



本文仅用于逆向研究交流,禁止非法用途,如遇侵权联系删除!!!
准备
某购物APP 15.2.80版本
通过豌豆荚下载
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9hcHBzLzI3OTk4Ny9oaXN0b3J5X3YxMDE3NjE=
设备mi6
抓包工具reqable
APP抓包
这个app直接抓是抓不到的因为有ssl pinning
这里推荐的方案是
Lsposed+JustTrustMe 过掉ssl pinning
接口分析
接口位置为首页下拉
关键词搜下面
首先看参数
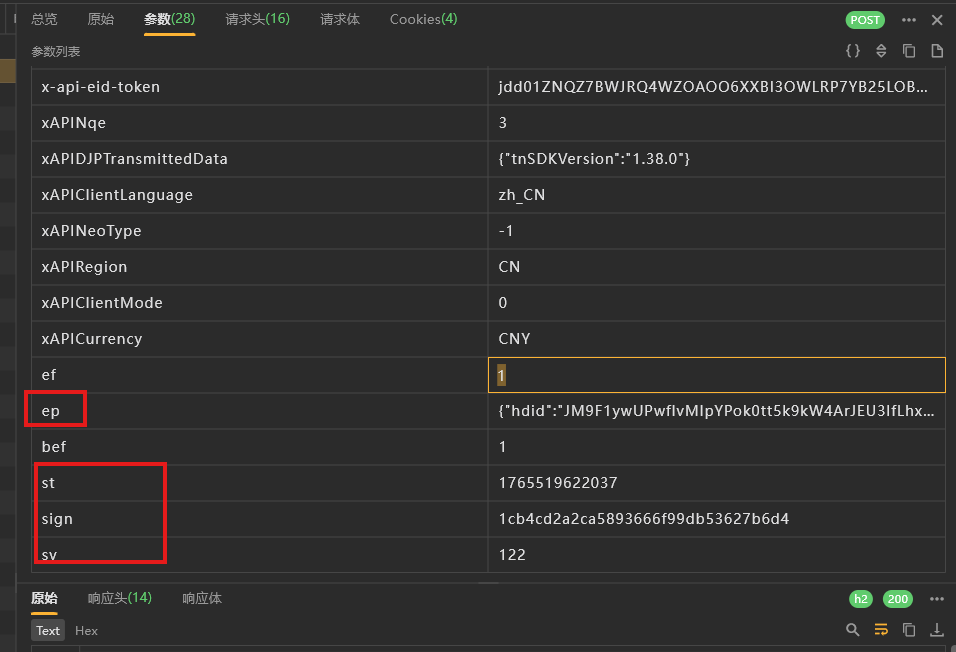
再看请求体
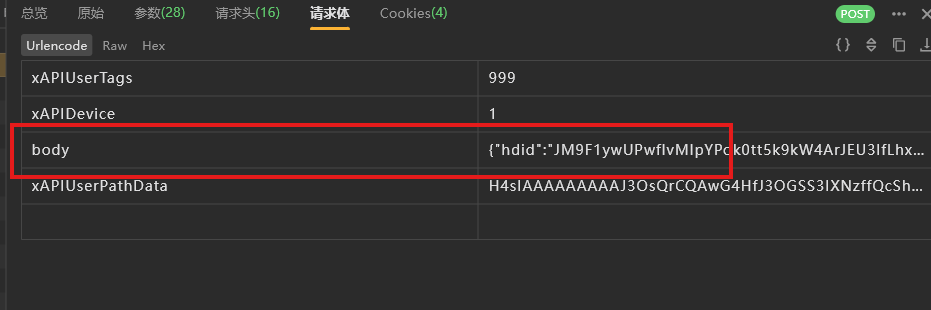
有很多都是加密
我们本篇就先分析这几个
body和ep中都很像base64加密但是我测试了一下都不是 估计是魔改的算法
sign像是md5
st时间戳
sv暂时不知道
魔改base64分析
把下载的安装包拖进去进行jadx反编译分析
反编译之后搜索ep里面关键字cipher
可以看到这里把参数put进去的我们看看JSONObject是怎么来的
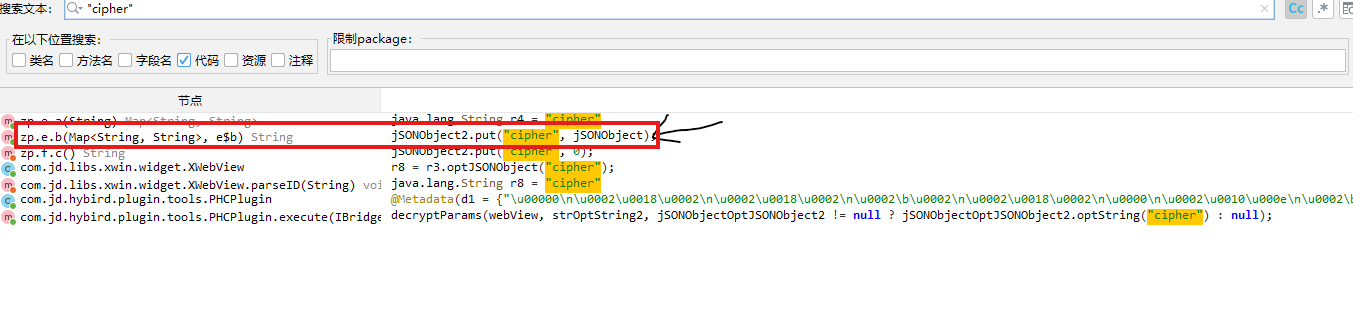
定位到了生存位置我们分析下JSONObject生成流程
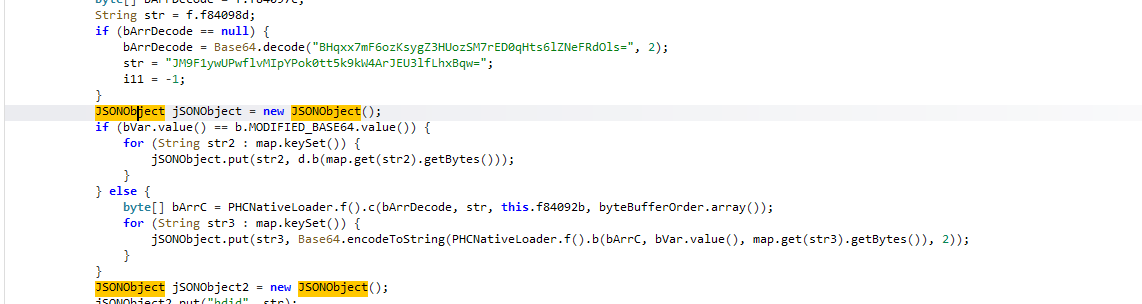
JSONObject jSONObject = new JSONObject();
if (bVar.value() == b.MODIFIED_BASE64.value()) {
for (String str2 : map.keySet()) {
jSONObject.put(str2, d.b(map.get(str2).getBytes()));
}
} else {
byte[] bArrC = PHCNativeLoader.f().c(bArrDecode, str, this.f84092b, byteBufferOrder.array());
for (String str3 : map.keySet()) {
