




 这篇博客介绍了机器学习的基础算法,包括使用sklearn库实现k-近邻算法,通过数据处理、模型选择与调优进行预测。还探讨了朴素贝叶斯算法,详细讲解了贝叶斯公式、分类流程及其优缺点,并给出了实际案例。
这篇博客介绍了机器学习的基础算法,包括使用sklearn库实现k-近邻算法,通过数据处理、模型选择与调优进行预测。还探讨了朴素贝叶斯算法,详细讲解了贝叶斯公式、分类流程及其优缺点,并给出了实际案例。
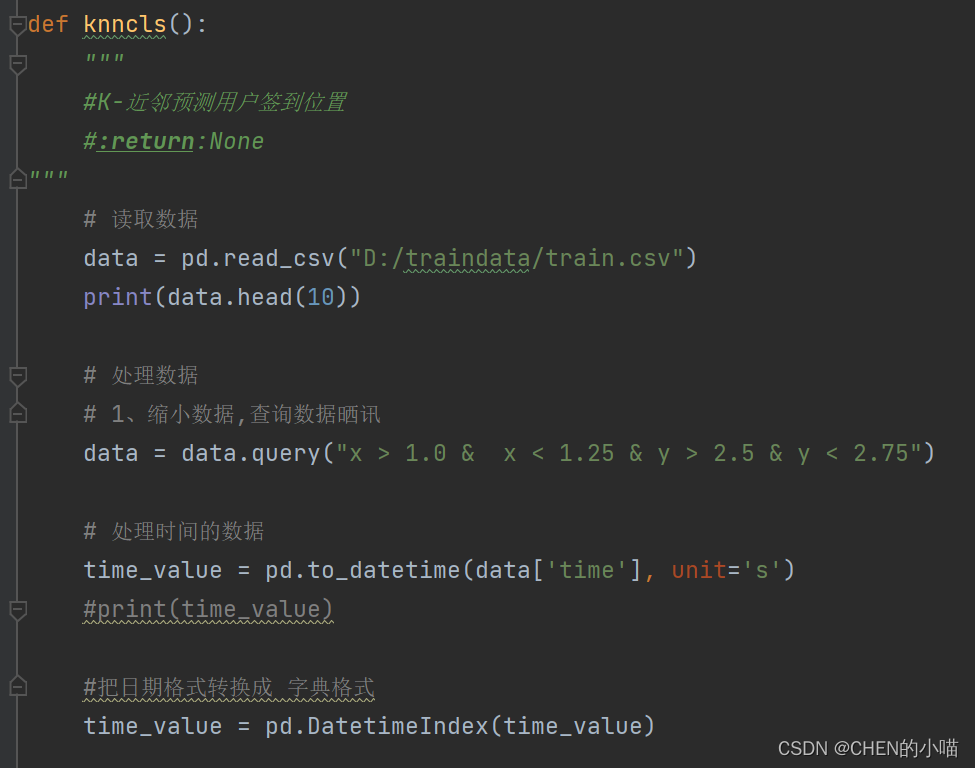
1sklearn k-近邻算法API

数据的处理
(1)缩小数据集范围
DataFrame.query()
(2)处理日期数据
pd.to_datetime
