







一、前言
继续上篇文章叙述,上一篇主要讲解了动作识别的基础知识和研究内容。如果没有了解,可浏览上一篇文章基于动作识别的健身动作识别记录系统
本文主要解释系统的具体实现,其中包括主要实现模块和方法,以及相关的主要代码。
二、Mediapipe框架
Mediapipe是谷歌公司开发的一款开源框架,是一种基于机器视觉的数据处理方式 ,MediaPipe 可以用于处理多种形式的数据输入 包括但不限于图片、视频、音频、文本。MediaPipe显著优势是可移植性高,支持多平台部署, 同时可以部署在GPU和CPU。
通过MediaPipe,输入数据可以被分解成由图形模块表示的多个数据流管道 , 通过人体姿态估计检测器和姿态跟踪网络(如下图)。跟踪网络预测关键点坐标和判断当前帧的任务是否存在。当跟踪器反馈没有人时时,会在下一帧重新运行检测器网络。
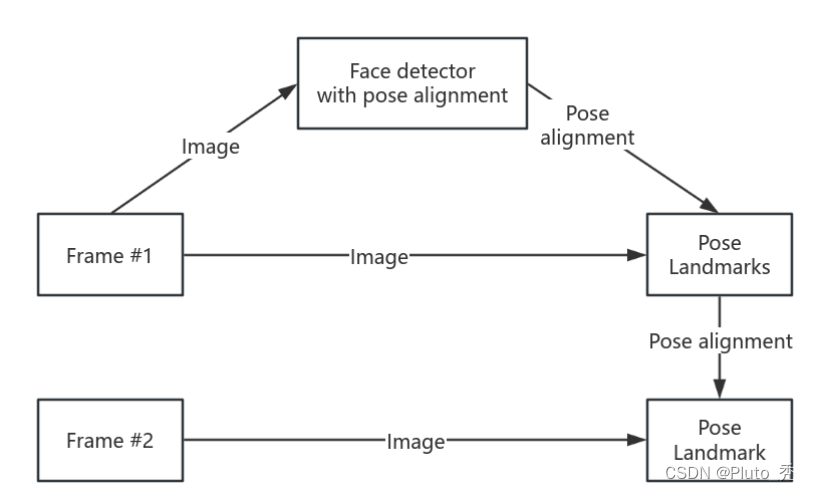
2.1、人体检测
多数物体检测的解决方案都通过非最大抑制(NMS)算法进行最后的处理。这对于自由度较小的检测显然是很实用的。但是,NMS会分解成包含高度清晰的人体姿势的帧,例如握手、深蹲。这是因为多个不确定的框值满足NMS算法的交集并集(IoU)阈值。
Mediapipe通过通过检测人体相对不变或相对刚性的人体部位(如人脸和脊柱),同时通过人脸检测器可预测其他特定于人体的对齐参数这一特性,作为人体检测的代理,计算臀部之间的中间点、环绕整个人的圆圈的大小和倾斜度(连接两个中肩和中臀部点的线之间的角度),从结果看这是有效的。
2.2、实现方法
人体姿态评估中,常见的方法是为每个骨关节点生成热图,同时通过深度学习或者卷积神经网络优化骨关节点坐标的偏移量。这种热图可以在资源使用尽可能小的情况下实现多人检测,但是对于单人的预测却是有过多的资源浪费,模型也要更大。Mediapipe实验中显示,对于这种特例的预测,并通过模型的显着加速,几乎没有质量的下降。
与基于热图的技术相比,基于回归的方法虽然计算要求较低且更具可扩展性,但通过预测平均值坐标,无法避免潜在的数据模糊,精度和可靠性远远不够。即使参数数量较少,堆叠沙漏架构也能显著提高预测质量。Mediapipe使用编码器-解码器网络架构来预测所有关节的热图,并通过另一个编码器降低热图数量,该编码器直接回归到所有骨关节的坐标。简而言之,就是热图分支可以在推理过程中被丢弃,这样推理模型可以足够轻便,在移动设备可快速运行。它的梯度停止连接如下图所示。
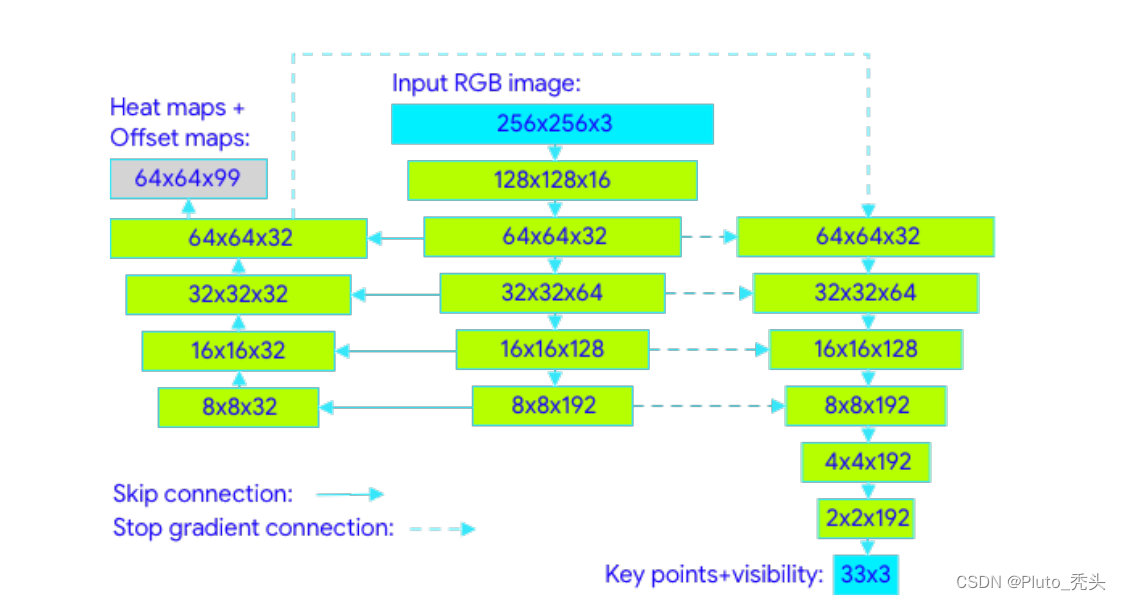
三、系统实现
本章节主要通过四个方面实现:采集骨骼关键点的信息、获取骨骼角度并设定阈值、定义运动状态、系统界面实现。下面依次论述讲解。
3.1、骨骼关键点信息采集
Mediapipe是由谷歌公司开发的开源机器学习应用框架,可以直接采用其预训练好的模型或者自己提供数据进行训练自定义模型。Mediapipe可以实现物体检测、图像分类、手势识别、人体坐标等功能。本文使用的是Mediapipe中对人体骨骼关键点采集的Pose模块实现数据信息采集,谷歌有自己的在线平台,通过在线获取摄像头图像进行识别演示。如果感兴趣可以点击
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