jSONObject.put(str3, Base64.encodeToString(PHCNativeLoader.f().b(bArrC, bVar.value(), map.get(str3).getBytes()), 2));
}
}
创建一个空的 JSON 对象,作为最终存储键值对的容器;
JSONObject jSONObject = new JSONObject();
判断分支过枚举b的value()方法(推测返回 int / 字符串),判断是否为MODIFIED_BASE64类型,因为我们看到抓包都是魔改算法所谓这步是true
if (bVar.value() == b.MODIFIED_BASE64.value()) { ... } else { ... }
1遍历入参map的所有 key(str2);
2对每个 key,获取对应的 value 字符串 → 转成字节数组(map.get(str2).getBytes());
3调用工具类d的静态方法b(),对字节数组执行「自定义的 MODIFIED_BASE64 编码」
4将编码后的结果(推测是字符串)作为 value,和原 key str2一起放入 JSONObject。
for (String str2 : map.keySet()) {
jSONObject.put(str2, d.b(map.get(str2).getBytes()));
}
经过分析下一步应该去看d.b方法
可以看到很明显的base64编码特征,找一下自定义的编码表
ps:魔改的base64一般都只会改编码表,其他的不好怎么动,所有要先关注编码表
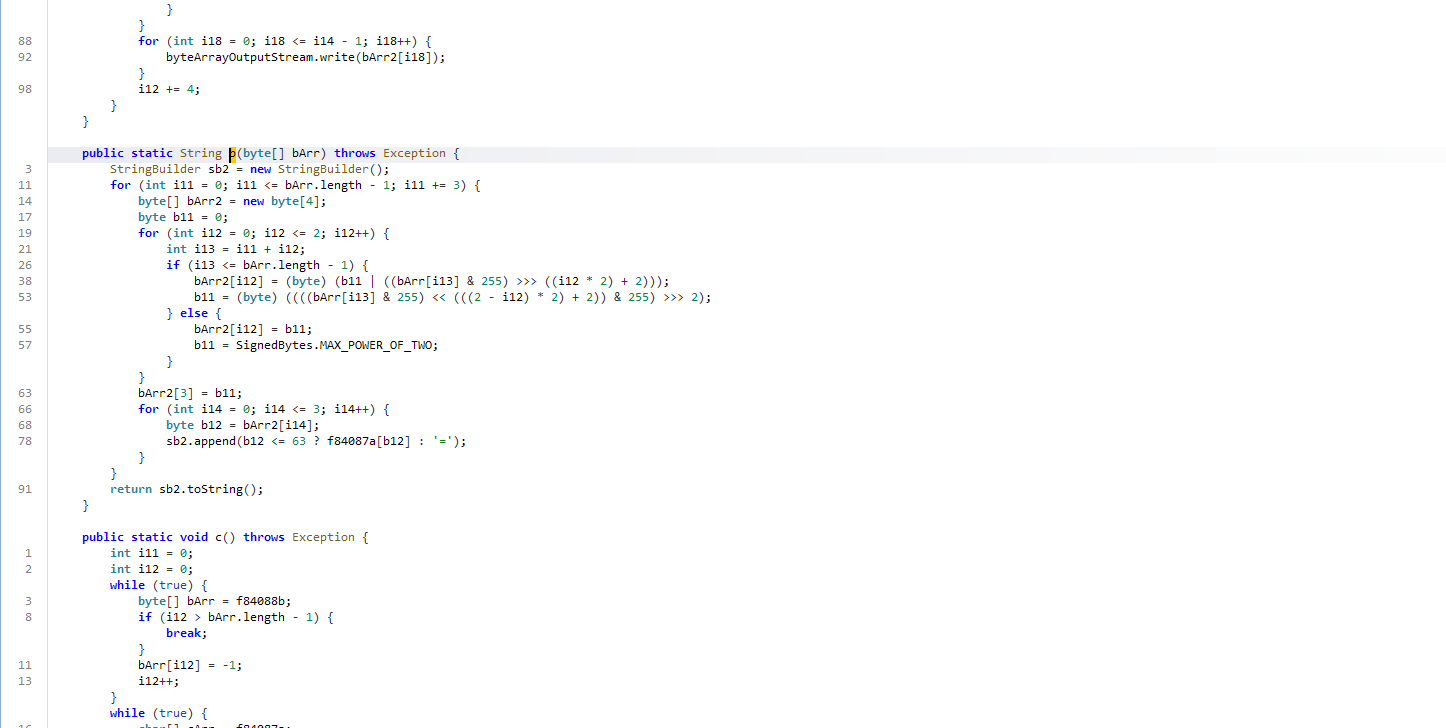
表在这个类的最上面

其中有一个字母明文还需要再进去看下是'u'
由此我们就可以获得完整的编码表

可以把这个直接扔给ai生成一个这个编码表的base64算法
告诉ai把 编码表扔给他让他生成对应的 base64算法
我们去找抓到的明文解析下试一试
ep原文
{
"hdid": "JM9F1ywUPwflvMIpYPok0tt5k9kW4ArJEU3lfLhxBqw=",
"ts": 1765517250744,
"ridx": -1,
"cipher": {
"area": "CV83Cv81DJY3DP8m",
"d_model": "JUu2",
"wifiBssid": "dW5hbw93bq==",
"osVersion": "EG==",