pd.DatetimeIndex
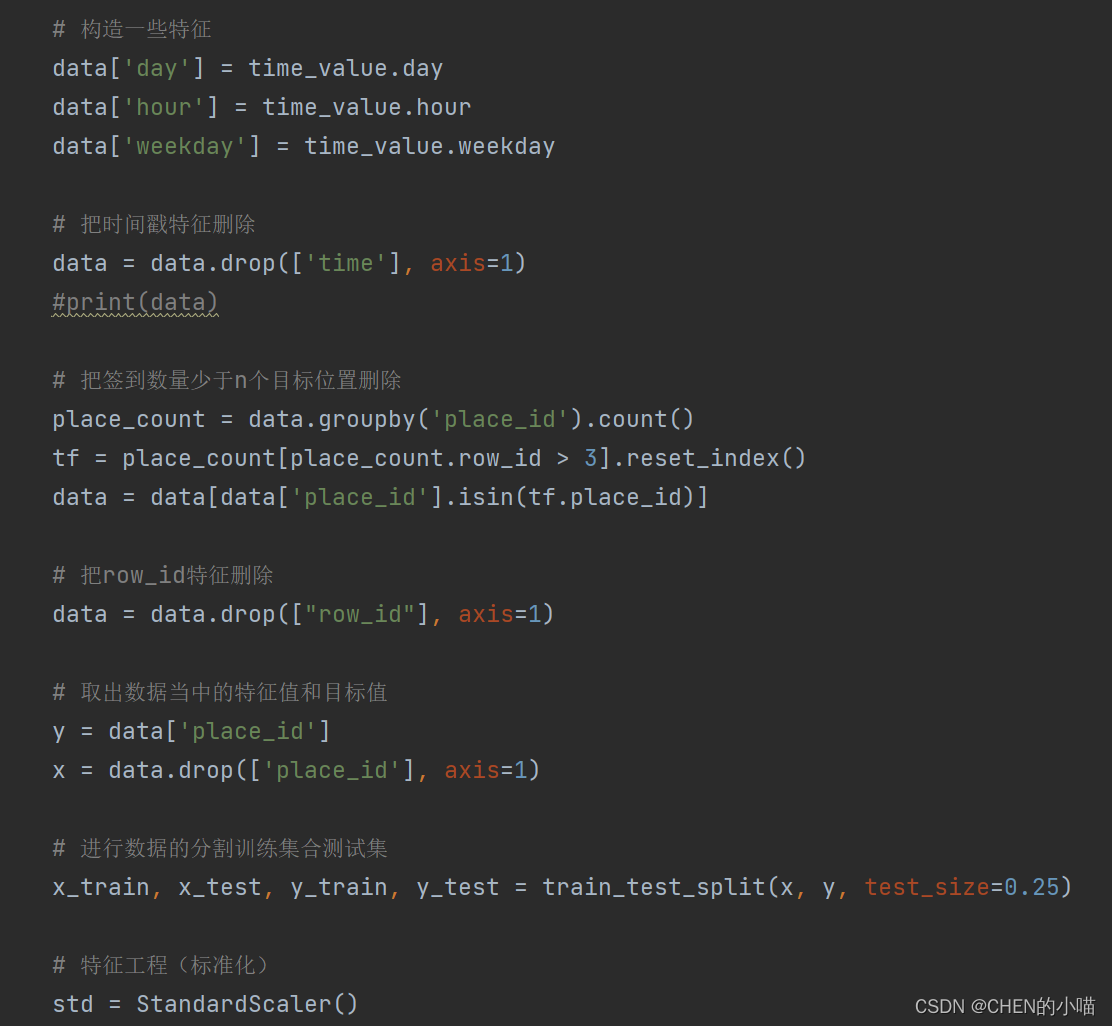
(3)增加分割的日期数据
(4)删除没用的日期数据
pd.drop
(5)将签到位置少于n个用户的删除
place_count =data.groupby('place_id').aggregate(np.count_nonzero)
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
k近邻算法实例-预测入住位置

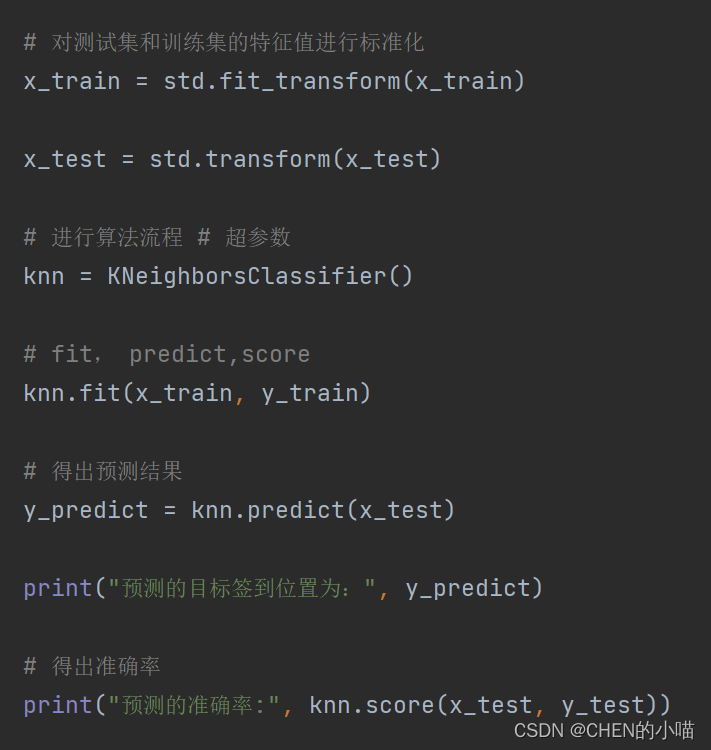
模型的选择与调优
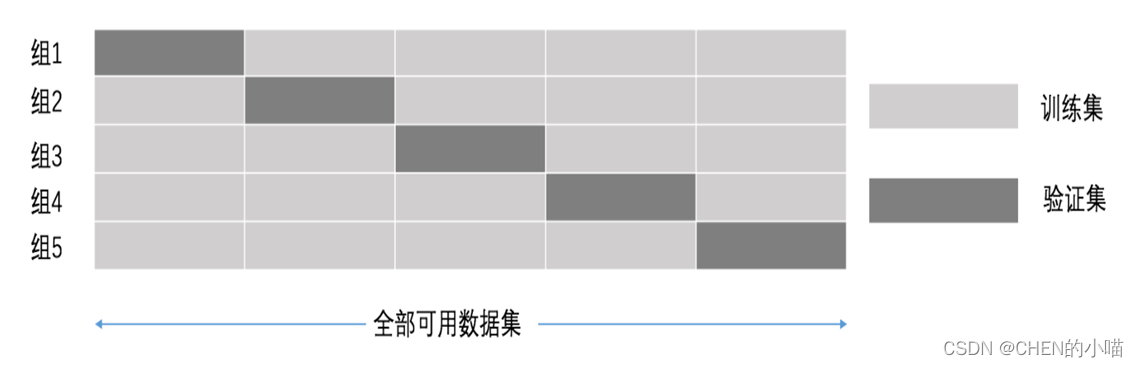
