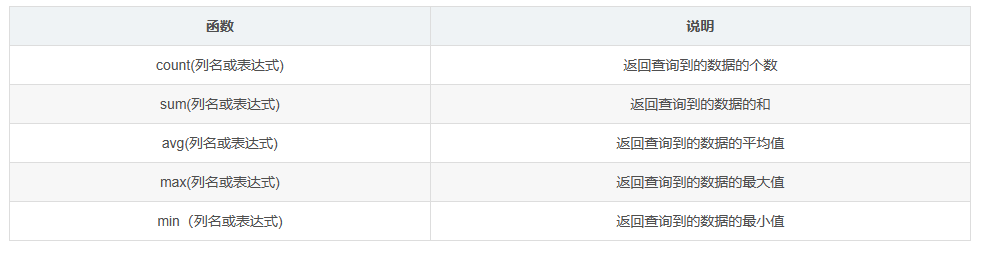
上面的聚合函数在使用时可以在列名或表达式前加上关键字distinct先让查询到的数据去重, 然后再进行计算.
这些聚合函数是针对一个或多个列的行来进行运算的, 其中sum,avg,max,min这几个聚合函数只能针对数值类型进行计算, 不能是字符串和日期类型.
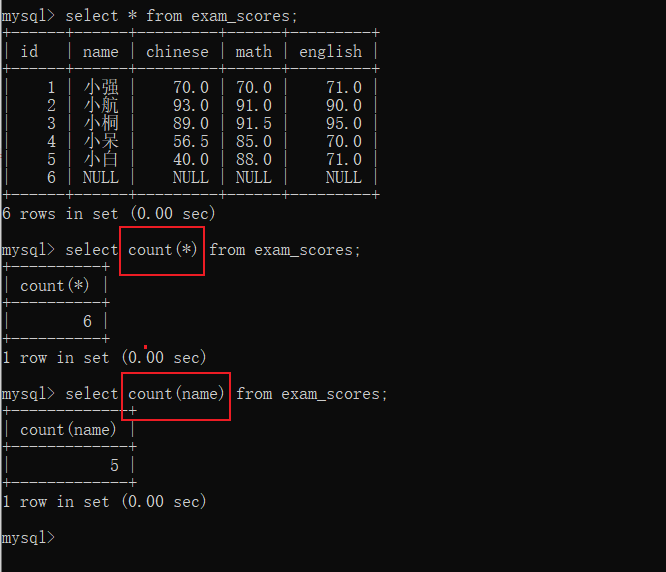
count函数
如果想查询一共有多少行数据 就直接count(*)进行全行查询
如果想去除掉值为null的数据,则通过count(指定列)进行查询,不统计值为null的行
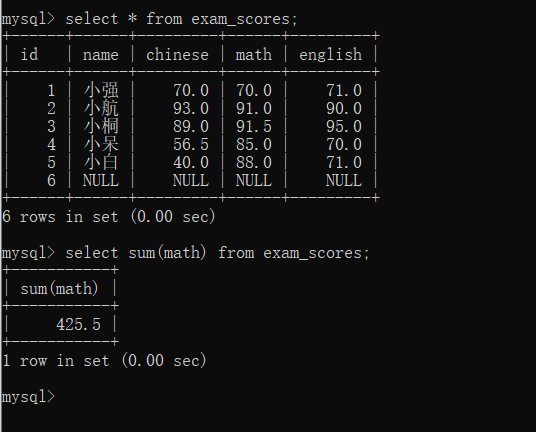
sum函数
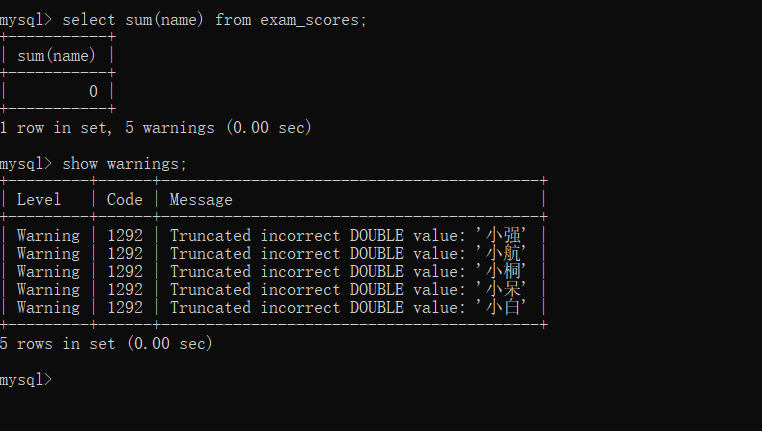
查询数学成绩的总和
null与任何数字的运算值都为null , 所以sum操作会自动跳过结果为null的行
sum只能针对数字,我们对name进行sum操作可以获得结果为0
虽然没报错,但有warnings警告
警告显示:尝试将 name值 转换为 double值 的操作失败
avg函数
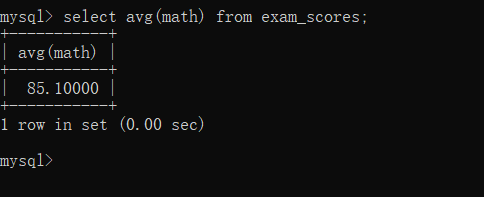
求 math 的平均成绩
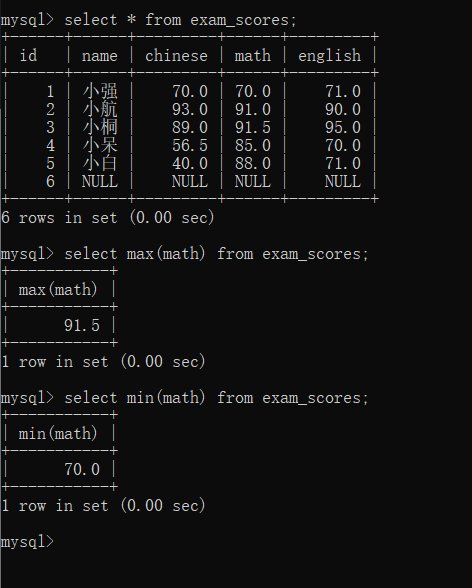
max函数
min函数
2.分组查询
sql中分组操作通过group by关键字实现, 一般和聚合函数结合使用, 通过指定分组条件实现分组查询.
select 列1,sum(列2),max(列3).... from table (条件查询) group by 列1;其中, 上面的条件筛选可以使用where, order by, limit等来实现, 条件筛选不是必写项.
例如要实现对不同岗位的人的薪资进行一个聚合查询 (求各个岗位的平均薪资)
生成一张岗位薪资表
mysql> -- 创建岗位薪资表
mysql> create table emp(
-> id int primary key auto_increment,
-> name varchar(20) not null,
-> role varchar(20) not null,
-> salary int