"d_brand": "WQvrb21f",
"screen": "CJuyCMenCNqm",
"uuid": "YtO4DwTrZNDtDtS4DJS0Cm==",
"aid": "YtO4DwTrZNDtDtS4DJS0Cm==",
"openudid": "YtO4DwTrZNDtDtS4DJS0Cm=="
},
"ciphertype": 5,
"version": "1.2.1",
"appname": "com.jingdong.app.mall"
}
ep解析后 可以看到是一些设备和位置信息 body里面同样这里面不展示
{
"hdid": "JM9F1ywUPwflvMIpYPok0tt5k9kW4ArJEU3lfLhxBqw=",
"ts": 1765517250744,
"ridx": -1,
"cipher": {
"area": '1_72_55674_0',
"d_model": 'MI6',
"wifiBssid": "unknown",
"osVersion": "9",
"d_brand": "Xiaomi",
"screen": "1920*1080",
"uuid": "b186bad3c6285243",
"aid": "b186bad3c6285243",
"openudid": "b186bad3c6285243"
},
"ciphertype": 5,
"version": "1.2.1",
"appname": "com.jingdong.app.mall"
}
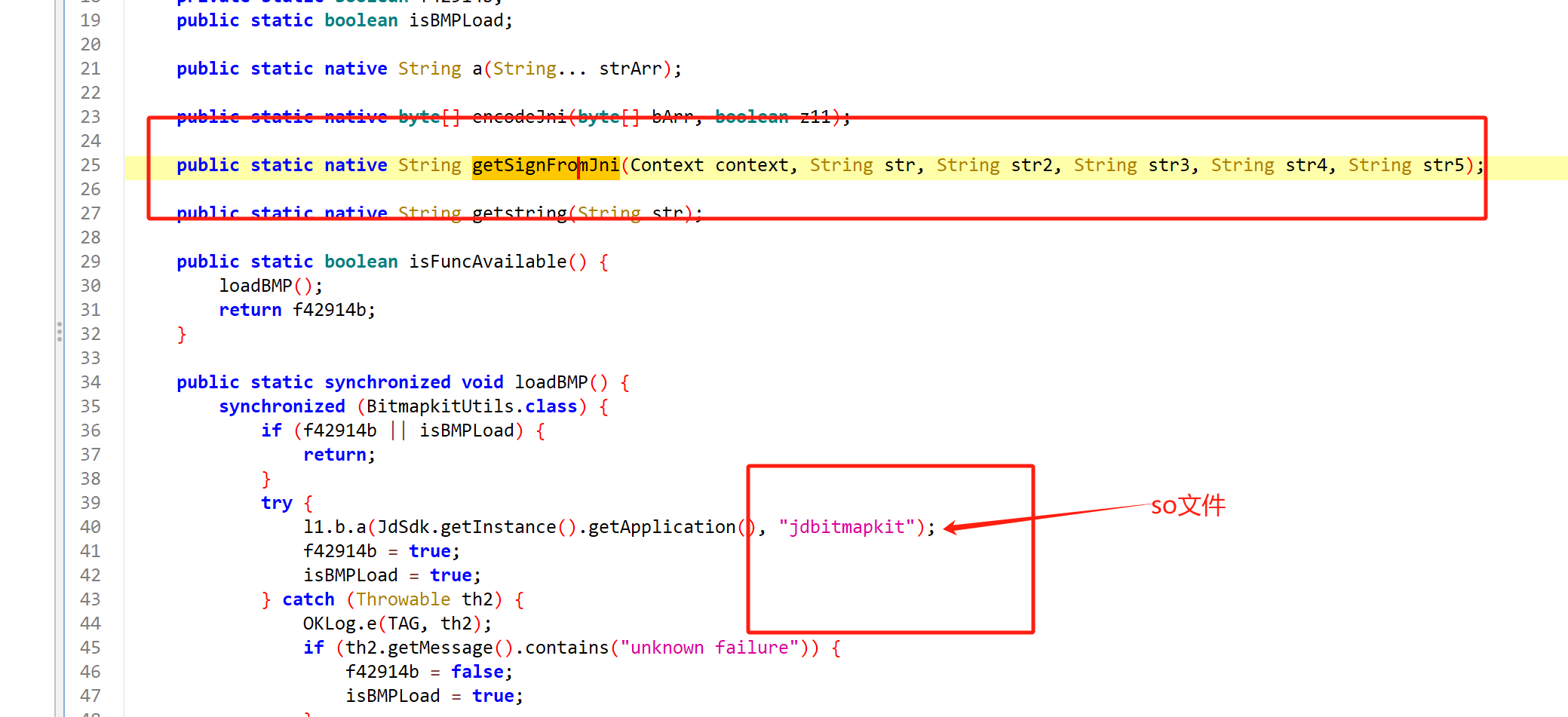
sign sv st
java层位置
这三个是一起的
每次sv个st都是变化的 看着像MD5


这个搜sign是搜不到的
真实位置是在这里
再hook下值看看传入了什么
frida hook
注!!! 用 -f 模式:Spawn 模式有检测 不会过的就用-f
如果hook没反应你可以ctrl +s 或者回车一个空行再ctrl +s
hook脚本 筛选一个只看商品下拉连接
Java.perform(() => {
console.log("[*] start hook BitmapkitUtils.getSignFromJni");
let BitmapkitUtils = Java.use("com.jingdong.common.utils.BitmapkitUtils");
