



内容:
编写程序,实现以下功能:
①按中序顺序建立一颗二叉树;
②用先序非递归方式遍历二叉树,输出遍历序列。
步骤:
1.算法分析
①由于中序无法确定唯一的二叉树,即中序无法创建二叉树,故它需要结合先序或者后序,而这联系起来才能建立二叉数。先序遍历序列中首元素是二叉树的根节点,在中序遍历序列中找到这个节点,则此节点为中序序列的分水岭,前边为其左节点,右边为其右节点,最后传入先序左子树和中序左子树作为左子树,传入先序右子树和中序右子树作为右子树。
②先序遍历二叉树的时候,首先建立一个栈,先访问根节点,再访问左孩子,最后访问右孩子。在先序非递归遍历二叉树算法中,先将根节点压栈,在栈不为空时执行循环,让栈顶元素出栈,访问栈顶元素,如果栈顶元素的右孩子不为空,则让右孩子先进栈,如果栈顶元素的左孩子不为空,再让左孩子进栈。
2.概要设计
使用C语言,其中设置了以下函数:
- 函数 CreateTree()用先序中序顺序建立一个二叉树;
- 函数PreOrder()用来实现先序非递归遍历二叉树;
程序运行流程图如下:
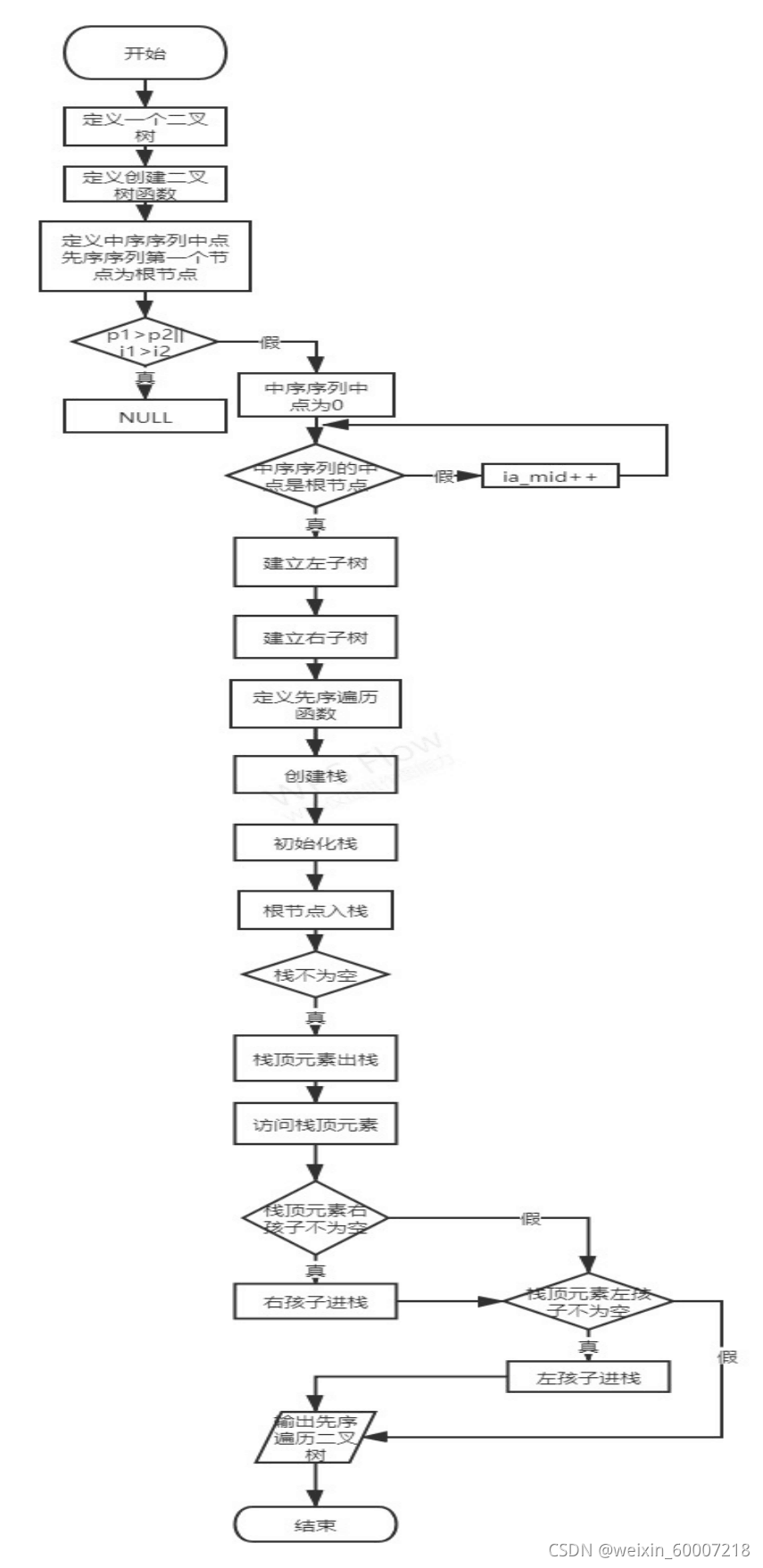
流程图
3.测试(设计测试用例或测试代码的设计与实现,测试结果截屏))
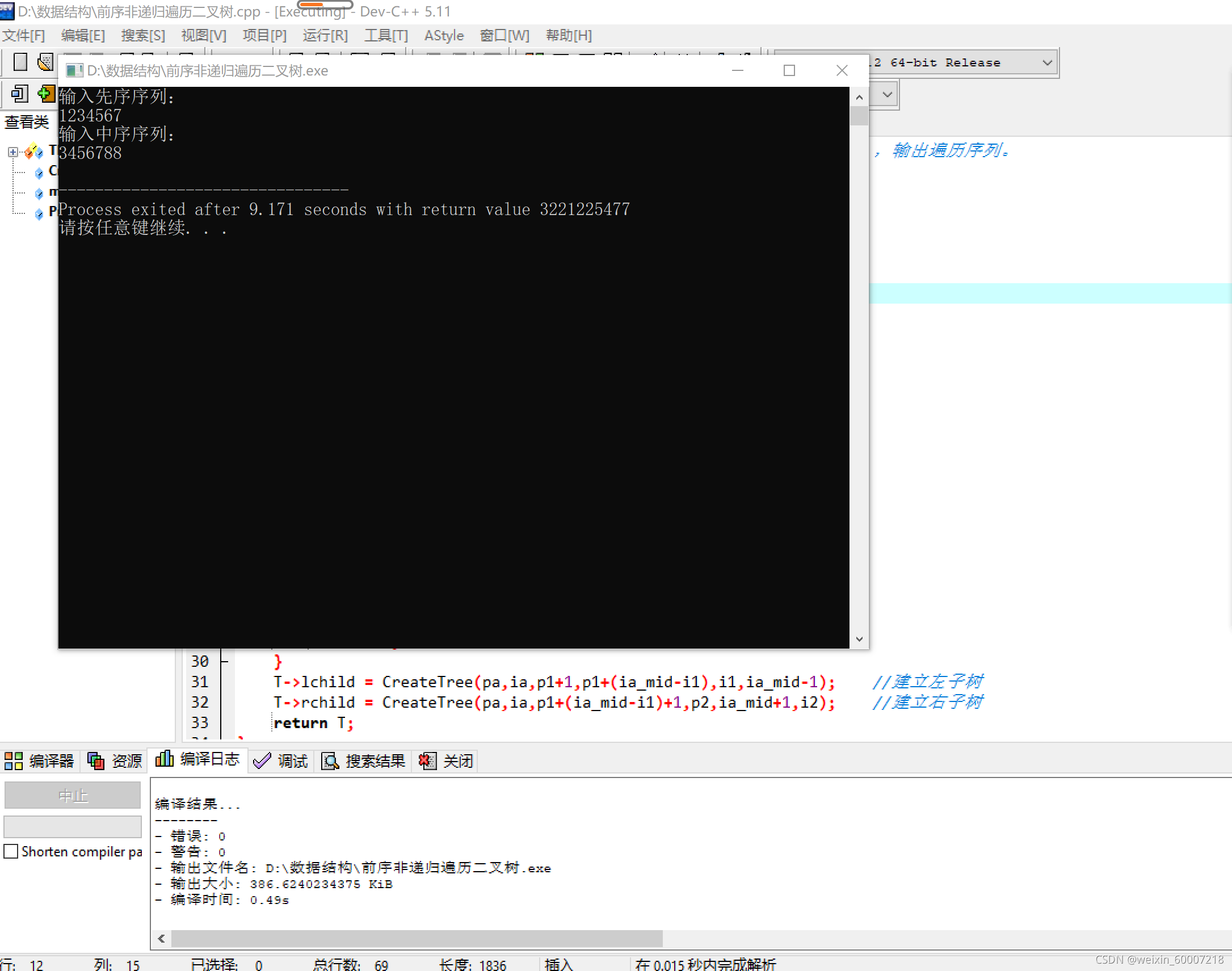
设计测试用例如下图:
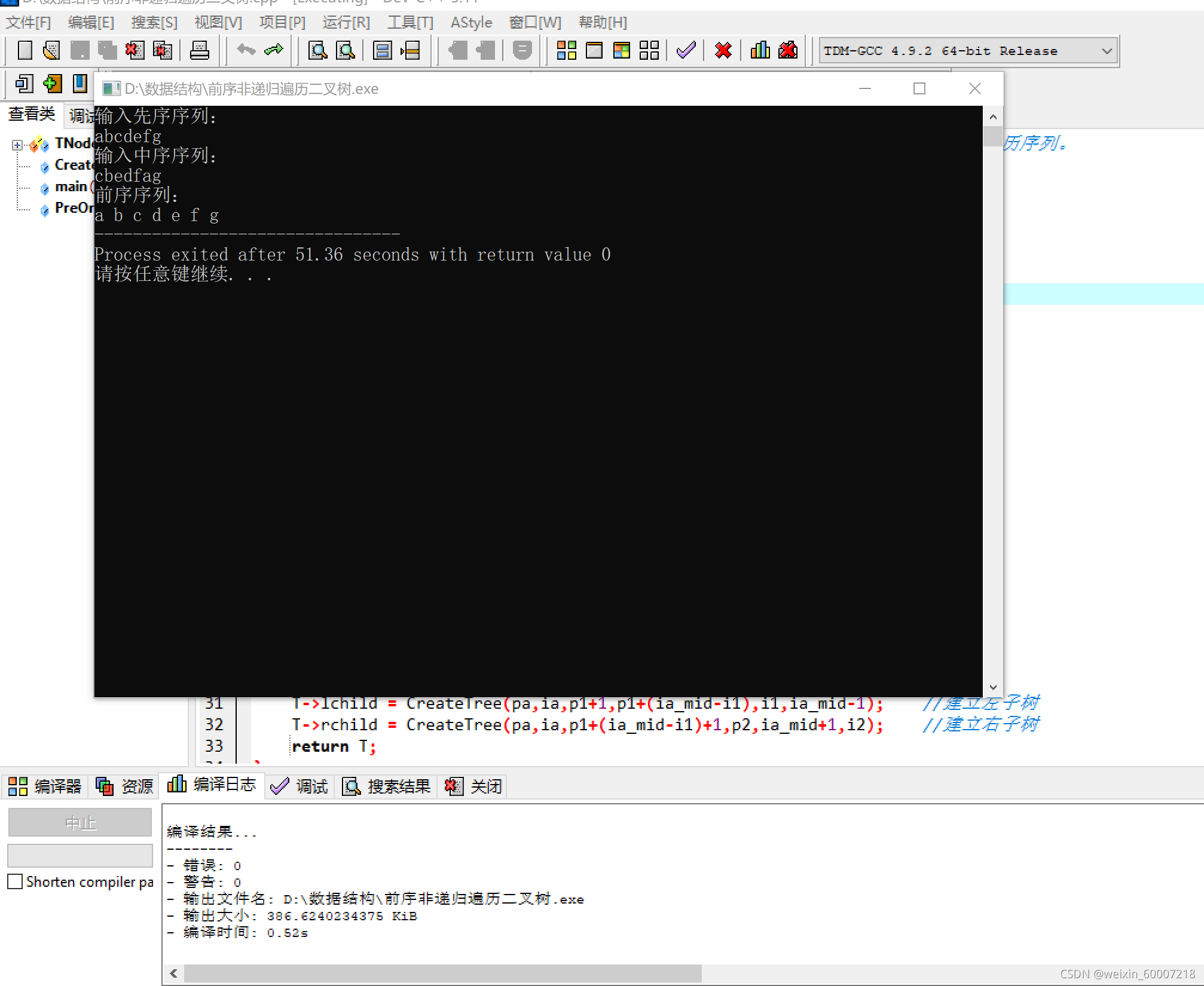
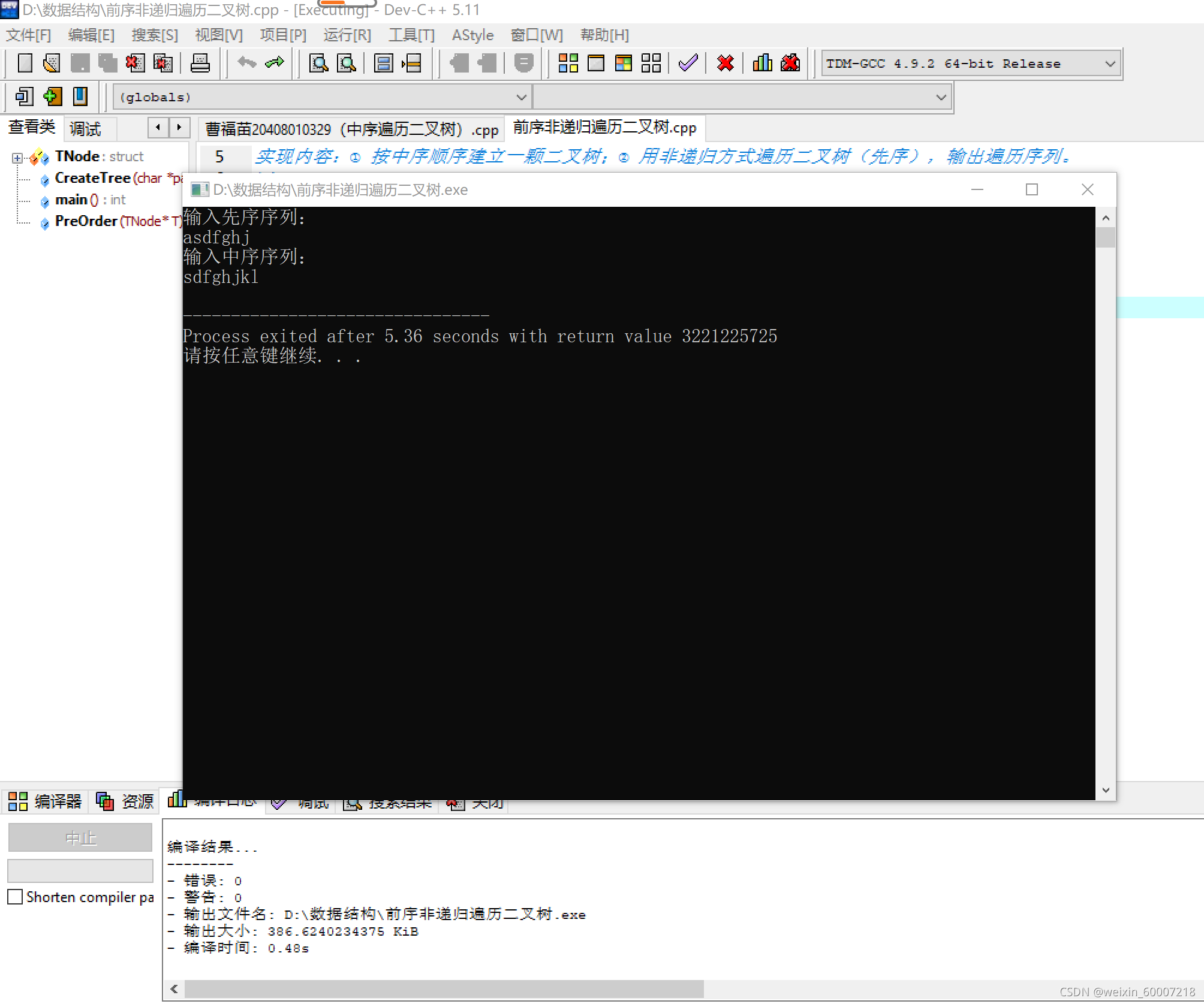
测试结果不存在问题。
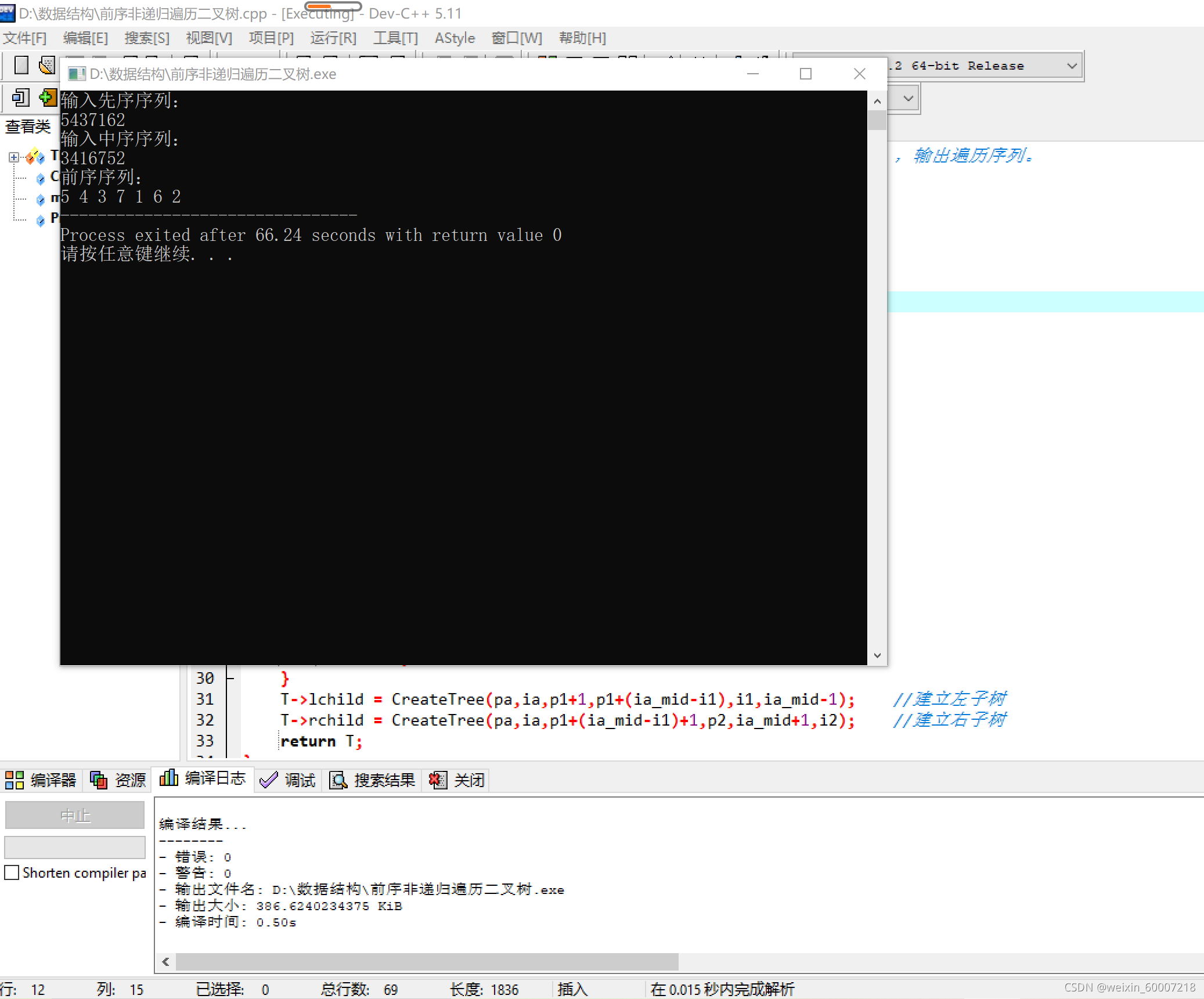
4.调试(对测试出的问题进行调试,界面截屏,调试修正编码)
编译过程出现的错误:
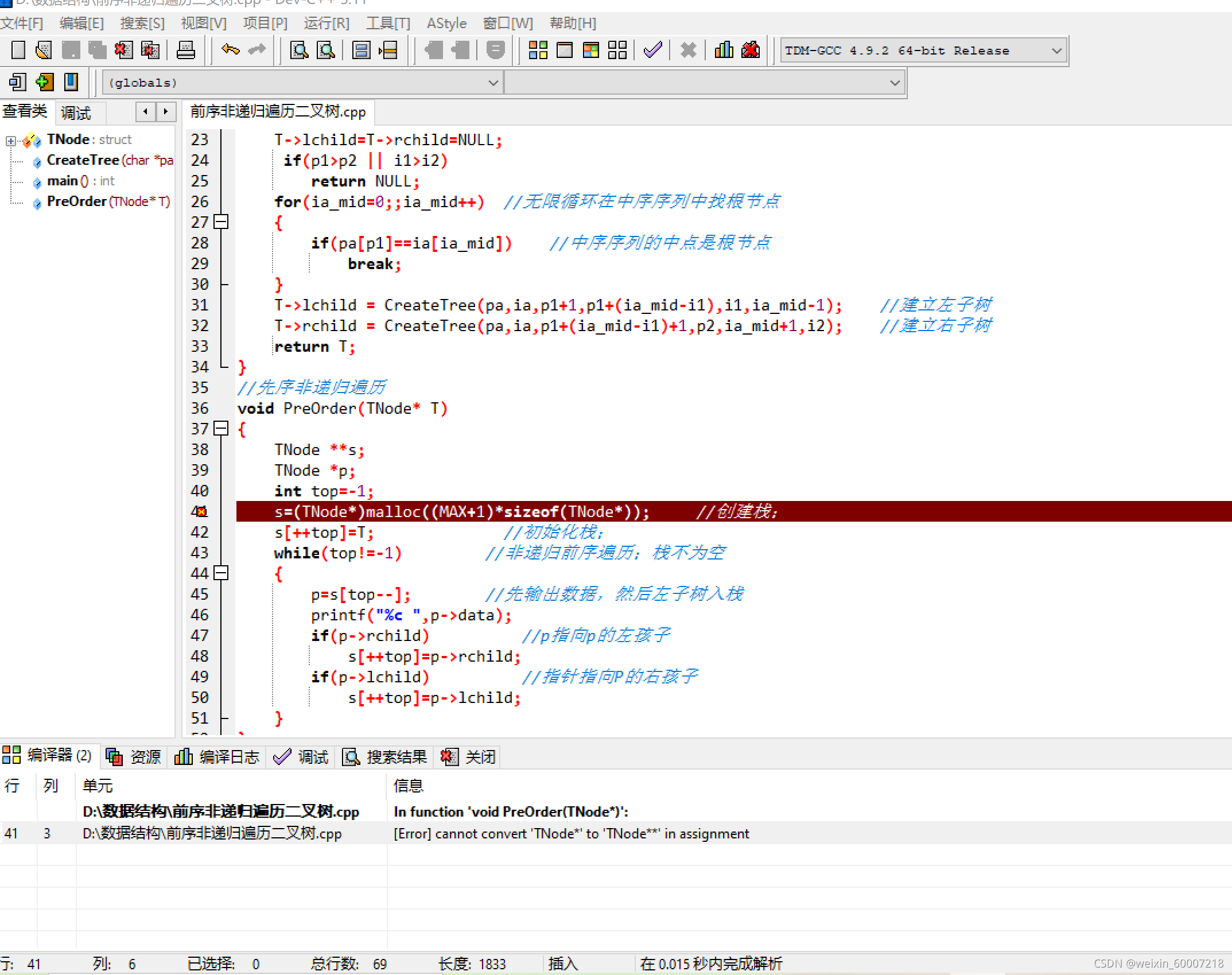
用malloc函数开辟空间,在前面加的是指针类型,由于malloc返回的是地址,是一个整数,将整数强制转换为一个链表节点,(TNode*)*将其返回的地址值变为void*类型的,因此出现错误。