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> -- 插入数据
mysql> insert into emp values
-> (null, '马大', '老板', 100000),
-> (null, '马二', '老板', 200000),
-> (null, '赵三', '技术员', 20000),
-> (null, '赵叁', '技术员', 50000),
-> (null, '赵桑', '技术员', 40000),
-> (null, '王6', '苦力', 4000),
-> (null, '王7', '苦力', 3400),
-> (null, '王9', '苦力', 5000),
-> (null, '王3', '苦力', 3000);
Query OK, 9 rows affected (0.00 sec)
Records: 9 Duplicates: 0 Warnings: 0
mysql> -- 查看表数据
mysql> select * from emp;
+----+------+--------+--------+
| id | name | role | salary |
+----+------+--------+--------+
| 1 | 马大 | 老板 | 100000 |
| 2 | 马二 | 老板 | 200000 |
| 3 | 赵三 | 技术员 | 20000 |
| 4 | 赵叁 | 技术员 | 50000 |
| 5 | 赵桑 | 技术员 | 40000 |
| 6 | 王6 | 苦力 | 4000 |
| 7 | 王7 | 苦力 | 3400 |
| 8 | 王9 | 苦力 | 5000 |
| 9 | 王3 | 苦力 | 3000 |
+----+------+--------+--------+
9 rows in set (0.00 sec)
mysql>分组查询不同岗位的薪资:
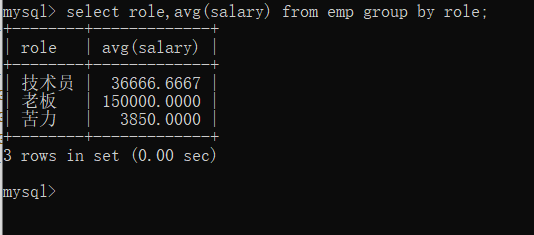
group by role 表示按照role这个列的值进行分组查询
3.having
在上面分组查询的基础上, 分组查询也可以添加指定条件, 这里的条件分有下面两种情况:
- 分组之前指定条件, 也就是先筛选再分组, 使用
where关键字. - 分组之后指定条件, 也就是先分组再筛选, 使用
having关键字.