BitmapkitUtils["getSignFromJni"].implementation = function (context, str, str2, str3, str4, str5) {
let result = this["getSignFromJni"](context, str, str2, str3, str4, str5);
if (str.toString().includes('uniformRecommend')) {
console.log(`BitmapkitUtils.getSignFromJni is called: context=${context}, str=${str}, str2=${str2}, str3=${str3}, str4=${str4}, str5=${str5}`);
console.log(`BitmapkitUtils.getSignFromJni result=${result}`);
}
return result;
};
});

str=uniformRecommend9, 函数名字
str2="areaCode":0,。。。。。。。:00","verOld":"2"},json来自请求
str3=b186bad3c6285243, uuid 注意!!!这个要和上面ep解析后的uuid值相同
str4=android,安卓
str5=15.2.80 app版本
之后我们需要获得so文件进行分析
需要把安装包解压之后改zip格式
之后就可以找到这个文件了
注意直接用windows搜有可能会搜不到这个文件名
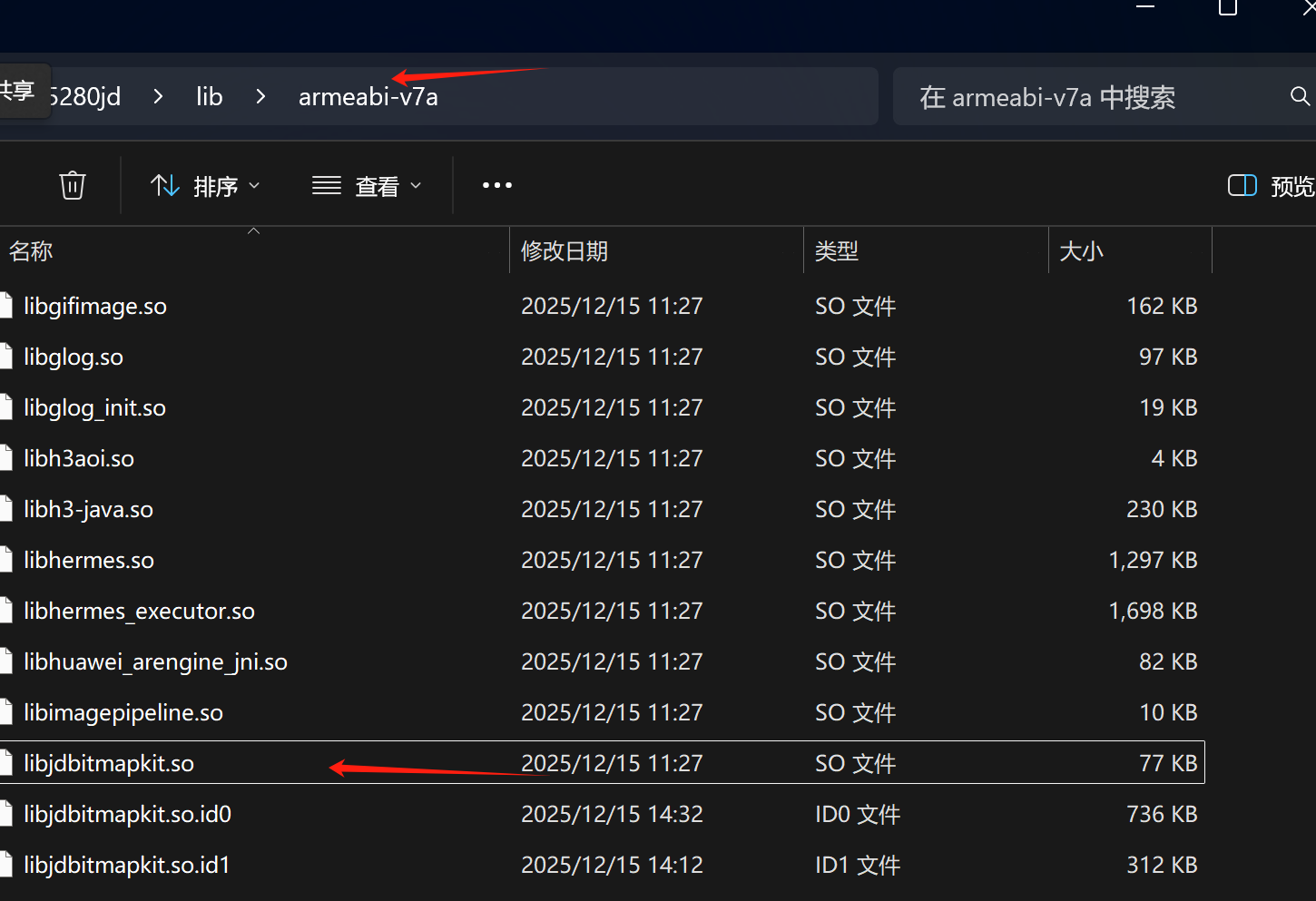
将这个文件拖入到ida进行分析
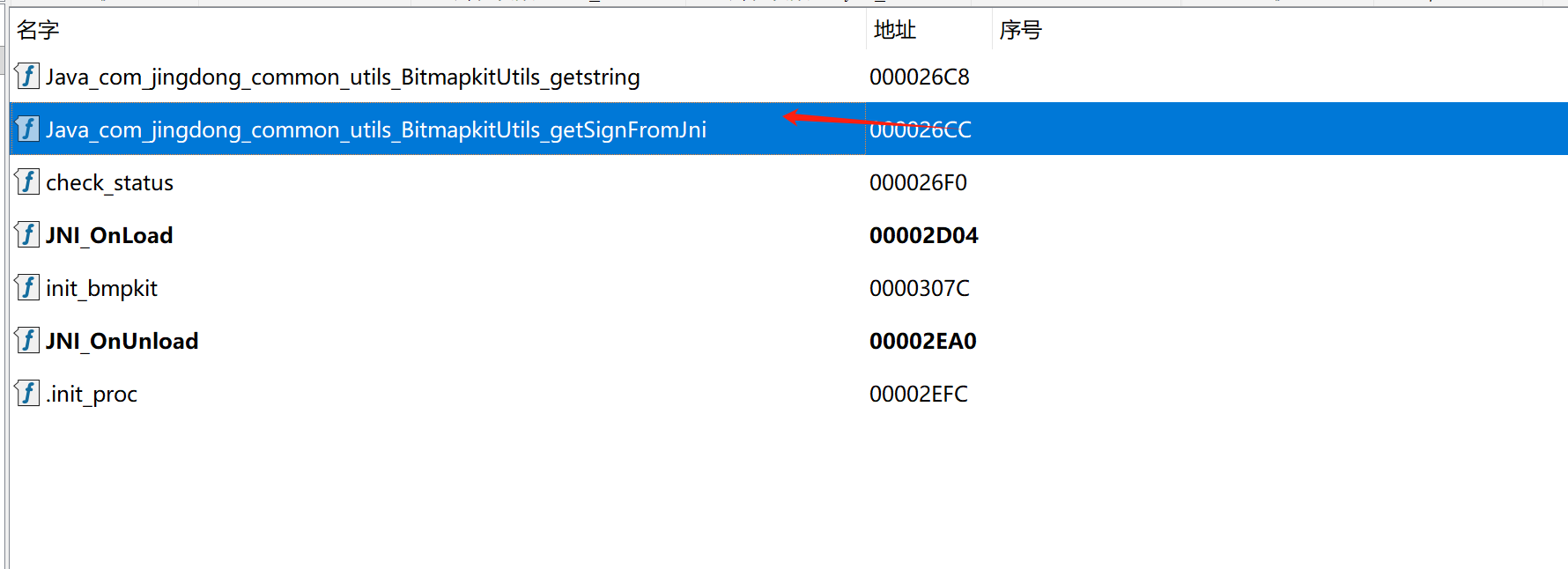
so层分析
反编译之后
看导出函数中 是静态的,不需要我们再去找了,点进去f5
可以看到下面 需要再进sub_5514看下
主函数
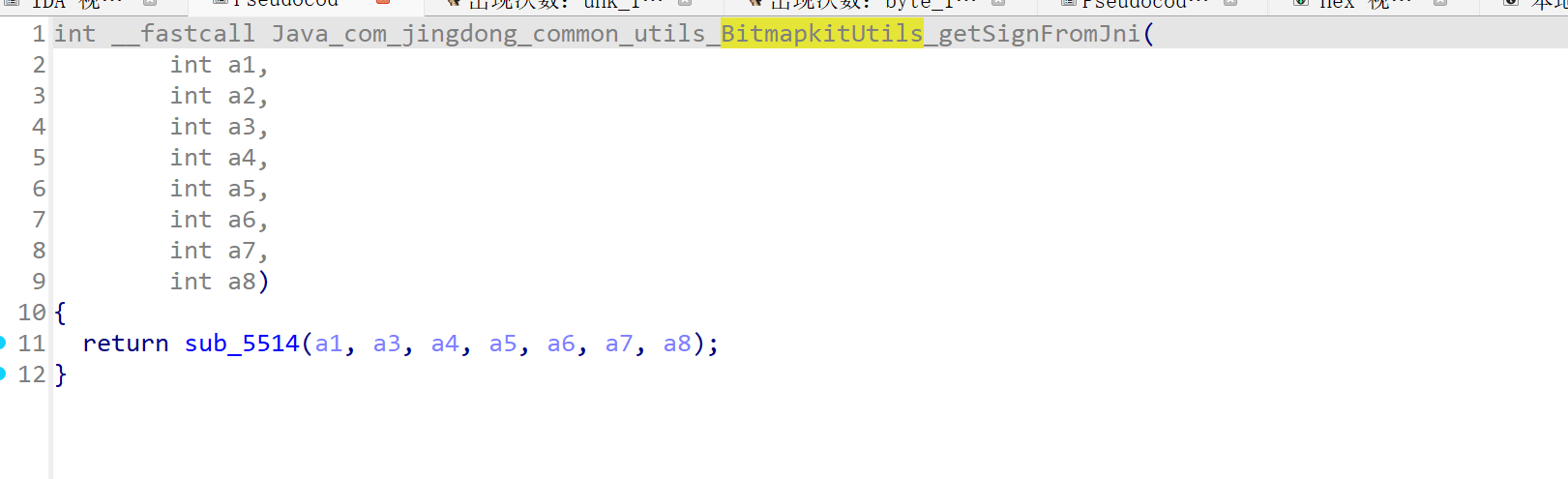
下面的sub函数可能在不同版本命名不同
sub_5514
这个是主要功能实现函数
拼接字符串

st和sv生成

这里面比较重要的是sv生成 sv对应下面走什么分支!!!