5.源码
//先序中序创建二叉树
TNode* CreateTree(char *pa, char *ia, int p1, int p2, int i1, int i2)
{
int ia_mid; //中序序列中点
TNode *T;
T=new TNode; //树根
T->data=pa[p1]; //先序序列的第一个结点为根节点
T->lchild=T->rchild=NULL;
if(p1>p2 || i1>i2)
return NULL;
for(ia_mid=0;;ia_mid++) //无限循环在中序序列中找根节点
{
if(pa[p1]==ia[ia_mid]) //中序序列的中点是根节点
break;
}
T->lchild = CreateTree(pa,ia,p1+1,p1+(ia_mid-i1),i1,ia_mid-1); //建立左子树
T->rchild = CreateTree(pa,ia,p1+(ia_mid-i1)+1,p2,ia_mid+1,i2); //建立右子树
return T;
}
//先序非递归遍历
void PreOrder(TNode* T)
{
TNode **s;
TNode *p;
int top=-1;
s=(TNode**)malloc((MAX+1)*sizeof(TNode*)); //创建栈;
s[++top]=T; //初始化栈;
while(top!=-1) //非递归前序遍历;栈不为空
{
p=s[top--]; //先输出数据,然后左子树入栈
printf("%c ",p->data);
if(p->rchild) //p指向p的左孩子
s[++top]=p->rchild;
if(p->lchild) //指针指向P的右孩子
s[++top]=p->lchild;
}
}
int main()
{
char pre[200], in[200];
int n; //保存序列长度
TNode *T; //用来保存二叉树的根
printf("输入先序序列:\n");
scanf("%s", pre);
printf("输入中序序列:\n");
scanf("%s", in);
n=0;
while(pre[n]) n++; //计算序列长度
T= CreateTree(pre, in, 0, n-1, 0, n-1);
printf("前序序列:\n");
PreOrder(T); //打印前序序列
return 0;
}

















 5211
5211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