(1)交叉验证
交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
(2)网格搜索
超参数搜索-网格搜索API
•sklearn.model_selection.GridSearchCV
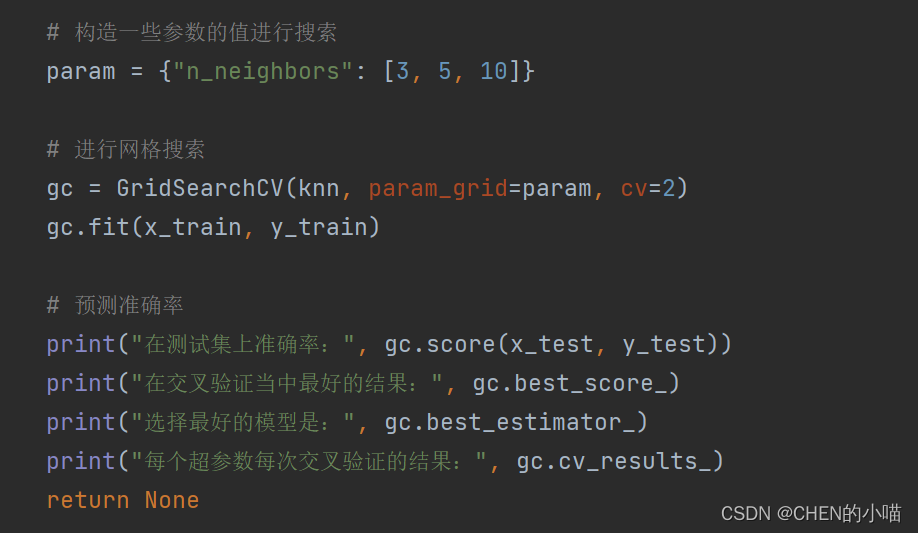
2 朴素贝叶斯-贝叶斯公式
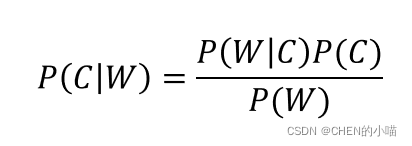
注:w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
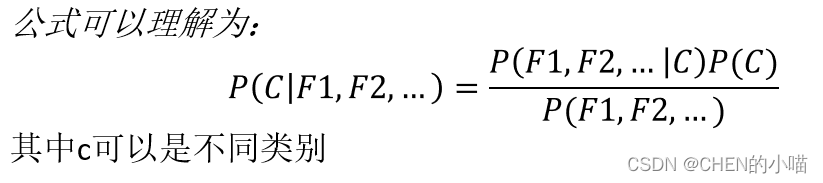

sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
•朴素贝叶斯分类
•alpha:拉普拉斯平滑系数
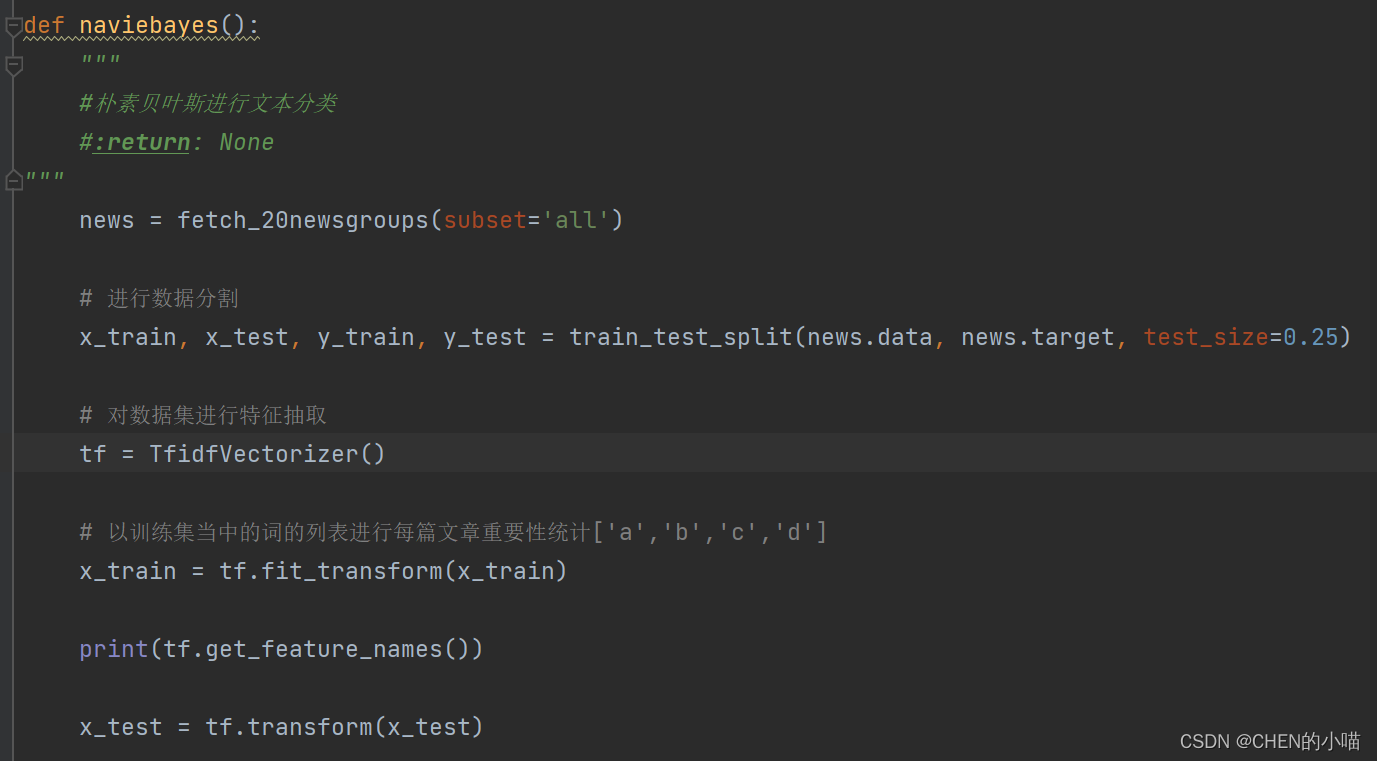
朴素贝叶斯案例
(1)加载20类新闻数据,并进行分割
(2)生成文章特征词
(3)朴素贝叶斯estimator流程进行预估
朴素贝叶斯分类优缺点
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快
缺点:
需要知道先验概率P(F1,F2,…|C),因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