sv的百位永远是1 个位和十位 是 0,1,2的组合
个位和十位是影响分支的关键因素这个我们下面说
sub_52C4
v38 = sub_52C4(a1, v36, v37, 1, v30, v65);
这个函数是加密控制的入口
sub_52C4入参意思是
| 参数 1 | a1 | 指针 | 不是普通指针,是 JNIEnv*(JNI 环境指针) |
| 参数 2 | v36 | 明文字节 | 是 字符串进行拼接之后的字节 |
| 参数 3 | v37 | 明文长度 | 完全正确(int 类型,对应 v36 字节数组的长度) |
| 参数 4 | 1 | 固定为 1 | 是加密模式标识(1 = 加密,0 = 解密) |
| 参数 5 | v30 | SV 的个位 |
| 参数 6 | v65 | SV 的十位 |
知道sub_52C4参数意思后我们来看下函数内部详情
最重要的分支选择
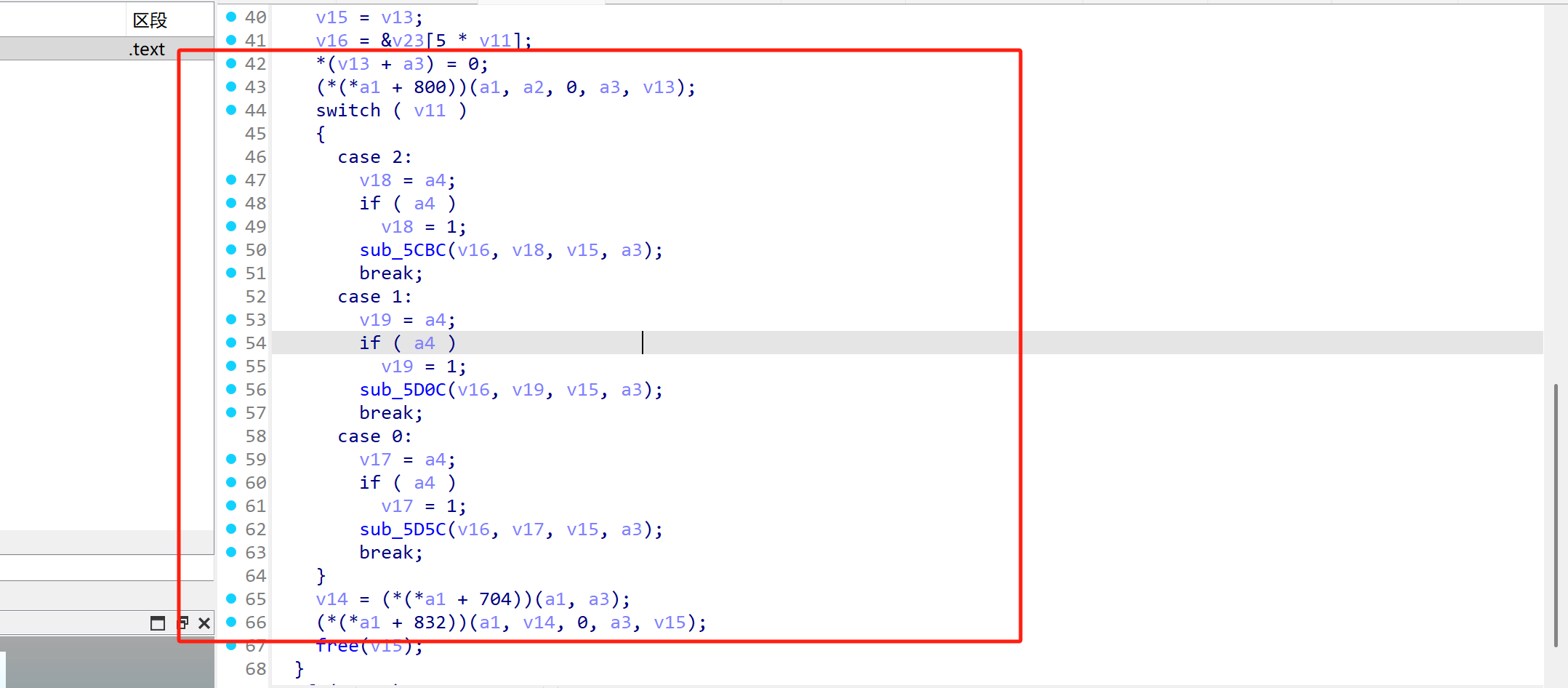
可以看到对应了三个分支,这个分支是和上文我们提到的sv有关系
看这个c代码有些费事,我们选择hook 方式
思路是这样子
我们目前可以hook到java层的 sign sv st的返回
可以知道sv
hook 下面三个分支的函数触发
因为 0,1,2的组合排序是有限的看看我们能不能发现规律
这是我的hook 给大家截下图
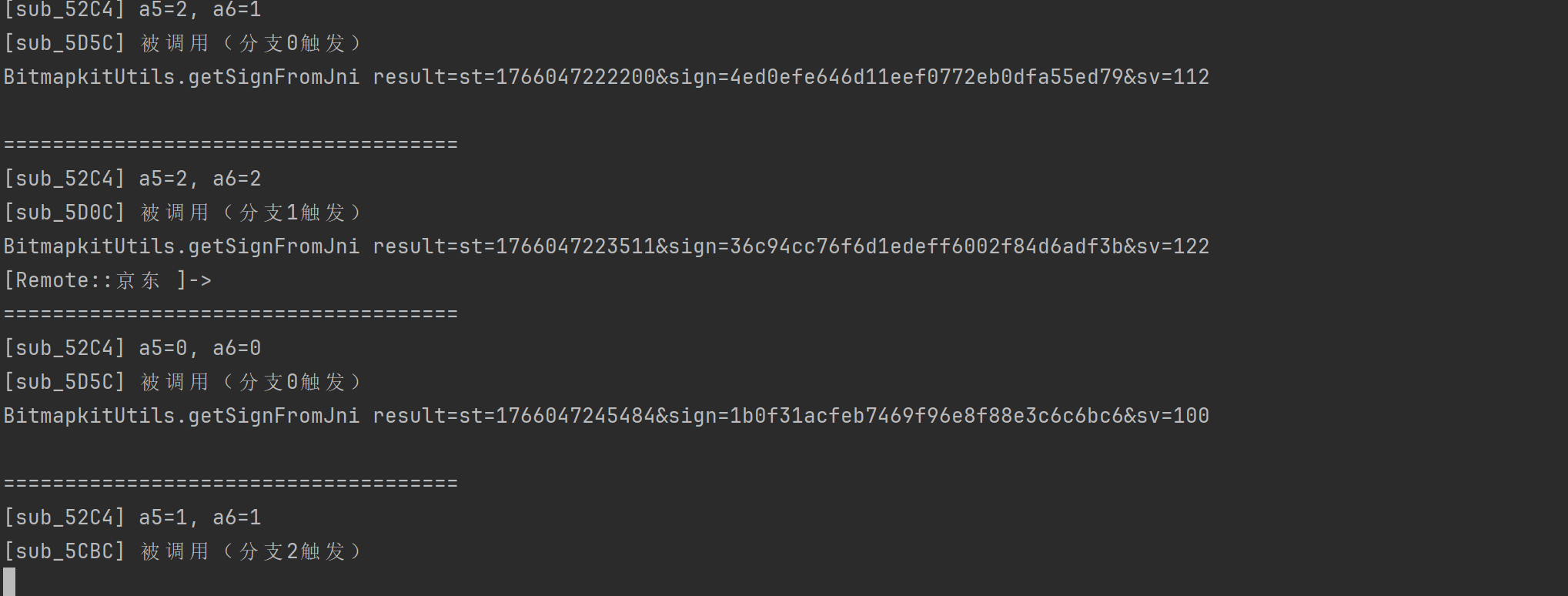
多次触发可以发现下面规律
100 触发 0分支
101触发 1分支
102触发 2分支
110触发 1分支
111触发 2分支
112触发 0分支
120触发 2分支
121触发 0分支
122触发 1分支
所以说我们其实可以挑一个简单的分支只分析一个就ok
这里面建议直接看2分支好一点 也就是5cbc
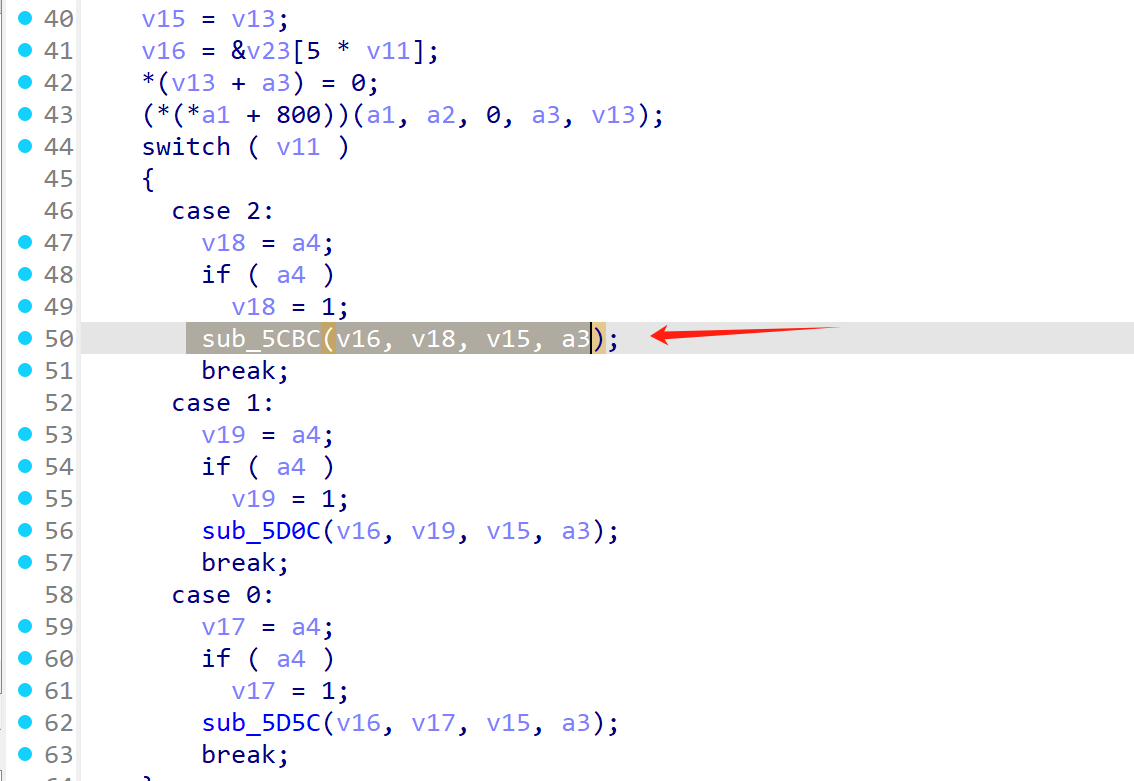
sub_5CBC
sub_5CBC(v16, v18, v15, a3);
入参意思分别是
[+] a1 (上下文):
[+] a2 (分支/密钥): 0x1 (0x1)固定
[+] a3 (字节数组指针): 这个是指针 入参时候这个指针是明文,加密结束后这个指针是密文
[+] a4 (数组长度): 上面a3的长度
我们hook下这个函数
可以看到明文就是 字符串拼接起来加上st和sv