-- having语法
select 聚合函数(或者列), ... from 表名 group by 列 having 条件;
-- where语法
select 聚合函数(或者列), ... from 表名 where 条件 group by 列;



三. 联合查询(多表查询)
首先先建立多张表
一共有四张表, classes为班级表, student为学生表, course表为课程表, score为成绩表, 其中学生与班级的关系是一对多,学生与课程之间的关系是多对多.
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (
id int primary key auto_increment,
name varchar(20),
`desc` varchar(100)
);
create table student (
id int primary key auto_increment,
sn varchar(20), name varchar(20),
qq_mail varchar(20),
classes_id int
);
create table course (
id int primary key auto_increment,
name varchar(20)
);
create table score (
score decimal(3, 1),
student_id int,
course_id int
);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),
('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
mysql> select * from classes;
+----+-------------------------+-------------------------------------------------------------------+
| id | name | desc |
+----+-------------------------+-------------------------------------------------------------------+
| 1 | 计算机系2019级1班 | 学习了计算机原理、C和Java语言、数据结构和算法 |
| 2 | 中文系2019级3班 | 学习了中国传统文学 |
| 3 | 自动化2019级5班 | 学习了机械自动化 |
+----+-------------------------+-------------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql> select * from student;
+----+-------+-----------------+------------------+------------+
| id | sn | name | qq_mail | classes_id |
+----+-------+-----------------+------------------+------------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 |
| 7 | 83223 | tellme | NULL | 2 |
| 8 | 09527 | 老外学中文 | foreigner@qq.com | 2 |
+----+-------+-----------------+------------------+------------+
8 rows in set (0.00 sec)
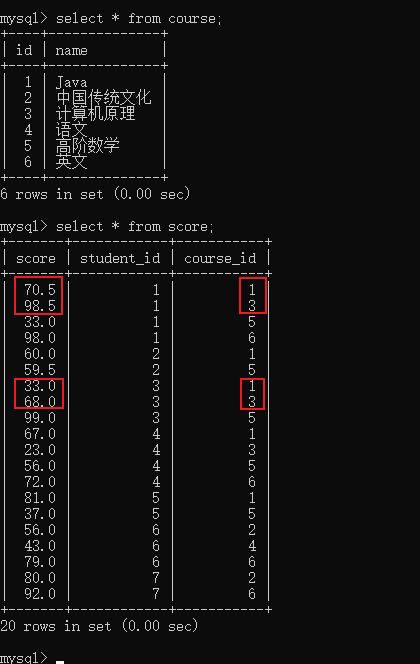
mysql> select * from course;
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------------+
6 rows in set (0.00 sec)
mysql> select * from score;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 70.5 | 1 | 1 |
| 98.5 | 1 | 3 |
| 33.0 | 1 | 5 |
| 98.0 | 1 | 6 |
| 60.0 | 2 | 1 |
| 59.5 | 2 | 5 |
| 33.0 | 3 | 1 |
| 68.0 | 3 | 3 |
| 99.0 | 3 | 5 |
| 67.0 | 4 | 1 |
| 23.0 | 4 | 3 |
| 56.0 | 4 | 5 |
| 72.0 | 4 | 6 |
| 81.0 | 5 | 1 |
| 37.0 | 5 | 5 |
| 56.0 | 6 | 2 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 80.0 | 7 | 2 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
20 rows in set (0.00 sec)
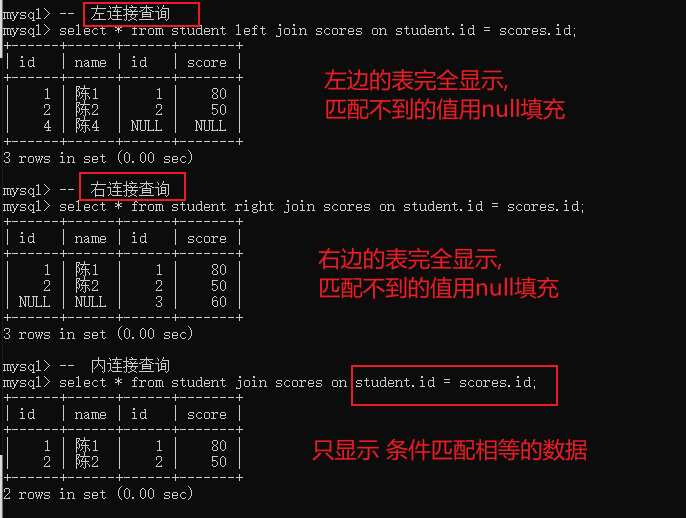
常用的连接方式有: 内连接和外连接(外连接分为左外连接和右外连接),
如果多表之间的记录数据均有对应, 内外连接的查询结果是没有区别的;
如果多表之间的记录数据有存在不对应的情况, 那么内外连接就有一定的区别了, 内链接只会查询显示多表对应的记录, 左外连接会把左表的记录都显示出来, 右表中不对应的地方用null填充, 而右外连接就会把右表的记录都显示出来, 左表中不对应的地方用null填充.
内连接
语法:
select 字段 from 表1, 表2, ... where 条件;
select 字段 from 表1 inner join 表2 on 条件 join 表3 on 条件...;
举例: 查询许仙同学的成绩
select student.name,course.name,score from score,course,student
where student.id = student_id and course.id = course_id
and student.name = '许仙';逐步解析一下最终的SQL语句:
1.此处涉及到了三个表,分别是 学生表,课程表,分数表,学生名字在student表,课程名字在course表
因此要对这三张表进行笛卡尔积
select * from score,course,student;2.加入where条件语句筛选出有效的数据
select * from score,course,student
where student.id = student_id and course.id = course_id;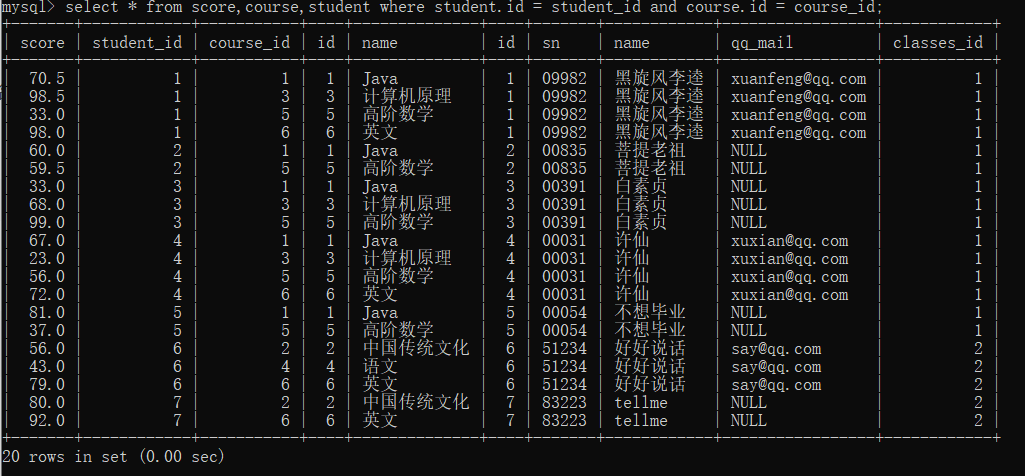
3.根据需求加入限制条件,我们要查询的是许仙的成绩,因此加入条件 student.name = '许仙'
select * from score,course,student
where student.id = student_id and course.id = course_id
and student.name = '许仙';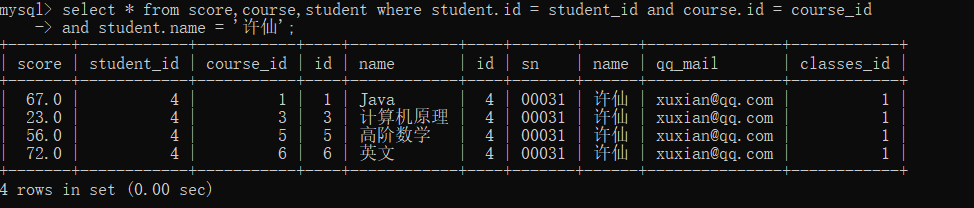
4.最后再把不必要的列删去,如我们查询成绩,只需要保留姓名,科目名,成绩即可
select student.name,course.name,score from score,course,student
where student.id = student_id and course.id = course_id
and student.name = '许仙';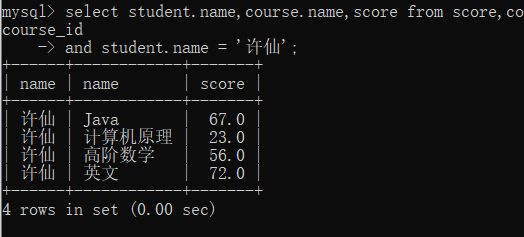
也可以使用 join on 关键字查询:
select student.name,course.name,score from score join course join student
on student.id = student_id and course.id = course_id and student.name ='许仙';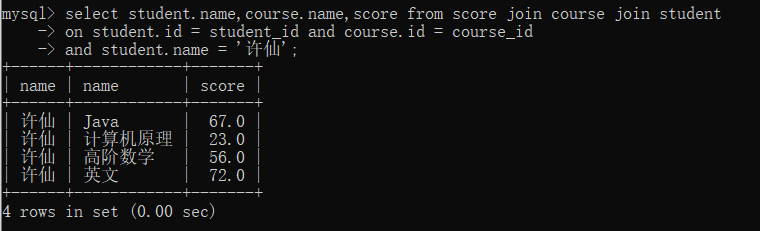
外连接
外连接通过关键字 join on 来实现
外连接分为左连接与右连接
-- 左外连接,表 1 完全显示select 字段名 from 表名 1 left join 表名 2 on 连接条件 ;-- 右外连接,表 2 完全显示select 字段 from 表名 1 right join 表名 2 on 连接条件 ;
