



 博主分享了自己对词云图的喜爱,并介绍了如何使用Python处理不同格式的数据(TXT、Excel、DOCX)来创建词云图。通过编写三个Python脚本,分别对应不同输入类型,最终整合成一个通用版的程序。
博主分享了自己对词云图的喜爱,并介绍了如何使用Python处理不同格式的数据(TXT、Excel、DOCX)来创建词云图。通过编写三个Python脚本,分别对应不同输入类型,最终整合成一个通用版的程序。
【创作背景】
所有图里面,我对词云图最情有独钟,因为它是人工最不可为的,偏偏对电脑来说,又是特别简单的。这样的人机差异,很动人。
通常,我会把一篇文章存在TXT里,然后画词云图。
偶尔,我会把整理好的词频放在excel里,然后画词云图。
还有的时候,比如我帮朋友画他的QQ群的聊天信息内容,需要把聊天记录文件处理一下(去掉名字和时间行),再画图,这时候用DOCX就很方便,因为DOCX可以逐行筛选处理。
于是我搞了3个PY文件。
之后我又嫌3个文件太占位子了,于是想:搞个三合一的通用版吧。
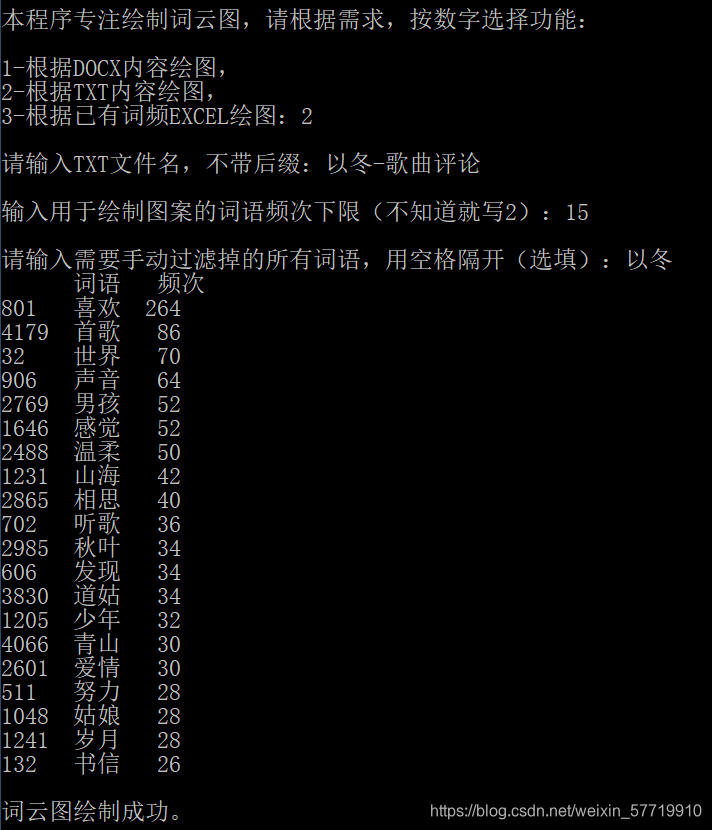
【程序预览】

【完整代码】
import jieba,re
import pandas as pd
import pyecharts.options as opts
from openpyxl import load_workbook
from pyecharts.charts import WordCloud
import docx
def docxcloud(fn,fre_set):
content=''
filename=fn+'.docx'
excelname=fn+'-词频.xlsx'
file = docx.Document(filename)
for p in file.paragraphs:
#if .... (可逐段设置筛选条件)
content+=p.text
return content
def txtcloud(fn,fre_set):
filename=fn+'.txt'
excelname=fn+'-词频.xlsx'
with open (filename,'r',encoding='utf-8') as f:
content=f.read()
return content
def fenci(fn,content):
excelname=fn+'-词频.xlsx'
stop1 = "[^\u4e00-\u9fa5]" # 去掉符号,数字,字母(只保留中文)
content=re.sub(stop1,'',content)
stop2=input('\n请输入需要手动过滤掉的所有词语,用空格隔开(选填):')
alist=stop2.split()
for i in alist:
content=content.replace(i,'')
# 需要自己建一个“绘制词云图-stopw.xlsx”文件,存放中文常用停顿词(百度就能搜到)
try:
stop3=load_workbook('绘制词云图-stopw.xlsx').active
for j in stop3['A']:
j=j.value
content=content.replace(j,'')
except:
pass
seg_list=jieba.cut(content,cut_all=False)
df=pd.DataFrame(seg_list)
df.columns=['词语']
df=df[df['词语'].str.len()>1] # 去掉所有单字(遗憾,去掉了“爱”等热词)
df['频次']=1
df=df.groupby('词语')['频次'].sum()
data=pd.DataFrame()
data['词语']=df.index
data['频次']=df.values
data=data[data['频次']>fre_set]
data=data.sort_values(by='频次',ascending=False)
print(data.head(20))
data.to_excel(excelname,index=False)
return data
def excelcloud(fn):
filename=fn+'.xlsx'
data=pd.read_excel(filename)
return data
def draw(data):
name=data['词语']
value=data['频次']
data1=[z for z in zip(name,value)]
chart=WordCloud()
chart.add('频次',data_pair=data1,shape='circle',word_size_range=[10,100])
chart.set_global_opts(title_opts=opts.TitleOpts(title=fn))
chart.render('{}-词云图.html'.format(fn))
input('\n词云图绘制成功。')
while True:
print('\n本程序专注绘制词云图,请根据需求,按数字选择功能:')
cho=input('\n1-根据DOCX内容绘图,\n2-根据TXT内容绘图,\n3-根据已有词频EXCEL绘图:')
if cho=='1':
fn=input('\n请输入DOCX文件名,不带后缀:')
fre_set=int(input('\n输入用于绘制图案的词语频次下限(不知道就写2):'))
neirong=docxcloud(fn,fre_set)
cipin=fenci(fn,neirong)
elif cho=='2':
fn=input('\n请输入TXT文件名,不带后缀:')
fre_set=int(input('\n输入用于绘制图案的词语频次下限(不知道就写2):'))
neirong=txtcloud(fn,fre_set)
cipin=fenci(fn,neirong)
else:
fn=input('\n请输入EXCEL文件名,不带后缀:')
cipin=excelcloud(fn)
draw(cipin)

















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