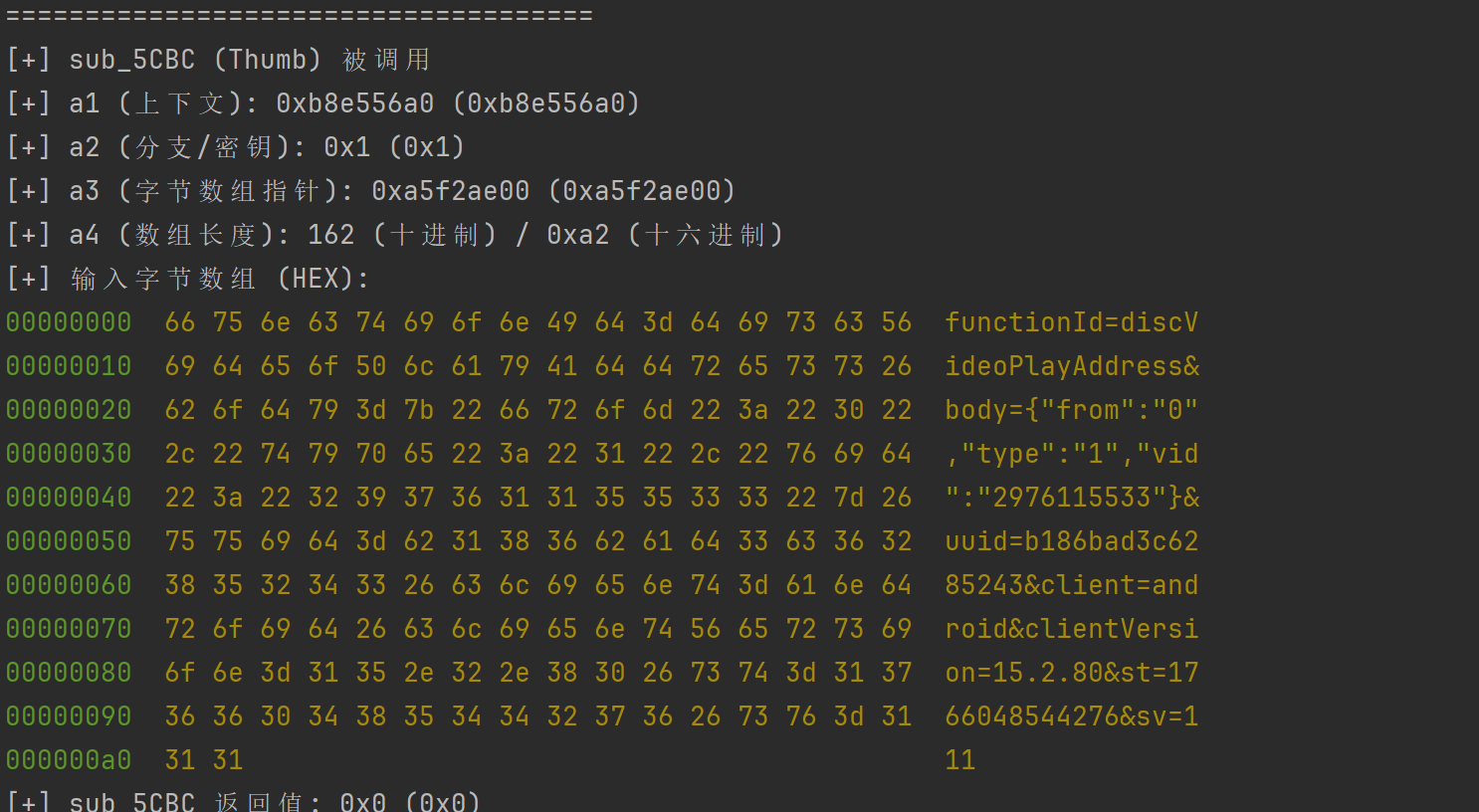
看下5cbc的内部
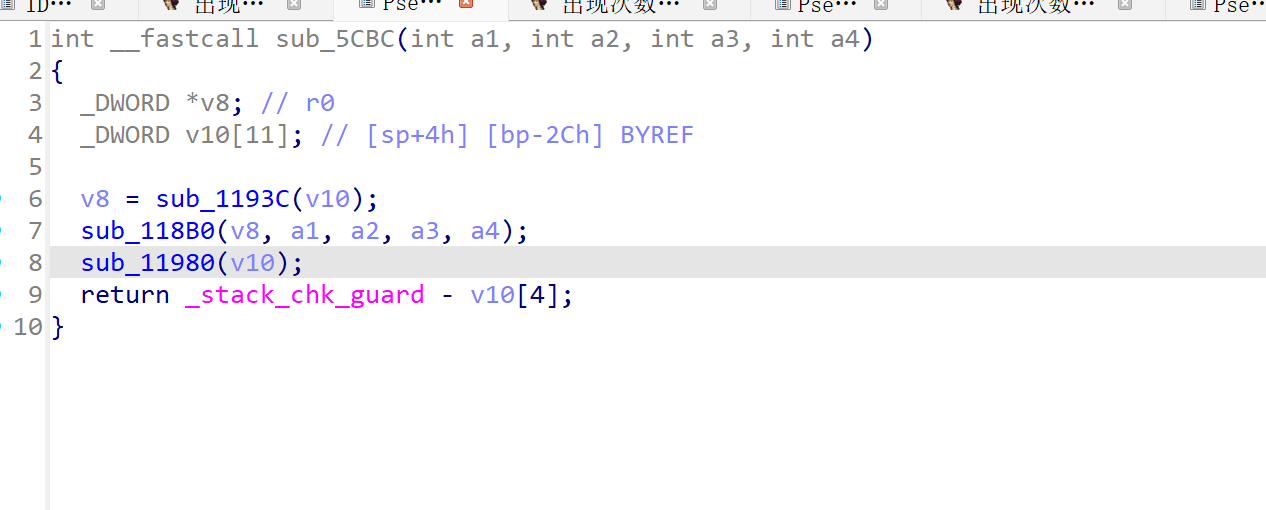
sub_1193c
先看sub_1193c 实际做了一些密钥处理
_DWORD *__fastcall sub_1193C(_DWORD *a1)
{
_DWORD *v2; // r0
void *v3; // r0
a1[2] = 0; // 步骤1:初始化上下文第3位为0(状态标记)
a1[3] = 0; // 步骤2:初始化上下文第4位为0(状态标记)
v2 = operator new[](8u); // 步骤3:分配8字节堆内存(存固定密钥/IV)
*a1 = v2; // 步骤4:上下文第1位 = 8字节内存指针
v2[1] = 16909322; // 步骤5:8字节内存的高4字节 = 固定常数(密钥/IV部分1)
*v2 = 270680193; // 步骤6:8字节内存的低4字节 = 固定常数(密钥/IV部分2)
v3 = operator new[](0x40u); // 步骤7:分配64字节堆内存(存加密S盒/轮密钥)
a1[1] = v3; // 步骤8:上下文第2位 = 64字节内存指针
qmemcpy(v3, &unk_16D8, 0x40u); // 步骤9:拷贝固定字节数组unk_16D8到64字节内存
return a1; // 步骤10:返回初始化后的上下文指针
}
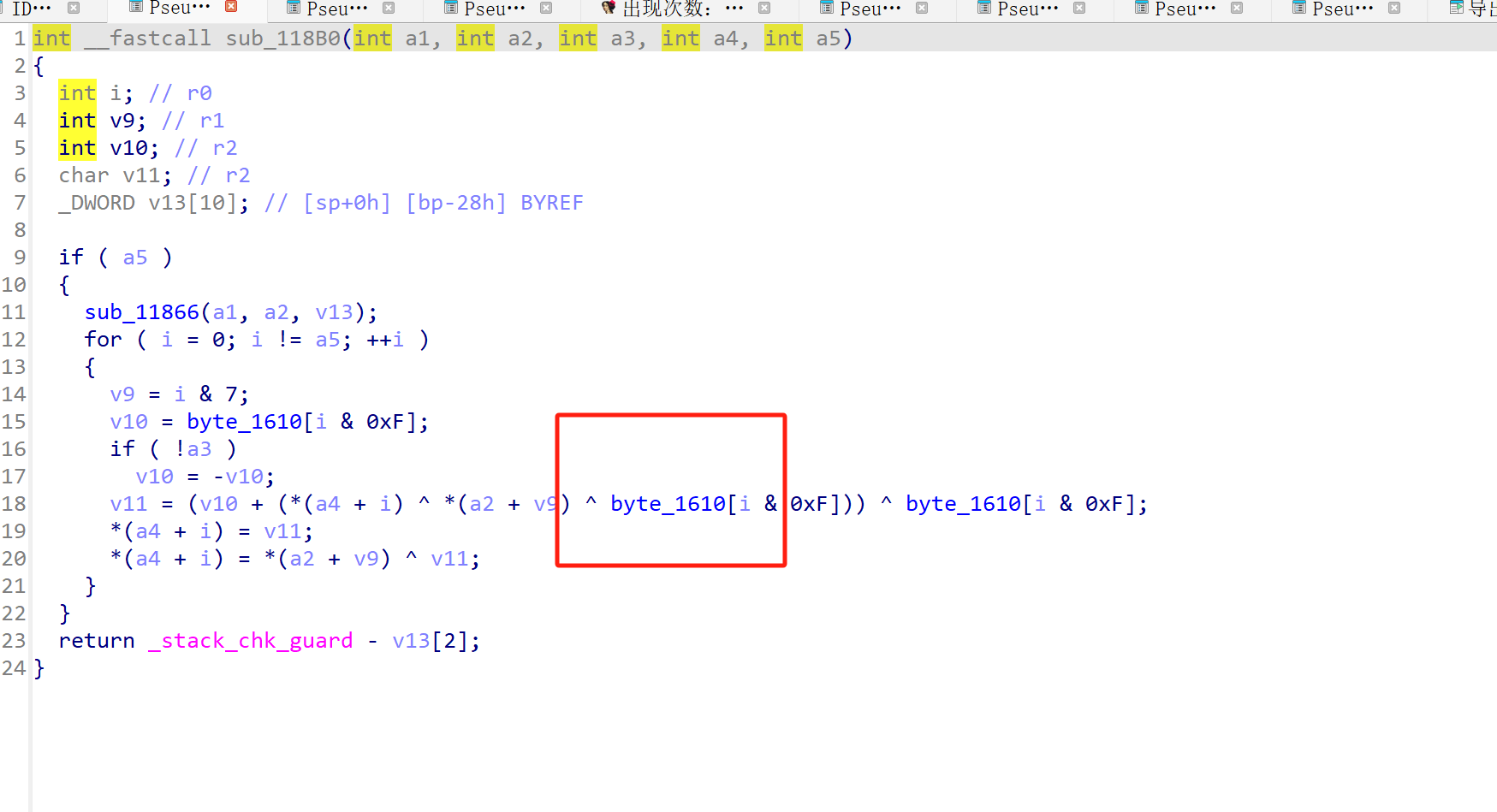
sub_118B0
实际加密是在这里 sub_118B0(v8, a1, a2, a3, a4);
看下函数内部
int __fastcall sub_118B0(int a1, int a2, int a3, int a4, int a5)
{
int i; // r0
int v9; // r1
int v10; // r2
char v11; // r2
_DWORD v13[10]; // [sp+0h] [bp-28h] BYREF
if ( a5 ) // 步骤1:明文长度a5≠0才执行加密(核心条件)
{
sub_11866(a1, a2, v13); // 步骤2:调用sub_11866生成密钥状态(v13)