创建两张表,学生表与分数表
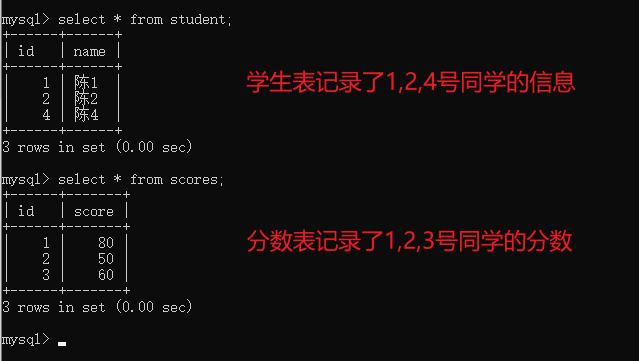
查询每位同学的成绩,因此条件就是 学生id = 分数id
自连接
通过自连接,可以将不同行的数据 转换为 不同列上的数据,便于比较
语法:
select 字段 from 表A as s1, 表A as s2,... where 条件;
两张表都要各取一个别名
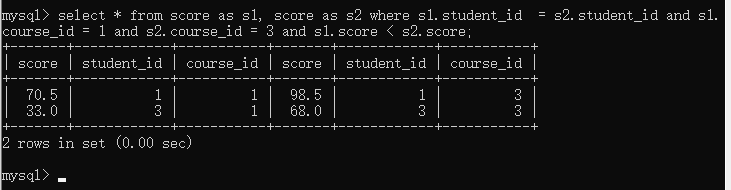
例如,要查询计算机原理成绩好于java成绩的同学
在分数表中,各科成绩位于不同行,不方便筛选
通过自连接就可以直观的筛选出id为1和3的同学,计算机原理成绩高于Java
子查询
指在一个select查询语句中再插入一个select查询语句,将多步的查询 转化为 一步查询
- 单行子查询
例子: 查询 '不想毕业' 这位同学的同班同学
常规查询需要两步:1,先找出 不想毕业 同学的班级id 2,找出班级id相同的学生
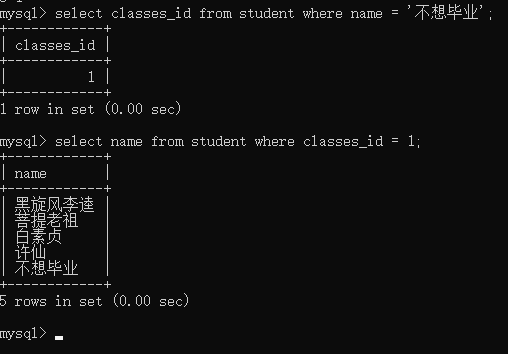
如上图,嵌套的classes_id查询结果只有一行数据,因此被称为单行子查询
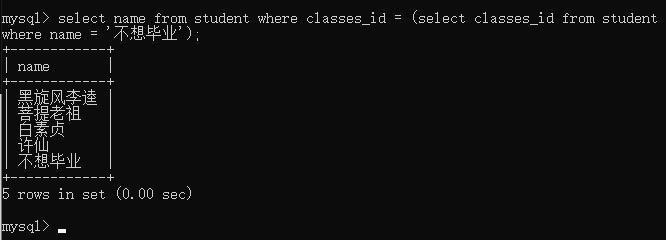
- 多行子查询
多行子查询需要通过关键字 in 连接
例子: 查询 语文 或 英语课程的成绩
常规查询需要两步,第一步查询课程id,返回两行数据
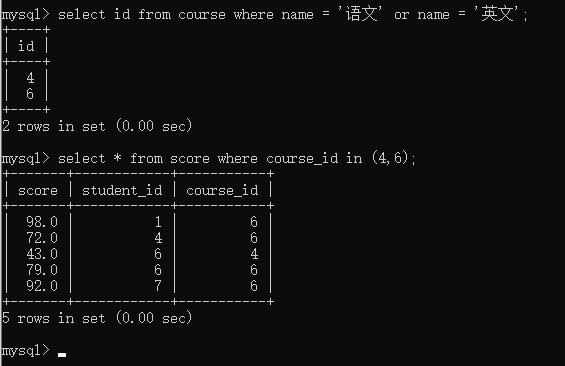
通过多行子查询
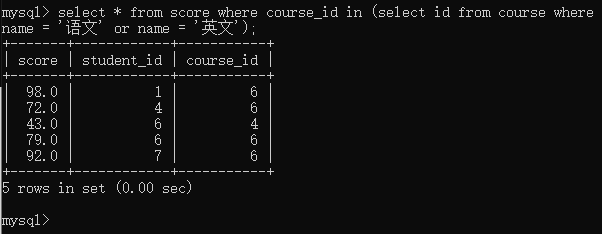
合并查询
通过 union 可以合并多个select的查询结果
-- 去重合并查询
select 字段 from 表1 where 条件 union select 字段 from 表2 where 条件;
-- 不去重合并查询
select 字段 from 表1 where 条件 union all select 字段 from 表2 where 条件;
对于不同表的合并查询
比如要查询课程id<4或者分数大于90的课程id
此处就涉及到两张表,课程表和分数表
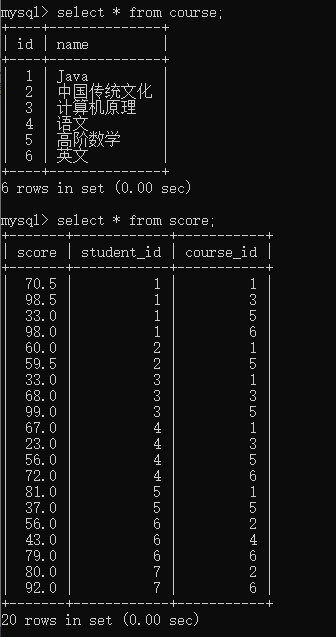
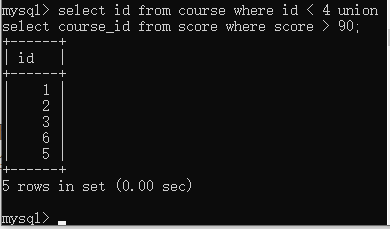
这里要注意一下or和union的区别, or只能针对同一张表下得到并集, 而union能够得到不同表的并集; 也就是说合并查询不仅能够查询单表中两个结果的并集, 也能查询多表中两个结果的并集, 而or只能实现单表查询并集.

















 6827
6827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