for ( i = 0; i != a5; ++i ) // 步骤3:遍历每个明文字节(流加密核心:逐字节处理)
{
v9 = i & 7; // 步骤4:i模8(对应密钥状态的8个位置,循环使用)
v10 = byte_1610[i & 0xF]; // 步骤5:读取固定16字节数组byte_1610的第(i模16)个字节(补充密钥流)
if ( !a3 ) // 步骤6:a3=0时取反(分支参数,控制加密变种)
v10 = -v10;
// 步骤7:核心加密运算(逐字节异或)
v11 = (v10 + (*(a4 + i) ^ *(a2 + v9) ^ byte_1610[i & 0xF])) ^ byte_1610[i & 0xF];
*(a4 + i) = v11; // 步骤8:加密后的字节写回原地址(原地加密)
*(a4 + i) = *(a2 + v9) ^ v11; // 步骤9:二次异或(变种RC4的核心修改)
}
}
return _stack_chk_guard - v13[2]; // 步骤10:栈溢出保护(和加密无关)
}
这里面有两个我们需要处理
sub_11866函数
和byte_1610数组
byte_1610数组
双击此处
跳转到这里
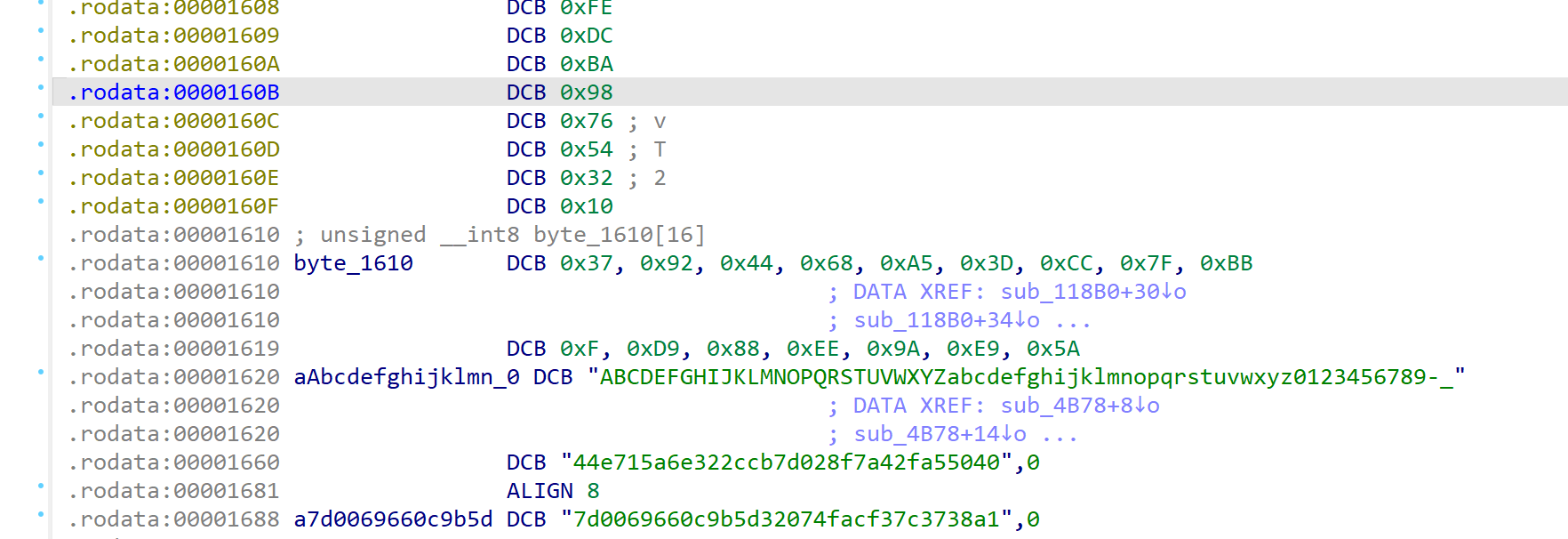
可以看到byte_1610的值了
BYTE_1610 = bytes([
0x37, 0x92, 0x44, 0x68, 0xA5, 0x3D, 0xCC, 0x7F,
0xBB, 0x0F, 0xD9, 0x88, 0xEE, 0x9A, 0xE9, 0x5A
])
sub_11866
_DWORD *__fastcall sub_11866(_DWORD *result, int a2, _DWORD *a3)
{
unsigned int v3; // lr
unsigned int v4; // r3
unsigned int v5; // r4
char v6; // r12
char v7; // r5
v3 = 0;
a3[1] = 0; // 步骤1:初始化密钥状态数组第2位为0
*a3 = 0; // 步骤2:初始化密钥状态数组第1位为0
do
{
v4 = *(result[1] + v3); // 步骤3:读取S盒字节(result[1]是sub_1193C的64字节S盒/unk_16D8)
v5 = v3 >> 3; // 步骤4:v3除以8(64字节S盒→8个DWORD,对应a3的8个位置)
v6 = *(a3 + (v3 >> 3)); // 步骤5:读取当前密钥状态字节
v7 = v3++ & 7; // 步骤6:v3模8(定位到DWORD内的第几位) + v3自增
// 步骤7:核心位运算 → 构建密钥状态(结合S盒+分支密钥a2)
*(a3 + v5) = (((*(*result + (v4 & 7)) & *(a2 + (v4 >> 3))) != 0) << v7) | v6;
} while ( v3 != 64 ); // 步骤8:遍历64次(覆盖整个64字节S盒)
return result; // 步骤9:返回上下文指针(无实际意义)
}
其实到这里面就没什么问题了
给大家截个图
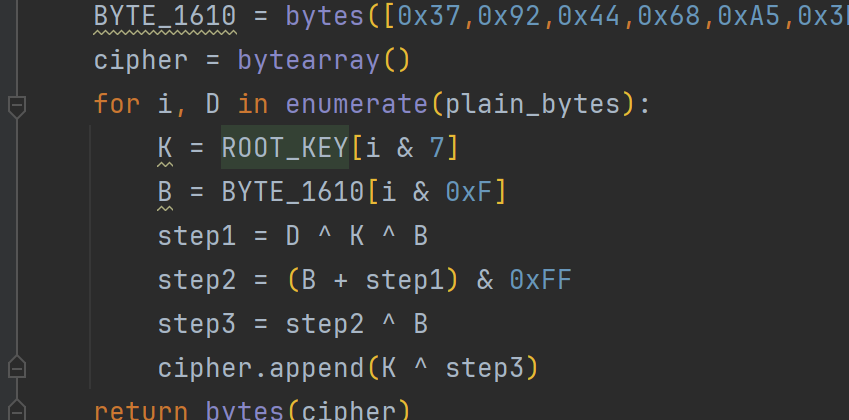
到这里5cbc的加密就结束了
到这里面还没有完成
还有两个函数处理
sub_1C08

这个函数是一个标准的base64算法,因为有标准的编码表
就是这个东西 aAbcdefghijklmn
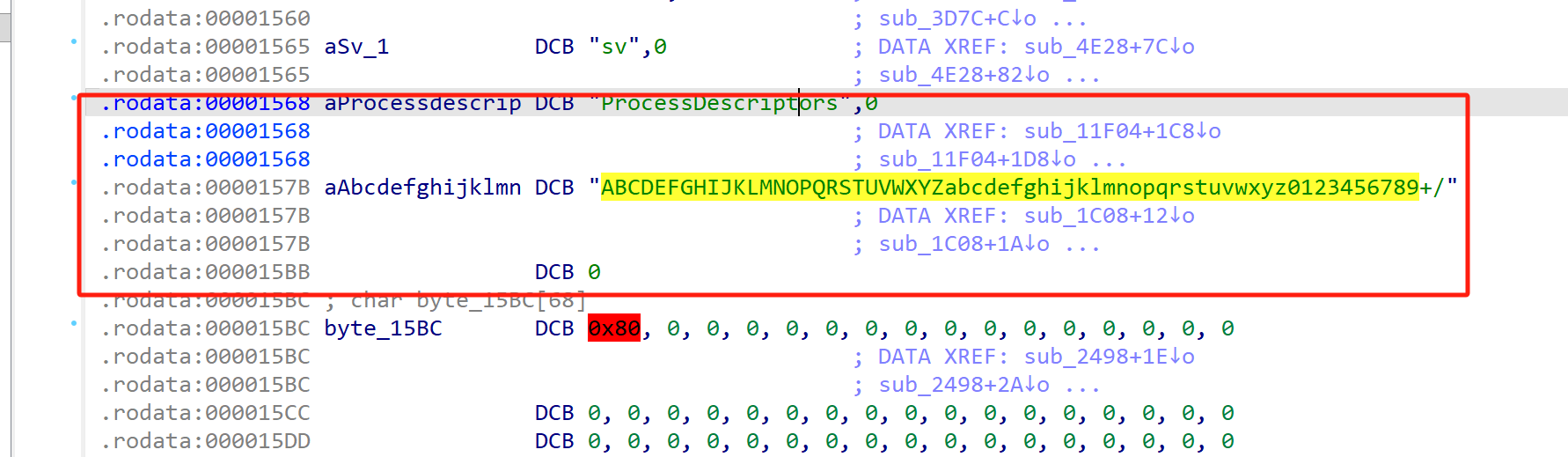
说明把加密后进行了base64处理
然后还有最后一步
sub_25D0
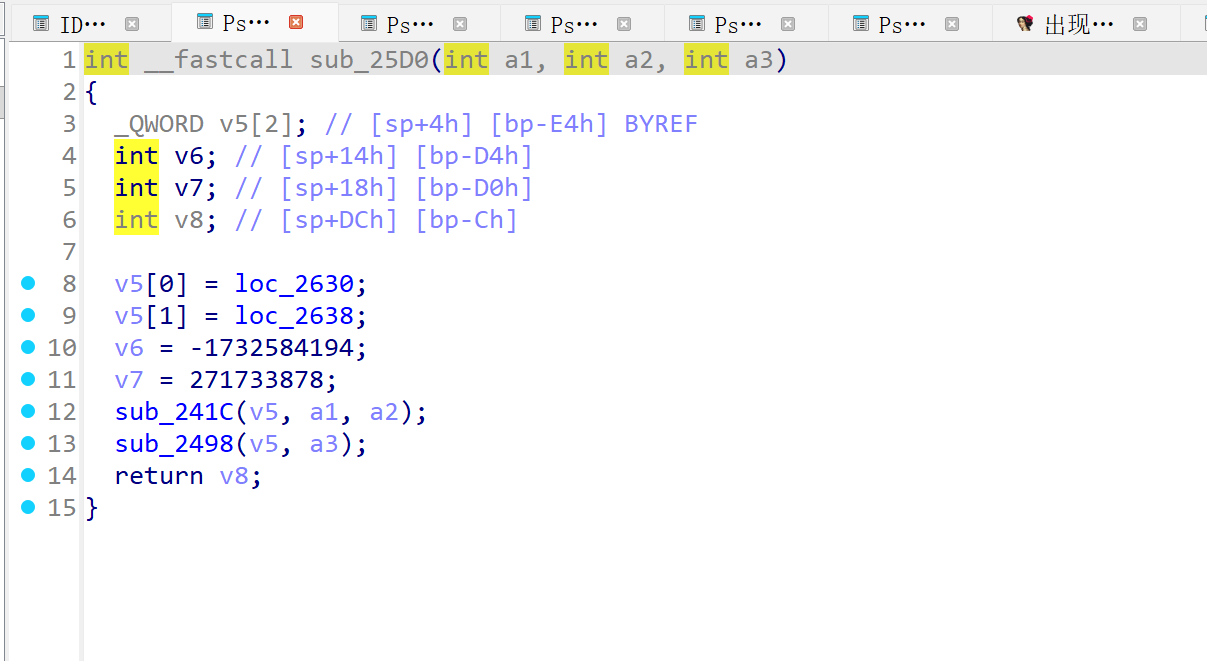
看到有这个
v6 = -1732584194;
v7 = 271733878;
就已经很明确了 标准的md5算法
这步就是把base64编码后进行md5最后生成了sv
流程梳理
入口函数
拼接字符串 生成st sv
加密控制函数 选择分支加密
加密函数(5cbc)进行加密返回加密字节
返回字节进行base64编码
编码后标准md5输出
验证
先hook下分支为2的

复制下值
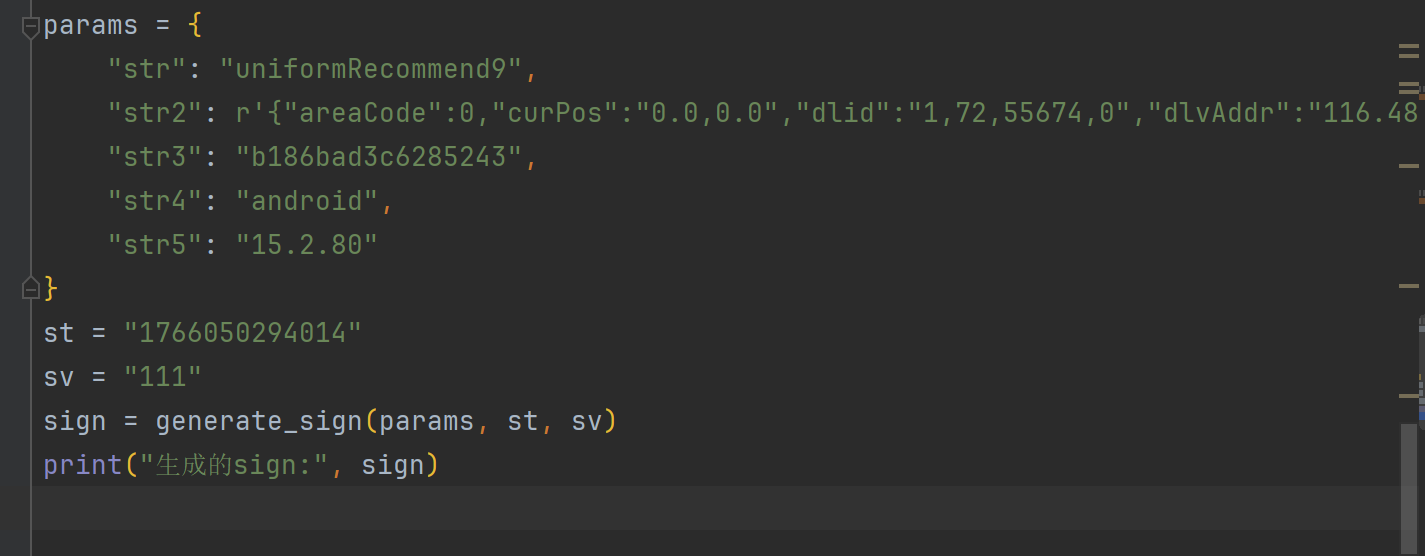

值完全一致成功了!!!
过frida检测
另外有兴趣的可以看下frida检测
实际上检测位于libJDMobileSec.so
用mt直接把这个文件删除了就行
/data/app/jd/lib/arm下


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









